Tutorial: Trainieren Ihres ersten Machine Learning-Modells (SDK v1, Teil 2 von 3)
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Tutorial wird gezeigt, wie Sie ein Machine Learning-Modell in Azure Machine Learning trainieren. Dieses Tutorial ist der zweite Teil einer zweiteiligen Tutorialreihe.
In Teil 1: Ausführen von „Hello World!“ der Reihe haben Sie erfahren, wie Sie ein Steuerungsskript verwenden, um einen Auftrag in der Cloud auszuführen.
In diesem Tutorial führen Sie den nächsten Schritt aus, indem Sie ein Skript senden, das ein Machine Learning-Modell trainiert. Dieses Beispiel hilft Ihnen zu verstehen, wie Azure Machine Learning ein konsistentes Verhalten zwischen lokalem Debuggen und Remoteausführungen erleichtert.
In diesem Tutorial führen Sie Folgendes durch:
- Erstellen Sie ein Trainingsskript.
- Definieren einer Azure Machine Learning-Umgebung mit Conda
- Erstellen eines Steuerungsskripts
- Kennenlernen der Azure Machine Learning-Klassen (
Environment,Run,Metrics) - Senden und Ausführen des Trainingsskripts
- Anzeigen Ihrer Codeausgabe in der Cloud
- Protokollieren von Metriken in Azure Machine Learning
- Anzeigen der Metriken in der Cloud
Voraussetzungen
- Durcharbeitung von Teil 1 der Reihe.
Erstellen der Trainingsskripts
Zuerst definieren Sie die Architektur des neuronalen Netzes in der Datei model.py. Der gesamte Trainingscode wird im Unterverzeichnis src gespeichert (einschließlich model.py).
Der Trainingscode stammt aus diesem Einführungsbeispiel von PyTorch. Die Azure Machine Learning-Konzepte gelten für beliebigen Machine Learning-Code und nicht nur für PyTorch.
Erstellen Sie die Datei model.py im Unterordner src. Kopieren Sie diesen Code in die Datei:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xWählen Sie in der Symbolleiste die Option Speichern aus, um die Datei zu speichern. Schließen Sie die Registerkarte, wenn Sie möchten.
Definieren Sie als Nächstes ebenfalls im Unterordner src das Trainingsskript. Mit diesem Skript wird das CIFAR10-Dataset mithilfe der
torchvision.dataset-APIs von PyTorch heruntergeladen, das in model.py definierte Netzwerk eingerichtet und zwei Epochen lang das Training mit Standard-SGD und Kreuzentropieverlust durchgeführt.Erstellen Sie im Unterordner src das Skript train.py:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Sie verfügen jetzt über die folgende Ordnerstruktur:
Lokales Testen
Wählen Sie die Option Save and run script in terminal (Skript speichern und im Terminal ausführen) aus, um das Skript train.py direkt auf der Compute-Instanz auszuführen.
Klicken Sie nach Abschluss des Skripts oberhalb der Dateiordner auf Aktualisieren. Der neue Datenordner mit dem Namen get-started/data wird angezeigt. Erweitern Sie diesen Ordner, um die heruntergeladenen Daten anzuzeigen.
Erstellen einer Python-Umgebung
Bei Azure Machine Learning wird das Konzept einer Umgebung verwendet, um eine reproduzierbare versionierte Python-Umgebung zum Ausführen von Experimenten darzustellen. Eine Umgebung kann ganz einfach aus einer lokalen Conda- oder PIP-Umgebung erstellt werden.
Zunächst erstellen Sie eine Datei mit den Paketabhängigkeiten.
Erstellen Sie im Ordner get-started eine neue Datei mit dem Namen
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionWählen Sie in der Symbolleiste die Option Speichern aus, um die Datei zu speichern. Schließen Sie die Registerkarte, wenn Sie möchten.
Erstellen des Steuerungsskripts
Der Unterschied zwischen dem folgenden Steuerskript und dem zum Senden von „Hallo Welt“ verwendeten besteht darin, dass Sie einige zusätzliche Zeilen hinzufügen, um die Umgebung festzulegen.
Erstellen Sie im Ordner get-started eine neue Python-Datei mit dem Namen run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Tipp
Wenn Sie beim Erstellen ihres Computeclusters einen anderen Namen verwendet haben, stellen Sie sicher, dass Sie auch den Namen im Code compute_target='cpu-cluster' anpassen.
