Verwenden von Parallelaufträgen in Pipelines
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Hier erfahren Sie, wie Sie die CLI v2 und das Python SDK v2 zum Ausführen von Parallelaufträgen in Azure Machine Learning-Pipelines verwenden. Parallelaufträge beschleunigen die Auftragsausführung, indem sie wiederkehrende Aufgaben auf leistungsstarke Computecluster mit mehreren Knoten verteilen.
ML-Techniker haben immer Skalierungsanforderungen an ihre Trainings- oder Rückschlussaufgaben. Wenn z. B. eine wissenschaftliche Fachkraft für Daten ein einzelnes Skript zum Trainieren eines Modells zur Umsatzvorhersage bereitstellt, müssen Machine Learning-Techniker diese Trainingsaufgabe auf jedes einzelne Geschäft anwenden. Herausforderungen dieses Skalierungsprozesses umfassen lange Ausführungszeiten, die zu Verzögerungen führen, und unerwartete Probleme, die manuelle Eingriffe erfordern, um die Ausführung der Aufgabe aufrechtzuerhalten.
Die Kernaufgabe einer Azure Machine Learning-Parallelisierung besteht darin, dass eine einzelne serielle Aufgabe in Minibatches aufgeteilt wird und diese Minibatches zur parallelen Ausführung an mehrere Compute-Instanzen gesendet werden. Parallelaufträge reduzieren die End-to-End-Ausführungszeit erheblich und behandeln auch Fehler automatisch. Erwägen Sie die Verwendung eines Azure Machine Learning-Parallelauftrags, um viele Modelle über Ihre partitionierten Daten zu trainieren oder um Ihre umfangreichen Batch-Rückschlussaufgaben zu beschleunigen.
In einem Szenario, in dem Sie ein Objekterkennungsmodell auf einer großen Gruppe von Bildern ausführen, können Sie Ihre Bilder ganz einfach verteilen, um benutzerdefinierten Code parallel auf einem bestimmten Computecluster auszuführen. Die Parallelisierung kann den Zeitaufwand erheblich reduzieren. Azure Machine Learning-Parallelaufträge können Ihren Prozess auch vereinfachen und automatisieren, um ihn effizienter zu gestalten.
Voraussetzungen
- Sie verfügen über ein Azure Machine Learning-Konto und einen Arbeitsbereich.
- Lernen Sie die Azure Machine Learning-Pipelines kennen.
- Installieren Sie die Azure CLI und die Erweiterung
ml. Weitere Informationen finden Sie unter Installieren, Einrichten und Verwenden der CLI (v2). Dieml-Erweiterung wird automatisch installiert, wenn Sie den Befehlaz mlzum ersten Mal ausführen. - Machen Sie sich damit vertraut, wie Sie Azure Machine Learning-Pipelines und -Komponenten mit der CLI v2 erstellen und ausführen.
Erstellen und Ausführen einer Pipeline mit einem Parallelauftragsschritt
Ein Azure Machine Learning-Parallelauftrag kann nur als ein Schritt in einem Pipelineauftrag verwendet werden.
Die folgenden Beispiele stammen aus Ausführen eines Pipelineauftrags mithilfe eines Parallelauftrags in der Pipeline im Repository mit Azure Machine Learning-Beispielen.
Vorbereiten auf die Parallelisierung
Dieser Parallelauftragsschritt erfordert Vorbereitung. Sie benötigen ein Einstiegsskript, das die vordefinierten Funktionen implementiert. Sie müssen auch Attribute in der Definition Ihres Parallelauftrags festlegen, die:
- Ihre Eingabedaten definieren und binden.
- die Datenteilungsmethode festlegen.
- Ihre Computeressourcen konfigurieren.
- das Einstiegsskript aufrufen.
In den folgenden Abschnitten wird beschrieben, wie der Parallelauftrag vorbereitet wird.
Deklarieren der Eingaben und der Einstellung für die Datenteilung
Ein paralleler Auftrag erfordert eine wichtige Eingabe, die parallel aufgeteilt und verarbeitet werden muss. Das Format der Haupteingabedaten kann entweder Tabellendaten sein oder eine Liste von Dateien umfassen.
