Nachverfolgen von ML-Modellen mit MLflow und Azure Machine Learning
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel wird erläutert, wie Sie MLflow Tracking aktivieren, um Azure Machine Learning als Back-End Ihrer MLflow-Experimente zu verbinden.
MLflow ist eine Open-Source-Bibliothek zum Verwalten des Lebenszyklus Ihrer Machine Learning-Experimente. MLflow-Nachverfolgung ist eine Komponente von MLflow, die Ihre Trainingsausführungsmetriken und Modellartefakte unabhängig von der Umgebung Ihres Experiments protokolliert und nachverfolgt: lokal auf Ihrem Computer, auf einem Remotecomputeziel, auf einem virtuellen Computer oder in einem Azure Databricks-Cluster.
Unter MLflow und Azure Machine Learning finden Sie alle unterstützten MLflow- und Azure Machine Learning-Funktionen, einschließlich MLflow Project-Unterstützung (Vorschau) und -Modellimplementierung.
Tipp
Weitere Informationen zum Nachverfolgen von Experimenten, die in Azure Databricks oder Azure Synapse Analytics ausgeführt werden, finden Sie in den dedizierten Artikeln Nachverfolgen von ML-Experimenten in Azure Databricks mit MLflow und Azure Machine Learning und Nachverfolgen von Azure Synapse Analytics-ML-Experimenten mit MLflow und Azure Machine Learning.
Hinweis
Die Informationen in diesem Dokument sind hauptsächlich für Datenanalysten und Entwickler gedacht, die den Modelltrainingsprozess überwachen möchten. Wenn Sie Administrator sind und sich für die Überwachung der Ressourcennutzung und Ereignisse von Azure Machine Learning (z. B. Kontingente, abgeschlossene Trainingsaufträge oder abgeschlossene Modellimplementierungen) interessieren, helfen Ihnen die Informationen im Artikel Überwachen von Azure Machine Learning weiter.
Voraussetzungen
Installieren Sie das
mlflow-Paket.- Sie können MLflow Skinny verwenden. Dabei handelt es sich um ein einfaches MLflow-Paket ohne SQL-Speicher, Server, Benutzeroberfläche oder Data-Science-Abhängigkeiten. Dies wird für Benutzer empfohlen, die in erster Linie die Nachverfolgungs- und Protokollierungsfunktionen benötigen, ohne die gesamte Suite von MLflow-Features einschließlich Bereitstellungen zu importieren.
Installieren Sie das
azureml-mlflow-Paket.Erstellen Sie einen Azure Machine Learning-Arbeitsbereich.
- Überprüfen Sie, welche Zugriffsberechtigungen Sie benötigen, um Ihre MLflow-Vorgänge mit Ihrem Arbeitsbereich auszuführen.
Installieren Sie die Azure Machine Learning CLI (v1), und richten Sie sie ein. Installieren Sie dann unbedingt die ML-Erweiterung.
Wichtig
Einige Azure CLI-Befehle in diesem Artikel verwenden die Erweiterung
azure-cli-mloder v1 für Azure Machine Learning. Der Support für die v1-Erweiterung endet am 30. September 2025. Sie können die v1-Erweiterung bis zu diesem Datum installieren und verwenden.Es wird empfohlen, vor dem 30. September 2025 zur
ml- oder v2-Erweiterung zu wechseln. Weitere Informationen zur v2-Erweiterung finden Sie unter Was sind die Azure Machine Learning CLI und das Python SDK v2?.Installieren Sie das Azure Machine Learning SDK für Python und richten Sie es ein.
Nachverfolgen von Ausführungen über Ihren lokalen Computer oder Remotecompute
Bei der Nachverfolgung mithilfe von MLflow mit Azure Machine Learning können Sie die Ausführungen der protokollierten Metriken und Artefakte in Ihrem Azure Machine Learning-Arbeitsbereich speichern, die auf Ihrem lokalen Computer ausgeführt wurden.
Einrichten der Nachverfolgungsumgebung
Um eine Ausführung nachzuverfolgen, die nicht über Azure Machine Learning-Compute (ab jetzt als lokale Compute bezeichnet) ausgeführt wird, müssen Sie Ihre lokale Compute auf den MLflow Tracking-URI in Azure Machine Learning ausrichten.