Erläuterung der Codeänderungen
env = ...
Verweist auf die Abhängigkeitsdatei, die Sie oben erstellt haben.
config.run_config.environment = env
Fügt die Umgebung der ScriptRunConfig-Klasse hinzu.
Senden der Ausführung an Azure Machine Learning
Wählen Sie Save and run script in terminal (Skript speichern und im Terminal ausführen) aus, um das Skript run-pytorch.py auszuführen.
In dem sich öffnenden Terminalfenster wird ein Link angezeigt. Wählen Sie den Link aus, um den Auftrag anzuzeigen.
Hinweis
Möglicherweise werden einige Warnungen angezeigt, die mit Failure while loading azureml_run_type_providers... (Fehler beim Laden von azureml_run_type_providers...) beginnen. Sie können diese Warnungen ignorieren. Zeigen Sie Ihre Ausgabe über den Link am unteren Rand dieser Warnungen an.
Anzeigen der Ausgabe
- Auf der sich öffnenden Seite sehen Sie den Auftragsstatus. Wenn Sie dieses Skript zum ersten Mal ausführen, erstellt Azure Machine Learning ein neues Docker-Image aus Ihrer PyTorch-Umgebung. Der gesamte Auftrag kann etwa 10 Minuten in Anspruch nehmen. Dieses Image wird auch in zukünftigen Aufträgen verwendet, um die Dauer deutlich zu verkürzen.
- Die Docker-Buildprotokolle werden in Azure Machine Learning Studio angezeigt. so zeigen Sie die Buildprotokolle an:
- Wählen Sie die Registerkarte Ausgaben + Protokolle aus.
- Wählen Sie den Ordner azureml-logs aus.
- Wählen Sie 20_image_build_log.txt aus.
- Wenn der Auftragsstatus Abgeschlossen lautet, wählen Sie Ausgabe und Protokolle aus.
- Wählen Sie user_logs und dann std_log.txt aus, um die Ausgabe Ihres Auftrags anzuzeigen.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Wenn ein Fehler vom Typ Your total snapshot size exceeds the limit (Gesamtgröße der Momentaufnahme überschreitet den Grenzwert) angezeigt wird, befindet sich der Ordner data unter dem Wert source_directory, der in ScriptRunConfig verwendet wird.
Wählen Sie am Ende des Ordners die Auslassungszeichen ( ... ) und dann die Option Verschieben aus, um data in den Ordner get-started zu verschieben.
Protokollieren von Trainingsmetriken
Nachdem Sie nun über ein Modelltraining in Azure Machine Learning verfügen, beginnen Sie mit dem Nachverfolgen einiger Leistungsmetriken.
Das aktuelle Trainingsskript gibt Metriken auf dem Terminal aus. Azure Machine Learning bietet einen Mechanismus zum Protokollieren von Metriken mit weiteren Funktionen. Durch Hinzufügen von wenigen Codezeilen können Sie Metriken in Studio visualisieren und Metriken aus mehreren Aufträgen vergleichen.
Ändern von train.py zur Einbindung der Protokollierung
Erweitern Sie Ihr Skript train.py um zwei weitere Codezeilen:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Speichern Sie diese Datei, und schließen Sie die Registerkarte, wenn Sie möchten.
Erläuterungen zu den beiden zusätzlichen Codezeilen
In train.py greifen Sie innerhalb des Trainingsskripts selbst mit der Methode Run.get_context() auf das Run-Objekt zu und verwenden es zum Protokollieren der Metriken:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Vorteile der Metriken in Azure Machine Learning:
- Metriken sind nach Experiment und Ausführung strukturiert und können daher leicht nachverfolgt und verglichen werden.
- Sie verfügen über eine Benutzeroberfläche zur Visualisierung der Trainingsleistung in Studio.
- Sie sind skalierbar konzipiert, sodass Sie auch bei Hunderten von Experimenten von diesen Vorteilen profitieren.
Aktualisieren der Conda-Umgebungsdatei
Das train.py-Skript weist eine neue Abhängigkeit von azureml.core auf. Aktualisieren Sie pytorch-env.yml, sodass diese Änderung widergespiegelt wird:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Stellen Sie sicher, dass Sie diese Datei speichern, bevor Sie die Ausführung übermitteln.
