Tutorial: Debuggen eines Skillsets mithilfe von Debugsitzungen
In Azure KI-Suche koordiniert ein Skillset die Aktionen von Fähigkeiten, die durchsuchbare Inhalte analysieren, transformieren oder erstellen. Häufig wird die Ausgabe einer Fähigkeit zur Eingabe einer anderen. Wenn Eingaben von Ausgaben abhängen, können Fehler in Skillsetdefinitionen und Feldzuordnungen zu fehlenden Vorgängen und Daten führen.
Debugsitzungen ist ein Tool im Azure-Portal, das eine ganzheitliche Visualisierung eines Skillsets ermöglicht, das in der Azure KI-Suche ausgeführt wird. Mithilfe dieses Tools können Sie einen Drilldown für bestimmte Schritte ausführen, um leicht zu ermitteln, wo eine Aktion möglicherweise fehlschlägt.
In diesem Artikel verwenden Sie Debugsitzungen, um fehlende Eingaben und Ausgaben zu suchen und zu korrigieren. Das Tutorial ist umfassend. Es stellt Beispieldaten, eine Postman-Sammlung, die Objekte erstellt, und Anweisungen zum Debuggen von Problemen im Skillset zur Verfügung.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Azure AI Search. Erstellen Sie einen Dienst, oder suchen Sie in Ihrem aktuellen Abonnement nach einem vorhandenen Dienst. In diesem Tutorial können Sie einen kostenlosen Dienst verwenden. Der kostenlose Tarif bietet keine Unterstützung für verwaltete Identitäten für einen Azure KI-Suche-Dienst. Sie müssen Schlüssel für Verbindungen mit Azure Storage verwenden.
Ein Azure Storage-Konto mit Blobspeicher, das zum Hosten von Beispieldaten und zum dauerhaften Speichern zwischengespeicherter Daten verwendet wird, die während einer Debugsitzung erstellt werden. Wenn Sie einen kostenlosen Suchdienst verwenden, müssen für das Speicherkonto freigegebene Zugriffstasten aktiviert sein, und es muss den Zugriff auf öffentliche Netzwerke zulassen.
Visual Studio Code mit einem REST-Client.
Beispieldatei debug-sessions.rest zum Erstellen der Anreicherungspipeline.
Hinweis
In diesem Tutorial werden auch Azure AI Services für Spracherkennung, Entitätserkennung und Schlüsselbegriffserkennung verwendet. Aufgrund der geringen Workloadgröße wird Azure AI Services im Hintergrund für die kostenlose Verarbeitung von bis zu 20 Transaktionen genutzt. Das bedeutet, dass Sie diese Übung durchführen können, ohne eine abrechenbare Azure AI Services-Ressource erstellen zu müssen.
Die Beispieldatenbank einrichten
In diesem Abschnitt wird das Beispieldataset in Azure Blob Storage erstellt, sodass Indexer und Skillset Inhalte aufweisen, mit denen Sie arbeiten können.
Laden Sie Beispieldaten (clinical-trials-pdf-19) herunter, die aus 19 Dateien bestehen.
Erstellen Sie ein Azure Storage-Konto, oder suchen Sie nach einem vorhandenen Konto.
Wählen Sie die gleiche Region wie Azure AI Search, um Bandbreitengebühren zu vermeiden.
Es muss den Kontotyp „StorageV2 (allgemein, Version 2)“ besitzen.
Navigieren Sie im Portal zu den Seiten mit den Azure Storage-Diensten, und erstellen Sie einen Blobcontainer. Eine bewährte Methode besteht darin, die Zugriffsebene „Privat“ anzugeben. Nennen Sie den Container
clinicaltrialdataset.Klicken Sie im Container auf Hochladen, um die im ersten Schritt heruntergeladenen und entpackte Beispieldateien hochzuladen.
Kopieren Sie im Portal die Verbindungszeichenfolge für Azure Storage. Sie können die Verbindungszeichenfolge im Portal unter Einstellungen>Zugriffsschlüssel abrufen.
