Erstellen und Verwalten von Datenressourcen
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel wird gezeigt, wie Sie Datenressourcen in Azure Machine Learning erstellen und verwalten.
Datenressourcen können ihnen helfen, wenn Sie Folgendes benötigen:
- Versionsverwaltung: Datenressourcen unterstützen die Versionsverwaltung von Daten.
- Reproduzierbarkeit: Nachdem Sie eine Datenobjektversion erstellt haben, ist sie unveränderlich. Sie kann nicht geändert oder gelöscht werden. Daher lassen sich Trainingsaufträge oder Pipelines, die die Datenressource nutzen, reproduzieren.
- Überprüfbarkeit: Da die Datenressourcenversion unveränderlich ist, können Sie die Versionen der Ressource, wer eine Version aktualisiert hat und wann die Aktualisierung stattgefunden hat, nachverfolgen.
- Datenherkunft: Sie können für jede beliebige Datenressource anzeigen, welche Aufträge oder Pipelines die Daten verwenden.
- Benutzerfreundlichkeit: Azure Machine Learning-Datenobjekte ähneln Lesezeichen (Favoriten) in Webbrowsern. Anstatt sich lange Speicherpfade (URIs) zu merken, die auf Ihre häufig verwendeten Daten in Azure Storage verweisen, können Sie eine Datenressourcenversion erstellen und dann mit einem Anzeigenamen (z. B.
azureml:<my_data_asset_name>:<version>) auf diese Version der Ressource zugreifen.
Tipp
Um in einer interaktiven Sitzung (z. B. einem Notebook) oder einem Auftrag auf Ihre Daten zugreifen möchten, müssen Sie nicht zuerst eine Datenressource erstellen. Sie können Datenspeicher-URIs verwenden, um auf die Daten zuzugreifen. Datenspeicher-URIs bieten eine einfache Möglichkeit, auf Daten zuzugreifen und mit Azure Machine Learning zu beginnen.
Voraussetzungen
Sie benötigen Folgendes, um Datenressourcen zu erstellen und zu nutzen:
Ein Azure-Abonnement. Wenn Sie keines haben, erstellen Sie ein kostenloses Konto, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Ein Azure Machine Learning-Arbeitsbereich. Erstellen von Arbeitsbereichsressourcen
Die CLI/das SDK von Azure Machine Learning muss installiert sein.
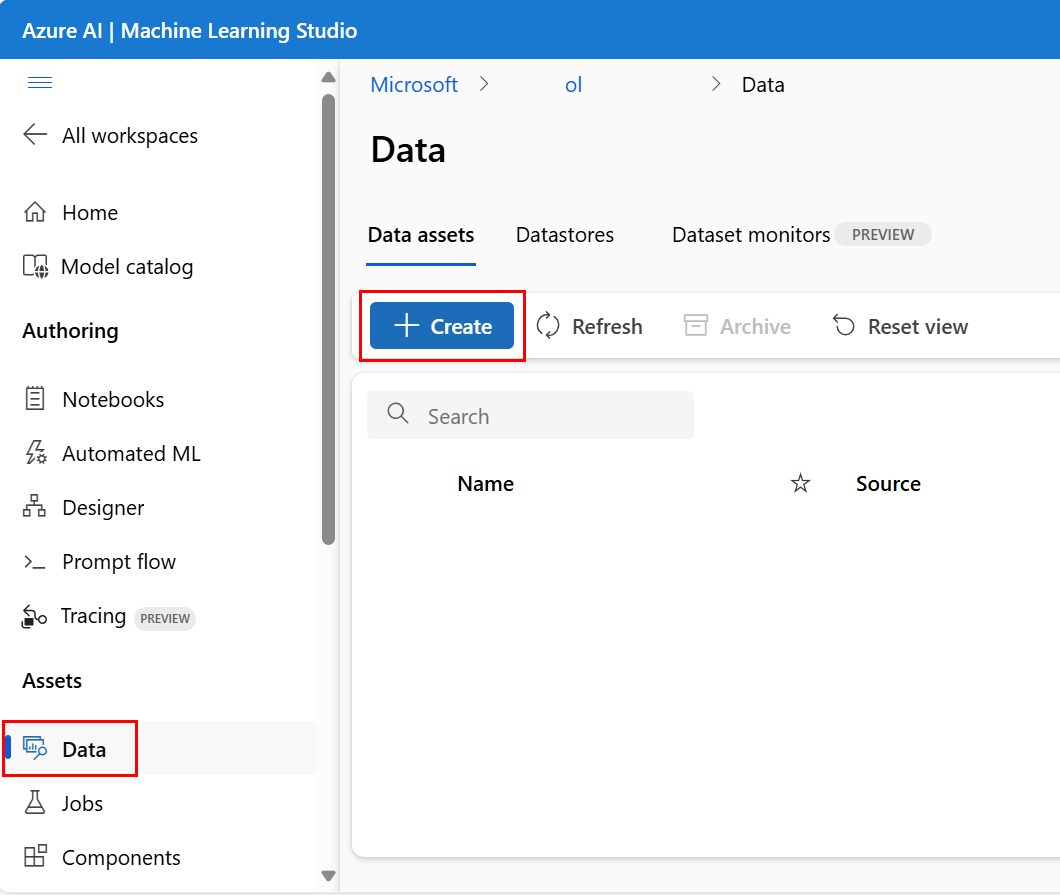
Erstellen von Datenressourcen
Wenn Sie Ihr Datenobjekt erstellen, müssen Sie den Datentyp festlegen. Azure Machine Learning unterstützt drei Datenressourcentypen:
| Type | API | Kanonische Szenarien |
|---|---|---|
| File Verweis auf eine einzelne Datei |
uri_file |
Lesen einer einzelnen Datei in Azure Storage (die Datei kann ein beliebiges Format haben). |
| Ordner Verweis auf einen Ordner |
uri_folder |
