Bedarfsorientiertes Trainieren von TensorFlow-Modellen mit Azure Machine Learning
GILT FÜR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Ihre TensorFlow-Trainingsskripts mithilfe des Python SDK v2 für Azure Machine Learning im großen Stil ausführen.
Der Beispielcode in diesem Artikel trainiert ein TensorFlow-Modell, um handschriftliche Ziffern mithilfe eines Deep Neural Network (DNN) zu klassifizieren, registriert das Modell und stellt es auf einem Onlineendpunkt bereit.
Unabhängig davon, ob Sie ein TensorFlow-Modell von Grund auf entwickeln oder ein vorhandenes Modell in die Cloud bringen, können Sie Azure Machine Learning zum Aufskalieren von Open-Source-Trainingsaufträgen mithilfe elastischer Cloudcomputeressourcen verwenden. Sie können produktionsgeeignete Modelle mit Azure Machine Learning erstellen, bereitstellen, überwachen sowie die Versionen verwalten.
Voraussetzungen
Damit dieser Artikel für Sie nützlich ist, müssen Sie folgende Schritte ausführen:
- Greifen Sie auf ein Azure-Abonnement zu. Sollten Sie noch keines besitzen, können Sie ein kostenloses Konto erstellen.
- Führen Sie den Code in diesem Artikel in einer Azure Machine Learning-Compute-Instanz oder in Ihrem eigenen Jupyter Notebook aus.
- Azure Machine Learning-Compute-Instanz – weder Download noch Installation erforderlich:
- Führen Sie das Tutorial Erstellen von Ressourcen für die ersten Schritte durch, um einen dedizierten Notebookserver zu erstellen, auf dem das SDK und das Beispielrepository vorinstalliert sind.
- Im Deep Learning-Beispielordner auf dem Notebook-Server finden Sie ein vollständiges und erweitertes Notebook. Navigieren Sie zum folgenden Verzeichnis: v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Ihr Jupyter Notebook-Server
- Azure Machine Learning-Compute-Instanz – weder Download noch Installation erforderlich:
- Laden Sie die folgenden Dateien herunter:
- Trainingsskript tf_mnist.py
- Bewertungsskript score.py
- Beispielanforderungsdatei sample-request.json
Auf der GitHub-Seite mit Beispielen finden Sie außerdem eine fertige Jupyter Notebook-Version dieser Anleitung.
Bevor Sie den Code in diesem Artikel ausführen können, um einen GPU-Cluster zu erstellen, müssen Sie für Ihren Arbeitsbereich eine Kontingenterhöhung anfordern.
Einrichten des Auftrags
In diesem Abschnitt wird der Auftrag für das Training eingerichtet, indem Sie die erforderlichen Python-Pakete laden, eine Verbindung mit einem Arbeitsbereich herstellen, eine Computeressource zum Ausführen eines Befehlsauftrags erstellen und eine Umgebung zum Ausführen des Auftrags erstellen.
Herstellen einer Verbindung mit dem Arbeitsbereich
Zuerst müssen Sie eine Verbindung mit Ihrem Azure Machine Learning-Arbeitsbereich herstellen. Der Azure Machine Learning-Arbeitsbereich ist die Ressource der obersten Ebene für den Dienst. Er bietet Ihnen einen zentralen Ort für die Arbeit mit allen Artefakten, die Sie bei der Verwendung von Azure Machine Learning erstellen.
Sie verwenden DefaultAzureCredential, um Zugriff auf den Arbeitsbereich zu erhalten. Diese Anmeldeinformationen sollten die meisten Azure SDK-Authentifizierungsszenarien abdecken können.
Wenn DefaultAzureCredential für Sie nicht funktioniert, finden Sie unter azure-identity reference documentation und Set up authentication weitere verfügbare Anmeldeinformationen.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Wenn Sie sich lieber über einen Browser anmelden und authentifizieren möchten, sollten Sie stattdessen die Auskommentierung des folgenden Codes aufheben und diesen verwenden.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Rufen Sie als Nächstes ein Handle für den Arbeitsbereich ab, indem Sie Ihre Abonnement-ID, den Namen der Ressourcengruppe und den Namen des Arbeitsbereichs angeben. So finden Sie diese Parameter
- Suchen Sie in der rechten oberen Ecke der Symbolleiste von Azure Machine Learning Studio nach dem Namen Ihres Arbeitsbereichs.
