Lernprogramm: Indizierte geschachtelte Markdown-Blobs aus Azure Storage mithilfe von REST
Hinweis
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschau wird ohne Vereinbarung zum Servicelevel bereitgestellt und nicht für Produktionsworkloads empfohlen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Azure KI-Suche kann Markdown-Dokumente und -Arrays in Azure Blob Storage mithilfe eines Indexers indizieren, der Markdown-Daten lesen kann.
In diesem Lernprogramm wird gezeigt, wie Sie Markdowndateien indizieren, die mithilfe des oneToMany-Markdown-Analysemodus indiziert wurden. Dabei werden der REST-Client und die Search REST-APIs verwendet, um folgende Aufgaben durchzuführen:
- Einrichten von Beispieldaten und Konfigurieren einer
azureblobDatenquelle - Erstellen eines Azure KI-Suche-Index mit durchsuchbarem Inhalt
- Erstellen und Ausführen eines Indexers zum Lesen des Containers und Extrahieren durchsuchbarer Inhalte
- Durchsuchen des soeben erstellten Index
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Visual Studio Code mit einem REST-Client.
Azure KI Search. Erstellen oder suchen Sie nach einer vorhandenen Ressource für Azure KI Search in Ihrem aktuellen Abonnement.
Hinweis
In diesem Tutorial können Sie den kostenlosen Dienst verwenden. Der kostenlose Suchdienst ist auf drei Indizes, drei Indexer und drei Datenquellen beschränkt. In diesem Tutorial wird davon jeweils eine Instanz erstellt. Vergewissern Sie sich zunächst, dass Ihr Dienst über genügend freie Kapazität für die neuen Ressourcen verfügt.
Erstellen eines Markdown-Dokuments
Kopieren Sie den folgenden Markdown-Code, und fügen Sie ihn in eine Datei mit dem Namen sample_markdown.md ein. Die Beispieldaten sind eine einzelne Markdowndatei mit verschiedenen Markdown-Elementen. Wir haben eine Markdowndatei ausgewählt, um unter den Speichergrenzwerten der kostenlosen Stufe zu bleiben.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
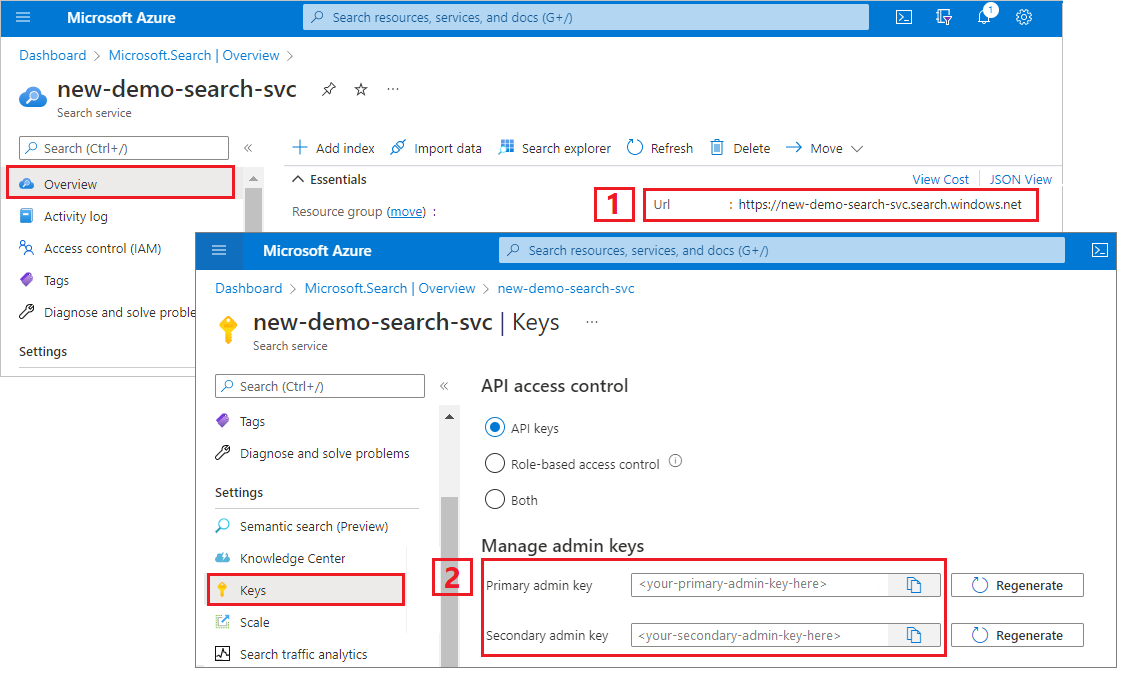
Kopiert die Suchdienst-URL und den API-Schlüssel
Für dieses Tutorial benötigen Verbindungen mit Azure KI Search einen Endpunkt und einen API-Schlüssel. Diese Werte erhalten Sie im Azure-Portal. Alternative Verbindungsmethoden finden Sie unter Verwaltete Identitäten.
