Übung 1: Entwickeln und Registrieren eines Feature-Sets mit verwaltetem Feature-Speicher
In dieser Tutorialreihe erfahren Sie, wie Features nahtlos alle Phasen des Lebenszyklus für maschinelles Lernen integrieren: Prototyperstellung, Training und Operationalisierung.
Mit dem verwalteten Feature Store von Azure Machine Learning können Sie Features entdecken, erstellen und anwenden. Der Lebenszyklus des maschinellen Lernens umfasst eine Phase für die Prototyperstellung, in der Sie mit verschiedenen Features experimentieren. Er umfasst auch eine Operationalisierungsphase, in der Modelle bereitgestellt werden und Rückschlussschritte nach Featuredaten suchen. Features fungieren im Lebenszyklus des maschinellen Lernens als Bindeglieder. Weitere Informationen zu den grundlegenden Konzepten des verwalteten Feature Stores finden Sie unter Was ist der verwaltete Feature Store? und Grundlegendes zu Entitäten auf oberster Ebene im verwalteten Feature Store.
Dieses Tutorial beschreibt, wie man eine Feature-Set-Spezifikation mit benutzerdefinierten Transformationen erstellt. Anschließend wird dieser Merkmalssatz verwendet, um Trainingsdaten zu generieren, die Materialisierung zu ermöglichen und ein Backfill durchzuführen. Die Materialisierung berechnet die Merkmalswerte für ein Merkmalsfenster und speichert diese Werte dann in einem Materialisierungsspeicher. Alle Merkmalsabfragen können dann diese Werte aus dem Materialisierungsspeicher verwenden.
Ohne Materialisierung wendet eine Featuresatzabfrage die Transformationen direkt auf die Quelle an, um die Features zu berechnen, bevor die Werte zurückgegeben werden. Dieser Vorgang funktioniert gut für die Phase der Prototyperstellung. Für Trainings- und Inferenzoperationen in einer Produktionsumgebung empfehlen wir jedoch, die Funktionen zu materialisieren, um die Zuverlässigkeit und Verfügbarkeit zu erhöhen.
Dieses Tutorial ist der erste Teil der Tutorial-Reihe zum Thema Managed Feature Store. In diesem Tutorial wird Folgendes vermittelt:
- Erstellen einer neuen minimalen Feature Store-Ressource
- Entwickeln und lokales Testen eines Featuresatzes mit Featuretransformationsfunktion
- Registrieren einer Feature Store-Entität beim Feature Store
- Registrieren des von Ihnen entwickelten Featuresatzes beim Feature Store
- Generieren eines Beispieldatenrahmens für das Training mithilfe der von Ihnen erstellten Features
- Aktivieren Sie die Offlinematerialisierung für die Featuresätze, und gleichen Sie die Featuredaten ab.
Diese Tutorialreihe verfügt über zwei Ansätze:
- Beim reinen SDK-Ansatz werden nur Python-SDKs verwendet. Wählen Sie diesen Ansatz für eine rein Python-basierte Entwicklung und Bereitstellung.
- Beim Ansatz mit SDK und CLI wird das Python-SDK nur für die Entwicklung und das Testen von Featuresätzen verwendet und die CLI für CRUD-Vorgänge (Erstellen, Lesen, Aktualisieren und Löschen). Dieser Ansatz ist in CI/CD- (Continuous Integration/Continuous Delivery) oder GitOps-Szenarien nützlich, in denen die CLI und YAML bevorzugt werden.
Voraussetzungen
Bevor Sie mit diesem Tutorial fortfahren, stellen Sie sicher, dass die folgenden Voraussetzungen erfüllt sind:
Ein Azure Machine Learning-Arbeitsbereich. Weitere Informationen zur Erstellung von Arbeitsbereichen finden Sie im Schnellstart: Erstellen von Arbeitsbereichsressourcen.
In Ihrem Benutzerkonto wird der Feature Store in der Rolle Besitzer*in der Ressourcengruppe erstellt.
Wenn Sie für dieses Tutorial eine neue Ressourcengruppe verwenden, können Sie ganz einfach alle Ressourcen löschen, indem Sie die Ressourcengruppe löschen.
Vorbereiten der Notebookumgebung
In diesem Tutorial wird ein Azure Machine Learning-Spark-Notebook für die Entwicklung verwendet.
Wählen Sie in der Azure Machine Learning Studio-Umgebung im linken Bereich Notebooks und dann die Registerkarte Beispiele aus.
Navigieren Sie zum Verzeichnis featurestore_sample (wählen Sie Samples>SDK v2>sdk>python>featurestore_sample aus), und wählen Sie dann Klonen aus.