Verschiedene Datenformate weisen unterschiedliche Eingabetypen, Eingabemodi und Datenteilungsmethoden auf. In der folgenden Tabelle werden diese Optionen beschrieben:
| Datenformat | Eingabetyp | Eingabemodus | Datenteilungsmethode |
|---|---|---|---|
| Dateiliste | mltable oder uri_folder |
ro_mount oder download |
Nach Größe (Anzahl der Dateien) oder nach Partition |
| Tabellendaten | mltable |
direct |
Nach Größe (geschätzte physische Größe) oder nach Partition |
Hinweis
Wenn Sie tabellarische mltable als Haupteingabedaten verwenden, müssen Sie:
- Die
mltable-Bibliothek in Ihrer Umgebung installieren, wie in Zeile 9 dieser Conda-Datei. - Eine MLTable-Spezifikationsdatei unter Ihrem angegebenen Pfad haben, wobei der Abschnitt
transformations: - read_delimited:ausgefüllt ist. Weitere Beispiele finden Sie unter Erstellen und Verwalten von Datenressourcen.
Sie können Ihre wichtigsten Eingabedaten mit dem Attribut input_data im parallelen Auftrag YAML oder Python deklarieren und die Daten mit dem definierten input Ihres parallelen Auftrags binden, indem Sie ${{inputs.<input name>}} verwenden. Anschließend definieren Sie das Datenteilungsattribut für die wichtigsten Eingaben je nach Ihrer Datenteilungsmethode.
| Datenteilungsmethode | Attributname | Attributtyp | Auftragsbeispiel |
|---|---|---|---|
| Nach Größe | mini_batch_size |
Zeichenfolge | Iris-Batchvorhersage |
| Nach Partition | partition_keys |
Eine Liste von Zeichenfolgen | Verkaufsvorhersage für Orangensaft |
Konfigurieren der Computeressourcen für die Parallelisierung
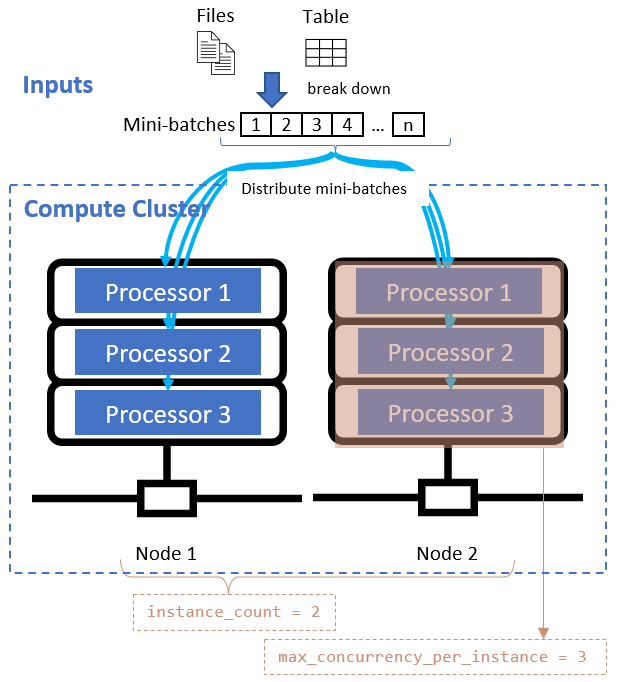
Konfigurieren Sie nach dem Definieren des Datenteilungsattributs die Computeressourcen für Ihre Parallelisierung, indem Sie die Attribute instance_count und max_concurrency_per_instance festlegen.
| Attributname | Typ | BESCHREIBUNG | Standardwert |
|---|---|---|---|
instance_count |
integer | Die Anzahl von Knoten, die für den Auftrag verwendet werden sollen. | 1 |
max_concurrency_per_instance |
integer | Die Anzahl der Prozessoren auf jedem Knoten. | Für eine GPU-Berechnung: 1. Für eine CPU-Berechnung: Anzahl der Kerne. |
Diese Attribute arbeiten mit dem von Ihnen angegebenen Computecluster zusammen, wie in der folgenden Abbildung gezeigt:
Aufrufen des Einstiegsskripts
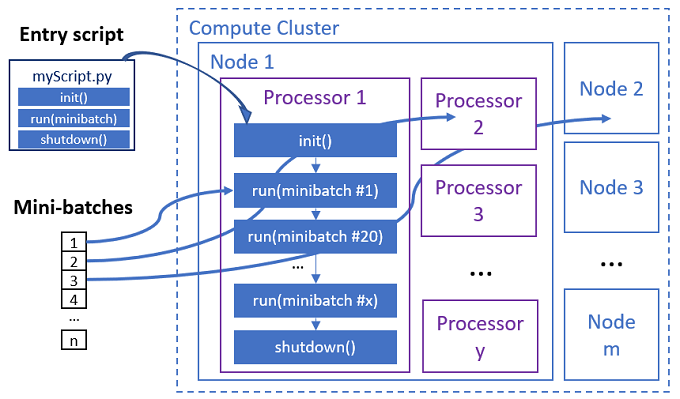
Das Einstiegsskript ist eine einzelne Python-Datei,die die folgenden drei vordefinierte Funktionen mit benutzerdefiniertem Code implementiert.
