Hinzufügen zusätzlicher sekundärer Standorte zu einem HANA Pacemaker-Cluster
In diesem Artikel werden die Anforderungen und die Einrichtung eines zusätzlichen HANA-Replikationsstandorts zur Ergänzung eines vorhandenen Pacemaker-Clusters beschrieben. Es werden auch Besonderheiten von SUSE Linux Enterprise Server (SLES) und Red Hat Enterprise Linux (RHEL) behandelt.
Übersicht
SAP HANA unterstützt die Systemreplikation (HSR) mit mehr als zwei verbundenen Standorten. Sie können zusätzliche Standorte für ein vorhandenes HSR-Paar konfigurieren, das Pacemaker in einem Setup mit Hochverfügbarkeit verwaltet. Sie können diese zusätzlichen Standorte beispielsweise in einer zweiten Azure-Region für die Notfallwiederherstellung (DR) bereitstellen.
Pacemaker und der HANA-Clusterressourcen-Agent verwalten nur die ersten beiden Standorte in HSR. Die zusätzlichen Standorte werden nicht vom Pacemaker-Cluster gesteuert.
SAP HANA unterstützt die Systemreplikation an zusätzliche sekundäre Standorte in zwei Modi:
- Mehrere Ziele: Datenänderungen werden vom primären auf mehrere Zielsysteme repliziert. Die zusätzlichen Standorte werden mit dem primären Replikat in einer Sterntopologie verbunden.
- Mehrschichtig ist eine kaskadierende oder verkettete Einrichtung der HANA-Systemreplikation. Der dritte Standort stellt eine Verbindung mit der sekundären Ebene bereit.
Weitere konzeptionelle Details zu HANA HSR in einer und in mehreren Regionen finden Sie unter SAP HANA-Verfügbarkeit in verschiedenen Azure-Regionen.
Voraussetzungen für SLES
Die Anforderungen an einen zusätzlichen HSR-Standort unterscheiden sich bei der Hochskalierung und der horizontalen Skalierung für HANA.
Hinweis
- Die Anforderungen in diesem Artikel gelten nur für eine Pacemaker-fähige Umgebung. Ohne Pacemaker gelten die SAP HANA-Versionsanforderungen für den gewählten Replikationsmodus.
- Pacemaker und der HANA-Clusterressourcen-Agent verwalten nur zwei Standorte. Der zusätzliche HSR-Standort wird nicht vom Pacemaker-Cluster gesteuert.
- SUSE unterstützt maximal einen zusätzlichen Systemreplikationsstandort in einer SAP HANA-Datenbank außerhalb des Pacemaker-Clusters.
- Sowohl Hochskalierung als auch horizontale Skalierung: SAP HANA SPS 04 oder höher ist erforderlich, um HSR mit mehreren Zielen mit einem Pacemaker-Cluster zu verwenden.
- Sowohl Hochskalierung als auch horizontale Skalierung: Es ist maximal eine SAP HANA-Systemreplikation zulässig, die von außerhalb des Linux-Clusters verbunden ist.
- Nur horizontale HANA-Skalierung: SLES 15 SP1 oder höher.
- Nur horizontale HANA-Skalierung: Betriebssystempaket „SAPHanaSR-ScaleOut“ Version 0.180 oder höher.
- Nur horizontale HANA-Skalierung: Verwendung des SAP HANA-Hochverfügbarkeitshooks SAPHanaSrMultiTarget. Der HANA-Hochverfügbarkeitshook
SAPHanaSRin der Vorschauversion kann nicht mehrere Ziele für die Skalierung nutzen.
Voraussetzungen für RHEL
Die Anforderungen an einen zusätzlichen HSR-Standort unterscheiden sich bei der Hochskalierung und der horizontalen Skalierung für HANA.
Hinweis
- Die Anforderungen in diesem Artikel gelten nur für eine Pacemaker-fähige Umgebung. Ohne Pacemaker gelten die SAP HANA-Versionsanforderungen für den gewählten Replikationsmodus.
- Pacemaker und der HANA-Clusterressourcen-Agent verwalten nur zwei Standorte. Die zusätzlichen HSR-Standorte werden nicht vom Pacemaker-Cluster gesteuert.
- Red Hat unterstützt einen oder mehr zusätzliche Systemreplikationsstandorte für eine SAP HANA-Datenbank außerhalb des Pacemaker-Clusters.
