Autorisierung für Batchendpunkte
Die Microsoft Entra-Authentifizierung wird von regionalen Endpunkten oder aad_token nicht unterstützt. Dies bedeutet, dass Benutzer*innen ein gültiges Microsoft Entra-Authentifizierungstoken an den Batchendpunkt-URI übermitteln müssen, um einen Batchendpunkt aufzurufen. Die Autorisierung wird auf Endpunktebene erzwungen. In diesem Artikel wird erläutert, wie Sie ordnungsgemäß mit Batchendpunkten interagieren und welche Sicherheitsanforderungen hierbei gelten.
Funktionsweise der Autorisierung
Um einen Batchendpunkt aufzurufen, müssen Benutzer*innen ein gültiges Microsoft Entra-Token vorlegen, das einen Sicherheitsprinzipal repräsentiert. Dieser Prinzipal kann ein Benutzerprinzipal oder ein Dienstprinzipal sein. In beiden Fällen wird nach dem Aufruf eines Endpunkts ein Batchbereitstellungsauftrag unter Verwendung der Identität erstellt, die mit dem Token verknüpft ist. Die Identität benötigt zum erfolgreichen Erstellen eines Auftrags die folgenden Berechtigungen:
- Lesen von Batchendpunkten/-bereitstellungen
- Erstellen von Aufträgen in Batchrückschlussendpunkten/-bereitstellungen
- Erstellen von Experimenten/Ausführungen
- Lesen und Schreiben aus/in Datenspeichern
- Auflisten von Datenspeichergeheimnissen
Eine detaillierte Liste der RBAC-Berechtigungen finden Sie unter Autorisierung für Batchendpunkte.
Wichtig
Die für den Aufruf eines Batchendpunkts verwendete Identität wird je nach Konfiguration des Datenspeichers möglicherweise nicht zum Lesen der zugrunde liegenden Daten verwendet. Ausführlichere Informationen finden Sie unter Konfigurieren von Computeclustern für den Datenzugriff.
Ausführen von Aufträgen mit verschiedenen Arten von Anmeldeinformationen
Die folgenden Beispiele zeigen verschiedene Möglichkeiten zum Starten von Batchbereitstellungsaufträgen mit verschiedenen Arten von Anmeldeinformationen:
Wichtig
Beim Arbeiten an Arbeitsbereichen mit aktiviertem privaten Link können Batchendpunkte nicht über die Benutzeroberfläche in Azure Machine Learning Studio aufgerufen werden. Verwenden Sie stattdessen die Azure Machine Learning CLI v2 für die Auftragserstellung.
Voraussetzungen
- In diesem Beispiel wird davon ausgegangen, dass ein Modell ordnungsgemäß als Batchendpunkt bereitgestellt wurde. Insbesondere verwenden Sie den Klassifizierer „heart condition“ (Herzleiden), der im Lernprogramm Verwenden von MLflow-Modellen in Batchbereitstellungen erstellt wurde.
Ausführen von Aufträgen mithilfe der Anmeldeinformationen des Benutzers
In diesem Fall sollte ein Batch-Endpunkt mit der Identität des derzeit angemeldeten Benutzers ausgeführt werden. Führen Sie folgende Schritte aus:
Verwenden Sie die Azure CLI, um sich entweder interaktiv oder mithilfe eines Gerätecodes zu authentifizieren:
az loginVerwenden Sie nach der Authentifizierung den folgenden Befehl, um einen Batchbereitstellungsauftrag auszuführen:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Ausführen von Aufträgen mithilfe eines Dienstprinzipals
In diesem Fall sollte ein Batchendpunkt mit einem bereits in Microsoft Entra ID erstellten Dienstprinzipal ausgeführt werden. Um die Authentifizierung abzuschließen, müssen Sie ein Geheimnis erstellen, um die Authentifizierung durchzuführen. Führen Sie die folgenden Schritte aus:
Erstellen Sie für die Authentifizierung ein Geheimnis, wie unter Option 3: Erstellen eines neuen geheimen Clientschlüssels beschrieben.
Verwenden Sie den folgenden Befehl, um sich mit einem Dienstprinzipal zu authentifizieren. Weitere Informationen finden Sie unter Anmelden mit der Azure CLI.