| Funktionsname | Erforderlich | Beschreibung | Eingabe | Rückgabewert |
|---|---|---|---|---|
Init() |
Y | Allgemeine Vorbereitung vor dem Ausführen von Minibatches. Ein Beispiel wäre etwa die Verwendung dieser Funktion zum Laden des Modells in ein globales Objekt. | -- | -- |
Run(mini_batch) |
Y | Implementiert die Hauptausführungslogik für „mini_batches“. | mini_batch ist Pandas Datenframe, wenn es sich bei Eingabedaten um tabellarische Daten handelt, oder die Dateipfadliste, wenn es sich bei Eingabedaten um ein Verzeichnis handelt. |
Dataframe, Liste oder Tupel. |
Shutdown() |
N | Optionale Funktion zur Durchführung benutzerdefinierter Bereinigungen, bevor die Compute-Instanz an den Pool zurückgegeben wird. | -- | -- |
Wichtig
Um Ausnahmen beim Analysieren von Argumenten in Init()- oder Run(mini_batch)-Funktionen zu vermeiden, verwenden Sie parse_known_args anstelle von parse_args. Ein Einstiegsskript mit Argumentparser finden Sie im Beispiel iris_score.
Wichtig
Die Funktion Run(mini_batch) erfordert die Rückgabe eines Elements aus einem Dataframe, einer Liste oder einem Tupel. Der Parallelauftrag verwendet den Zähler dieser Rückgabe, um die erfolgreichen Elemente unter diesem Minibatch zu messen. Die Anzahl der Minibatches sollte gleich der Anzahl der Rückgabelisten sein, wenn alle Elemente ordnungsgemäß verarbeitet wurden.
Der Parallelauftrag führt die Funktionen in jedem Prozessor aus, wie im folgenden Diagramm dargestellt.
Sehen Sie sich die folgenden Beispiele für Eintragsskripts an:
Um das Einstiegsskript aufzurufen, legen Sie die folgenden beiden Attribute in der Definition des Parallelauftrags fest:
| Attributname | Typ | Beschreibung |
|---|---|---|
code |
string | Lokaler Pfad zum Quellcodeverzeichnis, das hochgeladen und für den Auftrag verwendet werden soll. |
entry_script |
Zeichenfolge | Die Python-Datei, die die Implementierung der vordefinierten parallelen Funktionen enthält. |
Beispiel für Schritte von Parallelaufträgen
Der folgende Schritt des Parallelauftrags deklariert die Eingabetyp-, Modus- und Datenteilungsmethode, bindet die Eingabe, konfiguriert die Berechnung und ruft das Eingabeskript auf.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Berücksichtigen von Automatisierungseinstellungen
Ein Azure Machine Learning-Parallelauftrag stellt viele optionale Einstellungen bereit, um den Auftrag ohne manuelle Eingriffe automatisch zu steuern. Die Einstellungen sind in der folgenden Tabelle beschrieben.
| Schlüssel | type | BESCHREIBUNG | Zulässige Werte | Standardwert | Festlegen im Attribut- oder Programmargument |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Die Anzahl der fehlerhaften Minibatches, die in diesem Parallelauftrag ignoriert werden sollen. Wenn die Anzahl der fehlerhaften Minibatches über diesem Schwellenwert liegt, wird der Parallelauftrag als fehlerhaft markiert. Der Minibatch wird in folgender Situation als fehlerhaft markiert: - Die Anzahl der Rückgaben von run() ist kleiner als die Anzahl der Minibatcheingaben.- Ausnahmen werden in benutzerdefiniertem run()-Code erfasst. |
[-1, int.max] |
-1, d. h. alle fehlgeschlagenen Minibatches ignorieren |
Attribute mini_batch_error_threshold |
mini_batch_max_retries |
integer | Die Anzahl der Wiederholungen, wenn der Minibatch fehlschlägt oder ein Zeitüberschreitung auftritt. Wenn alle Wiederholungen fehlschlagen, wird der Minibatch pro mini_batch_error_threshold-Berechnung als fehlgeschlagen markiert. |
[0, int.max] |
2 |
Attribute retry_settings.max_retries |
mini_batch_timeout |
integer | Das Timeout in Sekunden für die Ausführung der benutzerdefinierten run()-Funktion. Wenn die Ausführungszeit diesen Schwellenwert überschreitet, wird der Minibatch abgebrochen und als fehlerhaft markiert, um eine Wiederholung auszulösen. |
(0, 259200] |
60 |
Attribute retry_settings.timeout |
item_error_threshold |