- Nur HANA-Hochskalierung: Weitere Informationen zur Mindestversion von Betriebssystem, SAP HANA und Clusterressourcen-Agents finden Sie in den Red Hat-Supportrichtlinien für RHEL-Hochverfügbarkeitscluster.
- Nur horizontale HANA-Skalierung: Eine HANA-Replikation mit mehreren Zielen wird in Azure mit einem Pacemaker-Cluster nicht unterstützt.
Tipp
Die Konfiguration veranschaulicht, wie Sie einen dritten Standort außerhalb des Pacemaker-Clusters einrichten. Wenn Sie unter RHEL mehr als einen zusätzlichen Standort außerhalb des Pacemaker-Clusters verwenden, müssen Sie das Setup auch auf diese anderen Standorte erweitern.
HANA-Hochskalierung: Hinzufügen der HANA-Systemreplikation mit mehreren Zielen für Notfallwiederherstellungszwecke
Mit den SAP HANA-Hochverfügbarkeitshooks SAPHanaSR/susHanaSR für SLES und RHEL können Sie zusätzliche Standorte für die HANA-Systemreplikation hinzufügen. In einer Pacemaker-Umgebung ist ein HANA-Setup mit mehreren Zielen möglich.
Ausfälle von zusätzlichen Standorten lösen keine Clusteraktion aus. Der Cluster erkennt den Replikationsstatus von verbundenen Standorten, und das überwachte Attribut für den dritten Standort kann zwischen den Zuständen SOK und SFAIL wechseln. Bei Übernahmetests am zusätzlichen Standort oder beim Ausführen von Übungsprozessen für die Notfallwiederherstellung sollten Sie zuerst die Clusterressourcen in den Wartungsmodus versetzen, um unerwünschte Clusteraktionen zu vermeiden.
Das folgende Beispiel zeigt ein Systemreplikationssystem mit mehreren Zielen. Weitere Informationen finden Sie in der SAP-Dokumentation.
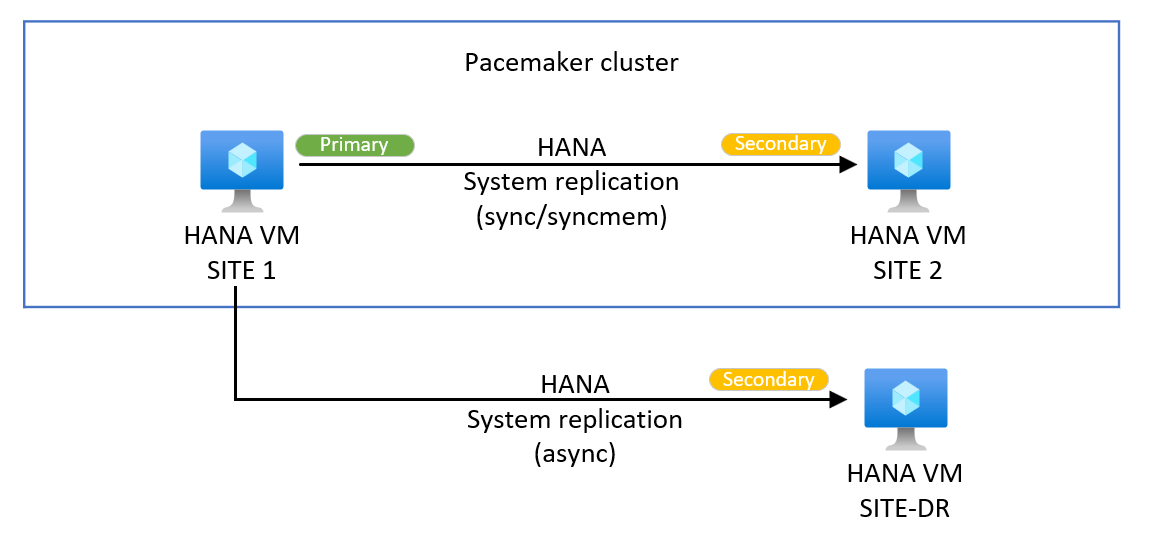
Stellen Sie Azure-Ressourcen für den dritten Knoten bereit. Je nach Ihren Anforderungen können Sie für die Notfallwiederherstellung eine andere Azure-Region auswählen.
