Erstellen von Azure Machine Learning-Datasets über Azure Open Datasets
In diesem Artikel erfahren Sie, wie Sie mithilfe von Azure Machine Learning-Datasets und Azure Open Datasets kuratierte Anreicherungsdaten in Ihre lokalen remote ausgeführten Machine Learning-Experimente einbringen.
Mit einem Azure Machine Learning-Dataset erstellen Sie einen Verweis auf den Speicherort der Datenquelle sowie eine Kopie der zugehörigen Metadaten. Da Datasets nur langsam ausgewertet werden und die Daten am vorhandenen Speicherort verbleiben, profitieren Sie von folgenden Vorteilen:
- Sie riskieren keine ungewollten Änderungen an Ihren ursprünglichen Datenquellen.
- Keine zusätzlichen Speicherkosten.
- Der ML-Workflow wird verbessert und beschleunigt.
Weitere Informationen dazu, welche Rolle Datasets im Workflow für den Datenzugriff in Azure Machine Learning spielen, finden Sie im Artikel Datenzugriff in Azure Machine Learning.
Azure Open Datasets sind kuratierte öffentliche Datasets, die szenariospezifische Features hinzufügen, um Ihre Vorhersagelösungen anzureichern und die Genauigkeit zu verbessern. In der Ressource Open Datasets-Katalog finden Sie Daten der öffentlichen Domäne, mit denen Sie Ihre Machine Learning-Modelle trainieren können, z. B. zu folgenden Themen:
- Gesundheit und Genomik
- Arbeit und Wirtschaft
- Bevölkerung und Sicherheit
- Ergänzende und allgemeine Datasets
- Transport
Offene Datasets werden in der Cloud in Microsoft Azure gehostet. Sie sind sowohl im Azure Machine Learning Python-SDK als auch im Azure Machine Learning Studio enthalten.
Voraussetzungen
Erforderlich:
Ein Azure-Abonnement. Wenn Sie keines haben, erstellen Sie ein kostenloses Konto, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Eine Installation des Azure Machine Learning SDK für Python, in dem das Paket
azureml-datasetsenthalten ist.- Erstellen Sie eine Azure Machine Learning-Computeinstanz, bei der es sich um eine vollständig konfigurierte und verwaltete Entwicklungsumgebung handelt, die integrierte Notebooks und das bereits installierte SDK beinhaltet.
ODER
- Arbeiten Sie in Ihrer eigenen Python-Umgebung, und installieren Sie das SDK selbst anhand dieser Anweisungen.
Hinweis
Einige Datasetklassen sind vom Paket azureml-dataprep abhängig. Dieses Paket ist nur mit 64-Bit-Python kompatibel. Für Linux-Benutzer werden diese Klassen nur unter diesen Linux-Distributionen unterstützt:
- Debian (8, 9)
- Fedora (27, 28)
- Red Hat Enterprise Linux (7, 8)
- Ubuntu (14.04, 16.04, 18.04)
Erstellen von Datasets mit dem SDK
Wenn Sie Azure Machine Learning-Datasets über Open Datasets-Klassen im Python SDK erstellen möchten, vergewissern Sie sich, dass Sie das Paket mit pip install azureml-opendatasets installiert haben. Im SDK repräsentiert die Klasse eines jeden diskreten Datensatzes diese Klasse, und bestimmte Klassen sind als Azure Machine Learning FileDataset-Datentyp, Azure Machine Learning TabularDataset-Datentyp oder beides verfügbar. Eine vollständige Liste der opendatasets-Klassen finden Sie in der Referenzdokumentation.
Sie können bestimmte opendatasets-Klassen entweder als TabularDataset- oder FileDataset-Ressourcen abrufen. Anschließend können Sie die Dateien direkt bearbeiten und/oder herunterladen. Andere Klassen können ein Dataset ausschließlich mithilfe der Funktion get_tabular_dataset() oder get_file_dataset() aus der Dataset-Klasse im Python SDK abrufen.