Kopieren eines Schlüssels und einer URL
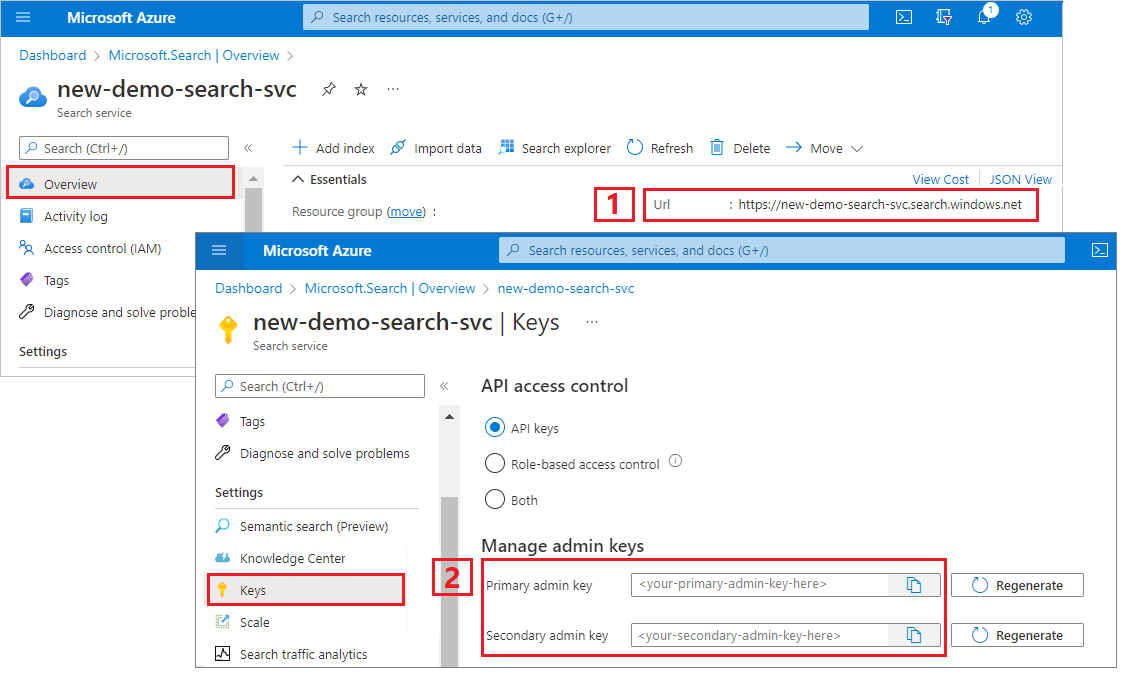
In diesem Tutorial werden API-Schlüssel für die Authentifizierung und Autorisierung verwendet. Sie benötigen den Suchdienstendpunkt und einen API-Schlüssel, den Sie über das Azure-Portal abrufen können.
Melden Sie sich im Azure-Portal an, navigieren Sie zur Seite Übersicht, und kopieren Sie die URL. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Kopieren Sie unter Einstellungen>Schlüssel einen Administratorschlüssel. Mit einem Administratorschlüssel können Sie Objekte hinzufügen, ändern und löschen. Es gibt zwei austauschbare Administratorschlüssel. Kopieren Sie einen der beiden Schlüssel.
Ein gültiger API-Schlüssel stellt anforderungsbasiert eine Vertrauensstellung her zwischen der Anwendung, die die Anforderung sendet, und dem Dienst, der sie verarbeitet.
Erstellen von Datenquellen, Skillset, Index und Indexer
Erstellen Sie in diesem Abschnitt einen Workflow mit dem Typ "Workflow", den Sie in diesem Lernprogramm beheben können.
Starten Sie Visual Studio Code, und öffnen Sie die
debug-sessions.restDatei.Stellen Sie die folgenden Variablen bereit: Suchdienst-URL, Administrator-API-Schlüssel der Suchdienste, Speicherverbindungszeichenfolge und der Name des BLOB-Containers, der die PDF-Dateien speichert.
Senden Sie jede Anforderung wiederum. Das Erstellen des Indexers dauert mehrere Minuten, bis der Vorgang abgeschlossen ist.
Schließen Sie die -Datei.
Überprüfen der Ergebnisse im Portal
Der Beispielcode erstellt als Folge der Probleme, die bei der Skillsetausführung aufgetreten sind, absichtlich einen fehlerhaften Index. Das Problem im Index sind fehlende Daten.
Wählen Sie im Azure-Portal auf der Seite Übersicht des Suchdiensts die Registerkarte Indizes aus.
Wählen Sie clinical-trials aus.
