Vorbereiten von Daten für Aufgaben zum maschinellen Sehen mit automatisiertem ML
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Wichtig
Die Unterstützung für das Trainieren von Modellen für maschinelles Sehen mit automatisiertem ML in Azure Machine Learning ist ein experimentelles Feature, das sich in der öffentlichen Vorschau befindet. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel erfahren Sie, wie Sie Bilddaten für das Trainieren von Modellen für maschinelles Sehen mit automatisiertem maschinellem Lernen in Azure Machine Learning vorbereiten. Um Modelle für Aufgaben zum maschinellen Sehen mit automatisiertem maschinellem Lernen zu generieren, müssen Sie beschriftete Bilddaten als Eingabe für das Modelltraining in Form eines MLTable verwenden.
Sie können eine MLTable aus beschrifteten Trainingsdaten im JSONL-Format erstellen. Wenn Ihre beschrifteten Trainingsdaten in einem anderen Format vorliegen, wie Pascal Visual Object Classes (VOC) oder COCO, können Sie ein Konvertierungsskript verwenden, um sie in JSONL zu konvertieren und dann eine MLTable zu erstellen. Alternativ können Sie das Datenbeschriftungstool von Azure Machine Learning verwenden, um Bilder manuell zu beschriften. Exportieren Sie dann die bezeichneten Daten, die für das Training Ihres AutoML-Modells verwendet werden sollen.
Voraussetzungen
- Kenntnis der akzeptierten Schemas für JSONL-Dateien für AutoML-Experimente für maschinelles Sehen
Abrufen beschrifteter Daten
Um Modelle für maschinelles Sehen mit AutoML zu trainieren, müssen Sie beschriftete Trainingsdaten abrufen. Die Bilder müssen in die Cloud hochgeladen werden. Beschriftungsanmerkungen müssen im JSONL-Format vorliegen. Sie können entweder das Azure Machine Learning-Datenbeschriftungstool zum Beschriften Ihrer Daten verwenden oder mit bereits beschrifteten Bilddaten beginnen.
Verwenden des Azure Machine Learning-Datenbeschriftungstools zum Beschriften Ihrer Trainingsdaten
Wenn Sie über keine bereits beschrifteten Daten verfügen, können Sie unter Verwendung des Datenbeschriftungstools von Azure Machine Learning Bilder manuell beschriften. Dieses Tool generiert automatisch die für das Training erforderlichen Daten im akzeptierten Format. Weitere Informationen finden Sie unter Einrichten eines Bildbezeichnungsprojekts.
Das Tool unterstützt Sie beim Erstellen, Verwalten und Überwachen von Datenbeschriftungsaufgaben für:
- Bildklassifizierung (mehrere Klassen und mehrere Beschriftungen)
- Objekterkennung (Begrenzungsrahmen)
- Instanzsegmentierung (Polygon)
Wenn Sie bereits die zu verwendenden Daten beschriftet haben, können Sie diese beschrifteten Daten als Azure Machine Learning-Dataset exportieren und in Azure Machine Learning Studio auf der Registerkarte Datasets auf das Dataset zugreifen. Sie können dieses exportierte Dataset im azureml:<tabulardataset_name>:<version>-Format als Eingabe verwenden. Weitere Informationen finden Sie unter Exportieren der Bezeichnungen.
Es folgt ein Beispiel dafür, wie Sie ein vorhandenes Dataset als Eingabe für das Training von Modellen für maschinelles Sehen verwenden können.
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Verwenden von vorab beschrifteten Trainingsdaten von lokalen Computern
Wenn Sie beschriftete Daten haben, die Sie zum Trainieren Ihres Modells verwenden möchten, laden Sie die Bilder in Azure hoch. Sie können Ihre Bilder in den standardmäßigen Azure Blob Storage Ihres Azure Machine Learning-Arbeitsbereichs hochladen. Registrieren Sie es als Datenressource. Weitere Informationen finden Sie unter Erstellen und Verwalten von Datenressourcen.
Das folgende Skript lädt die Bilddaten auf Ihrem lokalen Computer unter dem Pfad ./data/odFridgeObjects in den Datenspeicher von Azure Blob Storage hoch. Dann erstellt es ein neues Datenobjekt mit dem Namen fridge-items-images-object-detection in Ihrem Azure Machine Learning-Arbeitsbereich.
Wenn in Ihrem Azure Machine Learning-Arbeitsbereich bereits ein Datenobjekt namens fridge-items-images-object-detection vorhanden ist, aktualisiert der Code die Versionsnummer des Objekts und verweist auf den neuen Speicherort, in den die Bilddaten hochgeladen wurden.