Dieser Code zeigt, dass die opendatasets-Klasse „MNIST“ ein TabularDataset oder ein FileDataset zurückgeben kann:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
In diesem Beispiel ist die opendatasets-Klasse „Diabetes“ nur als TabularDataset verfügbar. Hierfür muss get_tabular_dataset() verwendet werden.
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Registrieren von Datasets
Registrieren Sie ein Azure Machine Learning-Dataset bei Ihrem Arbeitsbereich, damit Sie das Dataset für andere Benutzer freigeben und in Experimenten in Ihrem Arbeitsbereich wiederverwenden können. Wenn Sie ein Azure Machine Learning-Dataset registrieren, das aus Open Datasets erstellt wurde, werden die Daten nicht sofort heruntergeladen. Auf die Daten wird erst später, wenn sie angefordert werden (z. B. während des Trainings), in einem zentralen Speicherort zugegriffen.
Verwenden Sie die register()-Methode, um Ihre Datasets bei einem Arbeitsbereich zu registrieren.
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Erstellen von Datasets mit Studio
Sie können Azure Machine Learning-Datasets auch über Azure Open Datasets mit Azure Machine Learning Studio erstellen. Diese konsolidierte Weboberfläche umfasst Tools für maschinelles Lernen zur Durchführung von Data Science-Szenarien für Datenwissenschaftler aller Qualifikationsstufen.
Hinweis
Datasets, die über Azure Machine Learning Studio erstellt werden, werden automatisch beim Arbeitsbereich registriert.
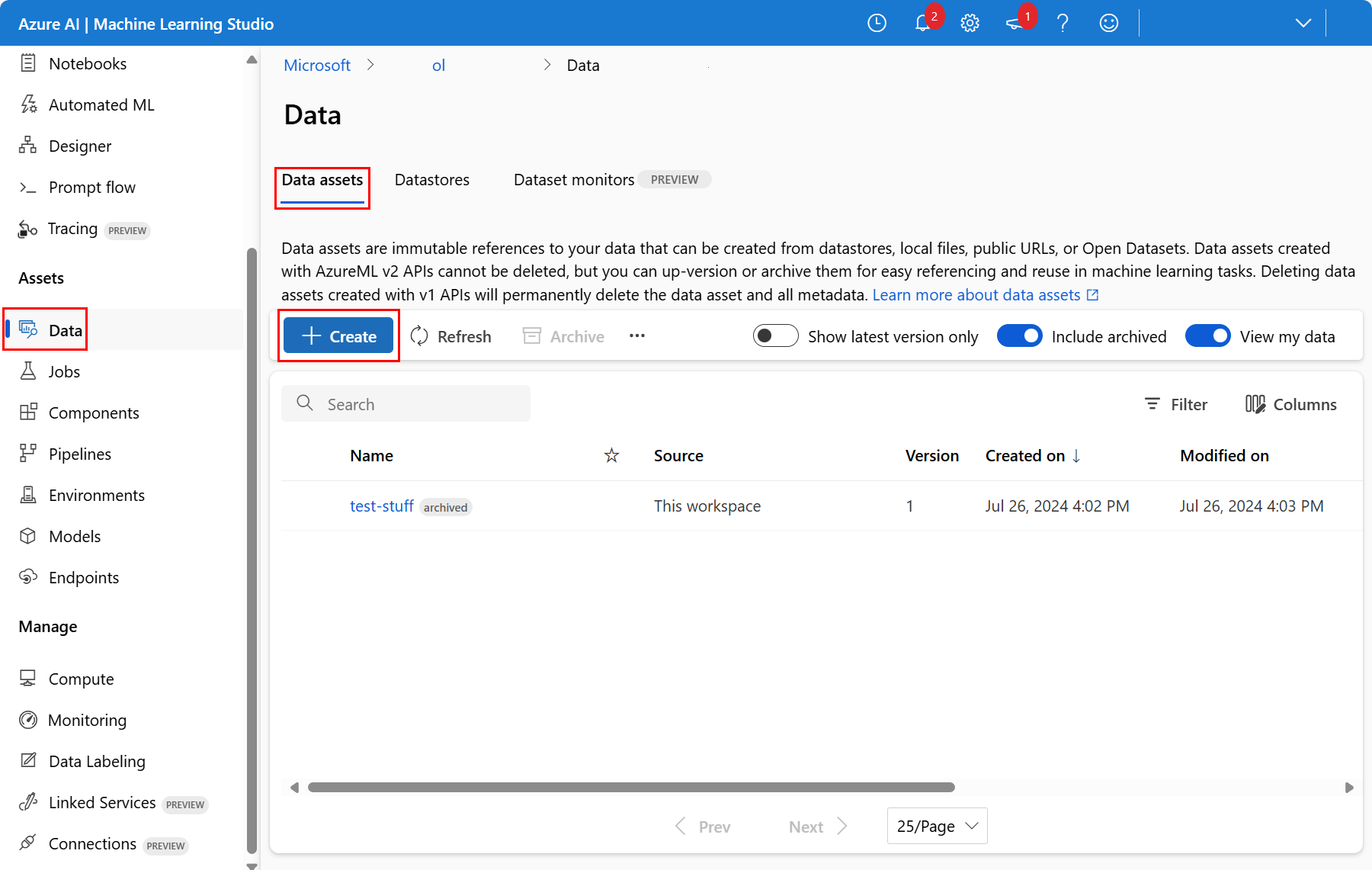
Wählen Sie in Ihrem Arbeitsbereich Daten im linken Navigationsbereich aus. Wählen Sie auf der Registerkarte Datenressourcen die Option Erstellen aus, wie in diesem Screenshot gezeigt:
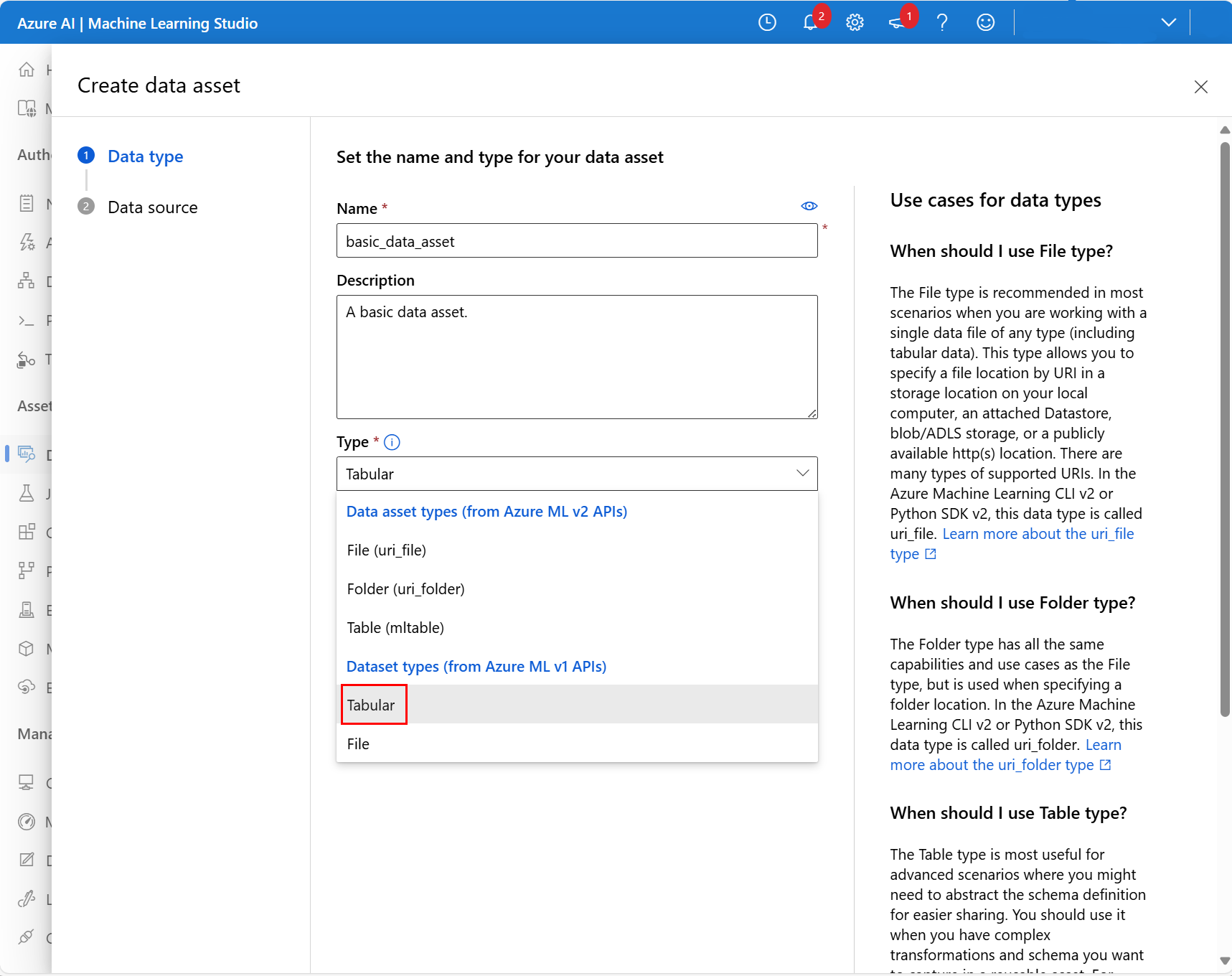
Fügen Sie auf dem nächsten Bildschirm einen Namen und eine optionale Beschreibung für die neue Datenressource hinzu. Wählen Sie dann Tabellarisch im Dropdownmenü Typ aus, wie in diesem Screenshot gezeigt:
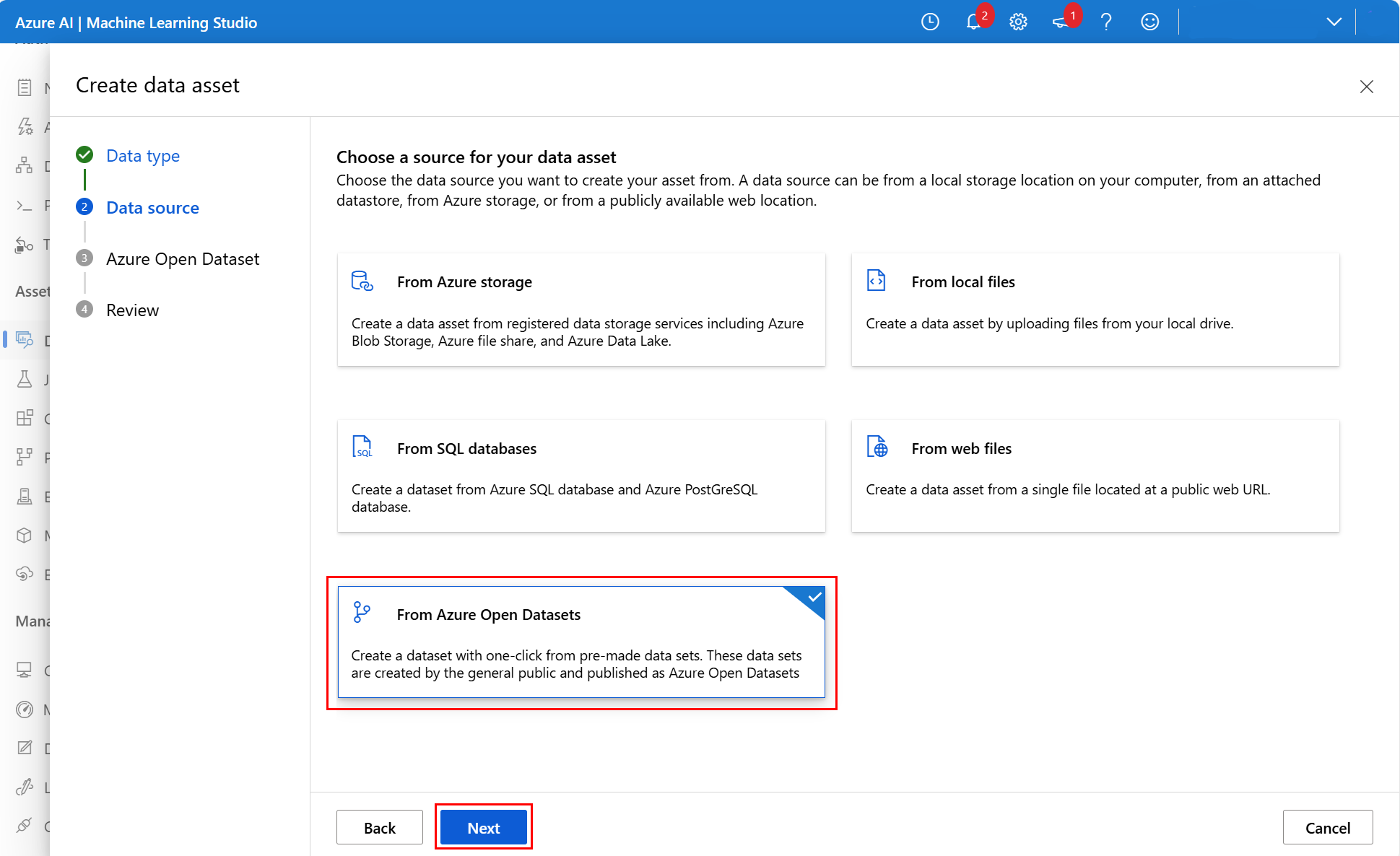
Wählen Sie auf dem nächsten Bildschirm die Option Aus Azure Open Datasets und dann Weiter aus, wie in diesem Screenshot gezeigt:
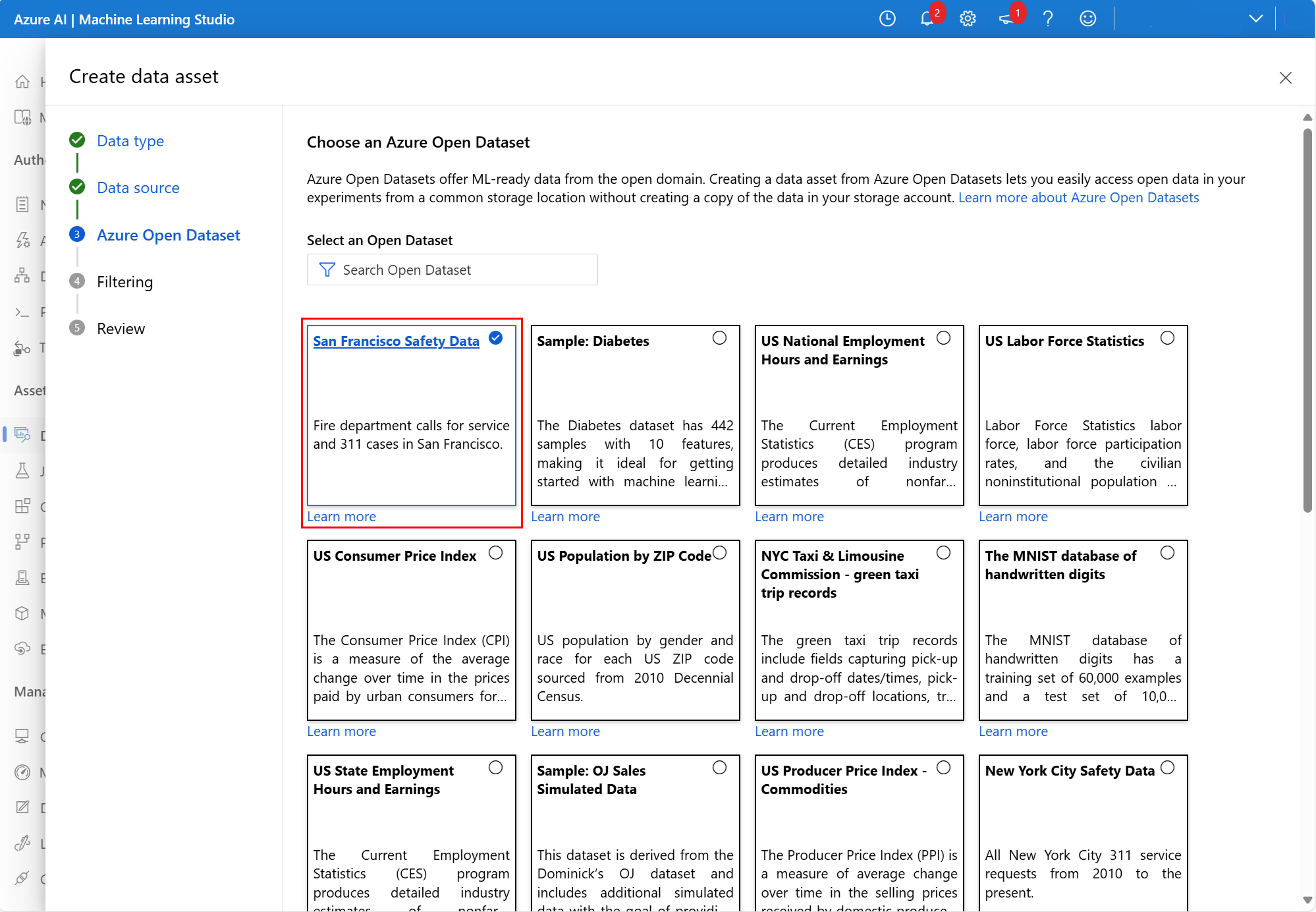
