Verwalten einer Promptflow-Computesitzung in Azure Machine Learning Studio
Eine Promptflow-Computesitzung stellt Computerressourcen bereit, die für die Ausführung der Anwendung erforderlich sind (einschließlich eines Docker-Images, das alle erforderlichen Abhängigkeitspakete enthält). Diese zuverlässige und skalierbare Umgebung ermöglicht dem Promptflow die effiziente Ausführung von Aufgaben und Funktionen für eine nahtlose Nutzung.
Berechtigungen und Rollen für die Computesitzungsverwaltung
Für das Zuweisen von Rollen müssen Sie über die Berechtigung owner oder Microsoft.Authorization/roleAssignments/write für die Ressource verfügen.
Weisen Sie Benutzern der Computesitzung die AzureML Data Scientist-Rolle im Arbeitsbereich zu. Weitere Informationen finden Sie unter Verwalten des Zugriffs auf einen Azure Machine Learning-Arbeitsbereich.
Die Rollenzuweisung kann mehrere Minuten benötigen, um in Kraft zu treten.
Starten einer Computesitzung in Studio
Bevor Sie Azure Machine Learning Studio verwenden, um eine Computesitzung zu starten, sollten Sie Folgendes sicherstellen:
- Sie verfügen über die Rolle
AzureML Data Scientistim Arbeitsbereich. - Der Standarddatenspeicher (normalerweise
workspaceblobstore) in Ihrem Arbeitsbereich ist der Blob-Typ. - Das Arbeitsverzeichnis (
workspaceworkingdirectory) ist im Arbeitsbereich vorhanden. - Wenn Sie ein virtuelles Netzwerk für den Prompt Flow verwenden, verstehen Sie die Überlegungen unter Netzwerkisolation in Prompt Flow.
Starten einer Computesitzung auf einer Flowseite
Ein Flow ist an eine Computesitzung gebunden. Sie können eine Computesitzung auf einer Flowseite starten.
Wählen Sie Start aus. Starten Sie eine Computesitzung, indem Sie die in
flow.dag.yamlim Flowordner definierte Umgebung verwenden. Sie wird auf einer VM der Größe „Serverloses Computing“ ausgeführt, für die Sie über ein ausreichendes Kontingent im Arbeitsbereich verfügen.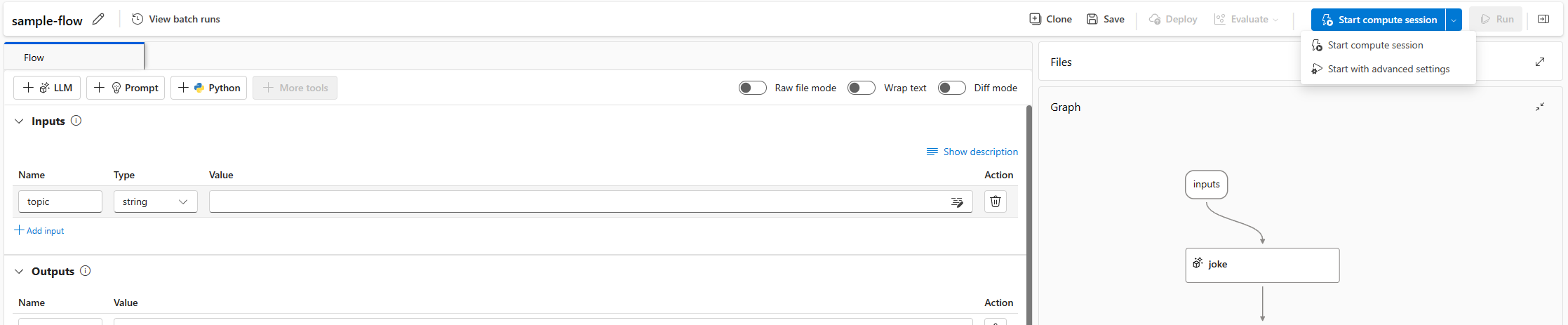