- Wählen Sie den Namen Ihres Arbeitsbereichs aus, um die Ressourcengruppe und die Abonnement-ID anzuzeigen.
- Kopieren Sie die Werte für die Ressourcengruppe und die Abonnement-ID in den Code.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Das Ausführen dieses Skripts führt zu einem Handle für den Arbeitsbereich, das Sie für die Verwaltung anderer Ressourcen und Aufträge verwenden.
Hinweis
- Beim Erstellen von
MLClientwird keine Verbindung des Clients mit dem Arbeitsbereich hergestellt. Die Clientinitialisierung ist ein langsamer Vorgang, bei dem gewartet wird, bis erstmals ein Aufruf erfolgen muss. In diesem Artikel geschieht dies während der Computeerstellung.
Erstellen einer Computeressource
Azure Machine Learning benötigt eine Computeressource, um einen Auftrag auszuführen. Bei dieser Ressource kann es sich um Computer mit einem oder mehreren Knoten mit Linux- oder Windows-Betriebssystemen oder um ein spezielles Computefabric wie Spark handeln.
Im folgenden Beispielskript wird ein Linux-compute cluster bereitgestellt. Auf der Seite Azure Machine Learning pricing finden Sie die vollständige Liste der VM-Größen und Preise. Da für dieses Beispiel ein GPU-Cluster benötigt wird, wählen Sie ein Modell des Typs STANDARD_NC6 aus und erstellen eine Azure Machine Learning-Computeressource.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Erstellen der Auftragsumgebung
Um einen Azure Machine Learning-Auftrag auszuführen, benötigen Sie eine Umgebung. Eine Azure Machine Learning-Umgebung kapselt die Abhängigkeiten (z. B. Softwareruntime und Bibliotheken), die zum Ausführen des Machine Learning-Trainingsskripts auf Ihrer Computeressource erforderlich sind. Diese Umgebung ähnelt einer Python-Umgebung auf Ihrem lokalen Computer.
Azure Machine Learning ermöglicht Ihnen, eine zusammengestellte (oder vorgefertigte) Umgebung zu verwenden, die für allgemeine Trainings- und Rückschlussszenarien nützlich ist, oder eine benutzerdefinierte Umgebung mithilfe eines Docker-Images oder einer Conda-Konfiguration zu erstellen.
In diesem Artikel verwenden Sie die kuratierte Azure Machine Learning-Umgebung AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu. Verwenden Sie die neueste Version dieser Umgebung mithilfe der @latest-Anweisung.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"Konfigurieren und Übermitteln Ihres Trainingsauftrags
In diesem Abschnitt wird mit der Einführung der Daten für das Training begonnen. Anschließend wird behandelt, wie Sie einen Trainingsauftrag mit einem bereitgestellten Trainingsskript ausführen. Sie lernen, den Trainingsauftrag zu erstellen, indem Sie den Befehl zum Ausführen des Trainingsskript konfigurieren. Danach übermitteln Sie den Trainingsauftrag zur Ausführung in Azure Machine Learning.
Abrufen der Trainingsdaten
Sie verwenden Daten aus der MNIST-Datenbank (Modified National Institute of Standards and Technology) handschriftlicher Ziffern. Diese Daten werden von der Website von Yan LeCun abgerufen und in einem Azure Storage-Konto gespeichert.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Weitere Informationen zum MNIST-Dataset finden Sie auf der Website von Yan LeCun.
Vorbereiten des Trainingsskripts
In diesem Artikel haben Sie das Trainingsskript tf_mnist.py bereitgestellt. In der Praxis sollten Sie benutzerdefinierte Trainingsskripts unverändert übernehmen und mit Azure Machine Learning ausführen können, ohne Ihren Code ändern zu müssen.
Das bereitgestellte Trainingsskript erledigt Folgendes:
- Es übernimmt die Vorverarbeitung der Daten und teilt die Daten in Test- und Trainingsdaten auf.
- Es trainiert ein Modell mit den Daten.
- Es gibt das Ausgabemodell zurück.
Während der Pipelineausführung verwenden Sie MLflow, um die Parameter und Metriken zu protokollieren. Informationen zum Aktivieren der MLflow-Nachverfolgung finden Sie unter Nachverfolgen von ML-Experimenten und -Modellen mit MLflow.