Geben Sie diese JSON-Abfragezeichenfolge in die JSON-Ansicht des Such-Explorers ein. Es werden Felder für bestimmte Dokumente (durch das eindeutige
metadata_storage_pathFeld identifiziert) zurückgegeben."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueAbfrage ausführen. Leere Werte für
organizationsundlocations.Diese Felder sollten durch den Skill „Entitätserkennung“ des Skillsets aufgefüllt worden sein, der zum Erkennen von Organisationen und Standorten überall im Blobinhalt verwendet wurde. In der nächsten Übung debuggen Sie das Skillset, um zu ermitteln, welche Fehler aufgetreten sind.
Fehler und Warnungen können auch im Azure-Portal untersucht werden.
Öffnen Sie die Registerkarte Indexer, und wählen Sie clinical-trials-idxr aus.
Beachten Sie, dass der Indexerauftrag insgesamt zwar erfolgreich ausgeführt wurde, aber Warnungen ausgegeben wurden.
Wählen Sie Erfolg aus, um die Warnungen anzuzeigen (liegen überwiegend Fehler vor, würde der Detaillink Fehler lauten). Sie sehen eine lange Liste aller vom Indexer ausgegebenen Warnungen.

Starten Sie Ihre Debugsitzung.
Wählen Sie im linken Navigationsbereich des Suchdiensts unter Suchverwaltung die Option Debugsitzungen aus.
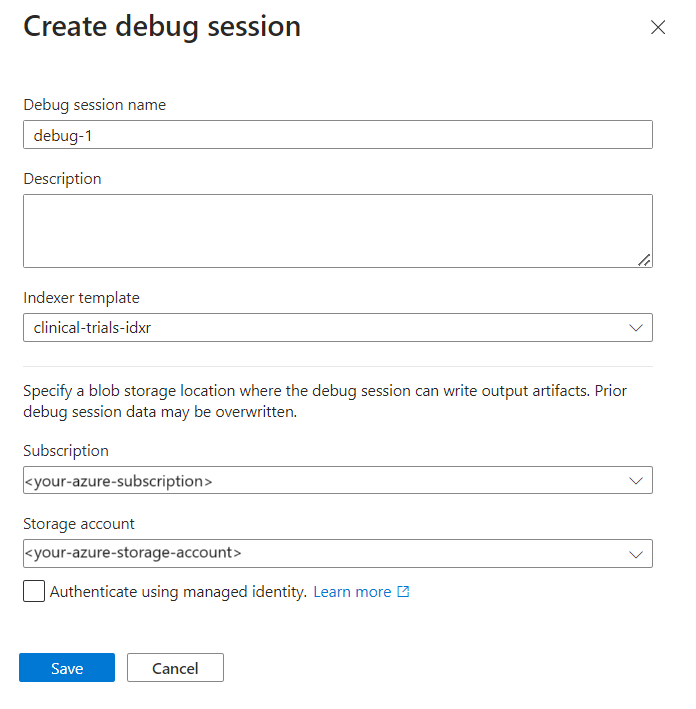
Wählen Sie + Debugsitzung hinzufügen aus.
Geben Sie der Sitzung einen Namen.
Geben Sie in der Indexervorlage den Indexernamen an. Der Indexer verweist auf die Datenquelle, das Skillset und den Index.
Wählen Sie das Speicherkonto aus.
Speichern Sie die Sitzung.
Eine Debugsitzung wird auf der Einstellungsseite geöffnet. Sie können Änderungen an der anfänglichen Konfiguration vornehmen und alle Standardwerte überschreiben. Eine Debugsitzung funktioniert nur mit einem einzelnen Dokument. Standardmäßig wird das erste Dokument in der Sammlung als Grundlage ihrer Debugsitzungen akzeptiert. Sie können ein bestimmtes Dokument zum Debuggen auswählen, indem Sie den URI in Azure Storage bereitstellen.
Wenn die Debugsitzung die Initialisierung abgeschlossen hat, sollten Sie einen Skills-Workflow mit Zuordnungen und einem Suchindex sehen. Die erweiterte Dokumentdatenstruktur wird in einem Detailbereich an der Seite angezeigt. Wir haben sie aus dem folgenden Screenshot ausgeschlossen, sodass mehr vom Workflow zu sehen ist.



Ermitteln von Problemen mit dem Skillset
Alle vom Indexer gemeldeten Probleme werden als Fehler und Warnungen angegeben.
