Erläutern von ML-Modellen und -Vorhersagen mithilfe des Python-Interpretierbarkeitspakets (Vorschau)
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Leitfaden erfahren Sie, wie Sie das Interpretierbarkeitspaket des Python-SDK für Azure Machine Learning für die folgenden Aufgaben nutzen können:
Erläutern Sie das gesamte Modellverhalten oder einzelne Vorhersagen lokal auf Ihrem persönlichen Computer.
Aktivieren Sie Techniken zur Interpretierbarkeit von entwickelten Features.
Erläutern Sie das Verhalten für das gesamte Modell und einzelne Vorhersagen in Azure.
Laden Sie Erklärungen zum Azure Machine Learning-Ausführungsverlauf hoch.
Verwenden Sie ein Visualisierungsdashboard, um sowohl in einem Jupyter Notebook als auch in Azure Machine Learning Studio mit Ihren Modellerklärungen zu interagieren.
Stellen Sie einen Bewertungsexplainer mit Ihrem Modell bereit, um die Erklärungen während der Rückschlüsse zu beobachten.
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Weitere Informationen zu den unterstützten Interpretierbarkeitstechniken und den Modellen des maschinellen Lernens finden Sie unter Modellinterpretierbarkeit in Azure Machine Learning und Beispielnotebooks.
Eine Anleitung zum Aktivieren der Interpretierbarkeit für Modelle, die mit automatisiertem maschinellem Lernen trainiert wurden, finden Sie unter Interpretierbarkeit: Modellerklärungen beim automatisierten maschinellen Lernen (Vorschau).
Generieren des Werts für die Featurerelevanz auf Ihrem persönlichen Computer
Das folgende Beispiel zeigt, wie Sie das Interpretierbarkeitspaket auf Ihrem persönlichen Computer verwenden, ohne auf Azure-Dienste zurückzugreifen.
Installieren Sie das
azureml-interpret-Paket.pip install azureml-interpretTrainieren Sie ein Beispielmodell in einem lokalen Jupyter Notebook.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Rufen Sie den Explainer lokal auf.
- Übergeben Sie das Modell und einige Trainingsdaten an den Konstruktor des Explainers, um ein Explainer-Objekt zu initialisieren.
- Sie können während der Klassifizierung optional auch Namen von Features und Ausgabeklassen übergeben, mit denen Ihre Erklärungen und Visualisierungen informativer gestaltet werden.
Die folgenden Codeblocks veranschaulichen, wie ein Explainer-Objekt mit
TabularExplainer,MimicExplainerundPFIExplainerlokal instanziiert wird.TabularExplainerruft einen der drei SHAP-Explainer darunter auf (TreeExplainer,DeepExplaineroderKernelExplainer).TabularExplainerwählt automatisch den Explainer aus, der für Ihren Anwendungsfall geeignet ist, aber Sie können jeden der drei zugrunde liegenden Explainer direkt aufrufen.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)oder
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)oder
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Erläutern des gesamten Modellverhalten (globale Erklärung)
Die aggregierten (globalen) Featurerelevanzwerte können Sie dem nachfolgenden Beispiel entnehmen.
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Erläutern einer individuellen Vorhersage (lokale Erklärung)
Rufen Sie die Relevanzwerte individueller Features von verschiedenen Datenpunkten ab, indem Sie eine einzelne Instanz oder eine Gruppe von Instanzen erklären.
Hinweis
PFIExplainer unterstützt keine lokalen Erklärungen.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Rohfeaturetransformationen
Sie können Erklärungen in Bezug auf rohe, unveränderte Features anstelle von entwickelten Features abonnieren. Bei dieser Option übergeben Sie Ihre Featuretransformationspipeline an den Explainer in train_explain.py. Andernfalls bietet der Explainer Erklärungen in Bezug auf entwickelte Features.
Das Format der unterstützten Transformationen entspricht dem unter sklearn-pandas beschriebenen. Grundsätzlich werden alle Transformationen unterstützt, solange sie eine einzelne Spalte verarbeiten, sodass sie eindeutig eine 1:n-Transformation darstellen.