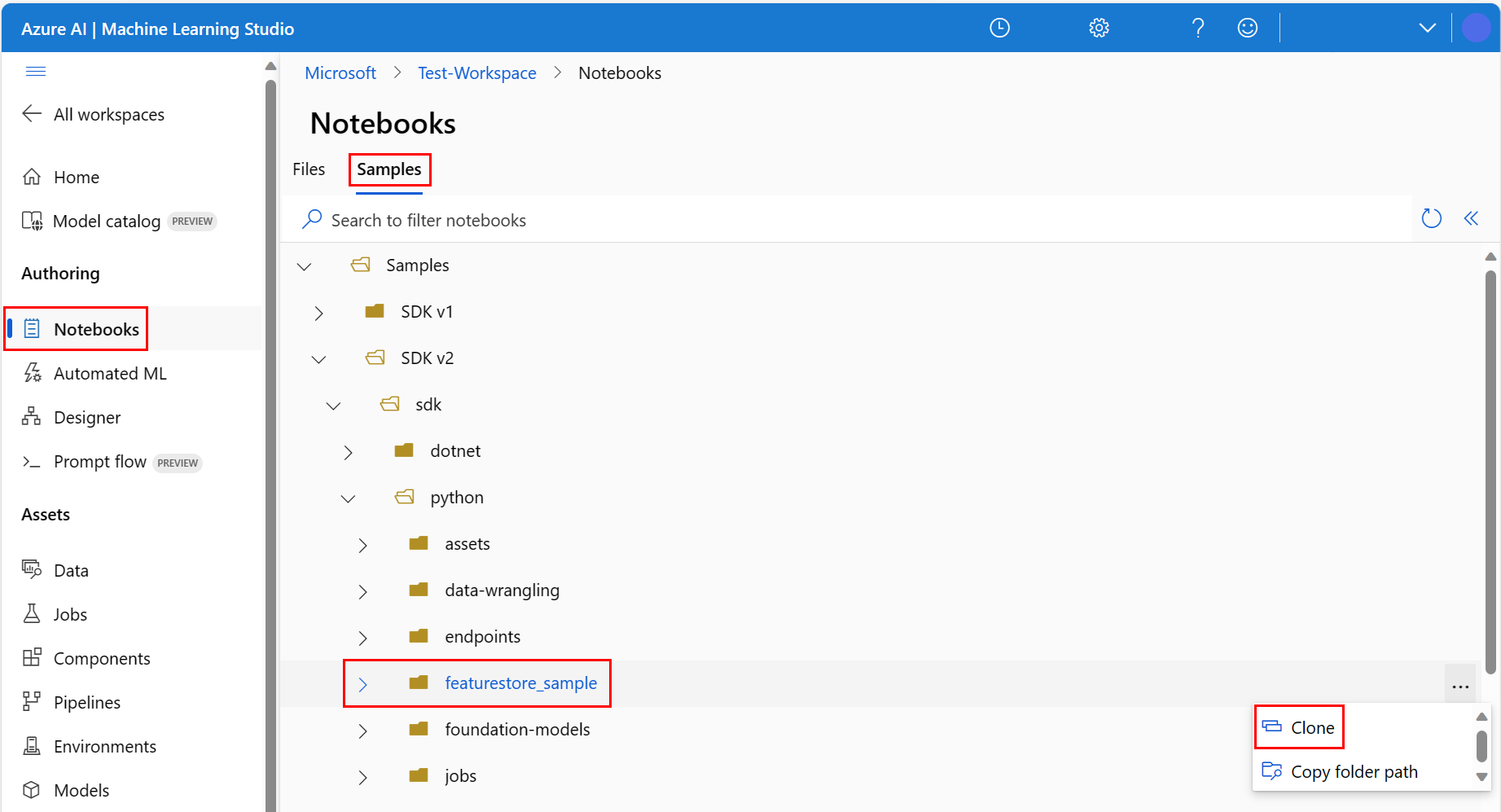
Der Bereich Zielverzeichnis auswählen wird geöffnet. Wählen Sie das Verzeichnis users, dann Ihren_Benutzernamen aus, und schließlich die Option Klonen.
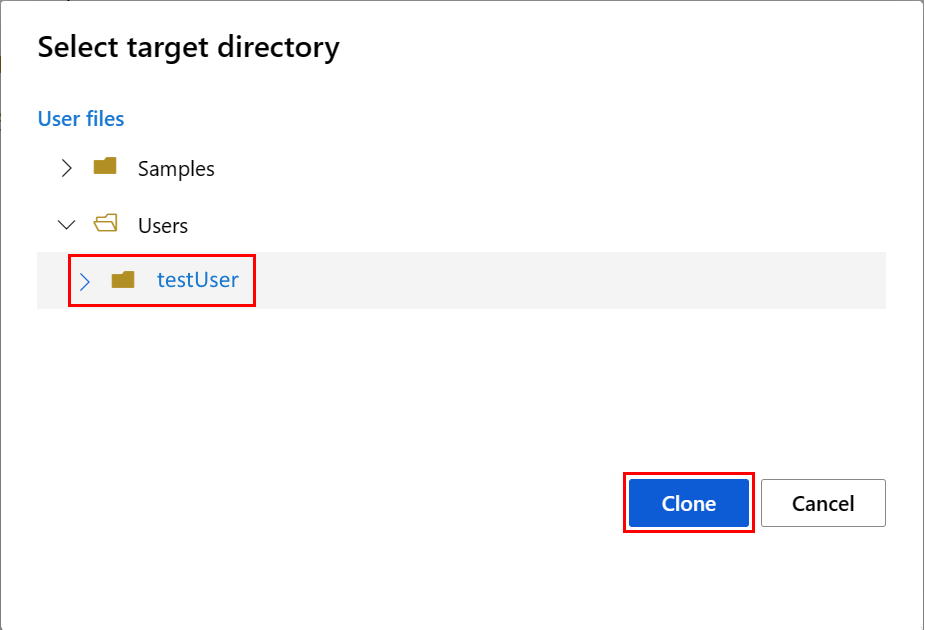
Sie müssen zur Konfiguration der Notebookumgebung die Datei conda.yml hochladen:
- Wählen Sie im linken Bereich Notebooks und dann die Registerkarte Dateien aus.
- Wechseln Sie in das Verzeichnis env (wählen Sie users>Ihren_Benutzernamen>featurestore_sample>project>env aus), und wählen Sie dann die Datei conda.yml aus.
- Wählen Sie Herunterladen aus.