Hinweis
Wenn Sie auf Azure Compute (Azure-Notizbücher, Jupyter-Notizbücher, die in Azure Compute Instances oder Compute-Clustern gehostet werden), müssen Sie den Tracking-URI nicht konfigurieren. Es ist automatisch für Sie konfiguriert.
- Verwenden des Azure Machine Learning SDK
- Verwenden einer Umgebungsvariable
- Erstellen des MLflow-Nachverfolgungs-URI
GILT FÜR: Python SDK azureml v1
Sie können den MLflow-Nachverfolgungs-URI von Azure Machine Learning mithilfe des Azure Machine Learning SDK v1 für Python abrufen. Stellen Sie sicher, dass Sie die Bibliothek azureml-sdk in dem von Ihnen verwendeten Cluster installiert haben. Das folgende Beispiel ruft den eindeutigen MLFLow-Nachverfolgungs-URI ab, der Ihrem Arbeitsbereich zugeordnet ist. Anschließend verweist die Methode set_tracking_uri() den MLflow-Nachverfolgungs-URI auf diesen URI.
Verwendung der Konfigurationsdatei für den Arbeitsbereich:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Tipp
Sie können die Konfigurationsdatei für den Arbeitsbereich herunterladen:
- Navigieren Sie zu Azure Machine Learning Studio.
- Klicken Sie auf die obere rechte Ecke der Seite, und > laden Sie die Konfigurationsdatei herunter.
- Speichern Sie die Datei
config.jsonim selben Verzeichnis, in dem Sie arbeiten.
Verwenden der Abonnement-ID, des Ressourcengruppennamens und des Arbeitsbereichsnamens:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Festlegen des Experimentnamens
Alle MLflow-Ausführungen werden im aktiven Experiment protokolliert. Standardmäßig werden Ausführungen mit einem Experiment namens Default protokolliert, das automatisch für Sie erstellt wird. Verwenden Sie den MLflow-Befehl mlflow.set_experiment(), um das Experiment zu konfigurieren, an dem Sie arbeiten möchten.
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Tipp
Wenn Sie Aufträge mithilfe des Azure Machine Learning SDK übermitteln, können Sie den Namen des Experiments bei der Übermittlung in der Eigenschaft experiment_name festlegen. Sie brauchen es in Ihrem Trainingsskript nicht zu konfigurieren.
Starten der Trainingsausführung
Nachdem Sie den Namen des MLflow-Experiments festgelegt haben, können Sie Ihre Trainingsausführung mit start_run() starten. Verwenden Sie anschließend log_metric(), um die API für die MLflow-Protokollierung zu aktivieren, und beginnen Sie mit dem Protokollieren Ihrer Metriken für die Trainingsausführungen.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
Weitere Informationen zum Protokollieren von Metriken, Parametern und Artefakten in einer Ausführung mithilfe von MLflow finden Sie unter Protokollieren und Anzeigen von Metriken und Protokolldateien.
Nachverfolgen von Ausführungen, die in Azure Machine Learning ausgeführt werden
GILT FÜR: Python SDK azureml v1
Remoteausführungen (Aufträge) ermöglichen es Ihnen, Ihre Modell auf robuste und repetitive Weise zu trainieren. Sie können auch leistungsstärkere Computekomponenten wie Machine Learning Compute-Cluster verwenden. Informationen zu den verschiedenen Computeoptionen finden Sie unter Übermitteln einer Trainingsausführung an ein Computeziel.
Wenn Sie Ausführungen übermitteln, wird MLflow von Azure Machine Learning automatisch für die Arbeit mit dem Arbeitsbereich konfiguriert, in dem die Ausführung ausgeführt wird. Dies bedeutet, dass der MLflow-Nachverfolgungs-URI nicht konfiguriert werden muss. Darüber hinaus werden Experimente basierend auf den Details der Experimentübermittlung automatisch benannt.
Wichtig
Wenn Sie Trainingsaufträge an Azure Machine Learning übermitteln, müssen Sie den MLflow-Nachverfolgungs-URI nicht für Ihre Trainingslogik konfigurieren, da diese bereits für Sie konfiguriert ist. Sie brauchen den Namen des Experiments auch nicht in Ihrer Trainingsroutine zu konfigurieren.