Erhalten Sie eine Erklärung für Rohfeatures, indem Sie sklearn.compose.ColumnTransformer oder eine Liste mit passenden Transformationstupeln verwenden. Im folgenden Beispiel wird sklearn.compose.ColumnTransformer verwendet.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Verwenden Sie den folgenden Code, falls Sie das Beispiel mit der Liste mit den passenden Transformationstupeln ausführen möchten:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Generieren von Featurerelevanzwerten über Remoteausführungen
Das folgende Beispiel zeigt die Verwendung der ExplanationClient-Klasse zum Aktivieren der Modellinterpretierbarkeit für Remoteausführungen. Es ähnelt dem lokalen Prozess, aber Sie:
- verwenden
ExplanationClientin der Remoteausführung, um den Interpretbarkeitskontext hochzuladen. - laden den Kontext später in einer lokalen Umgebung herunter.
Installieren Sie das
azureml-interpret-Paket.pip install azureml-interpretErstellen Sie ein Trainingsskript in einem lokalen Jupyter Notebook. Beispiel:
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Legen Sie ein Azure Machine Learning Compute-Ziel fest, und übermitteln Sie dann eine Trainingsausführung. Anweisungen finden Sie unter Erstellen und Verwalten von Azure Machine Learning-Computeclustern. Die Beispielnotebooks könnten Sie auch interessieren.
Laden Sie die Erklärung in Ihr lokales Jupyter Notebook herunter.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Visualisierungen
Nachdem Sie die Erklärungen in Ihre lokale Jupyter Notebook-Instanz heruntergeladen haben, können Sie Ihr Modell anhand der Visualisierungen auf dem Erklärungsdashboard auswerten und interpretieren. Verwenden Sie den folgenden Code, um das Erklärungsdashboard-Widget in Ihrer Jupyter Notebook-Instanz zu laden:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Die Visualisierungen unterstützen Erklärungen für entwickelte Features sowie für Features im Rohformat. Erklärungen im Rohformat basieren auf den Features des ursprünglichen Datasets, und Erklärungen im entwickelten Format basieren auf den Features des Datasets mit Anwendung von Feature Engineering („Featurisierung“).
Beim Interpretieren eines Modells in Bezug auf das ursprüngliche Dataset wird empfohlen, Erklärungen im Rohformat zu nutzen, da jede Featurerelevanz jeweils einer Spalte aus dem ursprünglichen Dataset entspricht. Ein Szenario, in dem Erklärungen im entwickelten Format ggf. hilfreich sind, sind Untersuchungen der Auswirkung einzelner Kategorien eines kategorischen Features. Wenn eine 1-Hot-Codierung auf ein kategorisches Feature angewendet wird, enthalten die sich ergebenden Erklärungen im entwickelten Format einen anderen Relevanzwert pro Kategorie (einen pro entwickeltem Feature mit 1-Hot-Codierung). Diese Codierung kann hilfreich sein, wenn eingegrenzt werden soll, welcher Teil des Datasets für das Modell die meisten Informationen enthält.
Hinweis
Erklärungen im entwickelten und im Rohformat werden sequenziell berechnet. Zuerst wird basierend auf der Modell- und Featurisierungspipeline eine entwickelte Erklärung erstellt. Anschließend wird basierend auf dieser entwickelten Erklärung die Erklärung im Rohformat erstellt, indem die Relevanz der entwickelten Features, die aus demselben Rohfeature stammen, aggregiert wird.
Erstellen, Bearbeiten und Anzeigen von Datasetkohorten
Im oberen Menüband wird die Gesamtstatistik für Ihr Modell und die Daten angezeigt. Sie können Ihre Daten in Datasetkohorten oder Untergruppen aufteilen, um die Leistung Ihres Modells und die Erklärungen für diese definierten Untergruppen zu untersuchen bzw. zu vergleichen. Indem Sie Ihre Datasetstatistik und die Erklärungen für diese Untergruppen vergleichen, können Sie ermitteln, warum in bestimmten Gruppen ggf. Fehler auftreten.

Verstehen des gesamten Modellverhalten (globale Erklärung)
Die ersten drei Registerkarten im Dashboard für die Erklärungen enthalten eine Gesamtanalyse des trainierten Modells mit den zugehörigen Vorhersagen und Erklärungen.