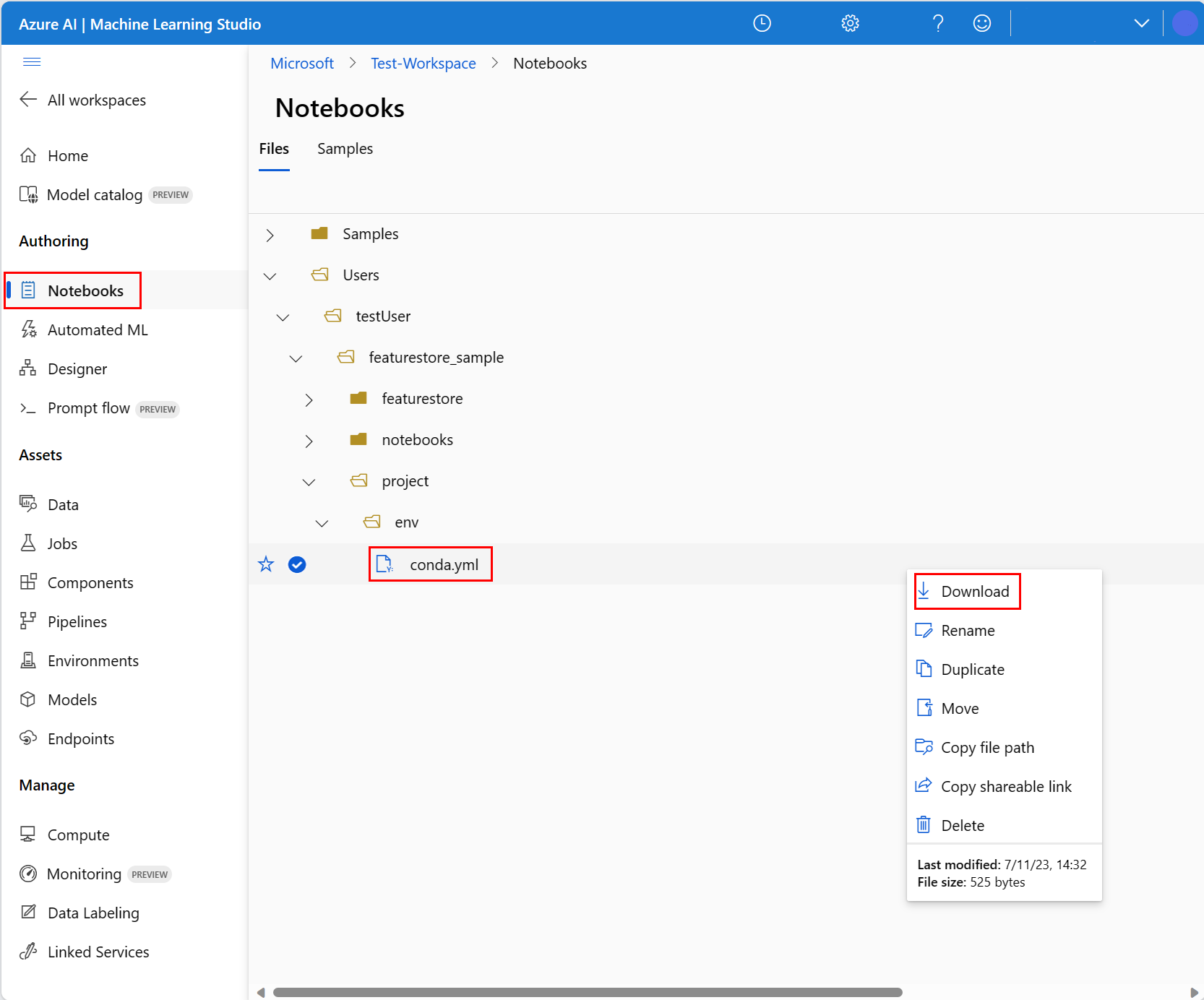
- Wählen Sie oben im Navigationsbereich im Dropdownmenü Compute die Option Serverloses Spark Compute aus. Dieser Vorgang kann ein bis zwei Minuten dauern. Warten Sie, bis auf einer Statusleiste oben Sitzung konfigurieren angezeigt wird.
- Wählen Sie in der oberen Statusleiste Sitzung konfigurieren aus.
- Wählen Sie Python-Pakete aus.
- Wählen Sie Conda-Datei hochladen aus.
- Wählen Sie die
conda.yml-Datei aus, die Sie auf Ihr Gerät heruntergeladen haben. - (Optional) Erhöhen Sie das Sitzungstimeout (Leerlaufzeit in Minuten), um die Startzeit des serverlosen Spark-Clusters zu verringern.
Öffnen Sie in der Azure Machine Learning-Umgebung das Notebook, und wählen Sie Sitzung konfigurieren aus.