Die Schritte für den dritten Standort ähneln denen für VMs (virtuelle Computer) für HANA-Hochskalierungscluster. Der dritte Standort verwendet die Azure-Infrastruktur. Die Betriebssystem- und HANA-Versionen entsprechen denen im vorhandenen Pacemaker-Cluster mit den folgenden Ausnahmen:
- Am dritten Standort wird kein Lastenausgleich bereitgestellt. Es erfolgt keine Integration in den Lastenausgleich im vorhandenen Cluster für die VM am dritten Standort.
- Installieren Sie nicht die Betriebssystempakete „SAPHanaSR“ und „SAPHanaSR-doc“ sowie das Betriebssystempaketmuster „ha_sles“ auf der VM am dritten Standort.
- Es erfolgt keine Integration in den Cluster für VM- oder HANA-Ressourcen am dritten Standort.
- Es erfolgt kein Setup für den HANA-Hochverfügbarkeitshook am dritten Standort in global.ini.
Installieren Sie SAP HANA auf dem dritten Knoten.
Sie müssen am dritten Standort dieselbe HANA-SID und HANA-Installationsnummer verwenden.
Wenn SAP HANA am dritten Standort installiert ist und ausgeführt wird, registrieren Sie den dritten Standort beim primären Standort.
Im folgenden Beispiel wird
SITE-DRals Name für den dritten Standort verwendet.# Execute on the third site su - hn1adm # Register the HANA third site to the primary. Switch --online will shutdown the HANA instance on third site. hdbnsutil -sr_register --name=SITE-DR --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=async --onlineÜberprüfen Sie, ob bei der HANA-Systemreplikation der sekundäre und der dritte Standort anzeigt werden.
# Verify HANA HSR is in sync, execute on primary sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Überprüfen Sie das
SAPHanaSR-Attribut für den dritten Standort. FürSITE-DRsollte im AbschnittSitesder StatusSOKangezeigt werden.# Check SAPHanaSR attribute on any cluster managed host (first or second site) sudo SAPHanaSR-showAttr # Example result # Global cib-time maintenance # -------------------------------------------- # global Tue Feb 21 19:28:21 2023 false # # Sites srHook # ----------------- # HN1-SITE1 PRIM # HN1-SITE2 SOK # SITE-DR SOKDer Cluster erkennt den Replikationsstatus verbundener Standorte. Die überwachten Attribute können zwischen
SOKundSFAILwechseln. Es erfolgt keine Clusteraktion, wenn bei der Replikation am Notfallwiederherstellungsstandort ein Fehler auftritt.
Horizontale HANA-Skalierung: Hinzufügen der HANA-Systemreplikation mit mehreren Zielen für Notfallwiederherstellungszwecke
Beim SAP HANA-Hochverfügbarkeitsanbieter SAPHanaSrMultiTarget können Sie einen dritten HANA-Standort für die horizontale Skalierung hinzufügen. Dieser dritte Standort wird häufig für die Notfallwiederherstellung in einer anderen Azure-Region verwendet. In einer Pacemaker-Umgebung ist ein HANA-Setup mit mehreren Zielen für die Notfallwiederherstellung bekannt. Dieser Abschnitt gilt nur für Systeme, auf denen Pacemaker unter SUSE ausgeführt wird. Ausführliche Informationen finden Sie im Abschnitt „Voraussetzungen“ in diesem Dokument.
Ausfälle am dritten Knoten lösen keine Clusteraktion aus. Der Cluster erkennt den Replikationsstatus von verbundenen Standorten, und das überwachte Attribut für den dritten Standort kann zwischen den Zuständen SOK und SFAIL wechseln. Bei Übernahmetests am dritten/Notfallwiederherstellungsstandort oder beim Ausführen von Übungsprozessen für die Notfallwiederherstellung sollten Sie zuerst die Clusterressourcen in den Wartungsmodus versetzen, um unerwünschte Clusteraktionen zu vermeiden.
Das folgende Beispiel zeigt ein Systemreplikationssystem mit mehreren Zielen. Weitere Informationen finden Sie in der SAP-Dokumentation.