Modellleistung
Evaluieren Sie die Leistung Ihres Modells, indem Sie die Verteilung Ihrer Vorhersagewerte und die Werte Ihrer Modellleistungsmetriken untersuchen. Sie können Ihr Modell genauer untersuchen, indem Sie sich eine vergleichende Analyse der Leistung für verschiedene Kohorten oder Untergruppen Ihres Datasets ansehen. Wählen Sie Filter für den Y-Wert und X-Wert aus, um unterschiedliche Dimensionen anzuzeigen. Zeigen Sie Metriken an, z. B. Genauigkeit, Rückruf, False Positive-Rate (FPR) und False-Negative-Rate (FNR).

Dataset-Explorer
Untersuchen Sie Ihre Datasetstatistik, indem Sie unterschiedliche Filter für die X-, Y- und Farbachsen auswählen, um Ihre Daten in verschiedene Dimensionen zu unterteilen. Erstellen Sie oben Datasetkohorten, um Datasetstatistiken mit Filtern zu analysieren, z. B. in Bezug auf vorhergesagtes Ergebnis, Datasetfeatures und Fehlergruppen. Verwenden Sie das Zahnradsymbol in der oberen rechten Ecke des Graphen, um die Graphtypen zu ändern.

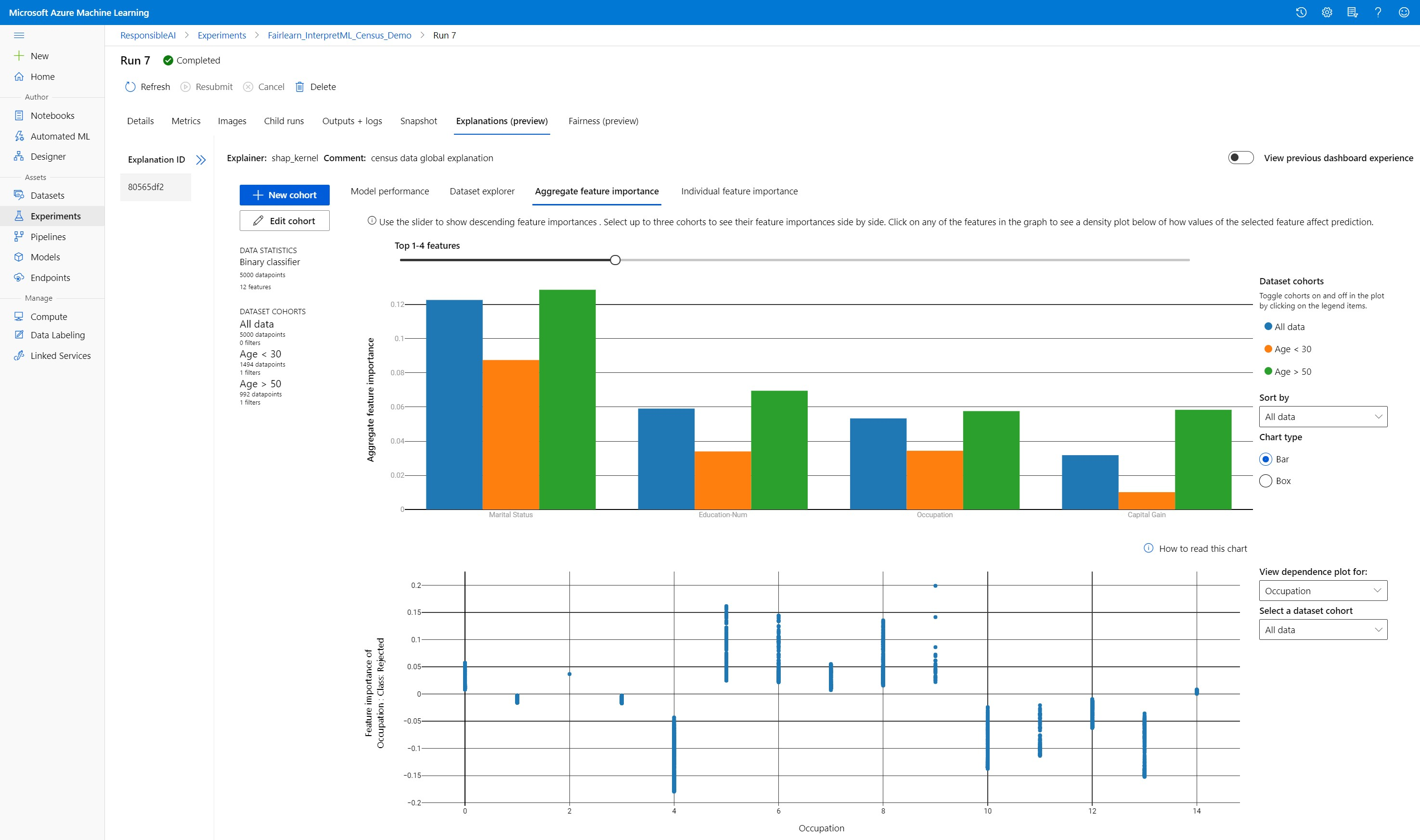
Aggregierte Featurerelevanz
Untersuchen Sie die Features mit Top-k-Relevanz, die sich auf Ihre Modellvorhersagen (auch als globale Erklärungen bezeichnet) insgesamt auswirken. Verwenden Sie den Schieberegler, um die Werte für die Featurerelevanz in absteigender Reihenfolge anzuzeigen. Wählen Sie bis zu drei Kohorten aus, um die entsprechenden Werte für die Featurerelevanz nebeneinander anzuzeigen. Wählen Sie im Graphen einen beliebigen Featurebalken aus, um anzuzeigen, wie sich die Werte des ausgewählten Features auf die Modellvorhersage unten im Abhängigkeitsplot auswirken.

Verstehen individueller Vorhersagen (lokale Erklärung)
Auf der vierten Registerkarte der Seite mit den Erklärungen können Sie einen Drilldown für einen Datenpunkt durchführen und die einzelnen Featurerelevanzwerte anzeigen. Sie können den jeweiligen Featurerelevanz-Plot für einen beliebigen Datenpunkt laden, indem Sie im Hauptpunktdiagramm auf einen beliebigen Datenpunkt klicken oder rechts im Bereichs-Assistenten einen bestimmten Datenpunkt auswählen.
