Lernprogramm: Indizierte geschachtelte JSON-Blobs aus Azure Storage mithilfe von REST
Azure KI-Suche kann JSON-Dokumente und -Arrays in Azure Blob Storage mithilfe eines Indexers indizieren, der teilweise strukturierte Daten lesen kann. Teilweise strukturierte Daten enthalten Tags oder Markierungen, mit denen Inhalte in den Daten voneinander getrennt werden. Sie bilden den Unterschied zwischen unstrukturierten Daten, die vollständig indiziert werden müssen, und formal strukturierten Daten, die einem Datenmodell entsprechen (wie z. B. einem Schema einer relationalen Datenbank), das pro Feld indiziert werden kann.
In diesem Lernprogramm werden geschachtelte JSON-Arrays indiziert. Dabei werden der REST-Client und die Search REST-APIs verwendet, um folgende Aufgaben durchzuführen:
- Einrichten von Beispieldaten und Konfigurieren einer
azureblobDatenquelle - Erstellen eines Azure KI-Suche-Index mit durchsuchbarem Inhalt
- Erstellen und Ausführen eines Indexers zum Lesen des Containers und Extrahieren durchsuchbarer Inhalte
- Durchsuchen des soeben erstellten Index
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Visual Studio Code mit einem REST-Client.
Azure KI Search. Erstellen oder suchen Sie nach einer vorhandenen Ressource für Azure KI Search in Ihrem aktuellen Abonnement.
Hinweis
In diesem Tutorial können Sie den kostenlosen Dienst verwenden. Der kostenlose Suchdienst ist auf drei Indizes, drei Indexer und drei Datenquellen beschränkt. In diesem Tutorial wird davon jeweils eine Instanz erstellt. Vergewissern Sie sich zunächst, dass Ihr Dienst über genügend freie Kapazität für die neuen Ressourcen verfügt.
Herunterladen von Dateien
Laden Sie eine ZIP-Datei des Beispiel-Repositorys herunter und extrahieren Sie den Inhalt. Weitere Informationen.
Beispieldaten sind eine einzelne JSON-Datei mit einem JSON-Array und 1.521 geschachtelten JSON-Elementen. Beispieldaten stammen aus NY Philharmonic Performance History auf Kaggle. Wir haben eine JSON-Datei ausgewählt, um unter den Speichergrenzwerten der kostenlosen Stufe zu bleiben.
Dies ist der erste geschachtelte JSON-Code in der Datei. Der Rest der Datei umfasst 1.520 weitere Instanzen von Konzertaufführungen.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Hochladen von Beispieldaten in Azure Storage
Erstellen Sie in Azure Storage einen neuen Container, und nennen Sie ihn ny-philharmonic-free.
Rufen Sie eine Speicherverbindungszeichenfolge ab, damit Sie eine Verbindung in Azure KI Search formulieren können.
Wählen Sie auf der linken Seite Zugriffsrichtlinien aus.
Kopieren Sie die Verbindungszeichenfolge für schlüssel 1 oder zwei Schlüssel. Die Verbindungszeichenfolge ist eine URL, die in etwa wie folgt aussieht:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
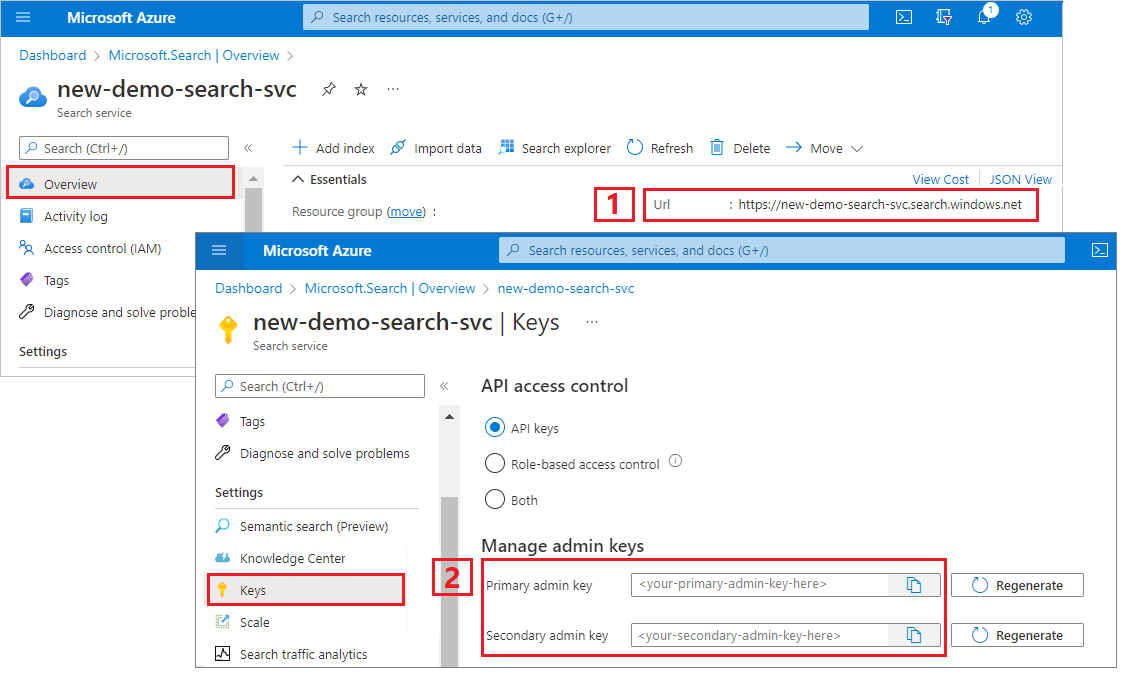
Kopiert die Suchdienst-URL und den API-Schlüssel
Für dieses Tutorial benötigen Verbindungen mit Azure KI Search einen Endpunkt und einen API-Schlüssel. Diese Werte erhalten Sie im Azure-Portal.