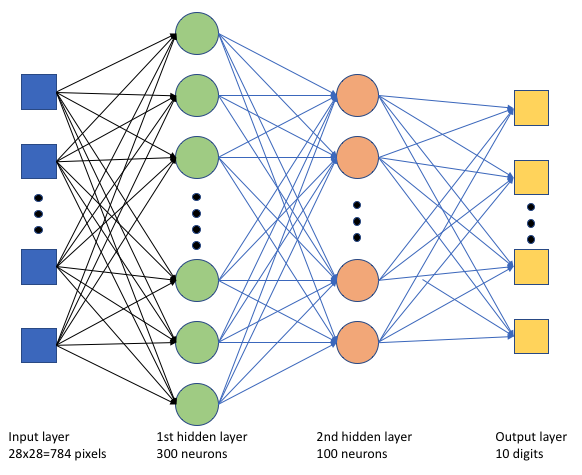
Im Trainingsskript tf_mnist.py wird ein einfaches Deep Neural Network (DNN) erstellt. Dieses DNN weist Folgendes auf:
- Eine Eingabeschicht mit 28 × 28 = 784 Neuronen. Jedes Neuron stellt ein Bildpixel dar.
- Zwei verborgene Schichten. Die erste ausgeblendete Schicht verfügt über 300 Neuronen, und die zweite ausgeblendete Schicht verfügt über 100 Neuronen.
- Eine Ausgabeschicht mit 10 Neuronen. Jedes Neuron stellt eine zielgerichtete Bezeichnung von 0 bis 9 dar.
Erstellen des Trainingsauftrags
Sie verfügen jetzt über alle für die Ausführung des Auftrags erforderlichen Objekte und können den Auftrag mit dem Azure Machine Learning Python SDK v2 erstellen. In diesem Beispiel erstellen Sie einen command.
In Azure Machine Learning ist ein command eine Ressource, die alle erforderlichen Details zum Ausführen Ihres Trainingscodes in der Cloud angibt. Diese Details umfassen die Eingaben und Ausgaben, die Art der zu verwendenden Hardware, zu installierende Software und Angaben zum Ausführen des Codes. Der command enthält Informationen zum Ausführen eines einzelnen Befehls.
Konfigurieren des Befehls
Sie verwenden den universellen Befehl (command), um das Trainingsskript und die gewünschten Aufgaben auszuführen. Erstellen Sie ein Command-Objekt, um die Konfigurationsdetails Ihres Trainingsauftrags anzugeben.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Die Eingaben für diesen Befehl umfassen den Datenspeicherort, die Batchgröße, die Anzahl der Neuronen in der ersten und zweiten Schicht und die Lernrate. Beachten Sie, dass der Webpfad direkt als Eingabe übergeben wurde.
Führen Sie für die Parameterwerte folgende Schritte aus:
- Geben Sie den Computecluster
gpu_compute_target = "gpu-cluster"an, den Sie für die Ausführung dieses Befehls erstellt haben. - Stellen Sie die zusammengestellte Umgebung
curated_env_namebereit, die Sie zuvor deklariert haben. - Konfigurieren Sie die eigentliche Befehlszeilenaktion, in diesem Fall mit dem Befehl
python tf_mnist.py. Sie können über die${{ ... }}-Notation auf die Eingaben und Ausgaben im Befehl zugreifen. - Konfigurieren Sie Metadaten wie den Anzeigenamen und den Experimentnamen. Dabei ist ein Experiment ein Container für alle Iterationen, die für ein bestimmtes Projekt durchlaufen werden. Alle mit demselben Experimentnamen übermittelten Aufträge werden nebeneinander in Azure Machine Learning Studio aufgelistet.
- Geben Sie den Computecluster
In diesem Beispiel verwenden Sie den
UserIdentity, um den Befehl auszuführen. Die Verwendung einer Benutzeridentität bedeutet, dass der Befehl unter Ihrer Identität den Auftrag ausführt und auf die Daten aus dem Blob zugreift.
Übermitteln des Auftrags
Jetzt ist es an der Zeit, den Auftrag zur Ausführung in Azure Machine Learning zu übermitteln. Dieses Mal verwenden Sie create_or_update für ml_client.jobs.
ml_client.jobs.create_or_update(job)Nach dem Abschluss registriert der Auftrag ein Modell in Ihrem Arbeitsbereich (als Ergebnis des Trainings) und gibt einen Link zum Anzeigen des Auftrags in Azure Machine Learning Studio aus.