Beachten Sie, dass die Anzahl der Fehler und Warnungen viel kleiner ist als die zuvor angezeigte, da diese Liste nur die Fehler für ein einzelnes Dokument enthält. Wie bei der Liste, die der Indexer anzeigt, können Sie auf eine Warnmeldung klicken und die Details zu dieser Warnung sehen.
Wählen Sie Warnungen aus, um die Benachrichtigungen zu überprüfen. Es sollten vier zu sehen sein:
„Could not execute skill because one or more skill inputs were invalid. Required skill input is missing. Name: 'text', Source: '/document/content'.“ (Skill konnte nicht ausgeführt werden, da mindestens eine Skilleingabe ungültig war. Eine erforderliche Skilleingabe fehlt. Name: 'text', Quelle: '/document/content'.)
„Could not map output field 'locations' to search index. Check the 'outputFieldMappings' property of your indexer. Missing value '/document/merged_content/locations'.“ (Das Ausgabefeld 'locations' konnte dem Suchindex nicht zugeordnet werden. Überprüfen Sie die Eigenschaft 'outputFieldMappings' des Indexers. Fehlender Wert für '/document/merged_content/locations'.)
„Could not map output field 'organizations' to search index. Check the 'outputFieldMappings' property of your indexer. Fehlender Wert für '/document/merged_content/organizations'.“ (Das Ausgabefeld 'organizations' konnte dem Suchindex nicht zugeordnet werden. Überprüfen Sie die Eigenschaft 'outputFieldMappings' des Indexers. Fehlender Wert für '/document/merged_content/organizations'.)
„Skill executed but may have unexpected results because one or more skill inputs were invalid. Optional skill input is missing. Name: 'languageCode', Source: '/document/languageCode'. Expression language parsing issues: Missing value '/document/languageCode'.“ (Der Skill wurde ausgeführt, hat jedoch unter Umständen unerwartete Ergebnisse, da mindestens eine Skilleingabe ungültig war. Eine optionale Skilleingabe fehlt. Name: 'languageCode', Quelle: '/document/languageCode'. Probleme bei der Analyse der Ausdruckssprache. Fehlender Wert für '/document/languageCode'.)
Viele Skills verfügen über den Parameter „languageCode“. Wenn Sie den Vorgang überprüfen, sehen Sie, dass diese Sprachcodeeingabe in EntityRecognitionSkill.#1 fehlt. Dabei handelt es sich um denselben Skill für die Entitätserkennung, bei der Probleme mit der Ausgabe von „locations“ und „organizations“ auftreten.
Da alle vier Benachrichtigungen zu diesem Skill gehören, besteht der nächste Schritt im Debuggen dieses Skills. Beginnen Sie nach Möglichkeit mit der Behebung von Eingabeproblemen, und fahren Sie dann mit Ausgabeproblemen fort.
Korrigieren fehlender Skilleingabewerte
Wählen Sie auf der Arbeitsoberfläche den Skill aus, der die Warnungen meldet. In diesem Tutorial ist es der Skill für die Entitätserkennung.
Der Detailbereich „Skill“ wird rechts geöffnet mit Abschnitten für Iterationen und deren jeweiligen Eingaben und Ausgaben, Qualifikationseinstellungen für die JSON-Definition des Skills und Nachrichten für alle Fehler und Warnungen, die dieser Skill ausgibt.
