Zuverlässigkeit im Azure Event Grid- und Event Grid-Namespace
Dieser Artikel enthält ausführliche Informationen zur regionalen Resilienz von Azure Event Grid- und Event Grid-Namespaces mit Verfügbarkeitszonen und regionsübergreifender Notfallwiederherstellung und Geschäftskontinuität.
Eine Übersicht über die Architektur der Zuverlässigkeit in Azure finden Sie unter Zuverlässigkeit in Azure.
Unterstützung für Verfügbarkeitszonen
Verfügbarkeitszonen sind physisch getrennte Gruppen von Rechenzentren innerhalb einer Azure-Region. Wenn eine Zone ausfällt, erfolgt ein Failover der Dienste zu einer der verbleibenden Zonen.
Weitere Informationen zu Verfügbarkeitszonen in Azure finden Sie unter Was sind Verfügbarkeitszonen?
Event Grid-Ressourcendefinitionen für Themen, Systemthemen, Domänen sowie Ereignisabonnements und Ereignisdaten werden automatisch in drei Verfügbarkeitszonen repliziert. Wenn in einer der Verfügbarkeitszonen ein regionaler Fehler auftritt, erfolgt für Event Grid-Ressourcen ohne menschliches Eingreifen ein automatisches Failover auf eine andere Verfügbarkeitszone. Derzeit ist es nicht möglich, dieses Feature zu steuern (aktivieren oder deaktivieren). Wenn in einer bestehenden Region Unterstützung von Verfügbarkeitszonen eingeführt wird, wird für bestehende Event Grid-Ressourcen automatisch ein Failover ausgeführt, um dieses Feature zu nutzen. Es ist keine Kundenaktion erforderlich.
Der Azure Event Grid-Namespace erreicht eine Hochverfügbarkeit innerhalb der Region mithilfe von Verfügbarkeitszonen.
Voraussetzungen
Für die Unterstützung von Verfügbarkeitszonen müssen sich Ihre Event Grid-Ressourcen in einer Region befinden, die Verfügbarkeitszonen unterstützt. Informationen dazu, welche Regionen Verfügbarkeitszonen unterstützen, finden Sie in der Liste der unterstützten Regionen.
Preiskalkulation
Da Event Grid Verfügbarkeitszonen automatisch in Regionen unterstützt, die Verfügbarkeitszonen unterstützen, entstehen daraus keine Preisänderungen.
Erstellen einer Ressource mit aktivierten Verfügbarkeitszonen
Da Event Grid Verfügbarkeitszonen automatisch in Regionen unterstützt, die Verfügbarkeitszonen unterstützen, gibt es keine erforderliche Setupkonfiguration.
Unterstützung für das Migrieren zu Verfügbarkeitszonen
Wenn Sie Ihre Event Grid-Ressourcen in eine Region verschieben, die Verfügbarkeitszonen unterstützt, erhalten Sie automatisch Unterstützung für Verfügbarkeitszonen. Informationen zum Verschieben Ihrer Ressourcen in eine andere Region, die Verfügbarkeitszonen unterstützt, finden Sie in den folgenden Artikeln:
- Verschieben von Azure Event Grid-Systemthemen in eine andere Region
- Verschieben von benutzerdefinierten Azure Event Grid-Themen in eine andere Region
- Verschieben von Azure Event Grid-Domänen in eine andere Region
Regionsübergreifende Notfallwiederherstellung und Geschäftskontinuität
Bei der Notfallwiederherstellung (DR) geht es um die Wiederherstellung nach Ereignissen mit schwerwiegenden Auswirkungen, z. B. Naturkatastrophen oder fehlerhaften Bereitstellungen, die zu Downtime und Datenverlust führen. Unabhängig von der Ursache ist das beste Mittel gegen einen Notfall ein gut definierter und getesteter Notfallplan und ein Anwendungsdesign, die Notfallwiederherstellung aktiv unterstützt. Bevor Sie mit der Erstellung Ihres Notfallwiederherstellungsplans beginnen, lesen Sie die Empfehlungen zum Entwerfen einer Notfallwiederherstellungsstrategie.