Einlesen eines Ordners mit Parquet-/CSV-Dateien in Pandas/Spark. Lesen unstrukturierter Daten (Bilder, Texte, Audio usw.), die sich in einem Ordner befinden. |
| Tabelle Verweis auf eine Datentabelle |
mltable |
Sie verfügen über ein komplexes Schema, das häufig geändert wird, oder Sie benötigen eine Teilmenge umfangreicher Tabellendaten. AutoML mit Tabellen Lesen unstrukturierter Daten (Bilder, Texte, Audio usw.), die auf mehrere Speicherorte verteilt sind. |
Hinweis
Verwenden Sie eingebettete neue Zeilen (Newlines) nur in CSV-Dateien, wenn Sie die Daten als MLTable registrieren. Eingebettete neue Zeilen (newlines) in CSV-Dateien können falsch ausgerichtete Feldwerte verursachen, wenn Sie die Daten lesen. MLTable verfügt über den support_multi_line-Parameter, der in der read_delimited-Transformation verfügbar ist, um zitierte Zeilenumbrüche als einen Datensatz zu interpretieren.
Wenn Sie die Datenressource in einem Azure Machine Learning-Auftrag nutzen, können Sie die Ressource entweder einbinden oder auf den/die Computeknoten herunterladen. Weitere Informationen finden Sie unter Modi.
Zudem müssen Sie einen path-Parameter angeben, der auf den Speicherort der Datenressource verweist. Unterstützte Pfade:
| Standort | Beispiele |
|---|---|
| Ein Pfad auf Ihrem lokalen Computer | ./home/username/data/my_data |
| Ein Pfad für einen Datenspeicher | azureml://datastores/<data_store_name>/paths/<path> |
| Ein Pfad auf einem öffentlichen HTTP(S)-Server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ein Pfad in Azure Storage | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS Gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS Gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Hinweis
Wenn Sie eine Datenressource aus einem lokalen Pfad erstellen, wird sie automatisch in den Standard-Clouddatenspeicher von Azure Machine Learning hochgeladen.
Erstellen einer Datenressource: Dateityp
Eine Datenressource vom Dateityp (uri_file) verweist auf eine einzelne Datei im Speicher (z. B. eine CSV-Datei). Sie können eine Datenressource vom Dateityp erstellen mit:
Erstellen Sie eine YAML-Datei, kopieren Sie den folgenden Codeschnipsel, und fügen Sie ihn ein. Achten Sie darauf, die <>-Platzhalter zu aktualisieren mit
- dem Namen Ihrer Datenressource
- der Version
- Beschreibung
- dem Pfad zu einer einzelnen Datei an einem unterstützten Speicherort
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Führen Sie als Nächstes folgenden Befehl in der CLI aus. Achten Sie darauf, den <filename>-Platzhalter auf den YAML-Dateinamen zu aktualisieren.