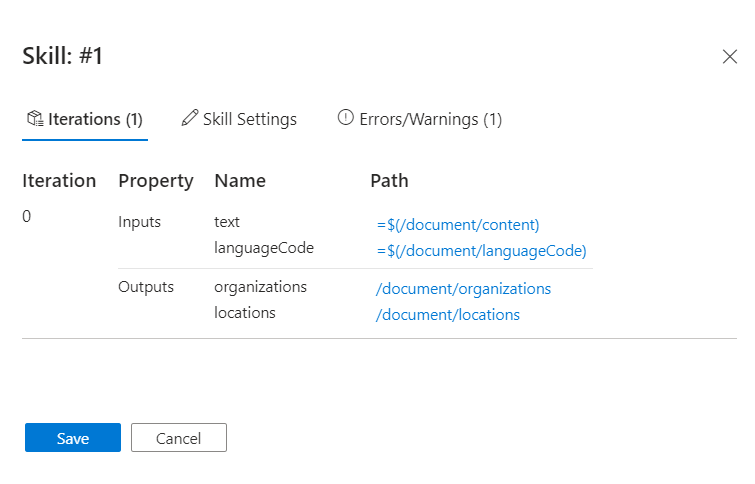
Zeigen Sie mit der Maus auf die einzelnen Eingaben (oder wählen Sie eine Eingabe aus), um die Werte in der Ausdrucksauswertung anzuzeigen. Beachten Sie, dass das angezeigte Ergebnis für diese Eingabe sieht nicht wie eine Texteingabe aus. Es sieht wie eine Reihe Zeilenvorschubzeichen
\n \n\n\n\nanstelle von Text aus. Das Fehlen von Text bedeutet, dass keine Entitäten identifiziert werden können, sodass dieses Dokument entweder die Voraussetzungen des Skills nicht erfüllt, oder stattdessen eine andere Eingabe verwendet werden sollte.
Wechseln Sie zurück zu Angereicherten Datenstruktur, und überprüfen Sie die Anreicherungsknoten für dieses Dokument. Beachten Sie, dass
\n \n\n\n\nfür „content“ keine Ursprungsquelle, aber ein anderer Wert für „merged_content“ eine OCR-Ausgabe hat. Obwohl es keinen Hinweis gibt, scheint der Inhalt dieser PDF-Datei eine JPEG-Datei zu sein, wie der extrahierte und verarbeitete Text in „merged_content“ zeigt.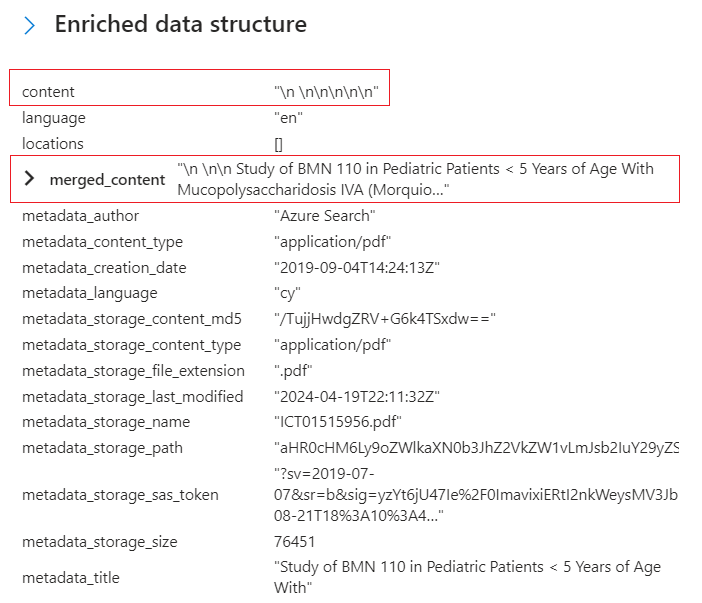
Wechseln Sie zurück zum Skill, und wählen Sie Skillset-Einstellungen aus, um die JSON-Definition zu öffnen.
Ändern Sie den Ausdruck von
/document/contentzu/document/merged_content, und wählen Sie dann Speichern aus. Beachten Sie, dass die Warnung nicht mehr aufgeführt ist.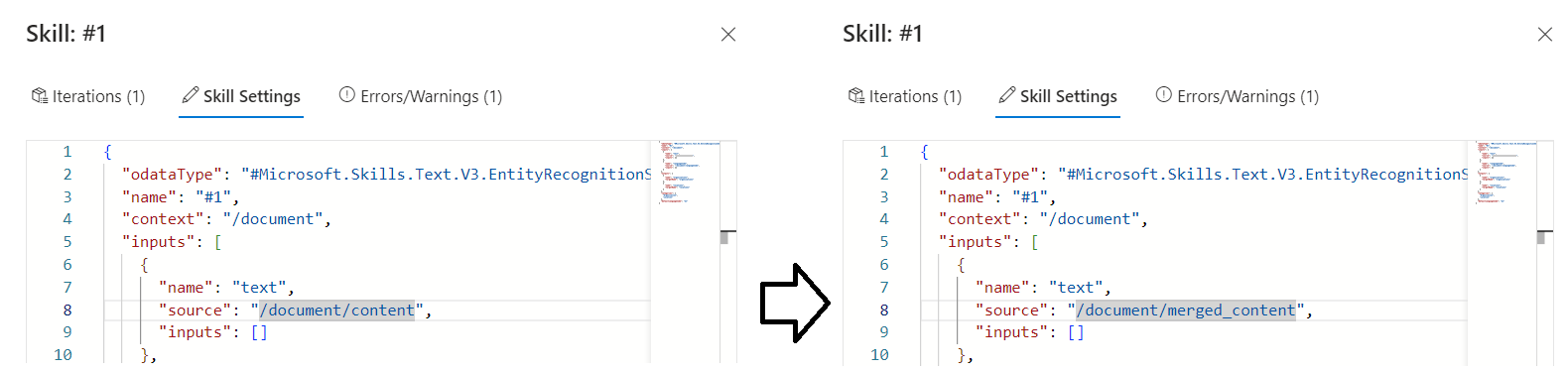
Wählen Sie im Sitzungsfenstermenü Ausführen aus. Dadurch wird eine weitere Ausführung des Skillsets unter Verwendung des Dokuments gestartet.