| Plot | BESCHREIBUNG |
|---|---|
| Individuelle Featurerelevanz | Zeigt die wichtigsten Top-k-Features für eine individuelle Vorhersage an. Veranschaulicht das lokale Verhalten des zugrunde liegenden Modells an einem bestimmten Datenpunkt. |
| Was-wäre-wenn-Analyse | Ermöglicht das Vornehmen von Änderungen an Featurewerten des ausgewählten realen Datenpunkts und das Beobachten der sich ergebenden Änderungen des Vorhersagewerts, indem ein hypothetischer Datenpunkt mit den neuen Featurewerten generiert wird. |
| Individual Conditional Expectation (ICE) | Ermöglicht die Änderung von Featurewerten von einem Mindestwert zu einem Maximalwert. Veranschaulicht, wie sich bei einer Änderung des Features die Vorhersage des Datenpunkts ändert. |

Hinweis
Diese Erklärungen basieren auf vielen Näherungen und sind nicht die „Ursache“ von Vorhersagen. Wir raten Benutzern davon ab, basierend auf den Featurestörungen des Was-wäre-wenn-Tools Entscheidungen für das reale Leben zu treffen, sofern nicht die absolute mathematische Belastbarkeit der kausalen Rückschlüsse sichergestellt ist. Dieses Tool dient hauptsächlich dem Verständnis des Modells und zum Debuggen.
Visualisierung in Azure Machine Learning-Studio
Wenn Sie die Schritte zur Remoteinterpretierbarkeit (Hochladen der generierten Erklärungen in den Azure Machine Learning-Ausführungsverlauf) abgeschlossen haben, können Sie die Visualisierungen auf dem Erklärungsdashboard in Azure Machine Learning Studio anzeigen. Bei diesem Dashboard handelt es sich um eine einfachere Version des Dashboardwidgets, das in Ihrem Jupyter Notebook generiert wird. Die Generierung von Was-wäre-wenn-Datenpunkten und die ICE-Plots sind deaktiviert, da in Azure Machine Learning Studio keine aktive Computeressource vorhanden ist, mit der die Echtzeitberechnungen durchgeführt werden können.