az ml data create -f <filename>.yml

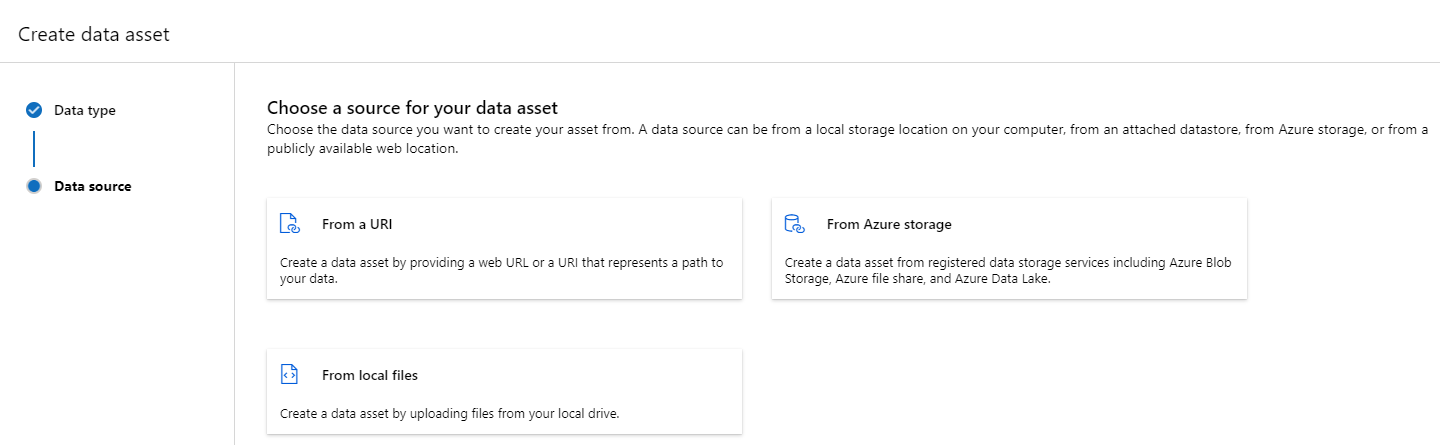
Erstellen einer Datenressource: Ordnertyp
Eine Datenressource vom Ordnertyp (uri_folder) ist eine Ressource, die auf einen Ordner in einer Speicherressource verweist (z. B. auf einen Ordner, der mehrere Unterordner mit Bildern enthält). Sie können eine Datenressource vom Ordnertyp erstellen, indem Sie:
den folgenden Code kopieren und ihn in eine neue YAML-Datei einfügen. Achten Sie darauf, die <>-Platzhalter zu aktualisieren mit
- dem Namen Ihrer Datenressource
- der Version
- Beschreibung
- dem Pfad zu einem Ordner an einem unterstützten Speicherort
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Führen Sie als Nächstes folgenden Befehl in der CLI aus. Achten Sie darauf, den <filename>-Platzhalter auf den YAML-Dateinamen zu aktualisieren.
az ml data create -f <filename>.yml

Erstellen einer Datenressource: Tabellentyp
Azure Machine Learning-Tabellen (MLTable) verfügen über eine umfangreiche Funktionalität, die unter Arbeiten mit Tabellen in Azure Machine Learning ausführlicher beschrieben wird. Anstatt diese Dokumentation hier zu wiederholen, lesen Sie dieses Beispiel, in dem beschrieben wird, wie sie eine Tabellentyp-Datenressource erstellen, wobei sich Titanic-Daten auf einem öffentlich verfügbaren Azure Blob Storage-Konto befinden.
Erstellen Sie zunächst ein neues Verzeichnis namens „data“ und anschließend eine Datei namens MLTable:
mkdir data
touch MLTable
Kopieren Sie als Nächstes den folgenden YAML-Code, und fügen Sie ihn in die Datei MLTable ein, die Sie im vorherigen Schritt erstellt haben:
Achtung
Sie dürfen die Datei MLTablenicht in MLTable.yaml oder MLTable.yml umbenennen. Azure Machine Learning erwartet eine MLTable-Datei.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Führen Sie folgenden Befehl in der CLI aus. Stellen Sie sicher, dass Sie die <>-Platzhalter mit dem Namen und den Versionswerten des Datenobjekts aktualisieren.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Wichtig
path muss ein Ordner mit einer gültigen MLTable-Datei sein.
Erstellen von Datenressourcen aus Auftragsausgaben
Sie können eine Datenressource aus einem Azure Machine Learning-Auftrag erstellen. Legen Sie dazu den name-Parameter in der Ausgabe fest. In diesem Beispiel übermitteln Sie einen Auftrag, der Daten aus einem öffentlichen Blobspeicher in Ihren Azure Machine Learning-Standarddatenspeicher kopiert und ein Datenobjekt namens job_output_titanic_asseterstellt.