Melden Sie sich beim Azure-Portalan, navigieren Sie zur Seite Übersicht des Suchdiensts, und kopieren Sie die URL. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Kopieren Sie unter Einstellungen>Schlüssel einen Administratorschlüssel. Mit einem Administratorschlüssel können Sie Objekte hinzufügen, ändern und löschen. Es gibt zwei austauschbare Administratorschlüssel. Kopieren Sie einen der beiden Schlüssel.
Einrichten der REST-Datei
Starten Sie Visual Studio Code und erstellen Sie eine neue Datei.
Geben Sie Werte für Variablen an, die in der Anforderung verwendet werden:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESpeichern Sie die Datei mit der Dateierweiterung
.restoder.http.
Siehe Schnellstart: Textsuche mithilfe von REST, wenn Sie Hilfe beim REST-Client benötigen.
Erstellen einer Datenquelle
Create Data Source (REST) erstellt eine Datenquellenverbindung, die angibt, welche Daten indiziert werden sollen.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Senden Sie die Anforderung. Die Antwort sollte in etwa wie folgt aussehen:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Erstellen eines Index
Index erstellen (REST) erstellt einen Suchindex für Ihren Suchdienst. Ein Index gibt alle Felder und die dazugehörigen Attribute an.
In der 1:n-Analyse definiert das Suchdokument die n-Seite der Beziehung. Die im Index angegebenen Felder bestimmen die Struktur des Suchdokuments.
Sie benötigen nur Felder für die Markdown-Elemente, die der Parser unterstützt. Die Felder lauten:
content: Eine Zeichenfolge, die den unformatierten Markdown enthält, der an einer bestimmten Stelle gefunden wurde, basierend auf den Headermetadaten an diesem Punkt im Dokument.sections: Ein Objekt, das Unterfelder für die Headermetadaten bis zur gewünschten Headerebene enthält. Wenn z. B.markdownHeaderDepthaufh3festgelegt ist, sind Zeichenfolgenfelderh1,h2undh3enthalten. Diese Felder werden durch Spiegelung dieser Struktur im Index oder durch Feldzuordnungen im Format/sections/h1,sections/h2usw. indiziert. In den folgenden Beispielen finden Sie Index- und Indexerkonfigurationen für Kontextbeispiele. Die enthaltenen Unterfelder sind:-
h1– Eine Zeichenfolge, die den h1-Headerwert enthält. Leere Zeichenfolge, wenn sie an diesem Punkt im Dokument nicht festgelegt ist. - (Optional)
h2– Eine Zeichenfolge, die den h2-Headerwert enthält. Leere Zeichenfolge, wenn sie an diesem Punkt im Dokument nicht festgelegt ist. - (Optional)
h3– Eine Zeichenfolge, die den h3-Headerwert enthält. Leere Zeichenfolge, wenn sie an diesem Punkt im Dokument nicht festgelegt ist. - (Optional)
h4– Eine Zeichenfolge, die den h4-Headerwert enthält. Leere Zeichenfolge, wenn sie an diesem Punkt im Dokument nicht festgelegt ist. - (Optional)
h5– Eine Zeichenfolge, die den h5-Headerwert enthält. Leere Zeichenfolge, wenn sie an diesem Punkt im Dokument nicht festgelegt ist. - (Optional)
h6– Eine Zeichenfolge, die den h6-Headerwert enthält. Leere Zeichenfolge, wenn sie an diesem Punkt im Dokument nicht festgelegt ist.
-
ordinal_position: Ein ganzzahliger Wert, der die Position des Abschnitts innerhalb der Dokumenthierarchie angibt. Dieses Feld wird verwendet, um die Abschnitte in der ursprünglichen, im Dokument angezeigten Reihenfolge zu sortieren, beginnend mit einer Ordnungsposition von 1 und einer sequenziellen Erhöhung für jeden Inhaltsblock.
Diese Implementierung nutzt Feldzuordnungen im Indexer, um vom erweiterten Inhalt zum Index zuzuordnen. Weitere Informationen zur analysierten 1:n-Dokumentstruktur finden Sie unter Indizierte Markdown-Blobs.