Wählen Sie Mit erweiterten Einstellungen beginnen aus. In den erweiterten Einstellungen haben Sie folgende Möglichkeiten:
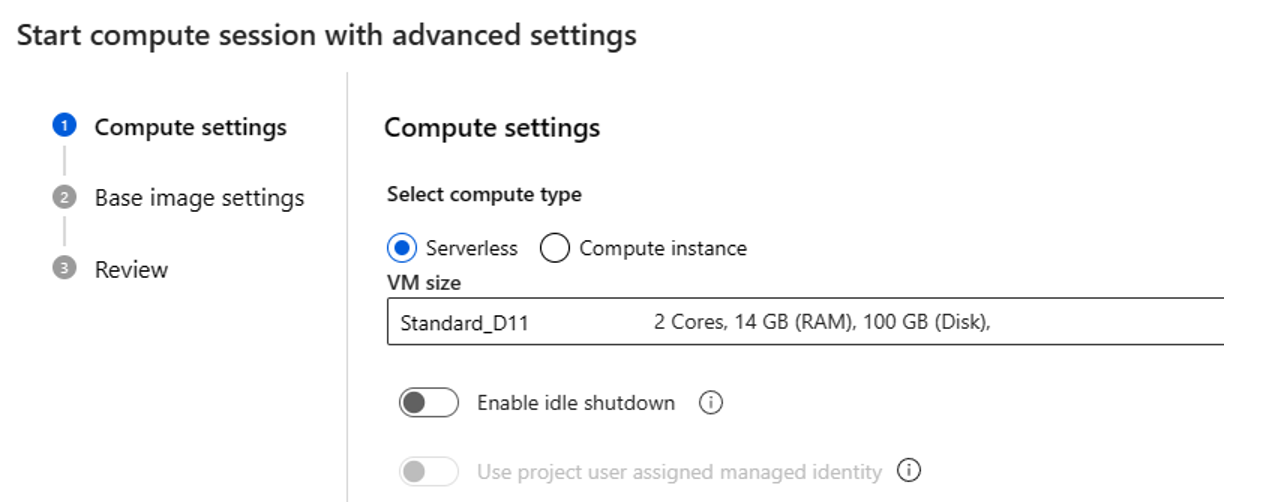
- Wählen Sie einen Compute-Typ aus. Sie können zwischen serverlosem Computing und einer Compute-Instanz auswählen.
Wenn Sie serverloses Computing auswählen, können Sie die folgenden Einstellungen festlegen:
- Passen Sie die Größe der VM an, die die Computesitzung verwendet. Verwenden Sie die VM-Serie D oder höher. Weitere Informationen finden Sie im Abschnitt Unterstützte VM-Serien und -Größen.
- Passen Sie die Leerlaufzeit an, die die Computesitzung automatisch löscht, wenn sie für eine Weile nicht verwendet wird.
- Legen Sie die benutzerseitig zugewiesene verwaltete Identität fest. Die Computesitzung verwendet diese Identität, um ein Basisimage zu pullen, eine Verbindung zu authentifizieren und Pakete zu installieren. Stellen Sie sicher, dass die benutzerseitig zugewiesene verwaltete Identität über die ausreichenden Berechtigungen verfügt. Wenn Sie diese Identität nicht festlegen, verwenden wir standardmäßig die Benutzeridentität.
- Sie können den folgenden CLI-Befehl verwenden, um dem Arbeitsbereich die benutzerseitig zugewiesene verwaltete Identität zuzuweisen. Erfahren Sie mehr über das Erstellen und Aktualisieren von benutzerseitig zugewiesenen Identitäten für den Arbeitsbereich..
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Der Inhalt der Datei workspace_update_with_multiple_UAIs.yml lautet wie folgt:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Tipp
Die folgenden Azure RBAC-Rollenzuweisungen sind für Ihre benutzerseitig zugewiesene verwaltete Identität für Ihren Azure Machine Learning-Arbeitsbereich erforderlich, um auf Daten in den mit dem Arbeitsbereich verbundenen Ressourcen zuzugreifen.