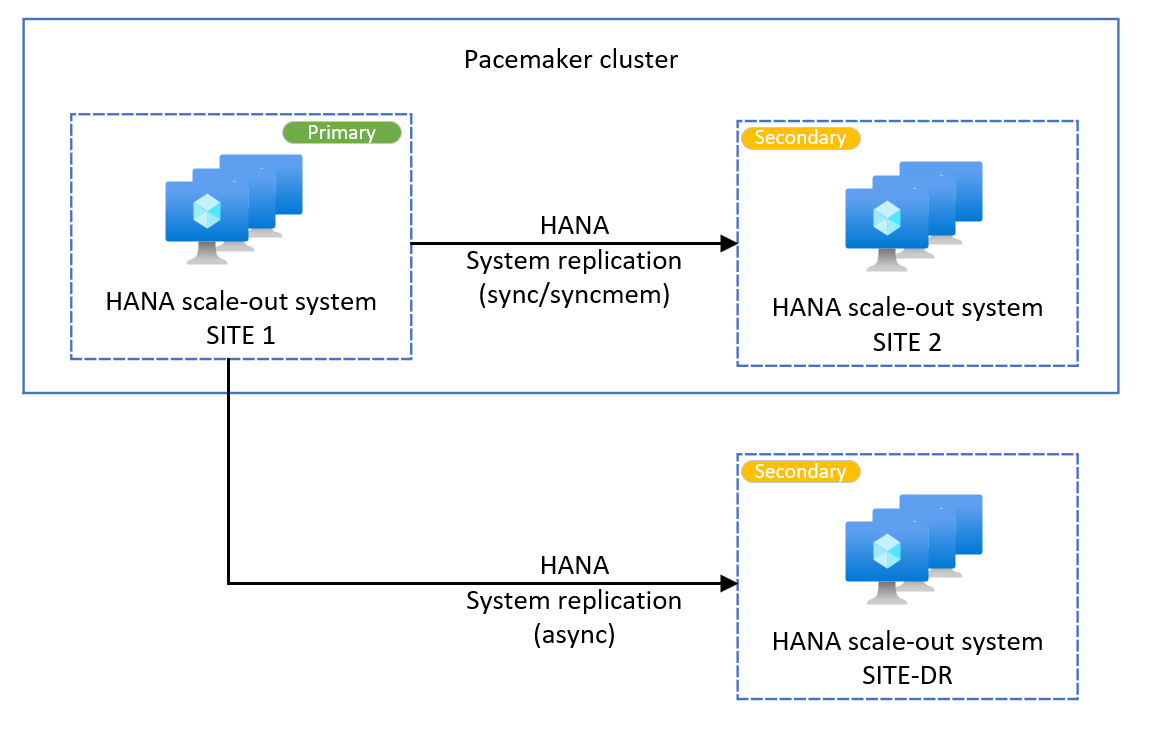
Stellen Sie Azure-Ressourcen für den dritten Standort bereit. Je nach Ihren Anforderungen können Sie für die Notfallwiederherstellung eine andere Azure-Region auswählen.
Die Schritte für die horizontale HANA-Skalierung am dritten Standort gleichen denen für das Bereitstellen des HANA-Clusters mit horizontaler Skalierung. Am dritten Standort werden dieselben Schritte wie für den
SITE1des Clusters mit horizontaler Skalierung in Bezug auf Azure-Infrastruktur, Betriebssystems und HANA-Installation angewandt, jedoch mit den folgenden Ausnahmen:- Am dritten Standort wird kein Lastenausgleich bereitgestellt. Es erfolgt keine Integration in den Lastenausgleich im vorhandenen Cluster für die VMs am dritten Standort.
- Installieren Sie nicht die Betriebssystempakete „SAPHanaSR-ScaleOut“ und „SAPHanaSR-ScaleOut-doc“ sowie das Betriebssystempaketmuster „ha_sles“ auf den VMs am dritten Standort.
- Es gibt keine Majority Maker-VM am dritten Standort, da keine Clusterintegration erfolgt.
- Erstellen Sie das NFS-Volume „/hana/shared“ für die exklusive Nutzung am dritten Standort.
- Es erfolgt keine Integration in den Cluster für die VM- oder HANA-Ressourcen am dritten Standort.
- Es erfolgt kein Setup für den HANA-Hochverfügbarkeitshook am dritten Standort in global.ini.
Sie müssen am dritten Standort dieselbe HANA-SID und HANA-Installationsnummer verwenden.
Wenn SAP HANA mit horizontaler Skalierung am dritten Standort installiert ist und ausgeführt wird, registrieren Sie den dritten Standort beim primären Standort.
Im folgenden Beispiel wird
SITE-DRals Name für den dritten Standort verwendet.# Execute on the third site su - hn1adm # Register the HANA third site to the primary. Switch --online will shutdown the HANA instance on third site. hdbnsutil -sr_register --name=SITE-DR --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=async --onlineÜberprüfen Sie, ob bei der HANA-Systemreplikation der sekundäre und der dritte Standort anzeigt werden.