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>Verwenden Sie nach der Authentifizierung den folgenden Befehl, um einen Batchbereitstellungsauftrag auszuführen:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
Ausführen von Aufträgen mithilfe einer verwalteten Identität
Sie können verwaltete Identitäten verwenden, um Batch-Endpunkte und -Bereitstellungen aufzurufen. Beachten Sie, dass diese verwaltete Identität nicht zum Batchendpunkt gehört, sondern die Identität ist, die zum Ausführen des Endpunkts und damit zum Erstellen eines Batchauftrags verwendet wird. In diesem Szenario können sowohl vom Benutzer als auch vom System zugewiesene Identitäten verwendet werden.
Auf Ressourcen, die für verwaltete Identitäten von Azure-Ressourcen konfiguriert sind, können Sie sich mit der verwalteten Identität anmelden. Das Anmelden mit der Identität der Ressource erfolgt über das Flag --identity. Weitere Informationen finden Sie unter Anmelden mit der Azure CLI.
az login --identity
Verwenden Sie nach der Authentifizierung den folgenden Befehl, um einen Batchbereitstellungsauftrag auszuführen:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Konfigurieren von RBAC für den Aufruf von Batchendpunkten
Batchendpunkte machen einen dauerhaften API-Consumer verfügbar, der zum Generieren von Aufträgen verwendet werden kann. Der Aufrufer fordert die richtige Berechtigung an, um diese Aufträge erzeugen zu können. Sie können entweder eine der integrierten Sicherheitsrollen verwenden oder eine benutzerdefinierte Rolle für diesen Zweck erstellen.
Um einen Batchendpunkt erfolgreich aufzurufen, müssen der Identität, mit der die Endpunkte aufgerufen werden, die Berechtigungen für die folgenden expliziten Aktionen zugewiesen werden. Anweisungen zur Rollenzuweisung finden Sie unter Schritte zum Zuweisen einer Azure-Rolle.
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
Konfigurieren von Computeclustern für den Datenzugriff
Batchendpunkte stellen sicher, dass nur autorisierte Benutzer Batchbereitstellungen aufrufen und Aufträge generieren können. Je nach Konfiguration der Eingabedaten können jedoch auch andere Anmeldeinformationen verwendet werden, um die zugrunde liegenden Daten zu lesen. Verwenden Sie die folgende Tabelle, um zu verstehen, welche Anmeldeinformationen verwendet werden:
| Dateneingabetyp | Anmeldeinformationen im Speicher | Verwendete Anmeldeinformationen | Zugriff gewährt durch |
|---|---|---|---|
| Datenspeicher | Ja | Anmeldeinformationen des Datenspeichers im Arbeitsbereich | Zugriffsschlüssel oder SAS |
| Datenasset | Ja | Anmeldeinformationen des Datenspeichers im Arbeitsbereich | Zugriffsschlüssel oder SAS |
| Datenspeicher | Nein | Identität des Auftrags + verwaltete Identität des Computeclusters | RBAC |
| Datenasset | Nein | Identität des Auftrags + verwaltete Identität des Computeclusters | RBAC |
| Azure Blob Storage | Nicht anwendbar | Identität des Auftrags + verwaltete Identität des Computeclusters | RBAC |
| Azure Data Lake Storage Gen1 | Nicht anwendbar | Identität des Auftrags + verwaltete Identität des Computeclusters | POSIX |
| Azure Data Lake Storage Gen2 | Nicht anwendbar | Identität des Auftrags + verwaltete Identität des Computeclusters | POSIX und RBAC |
Für die Elemente in der Tabelle, für die Identität des Auftrags + verwaltete Identität des Computeclusters angezeigt wird, wird die verwaltete Identität des Computeclusters zum Einbinden und Konfigurieren von Speicherkonten verwendet. Die Identität des Auftrags wird jedoch weiterhin verwendet, um die zugrunde liegenden Daten zu lesen, sodass Sie eine präzise Zugriffssteuerung erzielen können. Dies bedeutet, dass die verwaltete Identität des Computeclusters, auf dem die Bereitstellung durchgeführt wird, mindestens Zugriff als Storage-Blobdatenleser für das Speicherkonto benötigt, um erfolgreich Daten aus dem Speicher zu lesen.