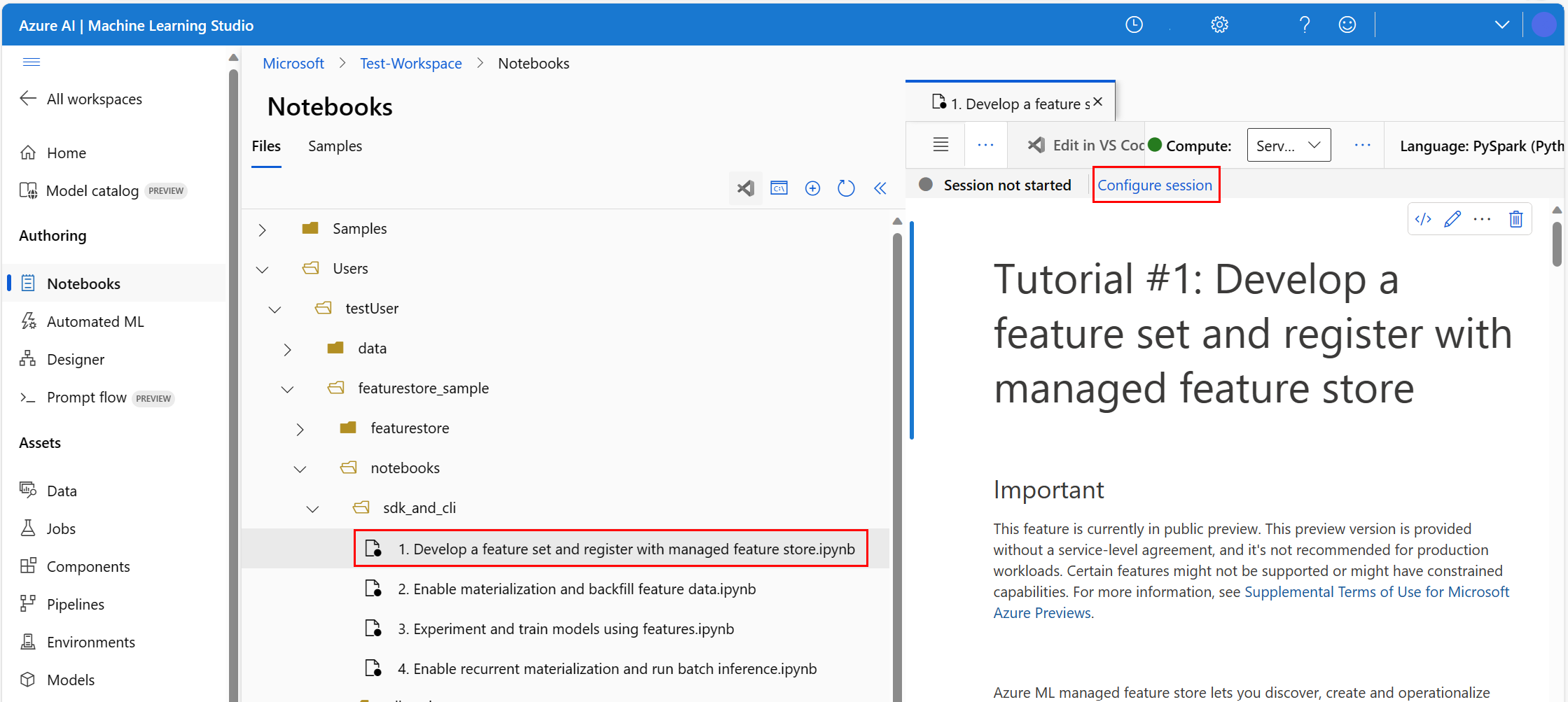
Wählen Sie im Bereich Sitzung konfigurieren die Option Python-Pakete aus.
Laden Sie die conda-Datei hoch:
- Wählen Sie auf der Registerkarte Python-Pakete die Option Conda-Datei hochladen aus.
- Navigieren Sie zum Verzeichnis mit der conda-Datei.
- Wählen Sie conda.yml und dann Öffnen aus.
Wählen Sie Übernehmen.






Starten der Spark-Sitzung
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Richten Sie das Stammverzeichnis für die Beispiele ein.
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Einrichten der CLI
Nicht zutreffend.
Hinweis
Sie verwenden einen Feature Store, um Features projektübergreifend wiederzuverwenden. Sie verwenden einen Projektarbeitsbereich (einen Azure Machine Learning-Arbeitsbereich), um Rückschlussmodelle zu trainieren, indem Sie Features aus Feature Stores nutzen. Viele Projektarbeitsbereiche können denselben Feature Store gemeinsam nutzen und wiederverwenden.
In diesem Tutorial werden zwei SDKs verwendet:
Feature Store CRUD SDK
Sie verwenden das gleiche
MLClientSDK (Paketnameazure-ai-ml) wie mit dem Azure Machine Learning-Arbeitsbereich. Ein Feature Store wird als eine Art Arbeitsbereich implementiert. Daher wird dieses SDK für CRUD-Vorgänge für Feature Stores, Featuresätze und Feature Store-Entitäten verwendet.Feature Store Core SDK
Dieses SDK (
azureml-featurestore) ist für die Entwicklung und Nutzung von Featuresätzen konzipiert. In den folgenden Schritten in diesem Tutorial werden die folgenden Vorgänge beschrieben:- Entwickeln einer Featuresatzspezifikation
- Abrufen von Featuredaten
- Auflisten/Abrufen registrierter Featuresätze
- Generieren und Auflösen von Spezifikationen für den Featureabruf
- Generieren von Trainings- und Rückschlussdaten mithilfe von Zeitpunktjoins
Dieses Tutorial erfordert keine explizite Installation dieser SDKs, da die früheren Anweisungen in conda.yml diesen Schritt abdecken.
Erstellen eines minimalen Feature Stores
Legen Sie Feature Store-Parameter fest, z. B. Name, Speicherort und andere Werte.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Erstellen Sie den Feature Store.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Initialisieren Sie einen Feature Store Core SDK-Client für Azure Machine Learning.
Wie weiter oben in diesem Tutorial erläutert, wird der Feature Store Core SDK-Client verwendet, um Features zu entwickeln und zu nutzen.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Erteilen Sie Ihrer Benutzeridentität die Rolle "Azure Machine Learning Data Scientist" im Feature Store. Beziehen Sie den Wert Ihrer Microsoft Entra-Objekt-ID aus dem Azure-Portal wie unter Suchen der Benutzerobjekt-ID beschrieben.
Weisen Sie Ihrer Benutzeridentität die Rolle AzureML Data Scientist zu, damit sie Ressourcen im Feature Store Workspace erstellen kann. Es kann einige Zeit dauern, bis sich die Genehmigungen durchsetzen.