Bei DR verwendet Microsoft das Modell der gemeinsamen Verantwortung. In einem Modell der gemeinsamen Verantwortung stellt Microsoft sicher, dass die grundlegenden Infrastruktur- und Plattformdienste verfügbar sind. Gleichzeitig replizieren viele Azure-Dienste nicht automatisch Daten oder greifen automatisch auf eine ausgefallene Region zurück, um eine regionsübergreifende Replikation in eine andere aktivierte Region durchzuführen. Für diese Dienste sind Sie dafür verantwortlich, einen Notfallwiederherstellungsplan zu erstellen, der für Ihre Workload geeignet ist. Die meisten Dienste, die auf Azure Platform as a Service (PaaS)-Angeboten laufen, bieten Funktionen und Anleitungen zur Unterstützung von Notfallwiederherstellung und Sie können dienstspezifische Funktionen zur Unterstützung einer schnellen Wiederherstellung nutzen, um Ihren Notfallwiederherstellungsplan zu entwickeln.
Bei der Notfallwiederherstellung wird in der Regel eine Sicherungsressource erstellt, um Unterbrechungen zu verhindern, wenn eine Region fehlerhaft wird. Während dieses Prozesses wird eine primäre und sekundäre Region mit Azure Event Grid-Ressourcen in Ihrer Workload benötigt.
Es gibt verschiedene Möglichkeiten, die Wiederherstellung nach einem schwerwiegenden Verlust der Anwendungsfunktionalität durchzuführen. In diesem Artikel wird die Checkliste beschrieben, die Sie befolgen müssen, um Ihren Client auf die Wiederherstellung nach einem Fehler aufgrund einer fehlerhaften Ressource oder Region vorzubereiten.
Event Grid unterstützt sowohl die manuelle als auch die automatische Notfallwiederherstellung mit Georeplikation (GeoDR) auf Serverseite. Sie können weiterhin die clientseitige Notfallwiederherstellungslogik implementieren, wenn Sie den Failoverprozess präziser steuern möchten. Ausführliche Informationen zur automatischen Notfallwiederherstellung mit Georeplikation finden Sie unter Server-side geo disaster recovery in Azure Event Grid (Serverseitige Notfallwiederherstellung mit Georeplikation in Azure Event Grid). Ausführliche Informationen zum Implementieren der clientseitigen Notfallwiederherstellung finden Sie unter Clientseitige Failoverimplementierung in Azure Event Grid.
In der folgenden Tabelle wird die Unterstützung für clientseitigen Failover und Notfallwiederherstellung mit Georeplikation in Event Grid veranschaulicht.
| Event Grid-Ressource | Clientseitige Failoverunterstützung | Unterstützung für Notfallwiederherstellung mit Georeplikation (GeoDR) |
|---|---|---|
| Benutzerdefinierte Themen | Unterstützt | Geoübergreifend/regional |
| Systemthemen | Nicht unterstützt | Automatisch aktiviert |
| Domänen | Unterstützt | Geoübergreifend/regional |
| Partnernamespaces | Unterstützt | Nicht unterstützt |
| Namespaces | Unterstützt | Nicht unterstützt |
Event Grid-Namespace
Der Event Grid-Namespace unterstützt keine regionsübergreifende Notfallwiederherstellung. Sie können eine regionsübergreifende Hochverfügbarkeit jedoch durch eine clientseitige Failoverimplementierung erzielen, indem Sie primäre und sekundäre Namespaces erstellen.
Mit einer clientseitigen Failoverimplementierung haben Sie folgende Möglichkeiten:
Implementieren eines benutzerdefinierten (manuellen oder automatisierten) Prozesses zur Replikation von Namespaces, Clientidentitäten und anderen Konfigurationen**, einschließlich ZS-Zertifikaten, Clientgruppen, Themenbereichen, Berechtigungsbindungen und Routing, zwischen primären und sekundären Regionen
Implementieren eines Concierge-Diensts, der primäre und sekundäre Endpunkte für Clients bereitstellt, indem er eine Integritätsprüfung für Endpunkte durchführt. Der Concierge-Dienst kann eine Webanwendung sein, die repliziert und deren Erreichbarkeit mithilfe von DNS-Umleitungsverfahren, z. B. per Azure Traffic Manager, gewährleistet wird.
Bereitstellen einer aktiv-aktiven Notfallwiederherstellungslösung durch die Replikation der Metadaten und die Lastverteilung auf die Namespaces. Eine Aktiv-Passiv-DR-Lösung kann durch die Replikation der Metadaten erreicht werden, um den sekundären Namespace bereitzuhalten, so dass der Datenverkehr auf den sekundären Namespace umgeleitet werden kann, wenn der primäre Namespace nicht verfügbar ist.