Schaffen einer Trainingsroutine
Zunächst sollten Sie ein src-Unterverzeichnis und eine Datei mit Ihrem Trainingscode in einer train.py-Datei im src-Unterverzeichnis erstellen. Der gesamte Trainingscode (einschließlich train.py) wird im Unterverzeichnis src gespeichert.
Der Trainingscode stammt aus diesem MLflow-Beispiel im Azure Machine Learning-Beispielrepository.
Kopieren Sie diesen Code in die Datei:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Konfigurieren des Experiments
Sie müssen Python verwenden, um das Experiment an Azure Machine Learning zu übermitteln. Konfigurieren Sie in einem Notebook oder einer Python-Datei Ihre Compute- und Trainingsausführungsumgebung mit der Klasse Environment.
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
Erstellen Sie anschließend ScriptRunConfig mit Ihrer Remotecomputeumgebung als Computeziel.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
Verwenden Sie bei dieser Konfiguration für Computevorgänge und Trainingsausführungen die Experiment.submit()-Methode, um eine Ausführung zu übermitteln. Mit dieser Methode wird der MLflow Tracking-URI automatisch festgelegt und die Protokollierung von MLflow an Ihren Arbeitsbereich geleitet.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
Anzeigen von Metriken und Artefakten in Ihrem Arbeitsbereich
Die Metriken und Artefakte aus dem MLflow-Protokoll werden in Ihrem Arbeitsbereich nachverfolgt. Sie können sie jederzeit anzeigen. Navigieren Sie dazu zu Ihrem Arbeitsbereich, und suchen Sie über den Namen nach dem Experiment in Ihrem Arbeitsbereich in Azure Machine Learning-Studio. Führen Sie alternativ den folgenden Befehl aus:
Rufen Sie die Ausführungsmetrik mithilfe von MLflow get_run() ab.
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
Zum Anzeigen der Artefakte einer Ausführung können Sie MlFlowClient.list_artifacts() verwenden.
client.list_artifacts(run_id)
Zum Herunterladen eines Artefakts in das aktuelle Verzeichnis können Sie MLFlowClient.download_artifacts() verwenden.
client.download_artifacts(run_id, "helloworld.txt", ".")
Weitere Informationen zum Abrufen von Informationen von Experimenten und Ausführungen in Azure Machine Learning mithilfe von MLflow finden Sie unter Verwalten von Experimenten und Ausführungen mit MLflow.
Vergleichen und Abfragen
Vergleichen und fragen Sie alle MLflow-Ausführungen in Ihrem Azure Machine Learning-Arbeitsbereich mit dem folgenden Code ab. Erfahren Sie mehr über das Abfragen von Ausführungen mit MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Automatische Protokollierung
Mit Azure Machine Learning und MLFlow können Benutzer Metriken, Modellparameter und Modellartefakte automatisch protokollieren, wenn sie ein Modell trainieren. Eine Vielzahl beliebter Machine Learning-Bibliotheken wird unterstützt.
Um die automatische Protokollierung zu aktivieren, fügen Sie den folgenden Code vor dem Trainingscode ein:
mlflow.autolog()
Erfahren Sie mehr über die automatische Protokollierung mit MLflow.
Verwalten von Modellen
Registrieren und verfolgen Sie Ihre Modelle mit der Azure Machine Learning-Modellregistrierung, die die MLflow-Modellregistrierung unterstützt. Azure Machine Learning-Modelle werden am MLflow-Modellschema ausgerichtet, sodass Sie diese Modelle problemlos exportieren und in verschiedene Workflows importieren können. Die Metadaten zu MLflow, z. B. die Ausführungs-ID, werden auch mit dem registrierten Modell nachverfolgt. Benutzer können Trainingsausführungen senden, registrieren und bereitstellen, die aus MLflow-Ausführungen erstellt wurden.
Wenn Sie Ihr Produktionsbereitstellungsmodell in einem Schritt bereitstellen und registrieren möchten, finden Sie weitere Informationen unter Bereitstellen und Registrieren von MLflow-Modellen.