Beachten Sie nach Abschluss der Ausführung der Debugsitzung, dass die Anzahl der Warnungen um eine reduziert wurde. Warnungen zeigen, dass der Fehler für die Texteingabe nicht mehr vorhanden ist, die anderen Warnungen bleiben jedoch erhalten. Im nächsten Schritt wird die Warnung zum fehlenden oder leeren Wert „
/document/languageCode“ behandelt.
Wählen Sie den Skill aus, und zeigen Sie auf
/document/languageCode. Der Wert für diese Eingabe ist null. Das ist keine gültige Eingabe.Wie bei dem vorherigen Problem, beginnen Sie mit der Überprüfung der Angereicherten Datenstruktur auf Hinweise zu seinen Knoten. Beachten Sie, dass es keinen Knoten „languageCode“ gibt, aber einen für „Sprache“. Es liegt also einen Tippfehler in den Skilleinstellungen vor.
Kopieren Sie den Ausdruck
/document/language.Wählen Sie im Detailbereich „Skill“ die Option Skilleinstellungen für den Skill 1 aus, und fügen Sie den neuen Wert „
/document/language“ ein.Wählen Sie Speichern aus.
Klicken Sie auf Run (Ausführen).
Nachdem die Ausführung der Debugsitzung abgeschlossen ist, können Sie die Ergebnisse im Detailbereich „Skill“ überprüfen. Wenn Sie mit der Maus auf
/document/languagezeigen, sollteenals Wert in der Ausdrucksauswertung angezeigt werden.
Beachten Sie, dass die Eingabewarnungen nicht mehr vorhanden sind. Es verbleiben jetzt nur noch die beiden Warnungen zu Ausgabefeldern für Organisationen und Standorte.
Korrigieren fehlender Qualifikationsausgabewerte
Die Meldungen fordern zur Überprüfung der Eigenschaft „outputFieldMappings“ Ihres Indexers auf, also beginnen wir dort.
Wählen Sie Ausgabefeldzuordnungen auf der Arbeitsoberfläche aus. Beachten Sie, dass die Ausgabefeldzuordnungen fehlen.