Melden Sie sich beim Azure-Portalan, navigieren Sie zur Seite Übersicht des Suchdiensts, und kopieren Sie die URL. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Kopieren Sie unter Einstellungen>Schlüssel einen Administratorschlüssel. Mit einem Administratorschlüssel können Sie Objekte hinzufügen, ändern und löschen. Es gibt zwei austauschbare Administratorschlüssel. Kopieren Sie einen der beiden Schlüssel.
Einrichten der REST-Datei
Starten von Visual Studio Code und Erstellen einer neuen Datei
Geben Sie Werte für Variablen an, die in der Anforderung verwendet werden:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESpeichern Sie die Datei mit der Dateierweiterung
.restoder.http.
Siehe Schnellstart: Textsuche mithilfe von REST, wenn Sie Hilfe beim REST-Client benötigen.
Erstellen einer Datenquelle
Create Data Source (REST) erstellt eine Datenquellenverbindung, die angibt, welche Daten indiziert werden sollen.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Senden Sie die Anforderung. Die Antwort sollte in etwa wie folgt aussehen:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Erstellen eines Index
Index erstellen (REST) erstellt einen Suchindex für Ihren Suchdienst. Ein Index gibt alle Parameter und die dazugehörigen Attribute an.
Für geschachtelte JSON müssen die Indexfelder mit den Quellfeldern identisch sein. Derzeit unterstützt Azure AI Search keine Feldzuordnungen zu geschachtelten JSON-Daten. Aus diesem Grund müssen Feldnamen und Datentypen vollständig übereinstimmen. Der folgende Index richtet sich an die JSON-Elemente im rohen Inhalt.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Die wichtigsten Punkte:
Sie können Feldzuordnungen nicht verwenden , um Unterschiede in Feldnamen oder Datentypen abzugleichen. Dieses Indexschema ist so konzipiert, dass der rohe Inhalt gespiegelt wird.
Geschachtelte JSON wird als
Collection(Edm.ComplextType)modelliert. Im Rohinhalt gibt es für jede Saison mehrere Konzerte und für jedes Konzert mehrere Werke. Verwenden Sie Sammlungen für komplexe Typen, um diese Struktur zu berücksichtigen.Im rohen Inhalt
DateundTimesind Zeichenfolgen, sodass die entsprechenden Datentypen im Index auch Zeichenfolgen sind.
Erstellen und Ausführen eines Indexers
"Indexer erstellen" erstellt einen Indexer für Ihren Suchdienst. Ein Indexer verbindet sich mit der Datenquelle, lädt und indiziert Daten und stellt optional einen Zeitplan für die Automatisierung der Datenaktualisierung bereit.
Die Indexerkonfiguration enthält den jsonArray Analysemodus und eine documentRoot.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Die wichtigsten Punkte:
Die Rohinhaltsdatei enthält ein JSON-Array (
"programs") mit 1.526 geschachtelten JSON-Strukturen. Legen SieparsingModediesen Wert fest,jsonArrayum dem Indexer mitzuteilen, dass jedes Blob ein JSON-Array enthält. Da der geschachtelte JSON-Code eine Ebene nach unten beginnt, legen Sie diesen WertdocumentRootauf/programs.Der Indexer wird mehrere Minuten lang ausgeführt. Warten Sie, bis die Indizierungsausführung abgeschlossen ist, bevor Sie Abfragen ausführen.
Ausführen von Abfragen
Sie können mit der Suche beginnen, sobald das erste Dokument geladen wurde.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Senden Sie die Anforderung. Dies ist eine nicht spezifizierte Volltextsuchabfrage, mit der zusätzlich zur Dokumentanzahl alle Felder zurückgegeben werden, die im Index als abrufbar gekennzeichnet sind. Die Antwort sollte in etwa wie folgt aussehen:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Fügen Sie einen search Parameter hinzu, um nach einer Zeichenfolge zu suchen. Fügen Sie den Abfrageparameter select hinzu, um die Ergebnisse auf eine geringere Anzahl von Feldern zu beschränken. Fügen Sie eine filter hinzu, um die Suche weiter einzugrenzen.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
In der Antwort werden zwei Dokumente zurückgegeben.
Sie können für Filter auch logische Operatoren (and, or, not) und Vergleichsoperatoren (eq, ne, gt, lt, ge, le) nutzen. Bei Zeichenfolgenvergleichen wird die Groß-/Kleinschreibung beachtet. Weitere Informationen und Beispiele finden Sie unter Erstellen einer Abfrage.
Hinweis
Der Parameter $filter funktioniert nur mit Metadaten, die beim Erstellen des Index als filterbar gekennzeichnet wurden.
Zurücksetzen und erneut ausführen
Indexer können zurückgesetzt werden. Dabei wird der Ausführungsverlauf gelöscht, sodass eine vollständige erneute Ausführung möglich ist. Die folgenden GET-Anforderungen werden zurückgesetzt, gefolgt von einer erneuten Ausführung.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können einzelne Ressourcen oder die gesamte Ressourcengruppe mit allen darin enthaltenen Ressourcen löschen.
Sie können das Azure-Portal verwenden, um Indizes, Indexer und Datenquellen zu löschen.
Nächste Schritte
Nachdem Sie sich nun mit den Grundlagen der Azure-Blobindizierung vertraut gemacht haben, können Sie sich die Indexerkonfiguration für JSON-Blobs in Azure Storage genauer ansehen.