Führen Sie die folgenden Schritte aus, um ein Modell aus einer Ausführung zu registrieren und anzuzeigen:
Wenn eine Ausführung beendet ist, rufen Sie die
register_model()-Methode auf.# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Zeigen Sie das registrierte Modell in Ihrem Arbeitsbereich in Azure Machine Learning Studio an.
Im folgenden Beispiel sind die Metadaten für die MLflow-Nachverfolgung für das registrierte Modell
my-modelgekennzeichnet.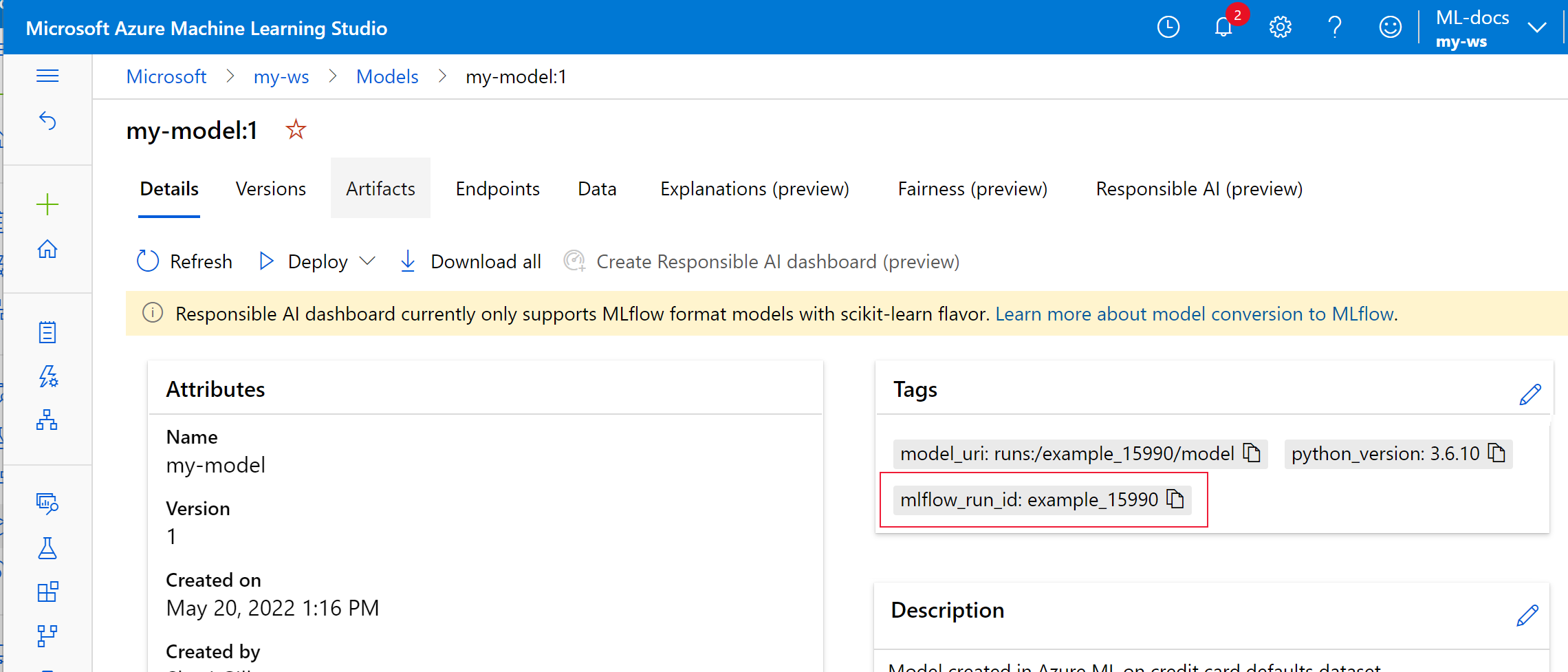
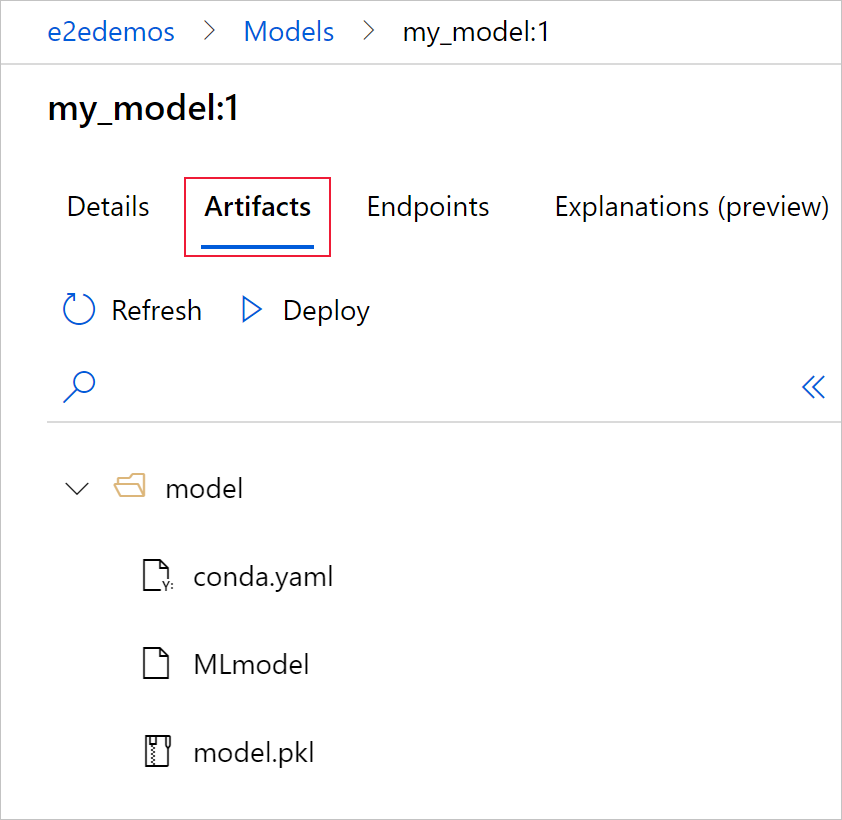
Wählen Sie die Registerkarte Artefakte aus, um alle Modelldateien anzuzeigen, die mit dem MLflow-Modellschema („conda.yaml“, MLmodel, „model.pkl“) übereinstimmen.