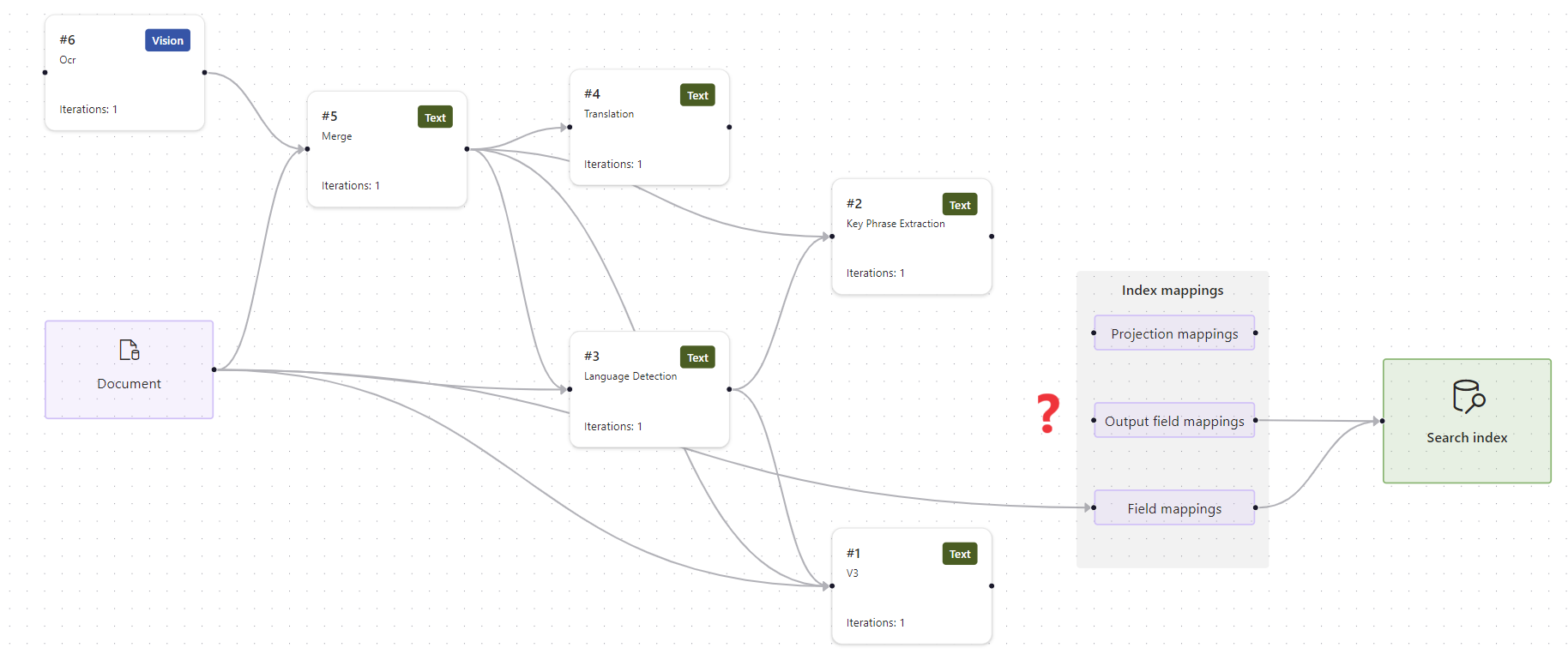
Vergewissern Sie sich im ersten Schritt, dass der Suchindex über die erwarteten Felder verfügt. In diesem Fall enthält der Index Felder für „Standorte“ und „Organisationen“.
Wenn kein Problem mit dem Index vorliegt, ist der nächste Schritt das Überprüfen der Skillausgabe. Wählen Sie wie zuvor die Angereicherte Datenstruktur aus, und scrollen Sie durch die Knoten, um „locations“ und „organizations“ zu finden. Beachten Sie, dass das übergeordnete Element „content“ anstelle von „merged_content“ ist. Der Kontext ist falsch.
Wechseln Sie zurück zum Detailbereich „Skill“, und wählen Sie den Skill für die Entitätserkennung aus.
Ändern Sie in Skilleinstellungen
contextzudocument/merged_content. An diesem Punkt sollte die Skilldefinition insgesamt drei Änderungen aufweisen.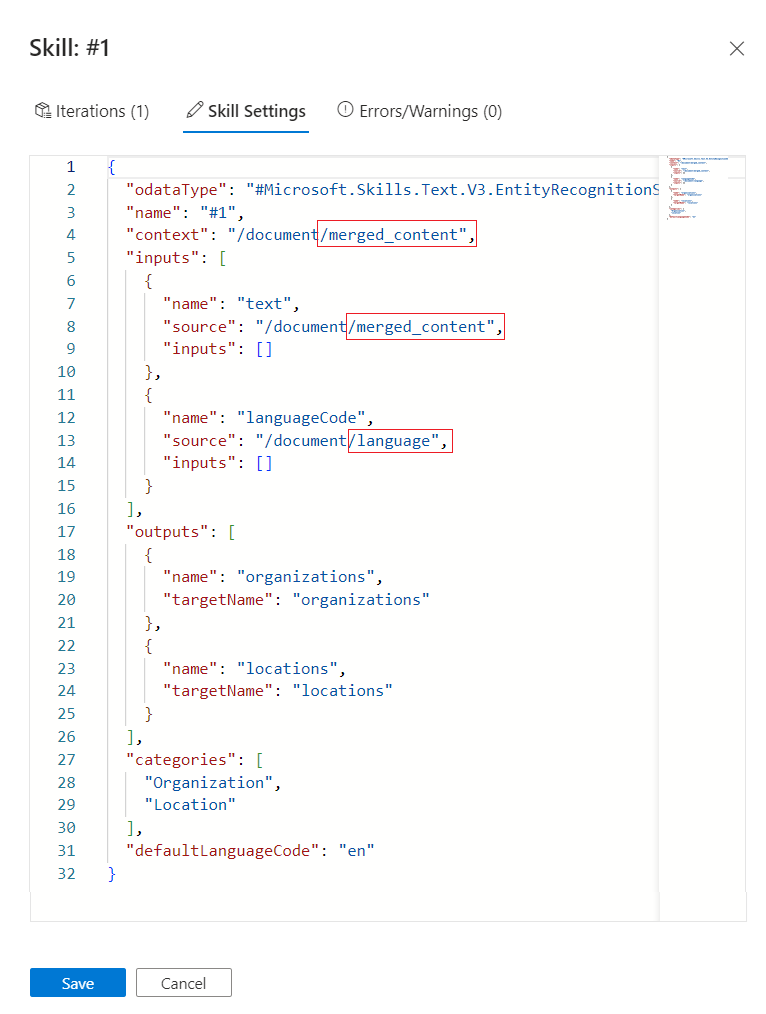
Wählen Sie Speichern aus.
Klicken Sie auf Run (Ausführen).
Alle Fehler wurden behoben.
Änderungen am Skillset committen
Beim Initiieren der Debugsitzung wurde vom Suchdienst eine Kopie des Skillsets erstellt. Dieser Schritt wurde ausgeführt, um das ursprüngliche Skillset für Ihren Suchdienst zu schützen. Nachdem Sie das Debugging Ihres Skillsets nun abgeschlossen haben, können Sie die Korrekturen committen (und das ursprüngliche Skillset überschreiben).
Wenn Sie die Änderungen noch nicht committen möchten, können Sie alternativ die Debugsitzung speichern und später erneut öffnen.
Wählen Sie im Hauptmenü der Debugsitzungen Änderungen committen aus.
Wählen Sie OK aus, um zu bestätigen, dass Sie Ihr Skillset aktualisieren möchten.
Schließen Sie die Debugsitzung, und öffnen Sie Indexer im linken Navigationsbereich.
Wählen Sie „clinical-trials-idxr“ aus.