Weitere Informationen zur Zugriffskontrolle finden Sie unter Verwalten der Zugriffskontrolle für verwaltete Feature-Stores.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Erstellen eines Prototyps und Entwicklung eines Featuresatzes
In diesen Schritten erstellen Sie ein Feature-Set mit dem Namen transactions, das auf Rolling-Window-Aggregaten basierende Features enthält:
Untersuchen Sie die
transactions-Quelldaten.Dieses Notebook verwendet Beispieldaten, die in einem öffentlich zugänglichen Blobcontainer gehostet werden. Es kann nur mit einem
wasbs-Treiber in Spark eingelesen werden. Wenn Sie Featuresätze mit Ihren eigenen Quelldaten erstellen, hosten Sie diese in einem Azure Data Lake Storage Gen2-Konto, und verwenden Sie einenabfss-Treiber im Datenpfad.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueEntwickeln Sie den Featuresatz lokal.
Eine Featuresatzspezifikation ist eine eigenständige Definition eines Featuresatzes, die Sie lokal entwickeln und testen können. Hier erstellen Sie die folgenden Features für rollierende Zeitfensteraggregationen:
transactions three-day counttransactions amount three-day sumtransactions amount three-day avgtransactions seven-day counttransactions amount seven-day sumtransactions amount seven-day avg
Überprüfen Sie die Codedatei für die Featuretransformation: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Beachten Sie die für die Features definierte rollierende Aggregation. Dies ist ein Spark-Transformator.
Weitere Informationen zum Featuresatz und zu den Transformationen finden Sie unter Was ist der verwaltete Feature Store?.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Exportieren Sie die Featuresatzspezifikation.
Um die Featuresatzspezifikation beim Feature Store zu registrieren, müssen Sie diese Featuresatzspezifikation in einem bestimmten Format speichern.
Überprüfen Sie die Spezifikation des generierten
transactions-Featuresatzes. Um die Spezifikation anzuzeigen, öffnen Sie die Datei featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml.Die Spezifikation enthält die folgenden Elemente:
source: ein Verweis auf eine Speicherressource. In diesem Fall handelt es sich um eine Parquet-Datei in einer Blob Storage-Ressource.features: eine Liste der Features und ihrer Datentypen. Wenn Sie Transformationscode bereitstellen, muss der Code einen DataFrame zurückgeben, der den Features und Datentypen entspricht.index_columns: die Joinschlüssel, die für den Zugriff auf Werte aus der Funktionsgruppe erforderlich sind.
Weitere Informationen zur Spezifikation finden Sie unter Grundlegendes zu Entitäten auf oberster Ebene im verwalteten Feature Store und YAML-Schema für die Featuresatzspezifikation der CLI (v2).
Das Beibehalten der Featuresatzspezifikation bietet einen weiteren Vorteil: Für die Featuresatzspezifikation kann die Quellcodeverwaltung verwendet werden.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Registrieren einer Feature Store-Entität
Als bewährte Methode helfen Entitäten dabei, die Verwendung derselben Joinschlüsseldefinition für Funktionsgruppen zu erzwingen, die dieselben logischen Entitäten verwenden. Beispiele für Entitäten sind Konten und Kund*innen. Entitäten werden in der Regel einmal erstellt und dann in Featuresätzen wiederverwendet. Weitere Informationen finden Sie unter Grundlegendes zu Entitäten auf oberster Ebene im verwalteten Feature Store.
Initialisieren Sie den CRUD-Client für den Feature Store.
Wie weiter oben in diesem Tutorial erläutert, wird
MLClientzum Erstellen, Lesen, Aktualisieren und Löschen von Feature Store-Ressourcen verwendet. Das hier gezeigte Beispiel einer Notebookcodezelle sucht nach dem Feature Store, den Sie in einem früheren Schritt erstellt haben. Hier können Sie nicht denselbenml_client-Wert wiederverwenden, den Sie zuvor in diesem Tutorial verwendet haben, da dieser auf Ressourcengruppenebene festgelegt ist. Die ordnungsgemäße Eingrenzung ist eine Voraussetzung für die Erstellung des Feature Stores.In diesem Codebeispiel wird der Client auf Feature Store-Ebene festgelegt.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Registrieren Sie die
account-Entität beim Feature Store.Erstellen Sie eine
account-Entität mit dem JoinschlüsselaccountIDvom Typstring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Registrieren des Transaktionsfeaturesatzes beim Feature Store
Verwenden Sie diesen Code, um ein Feature-Set-Asset im Feature Store zu registrieren. Sie können diese Ressource dann wiederverwenden und problemlos freigeben. Die Registrierung einer Featuresatzressource bietet verwaltete Funktionen, einschließlich Versionsverwaltung und Materialisierung. Später in dieser Tutorialreihe werden die verwalteten Funktionen behandelt.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Erkunden der Benutzeroberfläche des Feature Stores
Die Erstellung und Aktualisierung von Feature Store-Ressourcen können nur über das SDK und die CLI erfolgen. Sie können die Benutzeroberfläche verwenden, um den Feature Store zu durchsuchen:
- Öffnen Sie die globale Landing Page von Azure Machine Learning.
- Wählen Sie im linken Bereich Feature Stores aus.
- Wählen Sie in der Liste der zugänglichen Feature Stores den Feature Store aus, den Sie zuvor in diesem Tutorial erstellt haben.
Gewähren des Zugriffs für die Rolle „Leser von Storage Blob-Daten“ auf Ihr Benutzerkonto im Offlinespeicher
Die Rolle Storage Blob Data Reader muss Ihrem Benutzerkonto auf dem Offline-Speicher zugewiesen sein. Dadurch wird sichergestellt, dass das Benutzerkonto materialisierte Merkmalsdaten aus dem Offline-Materialisierungsspeicher lesen kann.