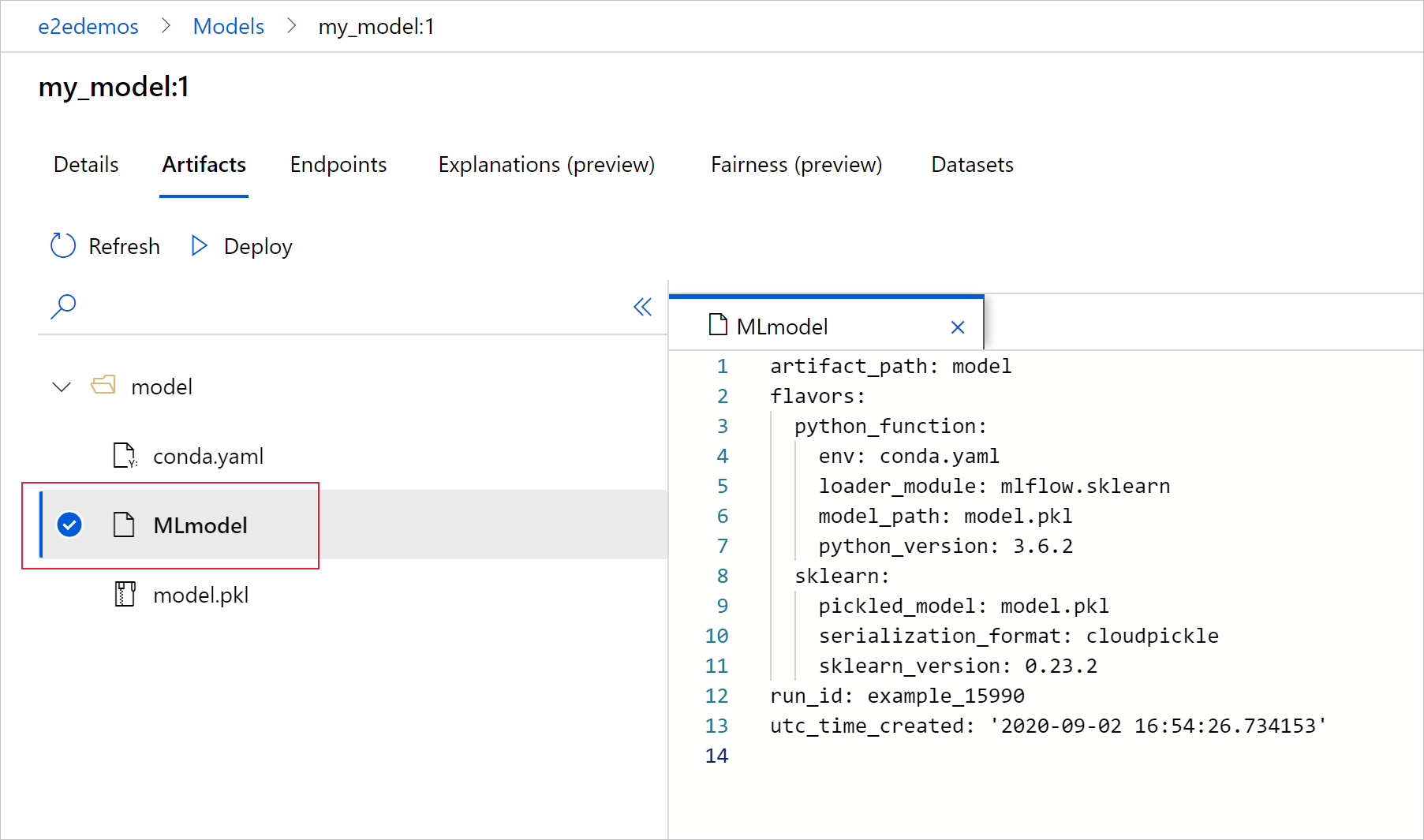
Wählen Sie „MLmodel“ aus, um die von der Ausführung generierte MLmodel-Datei anzuzeigen.
Bereinigen von Ressourcen
Beachten Sie Folgendes, falls Sie nicht planen, die protokollierten Metriken und Artefakte in Ihrem Arbeitsbereich zu verwenden: Das Löschen einzelner Einträge ist derzeit nicht möglich. Löschen Sie stattdessen die Ressourcengruppe, die das Speicherkonto und den Arbeitsbereich enthält, damit hierfür keine Gebühren anfallen:
Wählen Sie ganz links im Azure-Portal Ressourcengruppen aus.
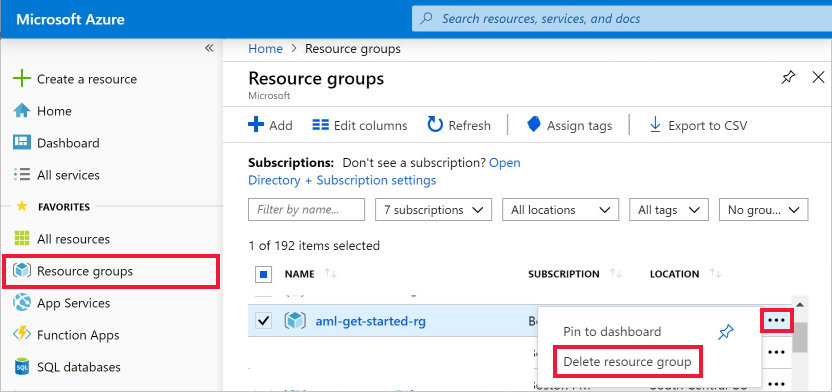
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie die Option Ressourcengruppe löschen.
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Beispielnotebooks
In den Notebooks „MLflow mit Azure Machine Learning“ werden die in diesem Artikel vorgestellten Konzepte weiter erläutert und demonstriert. Weitere Informationen finden Sie auch unter dem von der Community gesteuerten Repository AzureML-Examples.
Nächste Schritte
- Bereitstellen von Modellen mit MLflow.
- Überwachen Ihrer Produktionsmodelle auf Datenabweichungen
- Nachverfolgen von Azure Databricks-Ausführungen mit MLflow
- Verwalten Ihrer Modelle