Erstellen Sie eine YAML-Datei mit Auftragsspezifikationen (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Übermitteln Sie als Nächstes den Auftrag über die CLI:
az ml job create --file <file-name>.yml
Verwalten von Datenassets
Löschen einer Datenressource
Wichtig
Standardmäßig wird das Löschen von Datenressourcen nicht unterstützt.
Wenn Azure Machine Learning das Löschen von Datenressourcen zuließe, hätte dies die folgenden nachteiligen und negativen Auswirkungen:
- Produktionsaufträge, die später gelöschte Datenressourcen nutzen, schlagen fehl.
- Es würde dadurch schwieriger, ein ML-Experiment zu reproduzieren.
- Die Datenherkunft des Auftrags wäre nicht mehr nachvollziehbar, da es unmöglich wäre, die Version der gelöschten Datenressource anzuzeigen.
- Sie könnten die Ressourcen nicht ordnungsgemäß nachverfolgen und überwachen, da Versionen fehlen könnten.
Daher bietet die Unveränderlichkeit von Datenressourcen einen gewissen Schutz bei der Arbeit in einem Team, das Produktionsworkloads erstellt.
Wenn eine Datenressource falsch erstellt wurde ( z. B. ein falscher Name, ein falscher Typ oder Pfad), bietet Azure Machine Learning Lösungen, mit dieser Situation ohne die negativen Folgen des Löschens umzugehen:
| Ich möchte diese Datenressource aus folgendem Grund löschen... | Lösung |
|---|---|
| Der Name ist falsch. | Archivieren der Datenressource |
| Das Team verwendet das Datenobjekt nicht mehr. | Archivieren der Datenressource |
| Die Auflistung des Datenobjekts wird durcheinander gebracht. | Archivieren der Datenressource |
| Der Pfad ist falsch. | Erstellen Sie eine neue Version der Datenressource (mit demselben Namen) mit dem richtigen Pfad. Weitere Informationen finden Sie unter Erstellen von Datenressourcen. |