# Verify HANA HSR is in sync, execute on primary sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Überprüfen Sie das
SAPHanaSR-Attribut für den dritten Standort. FürSITE-DRsollte im AbschnittSitesder StatusSOKangezeigt werden.# Check SAPHanaSR attribute on any cluster managed host (first or second site) sudo SAPHanaSR-showAttr # Expected result # Global cib-time maintenance prim sec sync_state upd # --------------------------------------------------------------------- # HN1 Fri Jan 27 10:38:46 2023 false HANA_S1 - SOK ok # # Sites lpt lss mns srHook srr # ------------------------------------------------ # SITE-DR SOK # HANA_S1 1674815869 4 hana-s1-db1 PRIM P # HANA_S2 30 4 hana-s2-db1 SOK SDer Cluster erkennt den Replikationsstatus verbundener Standorte. Das überwachte Attribut kann zwischen
SOKundSFAILwechseln. Es erfolgt keine Clusteraktion, wenn bei der Replikation am Notfallwiederherstellungsstandort ein Fehler auftritt.
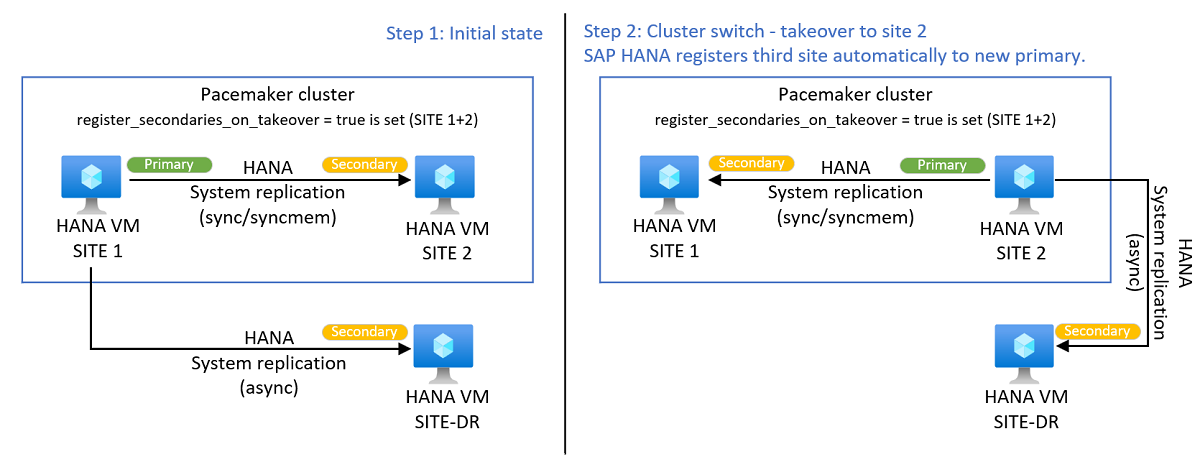
Automatische Registrierung des dritten Standorts
Während eines geplanten oder ungeplanten Übernahmeereignisses zwischen den beiden Pacemaker-Clusterstandorten wird auch eine HSR zum dritten Standort unterbrochen. Pacemaker ändert die HANA-Replikation an den dritten Standort nicht.
SAP stellt seit dem HANA 2 SPS 04 den register_secondaries_on_takeover-Parameter bereit. Wenn der Parameter auf den Wert true festgelegt ist, registriert HANA nach der HSR-Übernahme zwischen Clusterstandort 1 und 2 automatisch den dritten Standort am neuen primären Standort, um das HSR-Setup mit mehreren Zielen aufrechtzuerhalten. Konfigurieren Sie den HANA-Parameter register_secondaries_on_takeover = true, der im [system_replication]-Block von global.ini konfiguriert ist, an beiden SAP HANA-Standorten im Linux-Cluster. Sowohl SITE1 als auch SITE2 benötigen den Parameter in der jeweiligen HANA-Konfigurationsdatei global.ini. Der Parameter kann auch außerhalb eines Pacemaker-Clusters verwendet werden.
Bei einer HSR mit mehreren Ebenen erfolgt keine automatische SAP HANA-Registrierung des dritten Standorts. Sie müssen den dritten Standort manuell beim aktuellen sekundären Standort registrieren, um die HSR-Replikationskette für mehrere Ebenen beizubehalten.