Einrichten der Notfallwiederherstellung
Für gekoppelte Regionen bietet Event Grid die Möglichkeit, für benutzerdefinierte Themen, Systemthemen und Domänen ein Failover des Veröffentlichungsdatenverkehrs auf die gekoppelte Region auszuführen. Im Hintergrund synchronisiert Event Grid die Ressourcendefinitionen von Themen, Systemthemen, Domänen und Ereignisabonnements automatisch mit der gekoppelten Region. Ereignisdaten werden jedoch nicht in die gekoppelte Region repliziert. Im Normalzustand werden Ereignisse in der Region gespeichert, die Sie für diese Ressource ausgewählt haben. Wenn eine Region ausgefallen ist und Microsoft das Failover initiiert, werden neue Ereignisse ohne Eingriffe von Ihrer Seite an die geografisch gekoppelte Region übertragen und von dort gesendet. Ereignisse, die in der ursprünglichen Region veröffentlicht und akzeptiert wurden, werden von dort gesendet, nachdem der Ausfall behoben wurde.
Sie können zwischen zwei Failoveroptionen wählen: dem von Microsoft initiierten und dem vom Kunden initiierten Failover. Ausführliche Schritte zum Konfigurieren dieser beiden Einstellungen finden Sie unter Konfigurieren der Datenresidenz.
Das von Microsoft initiierte Failover wird von Microsoft in seltenen Fällen angewendet, um für alle Event Grid-Ressourcen einer betroffenen Region ein Failover in die entsprechende geografisch gekoppelte Region auszuführen. Microsoft behält sich das Recht vor, zu entscheiden, wann diese Option angewendet wird. Dieser Mechanismus bedarf nicht der Zustimmung des Benutzers, bevor ein Failover für den Datenverkehr des Benutzers ausgeführt wird.
Sie können diese Funktion aktivieren, indem Sie die Konfiguration für Ihr Thema oder Ihre Domäne aktualisieren. Wählen Sie Geografisch übergreifend (Standard) aus, um das von Microsoft initiierte Failover zu aktivieren.
Das vom Kunden initiierte Failover wird durch Ihren benutzerdefinierten Notfallwiederherstellungsplan für Azure Event Grid-Themen und -Domänen definiert, und es werden keine Daten jeglicher Art von Microsoft in eine andere Region repliziert. Diese Failoveroption ist zwar etwas aufwändiger, ermöglicht aber ein schnelleres Failover, und Sie können die sekundären Regionen selbst auswählen. Falls Sie eine clientseitige Notfallwiederherstellung für Azure Event Grid-Themen implementieren möchten, finden Sie unter Erstellen Ihrer eigenen clientseitigen Notfallwiederherstellung für Azure Event Grid-Themen weitere Informationen.
Nachfolgend sind einige Gründe dafür aufgeführt, warum Sie das Feature für das von Microsoft initiierte Failover deaktivieren sollten:
- Das von Microsoft initiierte Failover wird nach bestem Bemühen ausgeführt.
- Einige geografisch gekoppelte Regionen erfüllen möglicherweise nicht die Datenresidenzanforderungen Ihrer Organisation.
Sie können diese Funktion aktivieren, indem Sie die Konfiguration für Ihr Thema oder Ihre Domäne aktualisieren. Wählen Sie Regional aus.