Wenn die Dataset-, globalen und lokalen Erklärungen verfügbar sind, werden auf allen Registerkarten Daten eingefügt. Falls jedoch nur eine globale Erklärung verfügbar ist, wird die Registerkarte für „Individuelle Featurerelevanz“ deaktiviert.
Sie haben zwei Möglichkeiten, um auf das Erklärungsdashboard in Azure Machine Learning Studio zuzugreifen:
Bereich Experimente (Vorschau)
- Klicken Sie im linken Bereich auf Experimente, damit Ihnen eine Liste mit Experimenten angezeigt wird, die Sie in Azure Machine Learning ausgeführt haben.
- Wählen Sie ein bestimmtes Experiment aus, um alle Ausführungen in diesem Experiment anzuzeigen.
- Wählen Sie eine Ausführung aus, und klicken Sie dann auf die Registerkarte Erklärungen, um das Dashboard zur Erklärungsvisualisierung anzuzeigen.
Bereich Modelle
- Wenn Sie Ihr ursprüngliches Modell mithilfe der Schritte unter Bereitstellen von Modellen mit Azure Machine Learning registriert haben, können Sie Modelle im linken Bereich auswählen, um sie anzuzeigen.
- Wählen Sie ein Modell und anschließend die Registerkarte Erklärungen aus, um das Erklärungsdashboard anzuzeigen.

Interpretierbarkeit beim Ziehen von Rückschlüssen
Sie können den Explainer zusammen mit dem ursprünglichen Modell bereitstellen und ihn zur Rückschlusszeit verwenden, um die einzelnen Werte für die Featurerelevanz (lokale Erklärung) für beliebige neue Datenpunkte bereitzustellen. Wir bieten auch einfachere Bewertungsexplainer, um die Leistung der Interpretierbarkeit beim Ziehen von Rückschlüssen zu verbessern. Dies wird derzeit nur über das Azure Machine Learning SDK unterstützt. Der Bereitstellungsvorgang für einen einfacheren Bewertungsexplainer ähnelt der Bereitstellung eines Modells und umfasst die folgenden Schritte:
Erstellen Sie ein Erklärungsobjekt. Sie können z. B.
TabularExplainerverwenden:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Erstellen Sie mit dem Erklärungsobjekt einen Bewertungsexplainer.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Konfigurieren und Registrieren eines Images, das das Bewertungsexplainermodell verwendet
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Optional können Sie den Bewertungsexplainer aus der Cloud abrufen und die Erklärungen testen.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Stellen Sie das Image einem Computeziel bereit, indem Sie folgende Schritte ausführen:
Registrieren Sie gegebenenfalls Ihr ursprüngliches Vorhersagemodell mithilfe der Schritte unter Bereitstellen von Modellen mit Azure Machine Learning.
Erstellen Sie eine Bewertungsdatei.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Definieren Sie die Bereitstellungskonfiguration.
Diese Konfiguration hängt von den Anforderungen Ihres Modells ab. Das folgende Beispiel definiert eine Konfiguration, die einen CPU-Kern und 1 GB Arbeitsspeicher verwendet.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Erstellen Sie eine Datei mit Umgebungsabhängigkeiten.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Erstellen Sie ein benutzerdefiniertes Dockerfile mit installiertem g++.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Stellen Sie das erstellte Image bereit.
Dieser Vorgang dauert ca. 5 Minuten.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Testen Sie die Bereitstellung.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Bereinigen
Verwenden Sie zum Löschen eines bereitgestellten Webdiensts
service.delete().
Problembehandlung
Keine Unterstützung von Daten mit geringer Dichte: Da für das Dashboard für die Modellerklärungen Fehler auftreten können bzw. die Leistung erheblich verringert werden kann, wenn eine große Zahl von Features vorhanden ist, werden Daten mit geringer Dichte derzeit nicht unterstützt. Darüber hinaus treten bei großen Datasets und einer großen Anzahl von Features allgemeine Speicherprobleme auf.