| Der Typ ist falsch. | Derzeit lässt Azure Machine Learning die Erstellung einer neuen Version, die einen anderen Typ als die ursprüngliche Version hat, nicht zu. (1) Archivieren Sie die Datenressource. (2) Erstellen Sie eine neue Datenressource mit einem anderen Namen und dem richtigen Typ. |
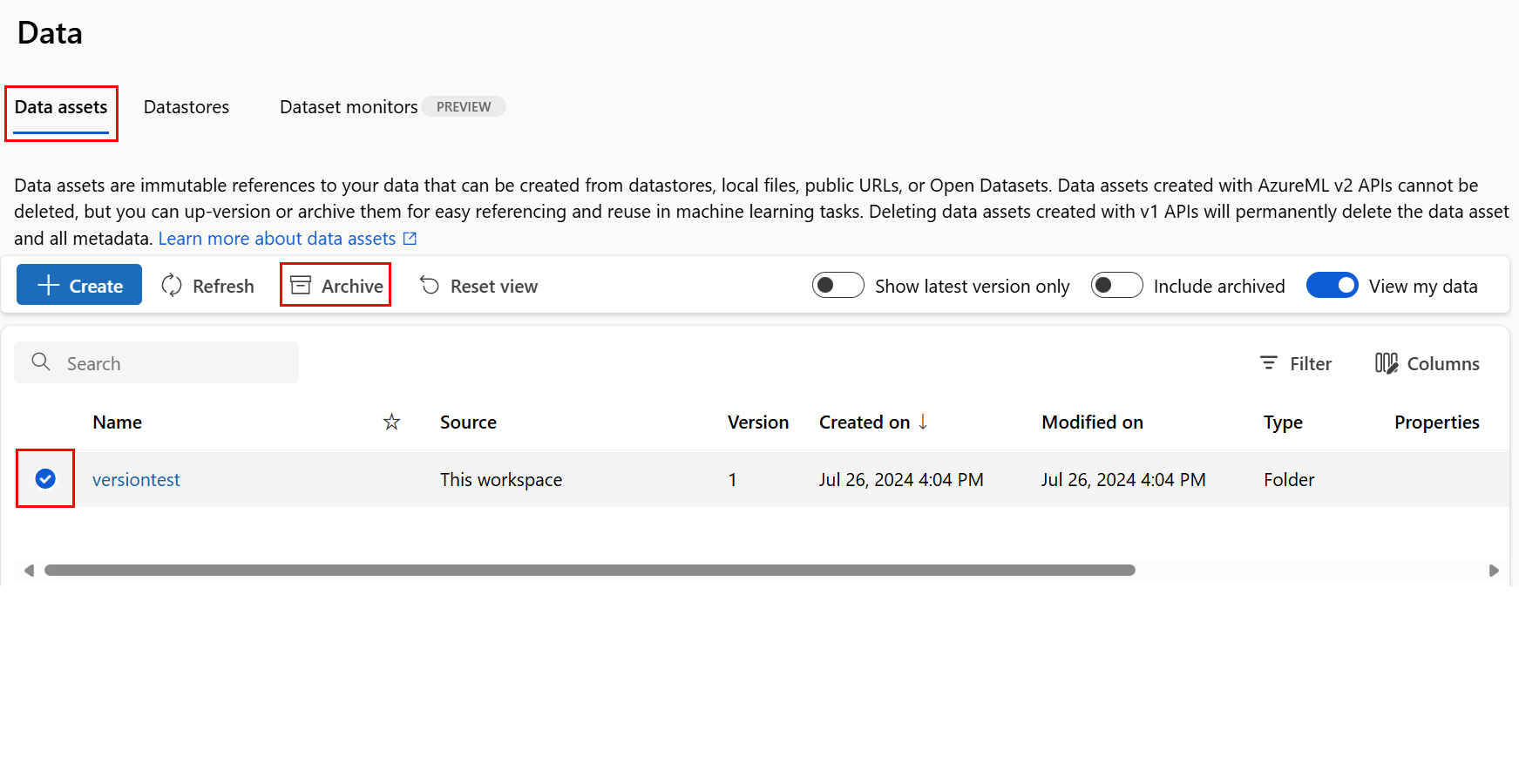
Archivieren einer Datenressource
Durch die Archivierung einer Datenressource wird diese standardmäßig bei Listenabfragen (z. B. in der CLI az ml data list) und der Datenressourcenauflistung in der Studio-Benutzeroberfläche ausgeblendet. Sie können in Ihren Workflows weiterhin auf archivierte Datenressourcen verweisen und diese verwenden. Sie können Folgendes archivieren:
- Alle Versionen der Datenressource unter einem bestimmten Namen
oder
- Eine bestimmte Datenressourcenversion
Archivieren aller Versionen einer Datenressource
Verwenden Sie folgendes Verfahren, um alle Versionen der Datenressource unter einem bestimmten Namen zu archivieren:
Führen Sie den folgenden Befehl aus. Achten Sie darauf, die <>-Platzhalter mit Ihren Informationen zu aktualisieren.
az ml data archive --name <NAME OF DATA ASSET>
Archivieren einer bestimmten Datenressourcenversion
Verwenden Sie folgendes Verfahren, um eine bestimmte Datenressourcenversion zu archivieren:
Führen Sie den folgenden Befehl aus. Achten Sie darauf, die <>-Platzhalter mit dem Namen Ihrer Datenressource und -version zu aktualisieren.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
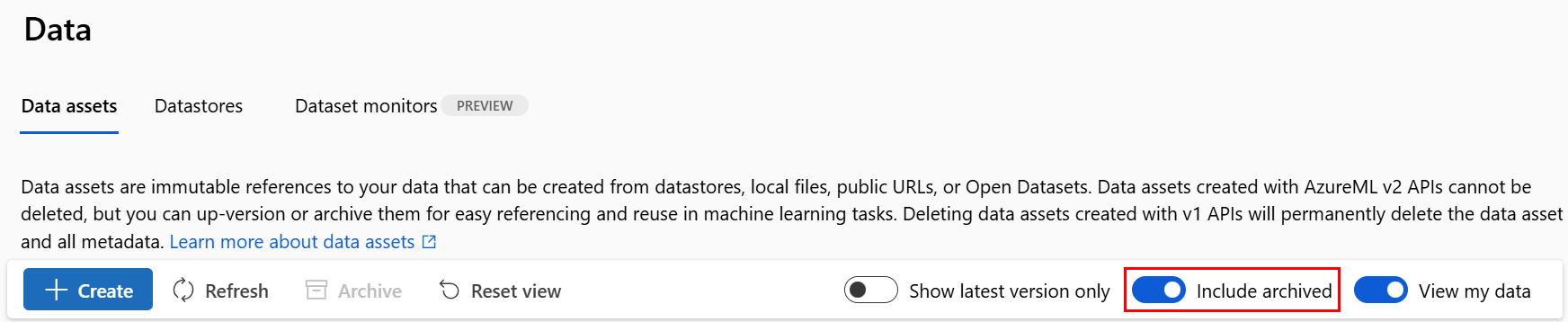
Wiederherstellen einer archivierten Datenressource
Sie können eine archivierte Datenressource wiederherstellen. Wenn alle Versionen der Datenressource archiviert werden, können nicht einzelne Versionen der Datenressource wiederhergestellt werden. Sie müssen alle Versionen wiederherstellen.