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Erstellen Sie eine YML-Datei mit der folgenden Konfiguration.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
Um die Bilder als Datenressource hochzuladen, führen Sie den folgenden CLI-v2-Befehl mit den Pfad zu Ihrer YML-Datei, dem Arbeitsbereichsnamen, der Ressourcengruppe und der Abonnement-ID aus.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Wenn Sie Ihre Daten bereits in einem vorhandenen Datenspeicher haben, können Sie daraus eine Datenressource erstellen. Geben Sie den Pfad zu den Daten im Datenspeicher anstelle des Pfads Ihres lokalen Computers an. Aktualisieren Sie den vorherigen Code durch den folgenden Codeschnipsel.
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Erstellen Sie eine YML-Datei mit der folgenden Konfiguration.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
Als Nächstes rufen Sie die Beschriftungsanmerkungen im JSONL-Format ab. Das Schema der beschrifteten Daten hängt davon ab, welche Aufgabe für maschinelles Sehen durchgeführt werden soll. Weitere Informationen zum erforderlichen JSONL-Schema für jeden Aufgabentyp finden Sie unter Datenschemata zum Trainieren von Modellen für Maschinelles Sehen mit automatisiertes ML.
Wenn Ihre Trainingsdaten in einem anderen Format vorliegen (z. B. Pascal VOC oder COCO), können Hilfsskripts die Daten in JSONL konvertieren. Die Skripts stehen in den Notebook-Beispielen zur Verfügung.