Warnung
Zum Ausführen von Trainingsskripts wird von Azure Machine Learning das gesamte Quellverzeichnis kopiert. Sind vertrauliche Daten vorhanden, die nicht hochgeladen werden sollen, verwenden Sie eine IGNORE-Datei, oder platzieren Sie diese Daten nicht im Quellverzeichnis.
Was geschieht während der Auftragsausführung?
Die Ausführung des Auftrags durchläuft die folgenden Phasen:
Vorbereitung: Ein Docker-Image wird entsprechend der definierten Umgebung erstellt. Das Image wird in die Containerregistrierung des Arbeitsbereichs hochgeladen und für spätere Ausführungen zwischengespeichert. Darüber hinaus werden Protokolle in den Auftragsverlauf gestreamt, mit deren Hilfe der Status überwacht werden kann. Bei Angabe einer zusammengestellten Umgebung wird das zwischengespeicherte Image verwendet, das diese zusammengestellte Umgebung unterstützt.
Skalierung: Der Cluster versucht ein Hochskalieren, wenn mehr Knoten zur Ausführung benötigt werden, als derzeit verfügbar sind.
Wird ausgeführt: Alle Skripts im Skriptordner src werden auf das Computeziel hochgeladen, Datenspeicher werden eingebunden oder kopiert, und das Skript wird ausgeführt. Ausgaben aus stdout und dem Ordner ./logs werden in den Auftragsverlauf gestreamt und können zur Überwachung des Auftrags verwendet werden.
Optimieren von Modellhyperparametern
Nachdem Sie gesehen haben, wie eine TensorFlow-Trainingsausführung über das SDK stattfindet, geht es nun darum, ob Sie die Genauigkeit Ihres Modells weiter verbessern können. Sie können die Hyperparameter Ihres Modells mithilfe der sweep-Funktionen von Azure Machine Learning fein abstimmen und optimieren.
Um die Hyperparameter des Modells zu optimieren, definieren Sie den Parameterraum, in dem während des Trainings gesucht werden soll. Dazu ersetzen Sie einige der Parameter (batch_size, first_layer_neurons, second_layer_neurons und learning_rate), die an den Trainingsauftrag übergeben werden, durch spezielle Eingaben aus dem Paket azure.ml.sweep.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Anschließend konfigurieren Sie den Befehlsauftrag mit einigen Sweep-spezifischen Parametern, z. B. der primär zu überwachenden Metrik und dem zu verwendenden Stichprobenalgorithmus.
Im folgenden Code werden zufällige Stichproben verwendet, um verschiedene konfigurierte Hyperparametergruppen auszuprobieren und die primäre Metrik validation_acc zu maximieren.
Außerdem wird eine Richtlinie zur vorzeitigen Beendigung definiert, BanditPolicy. Diese Richtlinie überprüft den Auftrag alle zwei Iterationen. Wenn die primäre Metrik validation_acc außerhalb des Bereichs der oberen 10 % liegt, beendet Azure Machine Learning den Auftrag. Dadurch wird das Modell daran gehindert, Hyperparameter zu verfolgen, die zum Erreichen der Zielmetrik nicht geeignet sind.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Jetzt können Sie diesen Auftrag wie zuvor übermitteln. Diesmal führen Sie einen Sweepauftrag aus, der Ihren Trainingsauftrag durchläuft.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Sie können den Auftrag mithilfe des Links zur Studio-Benutzeroberfläche überwachen, der während der Auftragsausführung angezeigt wird.
Suchen und Registrieren des besten Modells
Sobald alle Ausführungen abgeschlossen sind, können Sie nach der Ausführung suchen, die das Modell mit der höchsten Genauigkeit produziert hat.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Dieses Modell können Sie dann registrieren.
registered_model = ml_client.models.create_or_update(model=model)Bereitstellen des Modells als Onlineendpunkt
Nachdem Sie Ihr Modell registriert haben, können Sie es als Onlineendpunkt bereitstellen, also als Webdienst in der Azure-Cloud.