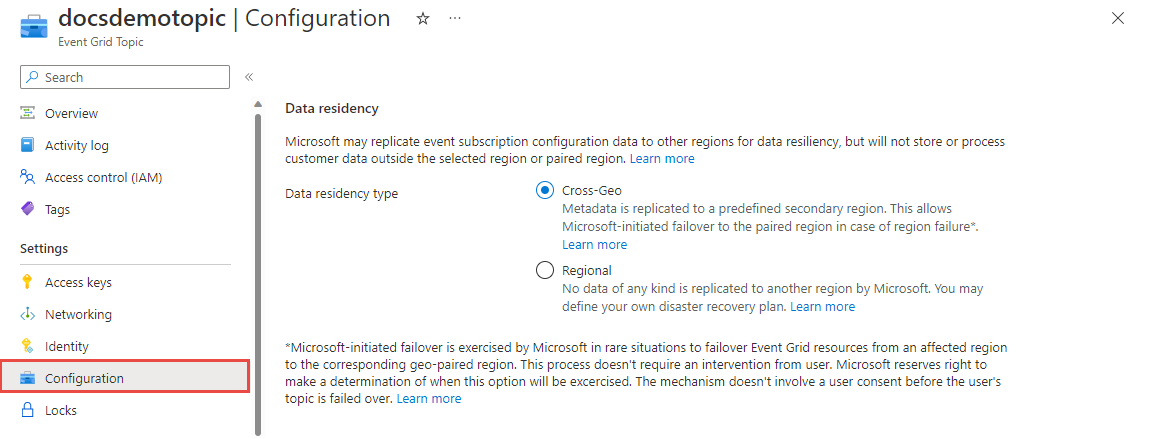
Wenn Sie eine nicht gekoppelte Region verwenden, werden Ihre Metadaten nur innerhalb der Region repliziert, unabhängig von der ausgewählten Datenresidenzkonfiguration.
Failover für die Notfallwiederherstellung
Die Notfallwiederherstellung wird mit zwei Metriken gemessen: Recovery Point Objective (RPO) und Recovery Time Objective (RTO). Weitere Informationen finden Sie unter Was sind Geschäftskontinuität, Hochverfügbarkeit und Notfallwiederherstellung?
Beim automatischen Failover von Event Grid gelten verschiedene RPOs und RTOs für Ihre Metadaten (Themen, Domänen und Ereignisabonnements) und für Ihre Daten (Ereignisse). Wenn Sie andere Werte als die unten angegebenen benötigen, können Sie auch weiterhin ein eigenes clientseitiges Failover mithilfe von APIs für die Themenintegrität implementieren.
Recovery Point Objective (RPO)
Metadaten-RPO: Null Minuten. Für die entsprechenden Ressourcen wird die Ressourcendefinition synchron in die geografisch gekoppelte Region repliziert, wenn eine Ressource erstellt, aktualisiert oder gelöscht wird. Bei einem Failover gehen keine Metadaten verloren.
Daten-RPO (Recovery Point Objective): Wenn ein Failover stattfindet, werden neue Daten über die gekoppelte Region verarbeitet. Nachdem der Ausfall für die betroffene Region behoben wurde, werden die unverarbeiteten Ereignisse von dort gesendet. Dauert die Wiederherstellung der Region länger als die festgelegte Gültigkeitsdauer für Ereignisse ist, werden die Daten u. U. gelöscht. Wir empfehlen, ein Ziel für unzustellbare Nachrichten für ein Ereignisabonnement einzurichten, um diesen Datenverlust zu minimieren. Wenn die betroffene Region verloren geht und nicht wiederhergestellt werden kann, treten Datenverluste auf. Im besten Fall behält der Abonnent die Veröffentlichungsrate bei, und es gehen nur Daten weniger Sekunden verloren. Im schlimmsten Fall verarbeitet der Abonnent Ereignisse nicht aktiv. Bei einer maximalen Gültigkeitsdauer von 24 Stunden könnten dann die Daten von bis zu 24 Stunden verloren gehen.
Recovery Time Objective (RTO)
Metadaten-RTO (Recovery Time Objective): Die Failoverentscheidung wird basierend auf Faktoren wie der verfügbaren Kapazität in der gekoppelten Region getroffen und kann 60 Minuten oder auch länger dauern. Nachdem ein Failover initiiert wurde, beginnt Event Grid innerhalb von fünf Minuten damit, Aufrufe zum Erstellen/Aktualisieren/Löschen von Themen und Abonnements zu akzeptieren.
Daten-RTO: Identisch mit den obigen Informationen.
Wichtig
- Im Fall einer serverseitigen Notfallwiederherstellung kann Event Grid das Failover nicht einleiten, wenn die gekoppelte Region nicht über verfügbare Kapazität zum Verarbeiten des zusätzlichen Datenverkehrs verfügt. Die Wiederherstellung erfolgt nach bestem Bemühen.
- Für die Verwendung dieses Features fallen keine Gebühren an.
- Die georedundante Notfallwiederherstellung wird für Partnernamespaces und Partnerthemen nicht unterstützt.