Wiederherstellen aller Versionen einer Datenressource
Verwenden Sie folgendes Verfahren, um alle Versionen der Datenressource unter einem bestimmten Namen wiederherzustellen:
Führen Sie den folgenden Befehl aus. Achten Sie darauf, die <>-Platzhalter mit dem Namen Ihrer Datenressource zu aktualisieren.
az ml data restore --name <NAME OF DATA ASSET>
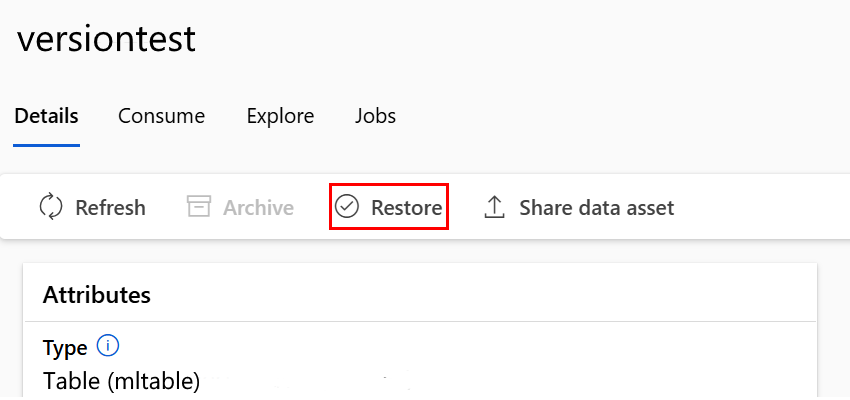
Wiederherstellen einer bestimmten Datenressourcenversion
Wichtig
Wenn alle Versionen der Datenressource archiviert werden, können nicht einzelne Versionen der Datenressource wiederhergestellt werden. Sie müssen alle Versionen wiederherstellen.
Zum Wiederherstellen einer bestimmten Datenressourcenversion verwenden Sie folgendes Verfahren:
Führen Sie den folgenden Befehl aus. Achten Sie darauf, die <>-Platzhalter mit dem Namen Ihrer Datenressource und -version zu aktualisieren.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Datenherkunft
Unter Datenherkunft wird im Allgemeinen der Lebenszyklus verstanden, der den Ursprung der Daten und ihre Bewegung im Speicher im Laufe der Zeit umfasst. Verschiedene Arten von abwärtsgerichteten Szenarien verwenden sie, zum Beispiel
- Problembehandlung
- Ursachen für die Ablaufverfolgung in ML-Pipelines
- Debuggen
Auch für Datenqualitätsanalyse, Compliance und „Was-wäre-wenn“-Szenarios wird die Herkunft verwendet. Die visuelle Darstellung der Herkunft soll die Bewegung der Daten von der Quelle zum Ziel zeigen und deckt darüber hinaus die Umwandlung der Daten ab. Aufgrund der Komplexität der meisten Unternehmensdatenumgebungen sind diese Sichten u. U. ohne Konsolidierung oder Maskierung peripherer Datenpunkte schwer zu verstehen.