Wählen Sie auf dem nächsten Bildschirm ein verfügbares Azure Open Dataset aus. In diesem Screenshot haben wir das Dataset San Francisco Safety Data ausgewählt:
Scrollen Sie bei Bedarf nach unten, und wählen Sie Weiter aus, wie in diesem Screenshot gezeigt:
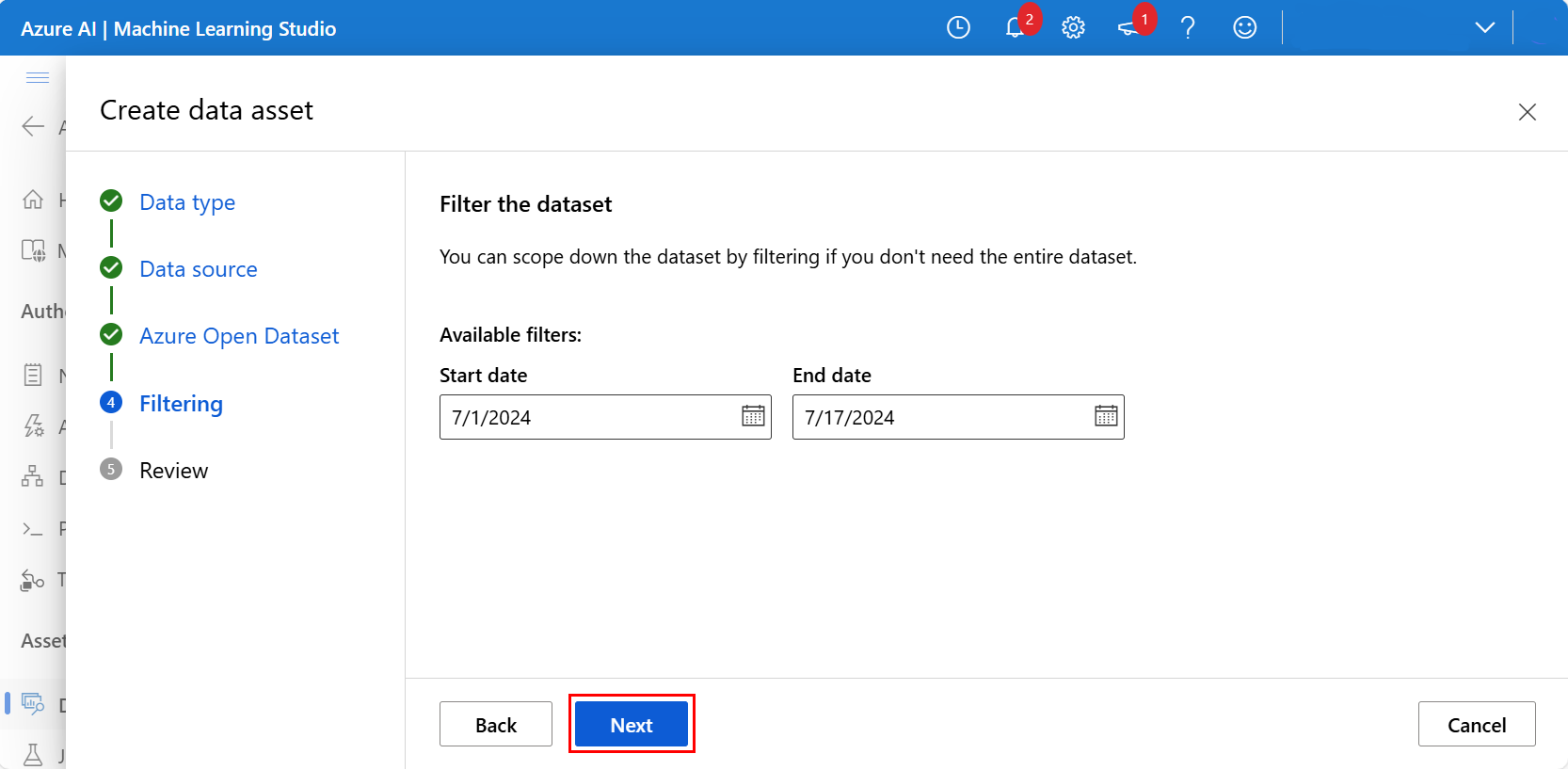
Filtern Sie optional die Daten mit den verfügbaren Filtern, die für das ausgewählte Dataset geeignet sind. Für das Dataset San Francisco Safety Data legen wir den gefilterten Datumsbereich zwischen einem Startdatum 1. Juli 2024 und 17. Juli 2024 fest. Wählen Sie Weiter aus, wie in diesem Screenshot gezeigt:
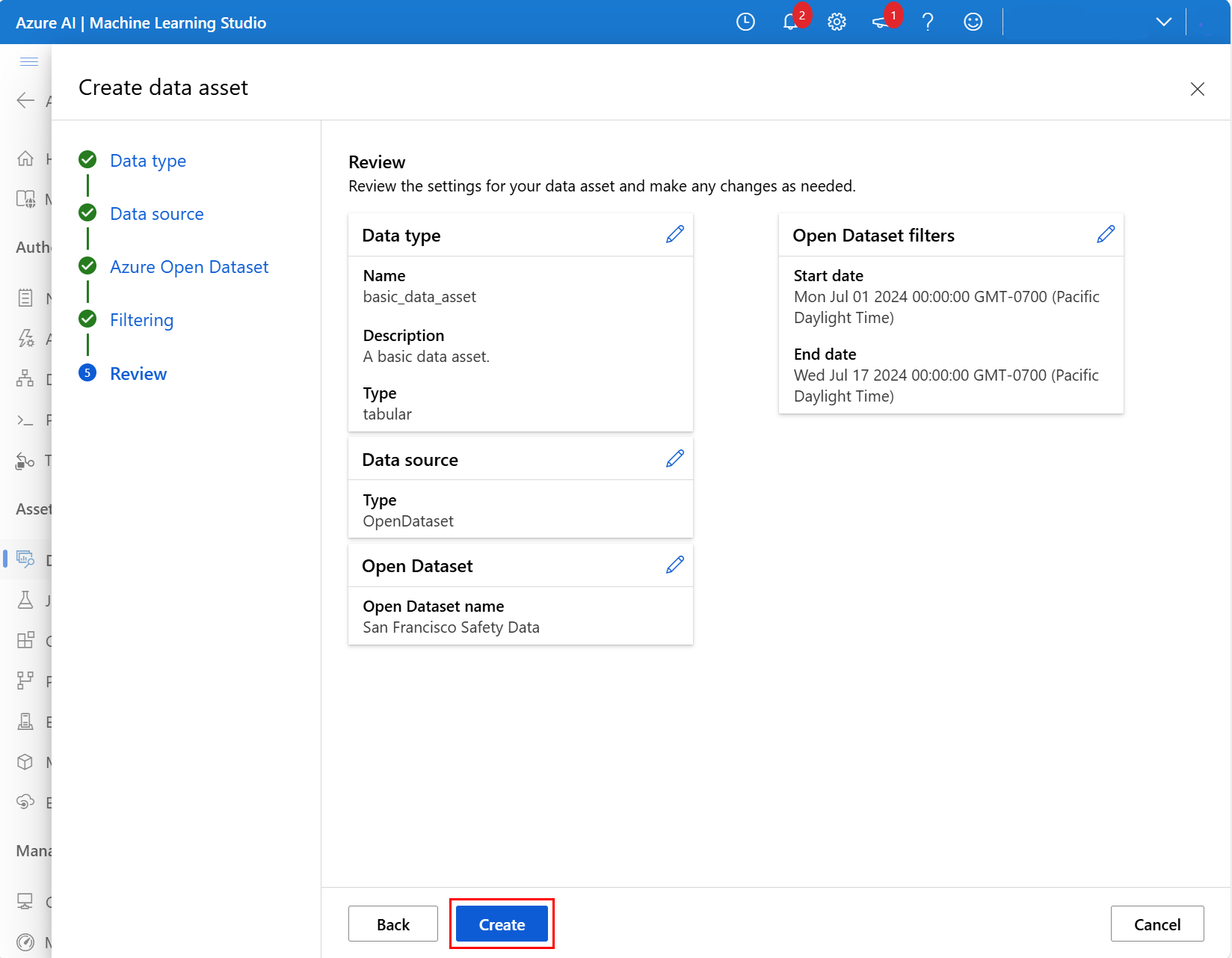
Überprüfen Sie auf dem nächsten Bildschirm die Einstellungen für die neue Datenressource, und nehmen Sie alle erforderlichen Änderungen vor. Wenn sie gut aussieht, wählen Sie dann Erstellen aus, wie in diesem Screenshot gezeigt:
Weitere Informationen zu den Feldbeschreibungen und Datumsbereichen für das Dataset San Francisco Safety Data finden Sie in der Ressource San Francisco Safety Data. Weitere Informationen zu den anderen Datasets finden Sie in der Azure Open Datasets Catalog-Ressource.







Das Dataset ist nun in Ihrem Arbeitsbereich unter Datasets verfügbar. Sie können es auf die gleiche Weise verwenden wie andere Datasets, die Sie erstellt haben.
Zugreifen auf Datasets für Ihre Experimente
Verwenden Sie Ihre Datasets in Ihren Machine Learning-Experimenten zum Trainieren von ML-Modellen. Weitere Informationen finden Sie unter Weitere Informationen zum Trainieren mit Datasets.
Beispielnotebooks
Beispiele und Demos für die Open Datasets-Funktionen finden Sie in diesen Beispiel-Notebooks.