Resource Berechtigung Azure Machine Learning-Arbeitsbereich Mitwirkender Azure Storage Mitwirkende (Steuerungsebene) + Mitwirkende an Speicherblobdaten + privilegierte Mitwirkende für Speicherdateidaten (Datenebene, Flowentwurf in Dateifreigabe und Daten im Blob nutzen) Azure Key Vault (bei Verwendung des Berechtigungsmodells für Zugriffsrichtlinien) Mitwirkender und alle Zugriffsrichtlinienberechtigungen außer Vorgänge zum Löschen, dies ist der Standardmodus für eine verknüpfte Azure Key Vault-Instanz. Azure Key Vault (bei Verwendung des RBAC-Berechtigungsmodells) Mitwirkender (Steuerungsebene) + Key Vault-Administrator (Datenebene) Azure Container Registry Mitwirkender Azure Application Insights Mitwirkender Hinweis
Der Auftragsübermittler benötigt die Berechtigung
assignfür die benutzerseitig zugewiesene verwaltete Identität, Sie können die RolleManaged Identity Operatorzuweisen, da jedes Mal, wenn eine serverlose Computingsitzung erstellt wird, der Compute eine benutzerseitig zugewiesene verwaltete Identität zugewiesen wird.Wenn Sie die Compute-Instanz als Computetyp auswählen, können Sie nur die Leerlaufzeit für das Herunterfahren festlegen.
Da die Ausführung auf einer vorhandenen Compute-Instanz erfolgt, ist die VM-Größe festgelegt und kann sitzungsseitig nicht geändert werden.
Die für diese Sitzung verwendete Identität wird auch in der Compute-Instanz definiert. Standardmäßig wird die Benutzeridentität verwendet. Erfahren Sie mehr über das Zuweisen einer Identität zu einer Compute-Instanz
Für die Leerlaufzeit zum Herunterfahren wird sie verwendet, um den Lebenszyklus der Computesitzung zu definieren. Wenn sich die Sitzung für die von Ihnen festgelegte Zeit im Leerlauf befindet, wird sie automatisch gelöscht. Wenn Sie das Herunterfahren bei Leerlauf für die Compute-Instanz aktiviert haben, wird diese Regel auf Compute-Ebene wirksam.

Weitere Informationen finden Sie unter Erstellen und Verwalten von Compute-Instanzen.
- Wählen Sie einen Compute-Typ aus. Sie können zwischen serverlosem Computing und einer Compute-Instanz auswählen.



Verwenden einer Computesitzung zum Übermitteln einer Flowausführung über eine CLI bzw. ein SDK
Neben Studio können Sie die Computesitzung auch über eine CLI bzw. ein SDK festlegen, wenn Sie eine Flowausführung übermitteln.
Sie können auch den Instanztyp oder den Namen der Compute-Instanz unter dem Ressourcenteil angeben. Wenn Sie den Instanztyp oder den Namen der Compute-Instanz nicht angeben, wählt Azure Machine Learning basierend auf Faktoren wie Kontingent, Kosten, Leistung und Datenträgergröße einen Instanztyp (VM-Größe) aus. Erfahren Sie mehr über serverloses Computing.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Übermitteln Sie diese Ausführung über CLI:
pfazure run create --file run.yml
Hinweis
Die Leerlaufzeit bis zum Herunterfahren beträgt eine Stunde, wenn Sie eine CLI bzw. ein SDK verwenden, um eine Flowausführung zu übermitteln. Sie können zur Seite „Compute“ wechseln, um Compute freizugeben.