In einer Azure Machine Learning-Pipeline wird für Datenressourcen angezeigt, woher die Daten stammen und wie die Daten verarbeitet wurden, z. B.:
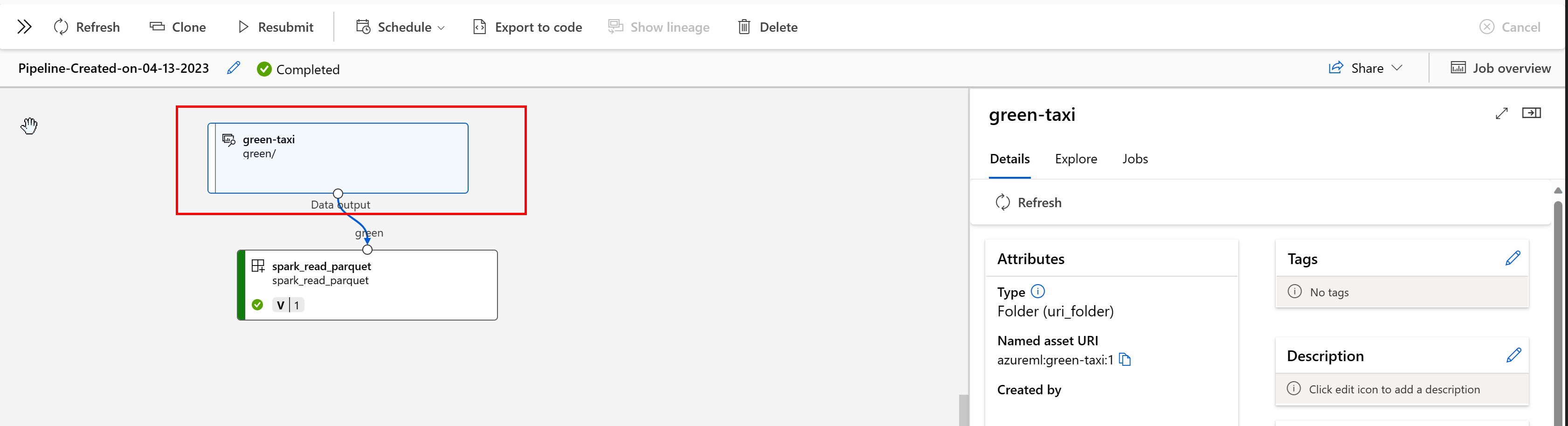
Sie können in der Studio-Benutzeroberfläche die Aufträge anzeigen, die die Datenressource nutzen. Wählen Sie zunächst im linken Menü Daten und anschließend den Namen der Datenressource aus. Beachten Sie die Aufträge, die die Datenressource verbrauchen:
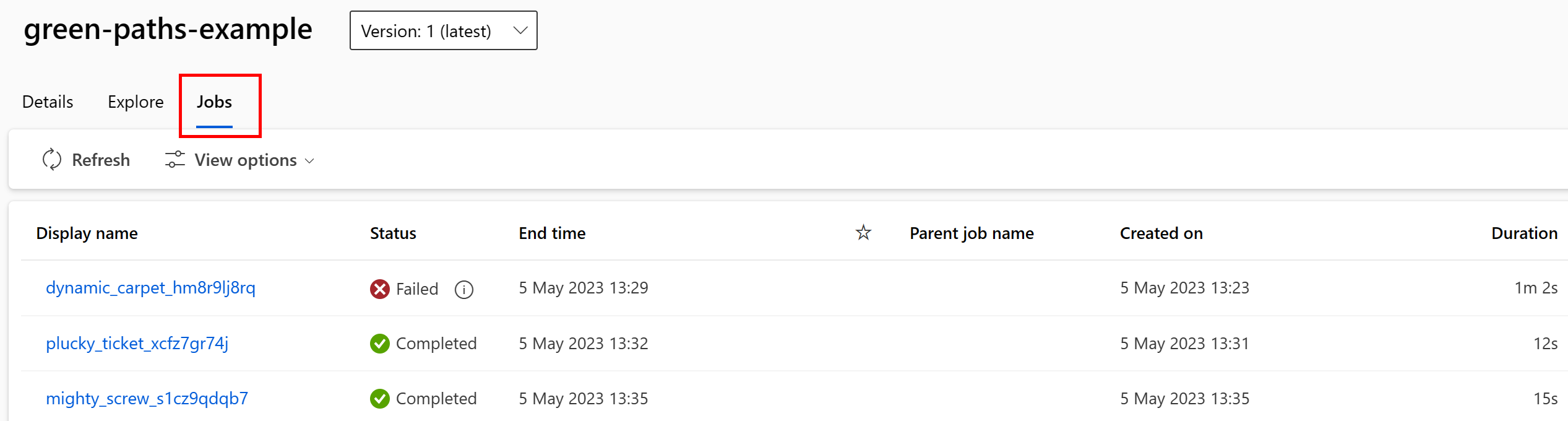
Die Auftragsansicht in Datenressourcen erleichtert das Auffinden von Auftragsfehlern und die Analyse von Fehlerursachen in ML-Pipelines und beim Debuggen.
Tagging von Datenressourcen
Datenressourcen unterstützen das Tagging. Dabei handelt es sich um zusätzliche Metadaten, die als Schlüssel-Wert-Paares auf die Datenressource angewendet werden. Das Tagging von Daten bietet viele Vorteile:
- Beschreibung der Datenqualität. Wenn Ihre Organisation beispielsweise eine Medallion Lakehouse-Architektur verwendet, können Sie Ressourcen mit
medallion:bronze(roh),medallion:silver(überprüft) undmedallion:gold(angereichert) markieren. - Effizientes Suchen und Filtern von Daten, um die Datenermittlung zu unterstützen.