Beziehen Sie den Wert Ihrer Microsoft Entra-Objekt-ID aus dem Azure-Portal wie unter Suchen der Benutzerobjekt-ID beschrieben.
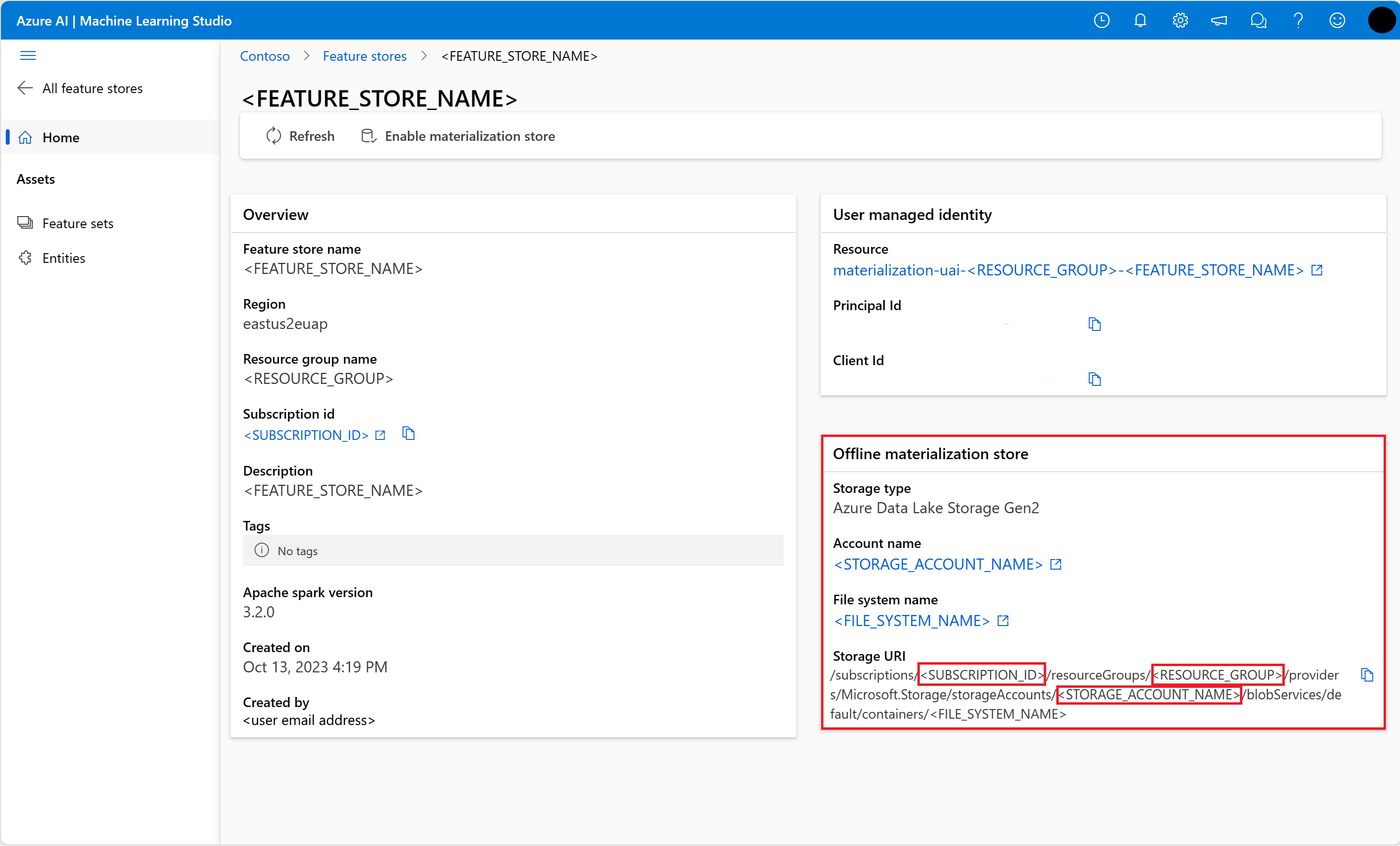
Informationen über den Offline-Materialisierungsspeicher erhalten Sie auf der Seite Feature Store Overview in der Feature Store UI. Die Werte für die Speicherkonto-Abonnement-ID, den Namen der Speicherkonto-Ressourcengruppe und den Namen des Speicherkontos für den Offline-Materialisierungsspeicher finden Sie auf der Karte Offline-Materialisierungsspeicher.
Weitere Informationen zur Zugriffskontrolle finden Sie unter Verwalten der Zugriffskontrolle für verwaltete Feature Stores.
Führen Sie diese Codezelle für die Rollenzuweisung aus. Es kann einige Zeit dauern, bis sich die Genehmigungen durchsetzen.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Generieren eines Datenrahmens für Trainingsdaten mithilfe des registrierten Featuresatzes
Laden Sie Beobachtungsdaten.
Beobachtungsdaten umfassen in der Regel die Kerndaten, die beim Training und bei Rückschlüssen verwendet werden. Diese Daten werden mit den Featuredaten verknüpft, um die vollständige Trainingsdatenressource zu erstellen.
Beobachtungsdaten sind Daten, die während des Ereignisses selbst erfasst werden. Hier enthalten sie wichtige Transaktionsdaten, einschließlich Transaktions-ID, Konto-ID und Transaktionsbeträgen. Da Sie diese für das Training verwenden, wird auch die Zielvariable (is_fraud) angefügt.
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueRufen Sie den registrierten Featuresatz ab, und listen Sie seine Features auf.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Wählen Sie die Features aus, die Teil der Trainingsdaten werden. Verwenden Sie anschließend das Feature Store SDK, um die Trainingsdaten selbst zu generieren.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueEin Zeitpunktjoin fügt die Features an die Trainingsdaten an.