Verweisen auf Dateien außerhalb des Flowordners
Manchmal möchten Sie möglicherweise auf eine requirements.txt-Datei verweisen, die sich außerhalb des Fluw-Ordners befindet. Beispielsweise können Sie ein komplexes Projekt haben, das mehrere Flows enthält, die dieselbe requirements.txt-Datei gemeinsam nutzen. Dazu können Sie dieses Feld additional_includes in flow.dag.yaml hinzufügen. Der Wert dieses Felds ist eine Liste des relativen Datei-/Ordnerpfads zum Flow-Ordner. Wenn sich requirements.txt beispielsweise im übergeordneten Ordner des Flussordners befindet, können Sie das Feld ../requirements.txt in additional_includes hinzufügen.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
Die requirements.txt-Datei wird in den Flowordner kopiert und zum Starten der Computesitzung verwendet.
Aktualisieren einer Computesitzung auf der Flowseite in Studio
Auf einer Flowseite können Sie die folgenden Optionen zum Verwalten einer Computesitzung verwenden:
- Mit der Option zum Ändern der Computesitzungseinstellungen können Sie Compute-Einstellungen wie die VM-Größe und die benutzerseitig zugewiesene verwaltete Identität für serverloses Computing ändern. Wenn Sie eine Compute-Instanz verwenden, können Sie festlegen, dass eine andere Instanz verwendet werden soll. Sie können auch Folgendes ändern:
- Sie können auch die benutzerseitig zugewiesene verwaltete Identität für serverloses Computing ändern. Wenn Sie die VM-Größe ändern, wird die Computesitzung mit der neuen VM-Größe zurückgesetzt. Wenn Sie sich
- Installieren von Paketen aus requirements.txt: Öffnen Sie
requirements.txtauf der Promptflow-Benutzeroberfläche, um Pakete hinzuzufügen. - Mit Installierte Pakete anzeigen werden die Pakete angezeigt, die in der Computesitzung installiert sind. Dazu zählen die Pakete zum Installieren von Basisimages und Pakete, die in der
requirements.txt-Datei im Flowordner angegeben sind. - Durch das Zurücksetzen der Computesitzung wird die aktuelle Computesitzung gelöscht und eine neue Sitzung mit derselben Umgebung erstellt. Wenn ein Paketkonfliktproblem auftritt, können Sie diese Option ausprobieren.
- Durch das Beenden der Computesitzung wird die aktuelle Computesitzung gelöscht. Wenn keine aktive Computesitzung über die zugrunde liegende Compute ausgeführt wird, wird auch die serverlose Computeressource gelöscht.

Sie können auch die Umgebung anpassen, die Sie zum Ausführen dieses Flows verwenden, indem Sie Pakete in der requirements.txt-Datei im Flow-Ordner hinzufügen. Nachdem Sie weitere Pakete in dieser Datei hinzugefügt haben, können Sie eine der Optionen auswählen:
- Speichern und Installieren löst
pip install -r requirements.txtim Flow-Ordner aus. Der Vorgang kann je nach den Paketen, die Sie installieren, einige Minuten dauern. - Nur speichern speichert nur die
requirements.txt-Datei. Sie können die Pakete später selbst installieren.

Hinweis
Sie können den Speicherort und sogar den Dateinamen von requirements.txt ändern, aber stellen Sie sicher, dass Sie ihn auch in der flow.dag.yaml-Datei im Flow-Ordner ändern.
Heften Sie die Version von promptflow und promptflow-tools in requirements.txt nicht an, da sie bereits im Sitzungsbasisimage enthalten sind.
requirements.txt unterstützt keine lokalen WHL-Dateien. Erstellen Sie sie in Ihrem Image, und aktualisieren Sie das angepasste Basisimage in flow.dag.yaml. Weitere Informationen finden Sie unter Erstellen von benutzerdefinierten Basisimages.
Hinzufügen von Paketen in einem privaten Feed in Azure DevOps
Führen Sie die folgenden Schritte aus, wenn Sie einen privaten Feed in Azure DevOps verwenden möchten:
Weisen Sie dem Arbeitsbereich oder der Compute-Instanz eine verwaltete Identität zu.