Dieses Beispiel enthält Beispiele zum Indizieren von Daten mit und ohne Feldzuordnungen. In diesem Fall wissen wir, dass h1 den Titel des Dokuments enthält, damit wir es einem Feld mit dem Namen title zuordnen können. Außerdem werden die Felder h2 und h3 den Feldern h2_subheader bzw. h3_subheader zugeordnet. Die Felder content und ordinal_position erfordern keine Zuordnung, da sie direkt aus dem Markdown in Felder extrahiert werden, die diese Namen verwenden. Ein Beispiel für ein vollständiges Indexschema, das keine Feldzuordnungen erfordert, finden Sie am Ende dieses Abschnitts.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Indexschema in einer Konfiguration ohne Feldzuordnungen
Mithilfe von Feldzuordnungen können Sie angereicherte Inhalte bearbeiten und filtern, damit sie in Ihre gewünschte Indexform passen, aber Sie können auch nur den angereicherten Inhalt direkt übernehmen. In diesem Fall würde das Schema wie folgt aussehen:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Zur Wiederholung: Wir verfügen über Unterfelder bis zu h3 im Abschnittsobjekt, da markdownHeaderDepth auf h3 festgelegt ist.
Wenn Sie sich für die Verwendung dieses Schemas entscheiden, stellen Sie sicher, dass Sie spätere Anforderungen entsprechend anpassen. Dies erfordert das Entfernen der Feldzuordnungen aus der Indexerkonfiguration und das Aktualisieren von Suchabfragen, um die entsprechenden Feldnamen zu verwenden.
Erstellen und Ausführen eines Indexers
"Indexer erstellen" erstellt einen Indexer für Ihren Suchdienst. Ein Indexer verbindet sich mit der Datenquelle, lädt und indiziert Daten und stellt optional einen Zeitplan für die Automatisierung der Datenaktualisierung bereit.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Die wichtigsten Punkte:
Der Indexer analysiert nur Header bis zu
h3. Alle Header auf niedrigerer Ebene (h4,h5,h6) werden als Nur-Text behandelt und im Feldcontentangezeigt. Aus diesem Grund existieren die Index- und Feldzuordnungen nur bis zu einer Tiefe vonh3.Die Felder
contentundordinal_positionerfordern keine Feldzuordnung, da sie mit diesen Namen im angereicherten Inhalt vorhanden sind.
Ausführen von Abfragen
Sie können mit der Suche beginnen, sobald das erste Dokument geladen wurde.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Senden Sie die Anforderung. Dies ist eine nicht spezifizierte Volltextsuchabfrage, mit der zusätzlich zur Dokumentanzahl alle Felder zurückgegeben werden, die im Index als abrufbar gekennzeichnet sind. Die Antwort sollte in etwa wie folgt aussehen:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Fügen Sie einen search Parameter hinzu, um nach einer Zeichenfolge zu suchen.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Senden Sie die Anforderung. Die Antwort sollte in etwa wie folgt aussehen:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Die wichtigsten Punkte:
Da die
markdownHeaderDepthaufh3festgelegt ist, werden die Headerh4,h5undh6als Nur-Text behandelt, sodass sie im Feldcontentangezeigt werden.Hier ist die Ordnungsposition
4. Dieser Inhalt wird als vierter der insgesamt 22 Inhaltsabschnitte angezeigt.
Fügen Sie den Abfrageparameter select hinzu, um die Ergebnisse auf eine geringere Anzahl von Feldern zu beschränken. Fügen Sie eine filter hinzu, um die Suche weiter einzugrenzen.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
Sie können für Filter auch logische Operatoren (and, or, not) und Vergleichsoperatoren (eq, ne, gt, lt, ge, le) nutzen. Bei Zeichenfolgenvergleichen wird die Groß-/Kleinschreibung beachtet. Weitere Informationen und Beispiele finden Sie unter Erstellen einer Abfrage.
Hinweis
Der Parameter $filter funktioniert nur mit Metadaten, die beim Erstellen des Index als filterbar gekennzeichnet wurden.
Zurücksetzen und erneut ausführen
Indexer können zurückgesetzt werden. Dabei wird der Ausführungsverlauf gelöscht, sodass eine vollständige erneute Ausführung möglich ist. Die folgenden GET-Anforderungen werden zurückgesetzt, gefolgt von einer erneuten Ausführung.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können einzelne Ressourcen oder die gesamte Ressourcengruppe mit allen darin enthaltenen Ressourcen löschen.
Sie können das Azure-Portal verwenden, um Indizes, Indexer und Datenquellen zu löschen.
Nächste Schritte
Nachdem Sie sich nun mit den Grundlagen der Azure-Blobindizierung vertraut gemacht haben, können Sie sich die Indexerkonfiguration für Markdown-Blobs in Azure Storage genauer ansehen.