Senden der Ausführung an Azure Machine Learning
Wählen Sie die Registerkarte für das Skript run-pytorch.py und dann die Option Skript speichern und im Terminal ausführen aus, um das Skript run-pytorch.py erneut auszuführen. Stellen Sie zunächst sicher, dass Sie ihre Änderungen in pytorch-env.ymlspeichern.
Bei diesem Zugriff auf Studio öffnen Sie die Registerkarte Metriken, auf der nun Liveupdates zum Modelltrainingsverlust angezeigt werden. Es kann ein bis zwei Minuten dauern, bis das Training beginnt.
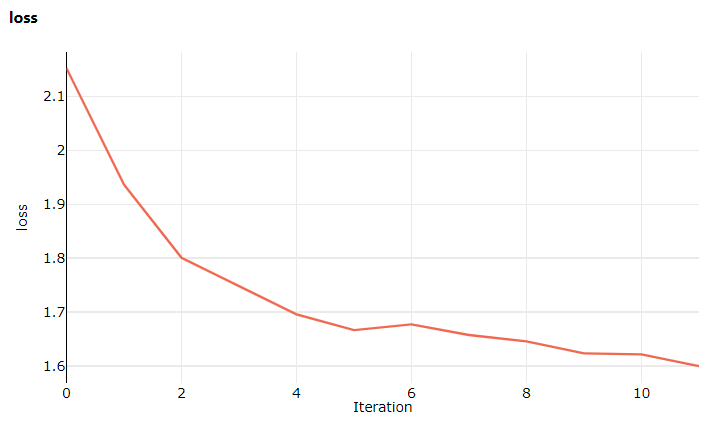
Bereinigen von Ressourcen
Wenn Sie beabsichtigen, jetzt mit einem anderen Tutorial fortzufahren oder Ihre eigenen Trainingsaufträge zu starten, fahren Sie mit Ähnliche Ressourcen.
Beenden der Compute-Instanz
Wenn Sie die Compute-Instanz jetzt nicht verwenden möchten, beenden Sie sie:
- Wählen Sie in Studio auf der linken Seite Compute aus.
- Wählen Sie auf den oberen Registerkarten Compute-Instanzen aus.
- Wählen Sie in der Liste die Compute-Instanz aus.
- Wählen Sie auf der oberen Symbolleiste Beenden aus.
Löschen aller Ressourcen
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Geben Sie im Azure-Portal den Suchbegriff Ressourcengruppen in das Suchfeld ein, und wählen Sie in den Ergebnissen die entsprechende Option aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie auf der Seite Übersicht die Option Ressourcengruppe löschen aus.
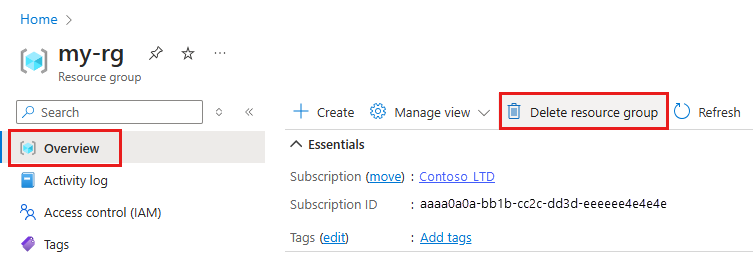
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Sie können die Ressourcengruppe auch behalten und einen einzelnen Arbeitsbereich löschen. Zeigen Sie die Eigenschaften des Arbeitsbereichs an, und klicken Sie auf Löschen.
Zugehörige Ressourcen
In dieser Sitzung haben Sie ein Upgrade von einem einfachen Hallo Welt!-Skript auf ein realistischeres Trainingsskript durchgeführt, für das eine bestimmte Python-Umgebung ausgeführt werden musste. Sie haben erfahren, wie Sie zusammengestellte Azure Machine Learning-Umgebungen verwenden. Schließlich haben Sie erfahren, wie Sie mit einigen wenigen Codezeilen Metriken für Azure Machine Learning protokollieren können.
Es gibt weitere Möglichkeiten, Azure Machine Learning-Umgebungen zu erstellen, z. B. mit der PIP-Datei „requirements.txt“ oder aus einer vorhandenen lokalen Conda-Umgebung.