Wenn Sie das serverlose Computing als Computesitzung verwenden, müssen Sie dem Arbeitsbereich eine benutzerseitig zugewiesene verwaltete Identität zuweisen.
Erstellen Sie eine benutzerseitig zugewiesene verwaltete Identität, und fügen Sie diese in der Azure DevOps-Organisation hinzu. Weitere Informationen finden Sie unter Verwenden von Dienstprinzipalen und verwalteten Identitäten.
Hinweis
Wenn die Schaltfläche Benutzer*in hinzufügen nicht sichtbar ist, verfügen Sie wahrscheinlich nicht über die erforderlichen Berechtigungen zum Ausführen dieser Aktion.
-
Hinweis
Stellen Sie sicher, dass die benutzerseitig zugewiesene verwaltete Identität über
Microsoft.KeyVault/vaults/readfür den mit dem Arbeitsbereich verknüpften Schlüsseltresor verfügt.
Wenn Sie die Compute-Instanz als Computesitzung verwenden, müssen Sie einer Compute-Instanz eine benutzerseitig zugewiesene verwaltete Identität zuweisen.
Fügen Sie
{private}zu Ihrer privaten Feed-URL hinzu. Wenn Sie beispielsweisetest_packageaustest_feedin Azure Devops installieren möchten, fügen Sie-i https://{private}@{test_feed_url_in_azure_devops}zurequirements.txthinzu:-i https://{private}@{test_feed_url_in_azure_devops} test_packageGeben Sie eine benutzerseitig zugewiesene verwaltete Identität in der Computesitzungskonfiguration an.
Geben Sie die benutzerseitig zugewiesene verwaltete Identität unter Mit erweiterten Einstellungen beginnen an, wenn Sie serverloses Computing verwenden und die Computesitzung nicht ausgeführt wird. Alternativ können Sie die Schaltfläche Computesitzungseinstellungen ändern verwenden, wenn die Computesitzung ausgeführt wird.
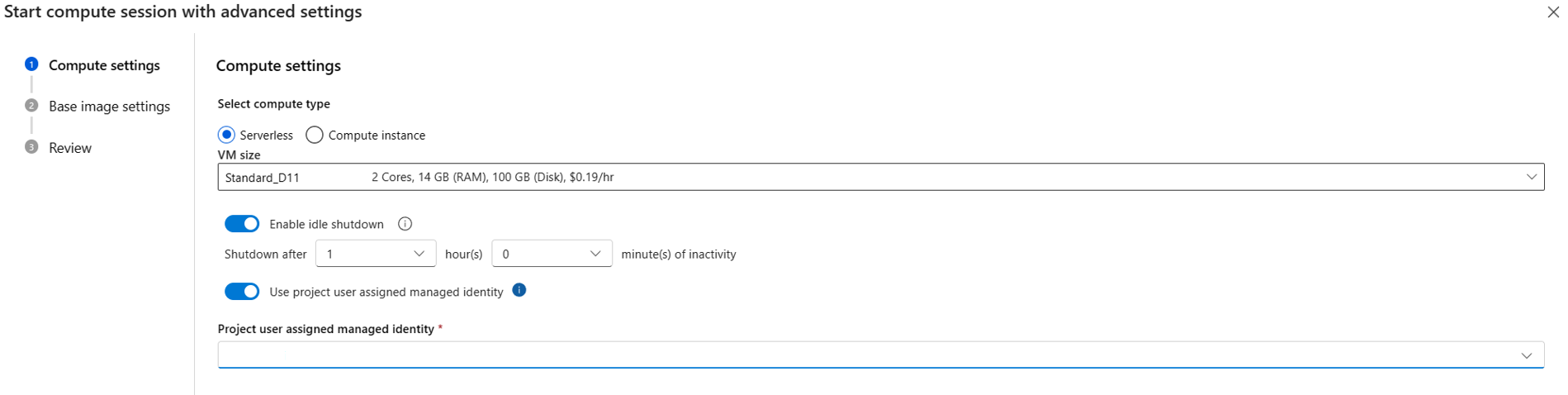
Wenn Sie eine Compute-Instanz verwenden, wird die benutzerseitig zugewiesene verwaltete Identität verwendet, die Sie der Compute-Instanz zugewiesen haben.

Hinweis
Dieser Ansatz konzentriert sich hauptsächlich auf schnelle Tests in der Entwicklungsphase des Flows; wenn Sie diesen Flow auch als Endpunkt bereitstellen möchten, erstellen Sie diesen privaten Feed in Ihrem Image, und aktualisieren Sie das Basisimage in flow.dag.yaml. Erfahren Sie mehr zum Erstellen von benutzerdefinierten Basisimages
Ändern des Basisimages für die Computesitzung
Standardmäßig wird das neueste Promptflow-Basisimage verwendet. Wenn Sie ein anderes Basisimage verwenden möchten, können Sie ein benutzerdefiniertes Basisimage erstellen.
- In Studio können Sie das Basisimage in den Basisimageeinstellungen in den Computesitzungseinstellungen ändern.

Sie können das neue Basisimage auch unter
environmentin derflow.dag.yaml-Datei im Flowordner angeben.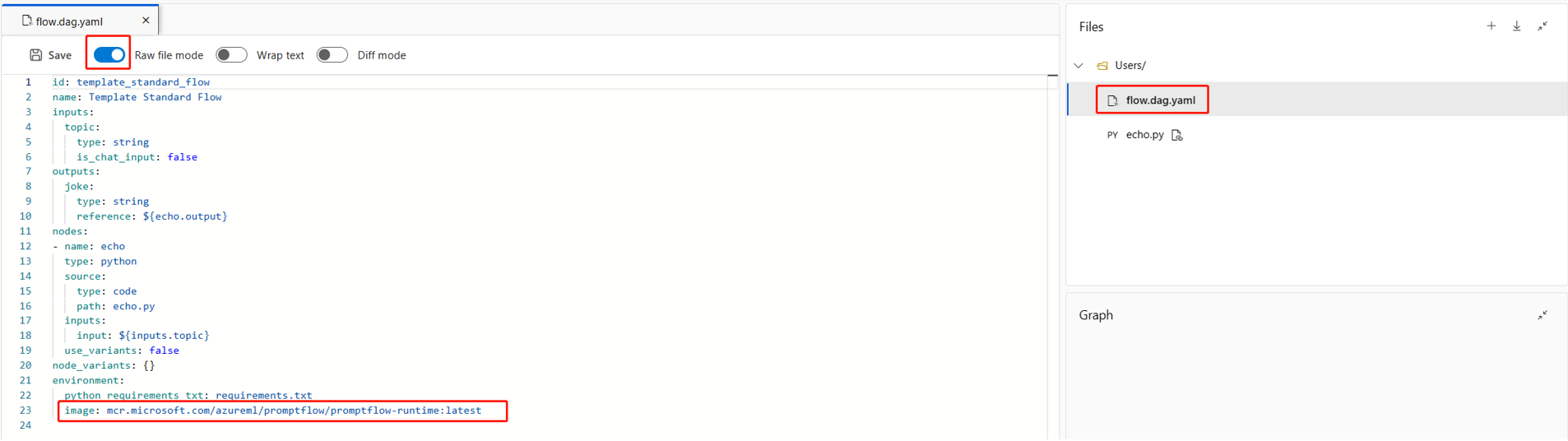
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Um das neue Basisimage verwenden zu können, müssen Sie die Computesitzung zurücksetzen. Dieser Vorgang dauert mehrere Minuten, da er das neue Basisimage abruft und Pakete neu installiert.