Aktivieren der Offline-Materialisierung für das Feature-Set transactions
Nachdem die Feature-Set-Materialisierung aktiviert wurde, können Sie eine Rückverfüllung durchführen. Sie können auch wiederkehrende Materialisierungsaufträge planen. Weitere Informationen finden Sie im dritten Tutorial der Reihe.
Legen Sie spark.sql.shuffle.partitions in der yaml-Datei entsprechend der Größe der Feature-Daten fest.
Die Spark-Konfiguration spark.sql.shuffle.partitions ist ein OPTIONALER Parameter, der die Anzahl der (pro Tag) erzeugten Parkettdateien beeinflussen kann, wenn der Featuresatz im Offline-Speicher materialisiert wird. Der Standardwert dieses Parameters ist 200. Als bewährte Methode sollten Sie die Erzeugung vieler kleiner Parkettdateien vermeiden. Wenn der Abruf von Offline-Features nach der Materialisierung von Features langsam wird, gehen Sie zu dem entsprechenden Ordner im Offline-Speicher, um zu prüfen, ob das Problem mit zu vielen kleinen Parkettdateien (pro Tag) zusammenhängt, und passen Sie den Wert dieses Parameters entsprechend an.
Hinweis
Die in diesem Notebook verwendeten Beispieldaten sind klein. Daher wird dieser Parameter in der Datei featureset_asset_offline_enabled.yaml auf 1 gesetzt.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())Sie können das Feature-Set-Asset auch als YAML-Ressource speichern.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Backfill-Daten für den Merkmalsatz transactions
Wie bereits erläutert, berechnet die Materialisierung die Merkmalswerte für ein Merkmalsfenster und speichert diese berechneten Werte in einem Materialisierungsspeicher. Die Featurematerialisierung erhöht die Zuverlässigkeit und Verfügbarkeit der berechneten Werte. Alle Featureabfragen verwenden nun die Werte aus dem Materialisierungsspeicher. In diesem Schritt wird ein einmaliges Backfill für ein Feature-Fenster von 18 Monaten durchgeführt.
Hinweis
Möglicherweise müssen Sie einen Wert für das Backfill-Datenfenster festlegen. Das Fenster muss mit dem Fenster Ihrer Trainingsdaten übereinstimmen. Um beispielsweise 18 Monate an Daten für das Training zu verwenden, müssen Sie Merkmale für 18 Monate abrufen. Das bedeutet, dass Sie für ein 18-monatiges Zeitfenster aufstocken sollten.
Diese Codezelle materialisiert Daten nach aktuellem Status Keine oder Unvollständig für das definierte Merkmalsfenster.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Tipp
- Die
timestamp-Spalte sollte dem Formatyyyy-MM-ddTHH:mm:ss.fffZfolgen. - Die
feature_window_start_timeundfeature_window_end_timeGranularität ist auf Sekunden begrenzt. Alle im Objektdatetimeangegebenen Millisekunden werden ignoriert. - Ein Materialisierungsauftrag wird nur dann übermittelt, wenn die Daten im Feature-Fenster mit den
data_statusübereinstimmen, die bei der Übermittlung des Backfill-Auftrags definiert wurden.
Drucken Sie Beispieldaten aus dem Feature-Set. Die Ausgabeinformationen zeigen, dass die Daten aus dem Materialisierungsspeicher abgerufen wurden. Die get_offline_features()-Methode hat die Trainings- und Rückschlussdaten abgerufen. Sie verwendet standardmäßig auch den Materialisierungsspeicher.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Weitere Untersuchung der Offline-Materialisierung von Merkmalen
Sie können den Feature-Materialisierungsstatus für ein Feature-Set in der Materialisierungsaufträge BENUTZEROBERFLÄCHE.
Öffnen Sie die globale Landing Page von Azure Machine Learning.
Wählen Sie im linken Bereich Feature Stores aus.
Wählen Sie aus der Liste der zugänglichen Feature-Stores den Feature-Store aus, für den Sie das Backfill durchgeführt haben.
Wählen Sie die Registerkarte Materialisierungsaufträge.
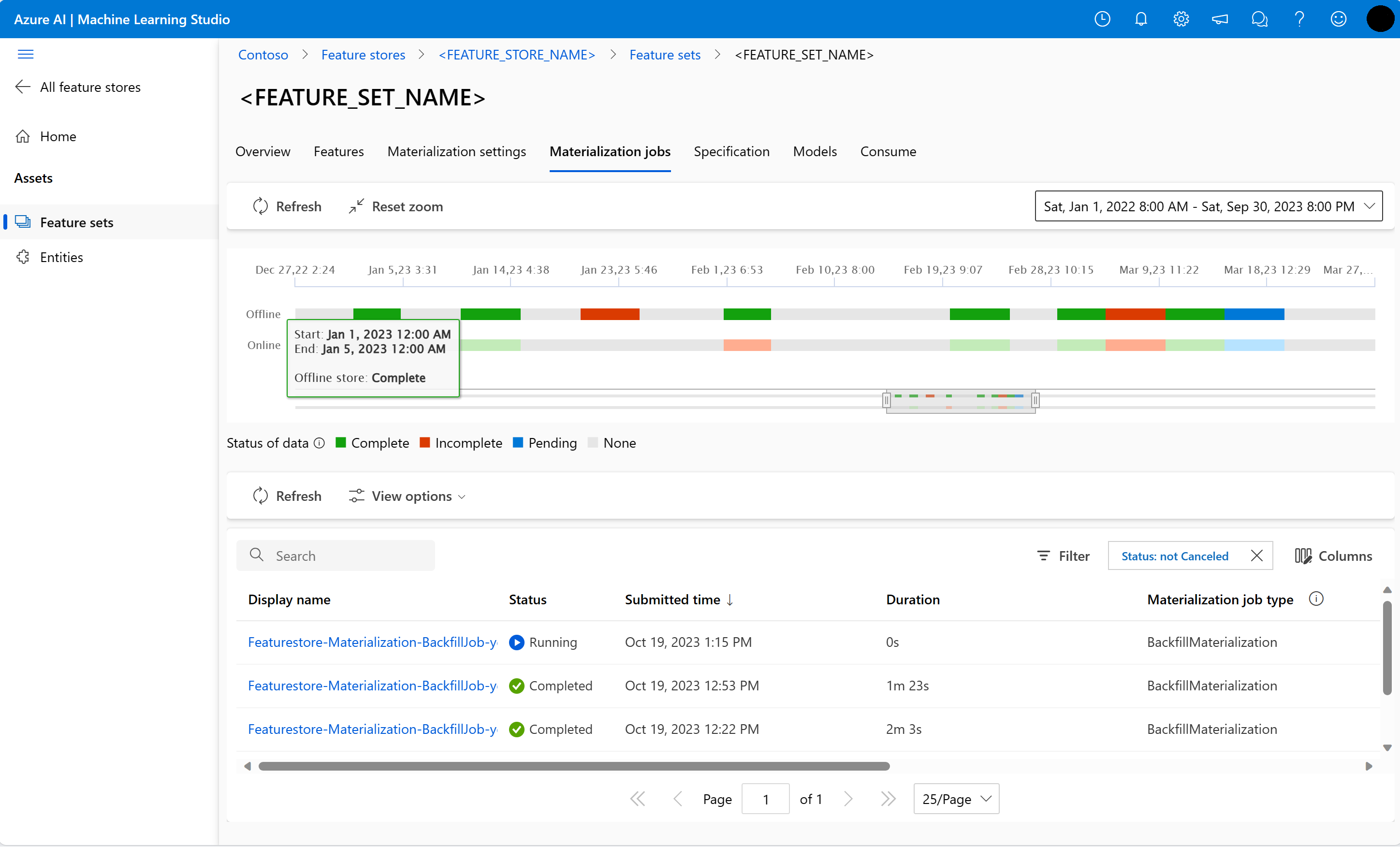

Der Status der Datenmaterialisierung kann sein
- Vollständig (grün)
- Unvollständig (rot)
- Anhängig (blau)
- Keiner (grau)
Ein Datenintervall stellt einen zusammenhängenden Teil von Daten mit demselben Datenmaterialisierungsstatus dar. Der frühere Snapshot hat zum Beispiel 16 Datenintervalle im Offline-Materialisierungsspeicher.
Die Daten können maximal 2.000 Datenintervalle haben. Wenn Ihre Daten mehr als 2.000 Datenintervalle enthalten, erstellen Sie eine neue Feature-Set-Version.
Sie können eine Liste mit mehreren Datenstatus (z. B.
["None", "Incomplete"]) in einem einzigen Backfill-Auftrag angeben.Beim Backfill wird für jedes Datenintervall, das in das definierte Feature-Fenster fällt, ein neuer Materialisierungsauftrag eingereicht.
Wenn ein Materialisierungsauftrag anhängig ist oder dieser Auftrag für ein Datenintervall läuft, das noch nicht wieder aufgefüllt wurde, wird für dieses Datenintervall kein neuer Auftrag eingereicht.
Sie können einen fehlgeschlagenen Materialisierungsauftrag wiederholen.
Hinweis
So erhalten Sie die Job-ID eines fehlgeschlagenen Materialisierungsauftrags:
- Navigieren Sie zum Feature-Set Materialisierungsaufträge BENUTZEROBERFLÄCHE.
- Wählen Sie den Anzeigenamen eines bestimmten Auftrags mit Status von Fehlgeschlagen.
- Suchen Sie die Auftragskennung unter der Eigenschaft Name auf der Auftragsseite Übersicht. Sie beginnt mit
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Aktualisierung des Offline-Materialisierungsspeichers
- Wenn ein Offline-Materialisierungsspeicher auf der Ebene des Feature-Speichers aktualisiert werden muss, sollte die Offline-Materialisierung für alle Feature-Sets im Feature-Speicher deaktiviert werden.
- Wenn die Offline-Materialisierung für ein Feature-Set deaktiviert ist, wird der Materialisierungsstatus der bereits im Offline-Materialisierungsspeicher materialisierten Daten zurückgesetzt. Durch das Zurücksetzen werden bereits materialisierte Daten unbrauchbar gemacht. Nach der Aktivierung der Offline-Materialisierung müssen Sie die Materialisierungsaufträge erneut einreichen.
In diesem Lernprogramm wurden die Trainingsdaten mit Merkmalen aus dem Merkmalsspeicher erstellt, die Materialisierung in den Offline-Merkmalsspeicher aktiviert und ein Backfill durchgeführt. Als Nächstes führen Sie ein Modelltraining mit diesen Merkmalen durch.
Bereinigen
Das fünfte Tutorial der Reihe beschreibt, wie Sie die Ressourcen löschen.
Nächste Schritte
- Siehe das nächste Tutorial in dieser Reihe: Experimentieren und trainieren Sie Modelle mit Hilfe von Merkmalen.
- Erfahren Sie mehr über Konzepte von Feature Stores und Grundlegendes zu Entitäten auf oberster Ebene im verwalteten Feature Store.
- Erfahren Sie mehr über die Identitäts- und Zugriffssteuerung für verwaltete Feature Stores.
- Sehen Sie sich den Leitfaden zur Problembehandlung für verwaltete Feature Stores an.
- Lesen Sie die YAML-Referenz.