Klicken Sie auf Zurücksetzen.
Klicken Sie auf Run (Ausführen).
Wählen Sie Aktualisieren aus, um den Status der Befehle zum Zurücksetzen und Ausführen anzuzeigen.
Wenn die Ausführung des Indexers beendet ist, sollte auf der Registerkarte Ausführungshistorie ein grünes Häkchen und das Wort „Erfolg“ neben dem Zeitstempel der letzten Ausführung angezeigt werden. So stellen Sie sicher, dass die Änderungen übernommen wurden:
Öffnen Sie im linken Navigationsbereich Indizes.
Wählen Sie den Index „clinical-trials“ aus, und geben Sie auf der Registerkarte „Suchexplorer“ die Abfragezeichenfolge
$select=metadata_storage_path, organizations, locations&$count=trueein, um Felder für bestimmte Dokumente (identifiziert durch das eindeutige Feldmetadata_storage_path) zurückzugeben.Klicken Sie auf Suchen.
In den Ergebnissen sollten Sie nun erkennen, dass Organisationen und Standorte mit den erwarteten Werten aufgefüllt wurden.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, sollten Sie sich am Ende eines Projekts überlegen, ob Sie die erstellten Ressourcen noch benötigen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können entweder einzelne Ressourcen oder aber die Ressourcengruppe löschen, um den gesamten Ressourcensatz zu entfernen.
Ressourcen können im Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich gesucht und verwaltet werden.
Ein kostenloser Dienst ist auf drei Indizes, Indexer und Datenquellen beschränkt. Sie können einzelne Elemente über das Portal löschen, um unter dem Limit zu bleiben.
Nächste Schritte
In diesem Tutorial wurden verschiedene Aspekte der Definition und Verarbeitung von Skillsets angesprochen. Weitere Informationen zu Konzepten und Workflows finden Sie in den folgenden Artikeln: