REST-Lernprogramm: Verwenden von Skillsets zum Generieren durchsuchbarer Inhalte in Azure AI Search
In diesem Lernprogramm erfahren Sie, wie Sie REST-APIs aufrufen, die eine KI-Anreicherungspipeline für inhaltsextraktion und Transformationen während der Indizierung erstellen.
Skillsets fügen KI-Verarbeitung zu Rohinhalten hinzu, wodurch diese Inhalte einheitlicher und durchsuchbarer werden. Sobald Sie wissen, wie Skillsets funktionieren, können Sie eine breite Palette von Transformationen unterstützen: von der Bildanalyse bis hin zur Verarbeitung natürlicher Sprachen bis hin zur angepassten Verarbeitung, die Sie extern bereitstellen.
In diesem Tutorial erfahren Sie Folgendes:
- Definieren von Objekten in einer Anreicherungspipeline
- Erstellen eines Skillsets Aufrufen von OCR, Spracherkennung, Entitätserkennung und Schlüsselbegriffserkennung
- Ausführen der Pipeline Erstellen und Laden eines Suchindex
- Überprüfen der Ergebnisse mithilfe der Volltextsuche
Sollten Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Übersicht
Dieses Tutorial verwendet einen REST-Client und die Azure AI Search REST APIs, um eine Datenquelle, einen Index, einen Indexer und ein Skillset zu erstellen.
Der Indexer steuert jeden Schritt in der Pipeline, beginnend mit der Inhaltsextraktion von Beispieldaten (unstrukturiertem Text und Bildern) in einem BLOB-Container in Azure Storage.
Sobald Inhalte extrahiert wurden, führt das Skillset integrierte Fähigkeiten von Microsoft aus, um Informationen zu finden und zu extrahieren. Die Schritte in der Pipeline umfassen die optische Zeichenerkennung (OCR) für Bilder, die Spracherkennung für Text sowie die Schlüsselwortextraktion und die Entitätserkennung (Organisationen). Neue Informationen, die vom Skillset erstellt wurden, werden an Felder in einem Indexgesendet. Nachdem der Index aufgefüllt wurde, können die Felder in Abfragen, Facetten und Filtern verwendet werden.
Voraussetzungen
Hinweis
Sie können einen kostenlosen Suchdienst für dieses Tutorial verwenden. Der Free-Tarif ist auf drei Indizes, drei Indexer und drei Datenquellen beschränkt. In diesem Tutorial wird davon jeweils eine Instanz erstellt. Vergewissern Sie sich zunächst, dass Ihr Dienst über genügend freie Kapazität für die neuen Ressourcen verfügt.
Herunterladen von Dateien
Laden Sie eine ZIP-Datei des Beispiel-Repositorys herunter und extrahieren Sie den Inhalt. Weitere Informationen.
Hochladen von Beispieldaten in Azure Storage
Erstellen Sie in Azure Storage einen neuen Container, und nennen Sie ihn kog-search-demo.
Rufen Sie eine Speicherverbindungszeichenfolge ab, damit Sie eine Verbindung in Azure KI Search formulieren können.
Wählen Sie auf der linken Seite Zugriffsrichtlinien aus.
Kopieren Sie die Verbindungszeichenfolge für schlüssel 1 oder zwei Schlüssel. Die Verbindungszeichenfolge ist eine URL, die in etwa wie folgt aussieht:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure KI Services
Die integrierte KI-Anreicherung nutzt Azure KI Services, darunter den Sprachdienst und Azure KI Vision für die linguistische Datenverarbeitung und die Verarbeitung von Bildern. Für kleine Workloads wie dieses Lernprogramm können Sie die kostenlose Zuordnung von zwanzig Transaktionen pro Indexer verwenden. Fügen Sie für größere Arbeitslasten eine Azure AI Services-Ressource mit mehreren Regionen an ein Skillset für Die Preise für Pay-as-you-go an.
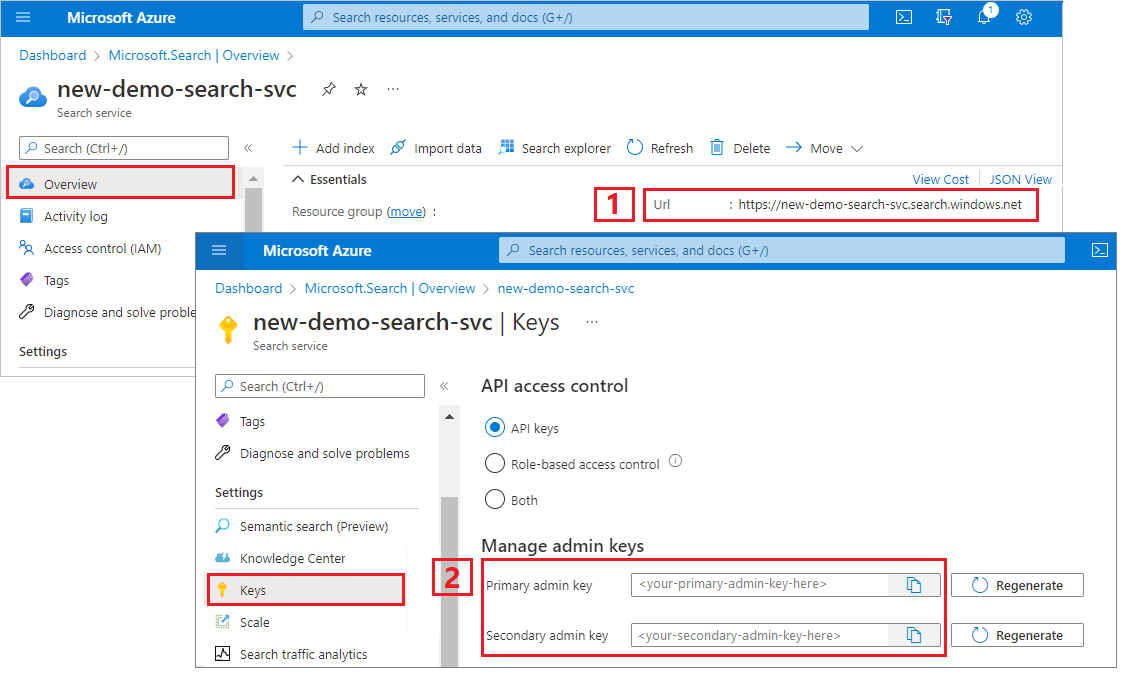
Kopieren von Suchdienst-URL und API-Schlüssel
Für dieses Tutorial benötigen Verbindungen mit Azure KI Search einen Endpunkt und einen API-Schlüssel. Diese Werte erhalten Sie im Azure-Portal.
Melden Sie sich beim Azure-Portalan, navigieren Sie zur Seite Übersicht des Suchdiensts, und kopieren Sie die URL. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Kopieren Sie unter Einstellungen>Schlüssel einen Administratorschlüssel. Mit einem Administratorschlüssel können Sie Objekte hinzufügen, ändern und löschen. Es gibt zwei austauschbare Administratorschlüssel. Kopieren Sie einen der beiden Schlüssel.
Einrichten der REST-Datei
Starten Sie Visual Studio Code, und öffnen Sie die Datei "skillset-tutorial.rest ". Siehe Schnellstart: Textsuche mithilfe von REST , wenn Sie Hilfe beim REST-Client benötigen.
Stellen Sie Werte für die Variablen bereit: Suchdienstendpunkt, Suchdienstadministrator-API-Schlüssel, Indexname, Verbindungszeichenfolge mit Ihrem Azure Storage-Konto und der Blobcontainername.
Erstellen der Pipeline
KI-Anreicherung ist indexgesteuert. In diesem Teil der exemplarischen Vorgehensweise werden vier Objekte erstellt: Datenquelle, Indexdefinition, Skillset und Indexer.
Schritt 1: Erstellen einer Datenquelle
Rufen Sie Datenquelle erstellen auf, um die Verbindungszeichenfolge auf den Blobcontainer festzulegen, der die Beispieldatendateien enthält.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Schritt 2: Erstellen eines Skillsets
Rufen Sie Skillset erstellen auf, um anzugeben, welche Anreicherungsschritte auf Ihren Inhalt angewendet werden. Skills werden parallel ausgeführt, sofern es keine Abhängigkeit gibt.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Die wichtigsten Punkte:
Der Anforderungstext gibt die folgenden integrierten Qualifikationen an:
Skill BESCHREIBUNG Optische Zeichenerkennung Erkennt Text und Zahlen in Bilddateien. Textzusammenführung Erstellt „zusammengeführten Inhalt“, der zuvor getrennte Inhalte neu kombiniert, nützlich für Dokumente mit eingebetteten Bildern (PDF, DOCX usw.). Bilder und Text werden während der Dokumententschlüsselungsphase getrennt. Der Zusammenführungs-Skill führt eine Neukombinierung durch, indem alle erkannten Texte, Bildbeschriftungen oder Tags, die während der Anreicherung erstellt wurden, an derselben Stelle eingefügt werden, an der das Bild aus dem Dokument extrahiert wurde. Wenn Sie mit zusammengeführten Inhalten in einem Skillset arbeiten, enthält dieser Knoten den gesamten Text im Dokument, einschließlich nur textbasierter Dokumente, die niemals OCR- oder Bildanalysen unterzogen werden. Sprachenerkennung Erkennt die Sprache und gibt entweder einen Sprachnamen oder Code aus. In mehrsprachigen Datasets kann ein Sprachfeld für Filter nützlich sein. Entitätserkennung Extrahiert die Namen von Personen, Organisationen und Orten aus zusammengeführten Inhalten. Textaufteilung Unterteilt große zusammengeführte Inhalte vor dem Aufrufen der Schlüsselbegriffserkennung in kleinere Blöcke. Die Schlüsselbegriffserkennung akzeptiert Eingaben von 50.000 Zeichen oder weniger. Für einige der Beispieldateien ist eine Aufteilung erforderlich, um diesen Grenzwert zu erfüllen. Schlüsselbegriffserkennung Extrahiert die wichtigsten Schlüsselbegriffe. Jede Qualifikation wird auf den Inhalten des Dokuments ausgeführt. Während der Verarbeitung knackt Azure AI Search jedes Dokument, um Inhalte aus verschiedenen Dateiformaten zu lesen. Gefundener Text, der aus der Quelldatei stammt, wird in einem generierten Feld
contentgespeichert, einem für jedes Dokument. Die Eingabe wird somit zu"/document/content".Da wir hier die Qualifikation „Text unterteilen“ verwenden, um größere Dateien in Seiten zu unterteilen, lautet der Kontext bei der Schlüsselbegriffserkennung nicht
"/document/content", sondern"document/pages/*"(für jede Seite im Dokument).
Hinweis
Ausgaben können einem Index zugeordnet, als Eingabe einer Downstream-Qualifikation verwendet oder in beider Weise zugleich eingesetzt werden, wie etwa bei Sprachcode. Im Index ist ein Sprachcode zu Filterungszwecken nützlich. Weitere Informationen zu den Grundlagen von Qualifikationsgruppen finden Sie unter How to define a skillset (Definieren von Qualifikationsgruppen).
Schritt 3: Erstellen eines Index
Rufen Sie Index erstellen auf, um das Schema bereitzustellen, das zum Erstellen von invertierten Indizes und anderen Konstrukten in Azure AI Search verwendet wird.
Die größte Komponente eines Indexes ist die Feldsammlung, in der Datentyp und Attribute Inhalt und Verhalten in Azure AI Search bestimmen. Stellen Sie sicher, dass Sie über Felder für die neu generierte Ausgabe verfügen.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Schritt 4: Erstellen und Ausführen eines Indexers
Rufen Sie Indexer erstellen auf, um die Pipeline zu steuern. Die drei bereits erstellten Komponenten (Datenquelle, Skillset und Index) sind Eingaben für einen Indexer. Die Erstellung des Indexers auf Azure AI Search ist das Ereignis, das die gesamte Pipeline in Gang setzt.
Sie sollten damit rechnen, dass die Ausführung dieses Schritts mehrere Minuten in Anspruch nimmt. Das Dataset ist zwar klein, Analysequalifikationen sind aber rechenintensiv.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Die wichtigsten Punkte:
Der Anforderungsteil enthält Verweise auf die vorherigen Objekte, Konfigurationseigenschaften, die für die Bildverarbeitung erforderlich sind, und zwei Typen von Feldzuordnungen.
"fieldMappings"werden vor dem Skillset verarbeitet und senden Inhalte aus der Datenquelle an Zielfelder in einem Index. Feldzuordnungen werden verwendet, um bereits vorhandene, unveränderte Inhalte an den Index zu senden. Wenn die Feldnamen und -typen auf beiden Seiten gleich sind, ist keine Zuordnung erforderlich."outputFieldMappings"sind für Felder, die nach der Ausführung des Skillsets von Qualifikationen erstellt wurden. Die Verweise aufsourceFieldNameinoutputFieldMappingsmüssen erst durch die Dokumententschlüsselung oder Anreicherung erstellt werden. BeitargetFieldNamehandelt es sich um ein im Indexschema definiertes Feld in einem Index.Der Parameter
"maxFailedItems"ist auf -1 gesetzt, wodurch die Indizierungsmaschine angewiesen wird, Fehler beim Datenimport zu ignorieren. Dies ist akzeptabel, da die Demodatenquelle nur einige wenige Dokumente enthält. Für eine größere Datenquelle sollten Sie den Wert größer als 0 festlegen.Die
"dataToExtract":"contentAndMetadata"-Anweisung weist den Indexer an, die Werte automatisch aus der Inhaltseigenschaft des Blobs und den Metadaten der einzelnen Objekte zu extrahieren.Der
imageActionParameter weist den Indexer an, Text aus Bildern zu extrahieren, die in der Datenquelle enthalten sind. Die Konfiguration"imageAction":"generateNormalizedImages"in Kombination mit der OCR- und der Textzusammenführungsqualifikation weist den Indexer an, Text aus den Bildern zu extrahieren (beispielsweise das Wort „Stop“ aus einem Stoppschild) und ihn als Teil des Inhaltsfelds einzubetten. Dieses Verhalten gilt sowohl für eingebettete Bilder (z. B. ein Bild in einer PDF-Datei) als auch für eigenständige Bilddateien, z. B. eine JPG-Datei.
Hinweis
Die Pipeline wird durch Erstellen eines Indexers aufgerufen. Wenn beim Zugriff auf die Daten, dem Zuordnen von Ein- und Ausgaben oder der Reihenfolge der Vorgänge Probleme bestehen, äußern sie sich in dieser Phase. Um die Pipeline mit Code- oder Skriptänderungen auszuführen, müssen Sie möglicherweise zuerst Objekte löschen. Weitere Informationen finden Sie unter Reset and re-run (Zurücksetzen und erneut Ausführen).
Überwachen der Indizierung
Indizierung und Anreicherung beginnen, sobald Sie die Anforderung für die Indexererstellung übermitteln. Je nach Komplexität und Vorgängen kann die Indizierung eine Weile dauern.
Um herauszufinden, ob der Indexer noch ausgeführt wird, rufen Sie Indexer-Status abrufen auf, um den Indexerstatus zu überprüfen.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Die wichtigsten Punkte:
Warnungen sind in einigen Szenarien üblich und deuten nicht immer auf ein Problem hin. Wenn ein Blob-Container beispielsweise Bilddateien enthält und die Pipeline keine Bilder verarbeitet, erhalten Sie eine Warnung, die besagt, dass die Bilder nicht verarbeitet wurden.
In diesem Beispiel gibt es eine PNG-Datei, die keinen Text enthält. Alle fünf textbasierten Qualifikationen (Spracherkennung, Entitätserkennung von Standorten, Organisationen, Personen und Schlüsselbegriffserkennung) können in dieser Datei nicht ausgeführt werden. Die resultierende Benachrichtigung wird im Ausführungsverlauf angezeigt.
Überprüfen der Ergebnisse
Nachdem Sie nun einen Index erstellt haben, der von KI generierte Inhalte enthält, rufen Sie Dokumente durchsuchen auf, um die Ergebnisse anzuzeigen.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Mithilfe von Filtern können Sie Ergebnisse auf interessante Elemente einschränken:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Diese Abfragen veranschaulichen einige der Möglichkeiten, wie Sie mit Abfragesyntax und Filtern für neue Felder arbeiten können, die von Azure AI Search erstellt wurden. Weitere Abfragebeispiele finden Sie unter Beispiele im Artikel „Durchsuchen von Dokumenten (Azure Cognitive Search-REST-API)“, unter Erstellen einer einfachen Abfrage in Azure Search sowie unter Verwenden der „vollständigen“ Lucene-Suchsyntax (erweiterte Abfragen in der kognitiven Azure-Suche).
Zurücksetzen und erneut ausführen
In frühen Phasen der Entwicklung kommt es häufig zu Iterationen des Entwurfs. Das Zurücksetzen und erneute Ausführen hilft bei der Iteration.
Wesentliche Punkte
In diesem Lernprogramm werden die grundlegenden Schritte zum Verwenden der REST-APIs zum Erstellen einer KI-Anreicherungspipeline veranschaulicht: eine Datenquelle, ein Skillset, ein Index und ein Indexer.
Es wurden integrierte Qualifikationen im Zusammenhang mit der Skillsetdefinition und den Mechanismen zur Verkettung von Qualifikationen mithilfe von Ein- und Ausgängen vorgestellt. Sie haben auch gelernt, dass outputFieldMappings in der Indexer-Definition erforderlich ist, um angereicherte Werte aus der Pipeline in einen durchsuchbaren Index auf einem Azure AI Search-Dienst zu leiten.
Ferner haben Sie erfahren, wie die Ergebnisse getestet werden und das System für weitere Entwicklungsschritte zurückgesetzt wird. Sie haben gelernt, dass das Ausgeben von Abfragen auf den Index die von der angereicherten Indizierungspipeline erstellte Ausgabe zurückgibt.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können entweder einzelne Ressourcen oder aber die Ressourcengruppe löschen, um den gesamten Ressourcensatz zu entfernen.
Ressourcen können im Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich gesucht und verwaltet werden.
Nächste Schritte
Nachdem Sie sich nun mit allen Objekten einer KI-Anreicherungspipeline vertraut gemacht haben, können Sie sich weiter über Skillsetdefinitionen und einzelne Qualifikationen informieren.