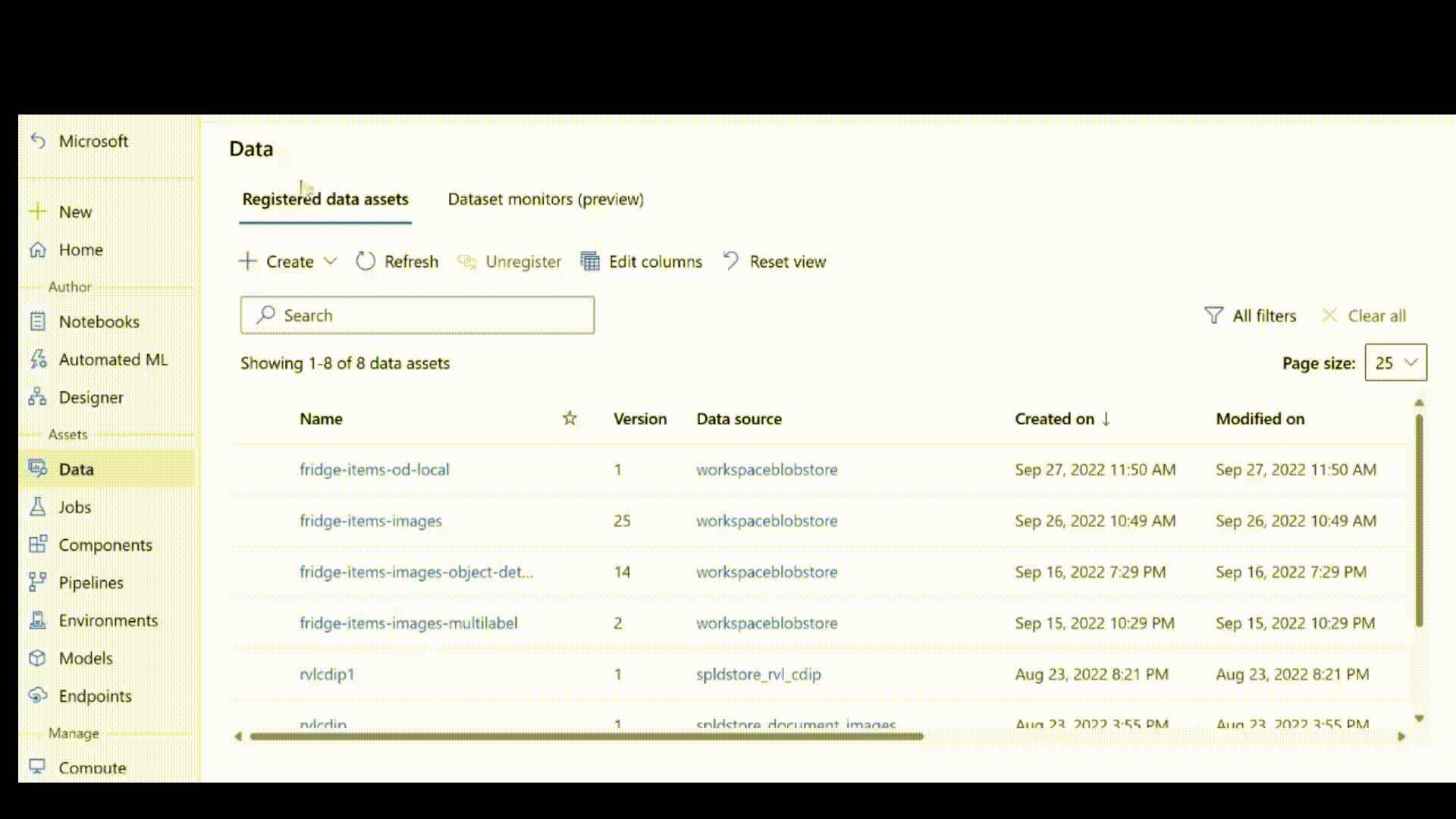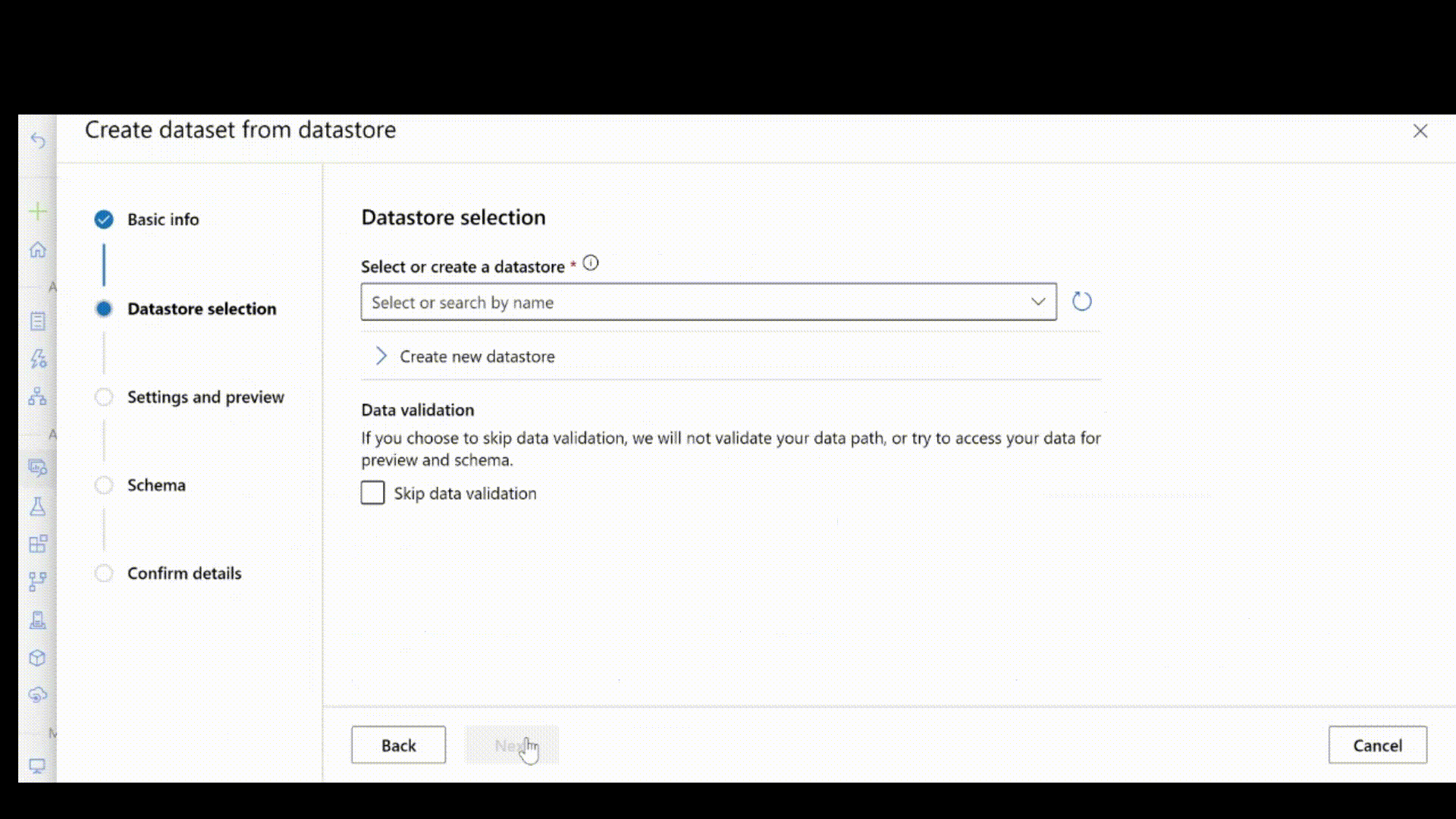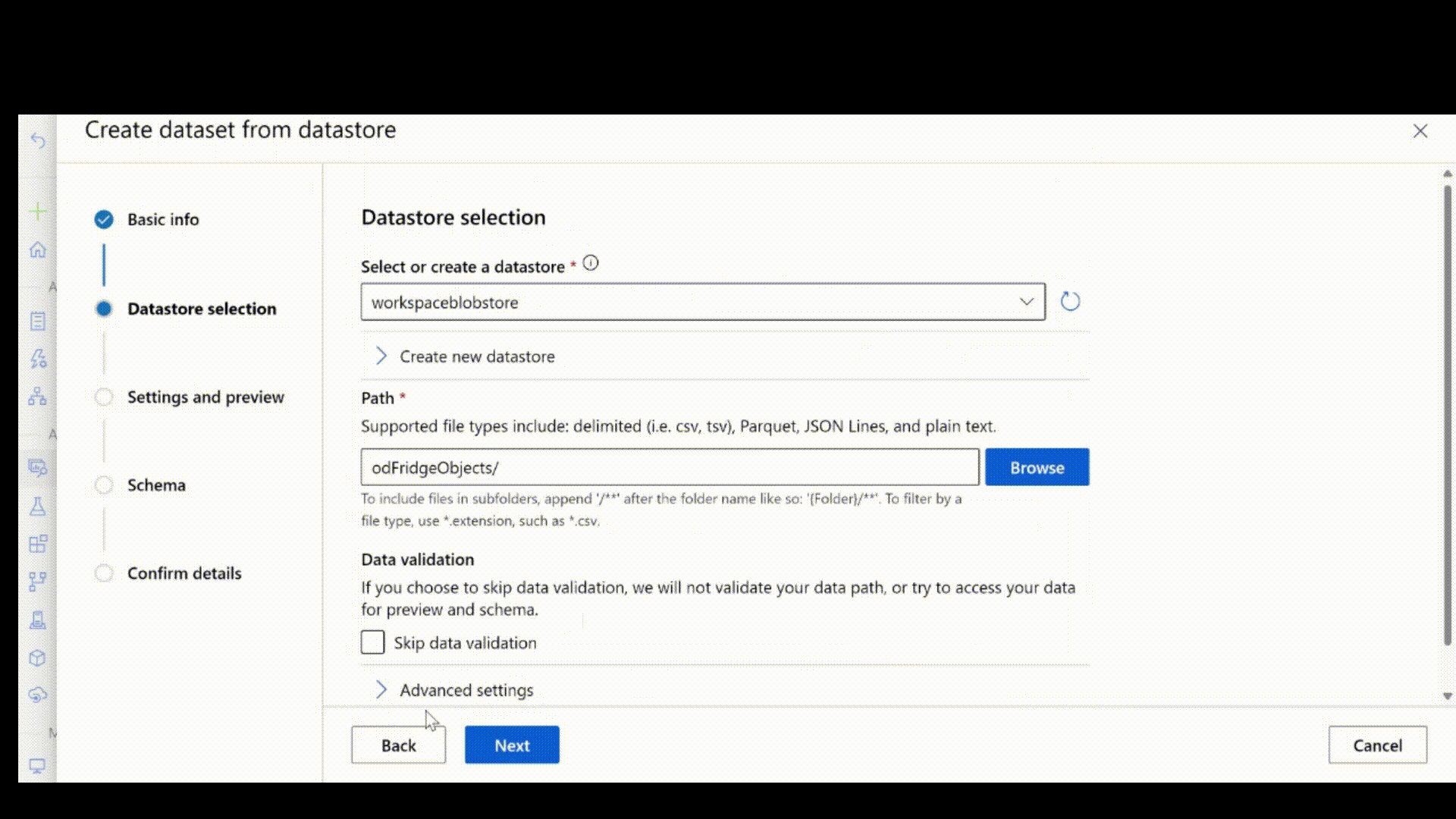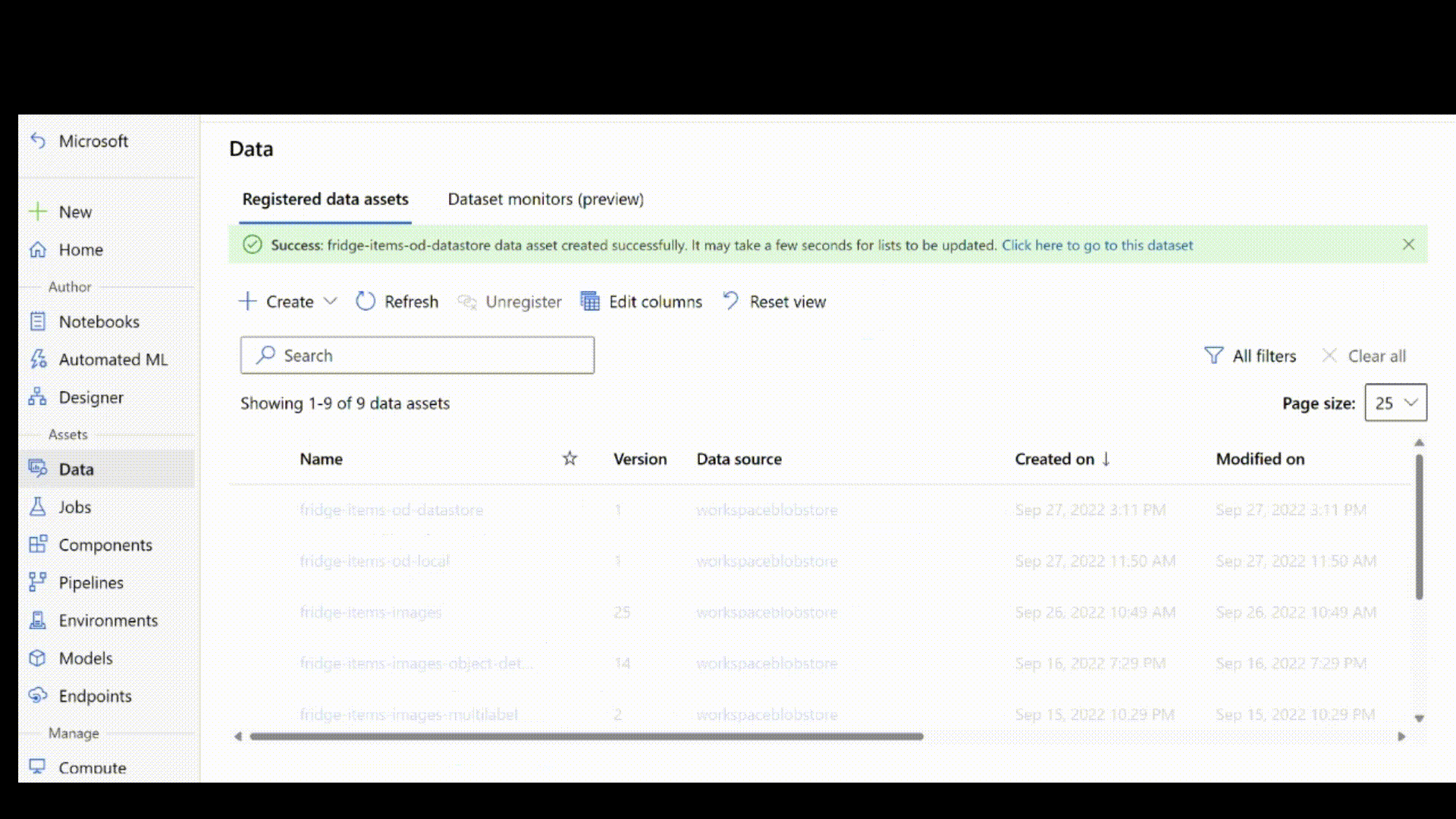
Nachdem Sie die JSONL-Datei erstellt haben, können Sie sie mithilfe der Benutzeroberfläche als Datenressource registrieren. Vergewissern Sie sich, dass Sie im Abschnitt „Schema“ den Typ stream auswählen, wie in dieser Animation gezeigt.
Verwenden von bereits beschrifteten Trainingsdaten aus Azure Blob Storage
Wenn Ihre beschrifteten Trainingsdaten in einem Container in Azure Blob Storage vorhanden sind, können Sie direkt darauf zugreifen. Erstellen Sie einen Datenspeicher für diesen Container. Weitere Informationen finden Sie unter Erstellen und Verwalten von Datenressourcen.
Erstellen einer MLTable
Nachdem Ihre beschrifteten Daten im JSONL-Format vorliegen, können Sie sie wie in diesem YAML-Schnipsel gezeigt verwenden, um eine MLTable zu erstellen. MLTable verpackt Ihre Daten in einem Objekt, das zum Trainieren genutzt werden kann.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Anschließend können Sie die MLTable als Dateneingabe für Ihren AutoML-Trainingsauftrag übergeben. Weitere Informationen finden Sie unter Einrichten von AutoML zum Trainieren von Modellen zum maschinellen Sehen.