- Identifizierung vertraulicher personenbezogener Daten, um den Datenzugriff ordnungsgemäß zu verwalten und zu steuern. Beispiel:
sensitivity:PII/sensitivity:nonPII. - Bestimmung, ob Daten von einer verantwortlichen AI(RAI)-Prüfung genehmigt wurden. Beispiel:
RAI_audit:approved/RAI_audit:todo.
Tags können im Rahmen der Erstellung zu Datenressourcen hinzugefügt werden. Sie können aber auch vorhandenen Datenressourcen Tags hinzufügen. In diesem Abschnitt wird beides gezeigt:
Hinzufügen von Tags im Rahmen der Datenressourcenerstellung
Erstellen Sie eine YAML-Datei, und kopieren Sie den folgenden Code in diese YAML-Datei. Achten Sie darauf, die <>-Platzhalter zu aktualisieren mit
- dem Namen Ihrer Datenressource
- der Version
- Beschreibung
- Tags (Schlüssel-Wert-Paare)
- dem Pfad zu einer einzelnen Datei an einem unterstützten Speicherort
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Führen Sie folgenden Befehl in der CLI aus. Achten Sie darauf, den <filename>-Platzhalter auf den YAML-Dateinamen zu aktualisieren.
az ml data create -f <filename>.yml
Hinzufügen von Tags zu einer vorhandenen Datenressource
Führen Sie in der Azure CLI folgenden Befehl aus. Achten Sie darauf, die <>-Platzhalter zu aktualisieren mit
- dem Namen Ihrer Datenressource
- der Version
- Schlüssel-Wert-Paar für das Tag
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Bewährte Methoden für die Versionsverwaltung
In der Regel organisieren Ihre ETL-Prozesse die Ordnerstruktur in Azure Storage nach der zeitlichen Abfolge, z. B.:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Die Kombination aus zeit-/versionsstrukturierten Ordnern und Azure Machine Learning-Tabellen (MLTable) ermöglicht es Ihnen, Datasets mit Versionsangaben zu erstellen. Anhand eines hypothetischen Beispiels wird gezeigt, wie mit Azure Machine Learning-Tabellen Daten mit Versionsangaben erzielt werden. Angenommen, Sie verfügen über einen Prozess, der jede Woche Kamerabilder in dieser Struktur in Azure Blob Storage hochlädt:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Hinweis
Wir zeigen zwar wie man Bilddaten (jpeg) versionieren, der gleiche Ansatz funktioniert aber für jeden Dateityp (z. B. Parkett, CSV).
Mit Azure Machine Learning-Tabellen (mltable) legen Sie eine Tabelle mit Pfaden an, die die Daten bis zum Ende der ersten Woche im Jahr 2023 enthalten. Erstellen Sie dann eine Datenressource:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Am Ende der folgenden Woche hat Ihr ETL-Prozess die Daten aktualisiert, um weitere Daten einzubinden:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Die erste Version (20230108) wird weiterhin nur Dateien von year=2022/week=52 und year=2023/week=1 einbinden/herunterladen, da die Pfade in der MLTable-Datei deklariert sind. Dies stellt die Reproduzierbarkeit für Ihre Experimente sicher. Um eine neue Version der Datenressource zu erstellen, die year=2023/week2 enthält, verwenden Sie folgendes Verfahren:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Sie verfügen nun über zwei Versionen der Daten, wobei der Name der Version dem Datum entspricht, an dem die Bilder in den Speicher hochgeladen wurden:
- 20230108: Die Bilder bis zum 08. Januar 2023.
- 20230115: Die Bilder bis zum 15. Januar 2023.
In beiden Fällen erstellt MLTable eine Tabelle mit Pfaden, die nur die Bilder bis zu den betreffenden Datumsangaben enthalten.
In einem Azure Machine Learning-Auftrag können Sie diese Pfade in der versionierten MLTable mit dem eval_download- oder dem eval_mount-Modus in Ihr Computeziel einbinden bzw. darauf herunterladen:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Hinweis
Die Modi eval_mount und eval_download sind MLTable eigen. In diesem Fall wertet die AzureML Data Runtime-Funktion die MLTable-Datei aus und stellt die Pfade auf dem Computeziel bereit.