Um einen Dienst für maschinelles Lernen bereitzustellen, benötigen Sie normalerweise Folgendes:
- Die Modellressourcen, die Sie bereitstellen möchten. Zu diesen Ressourcen gehören die Datei und die Metadaten des Modells, die Sie bereits in Ihrem Trainingsauftrag registriert haben.
- Code, der als Dienst ausgeführt werden soll. Der Code führt das Modell für eine bestimmte Eingabeanforderung (ein Einstiegsskript) aus. Dieses Einstiegsskript empfängt an einen bereitgestellten Webdienst übermittelte Daten und übergibt sie an das Modell. Nachdem das Modell die Daten verarbeitet hat, gibt das Skript die Antwort des Modells an den Client zurück. Das Skript ist modellspezifisch und muss die vom Modell erwarteten und zurückgegebenen Daten verstehen. Wenn Sie ein MLflow-Modell verwenden, erstellt Azure Machine Learning dieses Skript automatisch für Sie.
Weitere Informationen zur Bereitstellung finden Sie unter Bereitstellen und Bewerten eines Machine Learning-Modells mit verwaltetem Onlineendpunkt mithilfe des Python SDK v2.
Erstellen eines neuen Onlineendpunkts
Zum Bereitstellen Ihres Modells müssen Sie als Erstes Ihren Onlineendpunkt erstellen. Der Endpunktname muss innerhalb der gesamten Azure-Region eindeutig sein. Im Rahmen dieses Artikels erstellen Sie einen eindeutigen Namen mit einem universellen eindeutigen Bezeichner (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Wenn Sie den Endpunkt erstellt haben, können Sie ihn wie folgt abrufen:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Bereitstellen des Modells für den Endpunkt
Nach dem Erstellen des Endpunkts können Sie das Modell mit dem Einstiegsskript bereitstellen. Ein Endpunkt kann mehrere Bereitstellungen aufweisen. Mithilfe von Regeln kann der Endpunkt dann den Datenverkehr an diese Bereitstellungen weiterleiten.
Im folgenden Code erstellen Sie eine einzige Bereitstellung, die 100 % des eingehenden Datenverkehrs verarbeitet. Wählen Sie einen beliebigen Farbnamen (tff-blue) für die Bereitstellung aus. Sie können auch einen anderen Namen wie tff-grün oder tff-rot für die Bereitstellung verwenden. Der Code zum Bereitstellen des Modells auf dem Endpunkt führt Folgendes aus:
- Er stellt die beste Version des Modells bereit, das Sie zuvor registriert haben.
- Er bewertet das Modell mithilfe der Datei
score.py. - Er verwendet die gleiche zusammengestellte Umgebung, die Sie zuvor deklariert haben, um dem Rückschluss durchzuführen.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Hinweis
Gehen Sie davon aus, dass diese Bereitstellung etwas Zeit in Anspruch nimmt.
Testen der Bereitstellung mit einer Beispielabfrage
Nachdem Sie das Modell nun auf dem Endpunkt bereitgestellt haben, können Sie die Ausgabe des bereitgestellten Modells mithilfe der invoke-Methode auf dem Endpunkt vorhersagen. Verwenden Sie zum Ausführen des Rückschlusses die Beispielanforderungsdatei sample-request.json aus dem Ordner request.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Anschließend können Sie die zurückgegebenen Vorhersagen drucken und zusammen mit den Eingabebildern grafisch darstellen. Verwenden Sie rote Schrift und ein inverses Bild (Weiß auf Schwarz), um falsch klassifizierte Stichproben hervorzuheben.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Hinweis
Da die Modellgenauigkeit hoch ist, müssen Sie möglicherweise die Zelle einige Male ausführen, bevor Sie eine falsch klassifizierte Stichprobe sehen.
Bereinigen von Ressourcen
Wenn Sie den Endpunkt nicht verwenden, löschen Sie ihn, um die Verwendung der Ressource zu beenden. Vergewissern Sie sich, dass der Endpunkt nicht von anderen Bereitstellungen verwendet wird, bevor Sie ihn löschen.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Hinweis
Gehen Sie davon aus, dass diese Bereinigung etwas Zeit in Anspruch nimmt.
Nächste Schritte
In diesem Artikel haben Sie ein TensorFlow-Modell trainiert und registriert. Sie haben das Modell auch auf einem Onlineendpunkt bereitgestellt. Weitere Informationen zu Azure Machine Learning finden Sie in den folgenden Artikeln.