Verwalten der serverlosen Instanz, die von der Computesitzung verwendet wird
Wenn Sie serverloses Computing als Computesitzung verwenden, können Sie die serverlose Instanz verwalten. Zeigen Sie die serverlose Instanz auf Registerkarte mit der Computesitzungsliste auf der Computeseite an.

Unter der Registerkarte Aktive Flows und Ausführungen können Sie auch auf Flows und Ausführungen zugreifen, die über die Compute ausgeführt werden. Das Löschen der Instanz wirkt sich auf die zugehörigen Flows und Ausführungen aus.

Beziehung zwischen Computesitzung, Computeressource, Flow und Benutzer
- Ein einzelner Benutzer kann mehrere Computeressourcen (serverlose oder Computeinstanzen) haben. Aufgrund unterschiedlicher Anforderungen kann ein einzelner Benutzer über mehrere Computeressourcen verfügen. Beispielsweise kann ein Benutzer mehrere Computeressourcen mit unterschiedlicher VM-Größe oder einer anderen benutzerseitig zugewiesenen verwalteten Identität besitzen.
- Eine Computeressource kann nur von einem einzelnen Benutzer verwendet werden. Eine Computeressource wird als private Dev-Box eines einzelnen Benutzers verwendet. Mehrere Benutzer können nicht dieselben Computeressourcen verwenden.
- Eine Computeressource kann mehrere Computesitzungen hosten. Eine Computesitzung ist ein Container, der auf einer zugrunde liegenden Computeressource ausgeführt wird. Die Erstellung von Promptflows erfordert beispielsweise nicht allzu viele Computeressourcen, sodass eine einzelne Computeressource mehrere Computesitzungen von demselben Benutzer hosten kann.
- Eine Computesitzung gehört jeweils nur zu einer einzelnen Computeressource. Sie können jedoch eine Computesitzung löschen oder beenden und sie einer anderen Computeressource zuweisen.
- Ein Flow kann nur eine Computesitzung umfassen. Jeder Flow ist eigenständig und definiert das Basisimage und die erforderlichen Python-Pakete im Flowordner für die Computesitzung.
Ändern der Runtime in eine Computesitzung
Computesitzungen haben gegenüber Runtimes für Compute-Instanzen die folgenden Vorteile:
- Automatische Verwaltung des Lebenszyklus der Sitzung und der zugrunde liegenden Compute. Sie müssen sie nicht mehr manuell erstellen und verwalten.
- Passen Sie Pakete mühelos an, indem Sie in der
requirements.txt-Datei im Flow-Ordner Pakete hinzufügen, anstatt eine benutzerdefinierte Umgebung zu erstellen.
Mithilfe der folgenden Schritte können Sie die Runtime einer Compute-Instanz in eine Computesitzung ändern:
- Bereiten Sie Ihre
requirements.txt-Datei im Flow-Ordner vor. Stellen Sie sicher, dass Sie die Version vonpromptflowundpromptflow-toolsinrequirements.txtnicht anheften, da sie bereits im Basisimage enthalten sind. Die Computesitzung installiert die Pakete in derrequirements.txt-Datei, wenn sie gestartet wird. - Wenn Sie eine benutzerdefinierte Umgebung zum Erstellen der Runtime für eine Compute-Instanz erstellen, können Sie das Image von der Detailseite der Umgebung abrufen und in der
flow.dag.yaml-Datei im Flowordner angeben. Weitere Informationen finden Sie unter Ändern des Basisimages für Computesitzungen. Stellen Sie sicher, dass Sie oder die entsprechenden benutzerseitig zugewiesenen verwalteten Identitäten im Arbeitsbereich über dieacr pull-Berechtigung für das Image verfügen.

- Für die Computeressource können Sie die vorhandene Compute-Instanz weiterhin verwenden, wenn Sie den Lebenszyklus manuell verwalten möchten. Alternativ können Sie das serverlose Computing ausprobieren, dessen Lebenszyklus vom System verwaltet wird.