Matrix für unterstützte Erklärungsfeatures
| Unterstützte Erklärungsregisterkarte | Rohfeatures (dicht) | Rohfeatures (mit geringer Dichte) | Entwickelte Features (dicht) | Entwickelte Features (mit geringer Dichte) |
|---|---|---|---|---|
| Modellleistung | Unterstützt (keine Vorhersage) | Unterstützt (keine Vorhersage) | Unterstützt | Unterstützt |
| Dataset-Explorer | Unterstützt (keine Vorhersage) | Wird nicht unterstützt. Da Daten mit geringer Dichte nicht hochgeladen werden und die Benutzeroberfläche Probleme beim Rendern von Daten mit geringer Dichte hat. | Unterstützt | Wird nicht unterstützt. Da Daten mit geringer Dichte nicht hochgeladen werden und die Benutzeroberfläche Probleme beim Rendern von Daten mit geringer Dichte hat. |
| Aggregierte Featurerelevanz | Unterstützt | Unterstützt | Unterstützt | Unterstützt |
| Individuelle Featurerelevanz | Unterstützt (keine Vorhersage) | Wird nicht unterstützt. Da Daten mit geringer Dichte nicht hochgeladen werden und die Benutzeroberfläche Probleme beim Rendern von Daten mit geringer Dichte hat. | Unterstützt | Wird nicht unterstützt. Da Daten mit geringer Dichte nicht hochgeladen werden und die Benutzeroberfläche Probleme beim Rendern von Daten mit geringer Dichte hat. |
Keine Unterstützung von Vorhersagemodellen für Modellerklärungen: Interpretierbarkeit, die beste Modellerklärung, ist nicht für AutoML-Vorhersageexperimente verfügbar, die die folgenden Algorithmen als bestes Modell empfehlen: TCNForecaster, AutoArima, ExponentialSmoothing, Average, Naive, Seasonal Average und Seasonal Naive. Bei Vorhersagen mit automatisiertem maschinellem Lernen unterstützen Regressionsmodelle auch Erklärungen. Im Erklärungsdashboard wird die Registerkarte „Individuelle Featurerelevanz“ aufgrund der Komplexität der Datenpipelines aber nicht für Vorhersagen unterstützt.
Lokale Erklärung für Datenindex: Das Erklärungsdashboard verfügt nicht über die Unterstützung für das Abgleichen der lokalen Relevanzwerte mit einem Zeilenbezeichner aus dem ursprünglichen Validierungsdataset, wenn das Dataset mehr als 5000 Datenpunkte umfasst. Der Grund ist, dass für die Daten im Dashboard ein Downsampling nach dem Zufallsprinzip durchgeführt wird. Im Dashboard werden aber für jeden Datenpunkt, der an das Dashboard übergeben wird, auf der Registerkarte „Individuelle Featurerelevanz“ die Rohfeaturewerte für das Dataset angezeigt. Die Benutzer können die lokalen Relevanzwerte wieder dem ursprünglichen Dataset zuordnen, indem sie einen Abgleich mit den Rohfeaturewerten für das Dataset durchführen. Wenn das Validierungsdataset weniger als 5000 Stichproben umfasst, entspricht das
index-Feature in Azure Machine Learning Studio dem Index im Validierungsdataset.Keine Unterstützung von Was-wäre-wenn-/ICE-Plots in Studio: Was-wäre-wenn- und ICE-Plots (Individual Conditional Expectation) werden in Azure Machine Learning Studio auf der Registerkarte „Erklärungen“ nicht unterstützt, da für die hochgeladene Erklärung eine Computeressource benötigt wird, um die Vorhersagen und Wahrscheinlichkeiten von gestörten Features neu berechnen zu können. Dies wird derzeit in Jupyter Notebooks unterstützt, wenn für die Ausführung ein Widget mit dem SDK verwendet wird.
Nächste Schritte
Techniken für die Modellinterpretierbarkeit in Azure Machine Learning