integer | Der Schwellenwert für fehlerhafte Elemente. Die fehlerhaften Elemente werden nach der Anzahl der Lücken zwischen den Eingaben und den Rückgaben der einzelnen Minibatches gezählt. Wenn die Summe der fehlerhaften Elemente über diesem Schwellenwert liegt, wird der Parallelauftrag als fehlerhaft markiert. | [-1, int.max] |
-1, was bedeutet, dass alle Fehler während des Parallelauftrags ignoriert werden |
Programmargument--error_threshold |
allowed_failed_percent |
integer | Ähnlich wie mini_batch_error_threshold, verwendet jedoch den Prozentsatz der fehlerhaften Minibatches anstelle der Anzahl. |
[0, 100] |
100 |
Programmargument--allowed_failed_percent |
overhead_timeout |
integer | Timeout in Sekunden für die Initialisierung jedes Minibatch. Beispielsweise das Laden von Minibatchdaten und deren Übergabe an die run()-Funktion. |
(0, 259200] |
600 |
Programmargument--task_overhead_timeout |
progress_update_timeout |
integer | Timeout in Sekunden für die Überwachung des Status der Minibatchausführung. Wenn innerhalb dieser Timeouteinstellung kein Statusupdate empfangen wird, wird der Parallelauftrag als fehlerhaft markiert. | (0, 259200] |
Dynamisch berechnet durch andere Einstellungen | Programmargument--progress_update_timeout |
first_task_creation_timeout |
integer | Timeout in Sekunden zur Überwachung der Zeit zwischen dem Start des Auftrags und dem Ausführen des ersten Minibatch. | (0, 259200] |
600 |
Programmargument--first_task_creation_timeout |
logging_level |
Zeichenfolge | Die Ebene der Protokolle, die in Benutzerprotokolldateien gespeichert werden sollen. | INFO, WARNINGoder DEBUG |
INFO |
Attribute logging_level |
append_row_to |
Zeichenfolge | Aggregieren Sie alle Rückgaben aus jedem ausgeführten Minibatch, und geben Sie sie in dieser Datei aus. Kann auf eine der Ausgaben des Parallelauftrags mithilfe von ${{outputs.<output_name>}} verweisen |
Attribute task.append_row_to |
||
copy_logs_to_parent |
Zeichenfolge | Boolesche Option, ob der Auftragsstatus, die Übersicht und die Protokolle in den übergeordneten Pipelineauftrag kopiert werden sollen. | True oder False |
False |
Programmargument--copy_logs_to_parent |
resource_monitor_interval |
integer | Das Zeitintervall in Sekunden für die Ablage der Nutzung von Knotenressourcen (z. B. CPU, Arbeitsspeicher) im Protokollordner unter dem Pfad logs/sys/perf. Hinweis: Häufige Speicherabbildressourcenprotokolle werden leicht verlangsamt ausgeführt. Legen Sie diesen Wert auf 0 fest, um das Ablegen der Ressourcennutzung zu beenden. |
[0, int.max] |
600 |
Programmargument--resource_monitor_interval |
Der folgende Beispielcode aktualisiert diese Einstellungen:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Erstellen der Pipeline mit Schritten des Parallelauftrags
Das folgende Beispiel zeigt den vollständigen Pipelineauftrag mit dem Schritt des Parallelauftrags inline:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Übermitteln des Pipelineauftrags
Übermitteln Sie Ihren Pipelineauftrag mit parallelem Schritt mithilfe des az ml job create-CLI-Befehls:
az ml job create --file pipeline.yml
Überprüfen des parallelen Schritts in der Studio-Benutzeroberfläche
Nachdem Sie einen Pipelineauftrag übermittelt haben, erhalten Sie vom SDK- oder CLI-Widget einen Web-URL-Link zum Pipelinediagramm auf der Benutzeroberfläche von Azure Machine Learning Studio.
Um Ereignisse für Parallelaufträge anzuzeigen, doppelklicken Sie im Pipelinediagramm auf den parallelen Schritt, wählen Sie die Registerkarte Einstellungen im Detailbereich aus, erweitern Sie Einstellungen ausführen, und erweitern Sie dann den Abschnitt Parallel.

Um Fehler in Parallelaufträgen zu debuggen, wählen Sie die Registerkarte Ausgabe + Protokolle aus, erweitern Sie den Ordner Protokolle, und überprüfen Sie job_result.txt, um zu verstehen, warum der Parallelauftrag fehlgeschlagen ist. Informationen zur Protokollierungsstruktur von Parallelaufträgen finden Sie unter readme.txt im selben Ordner.