Führen Sie die folgenden Schritte aus, um den Computecluster für den Datenzugriff zu konfigurieren:
Navigieren Sie zu Azure Machine Learning Studio.
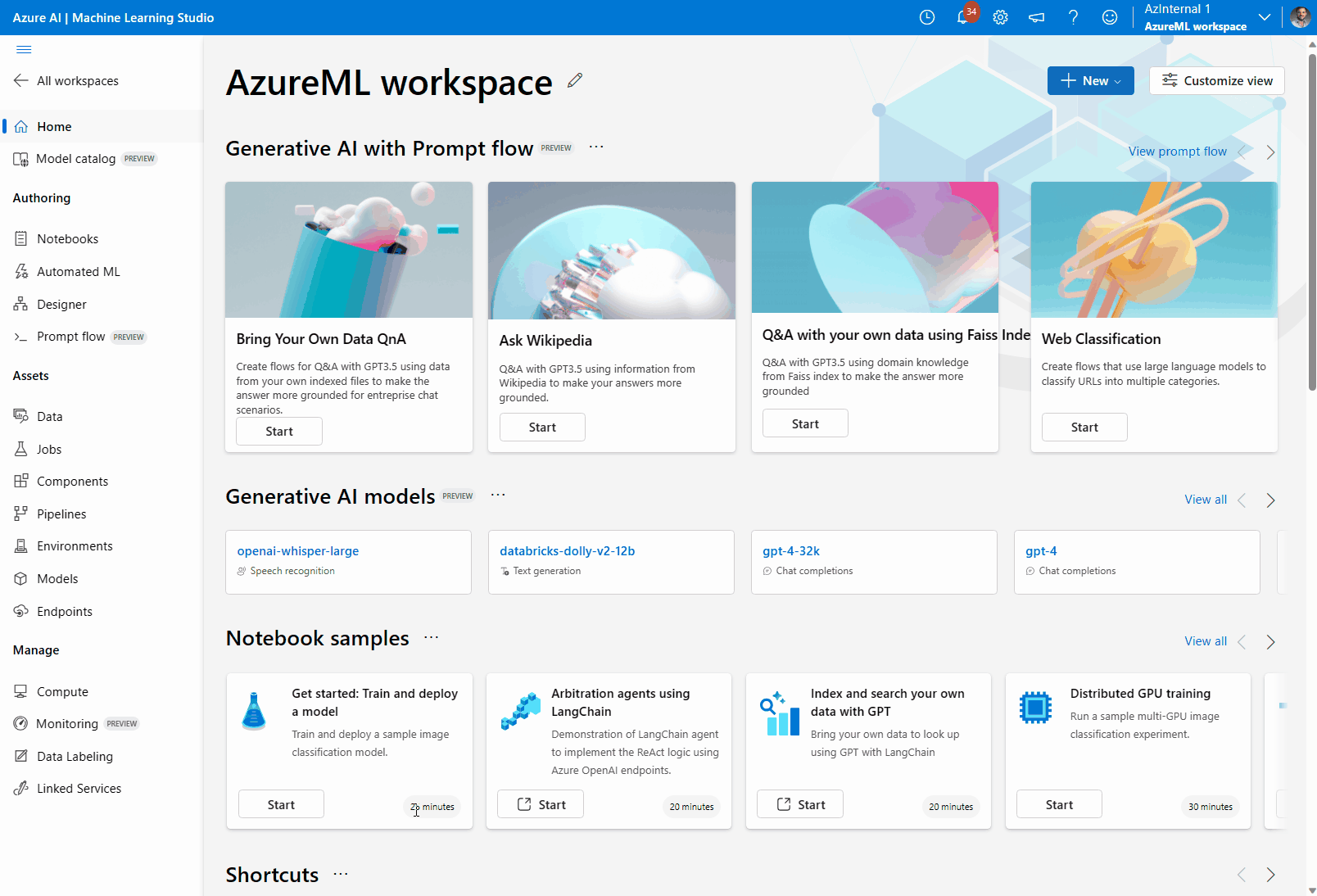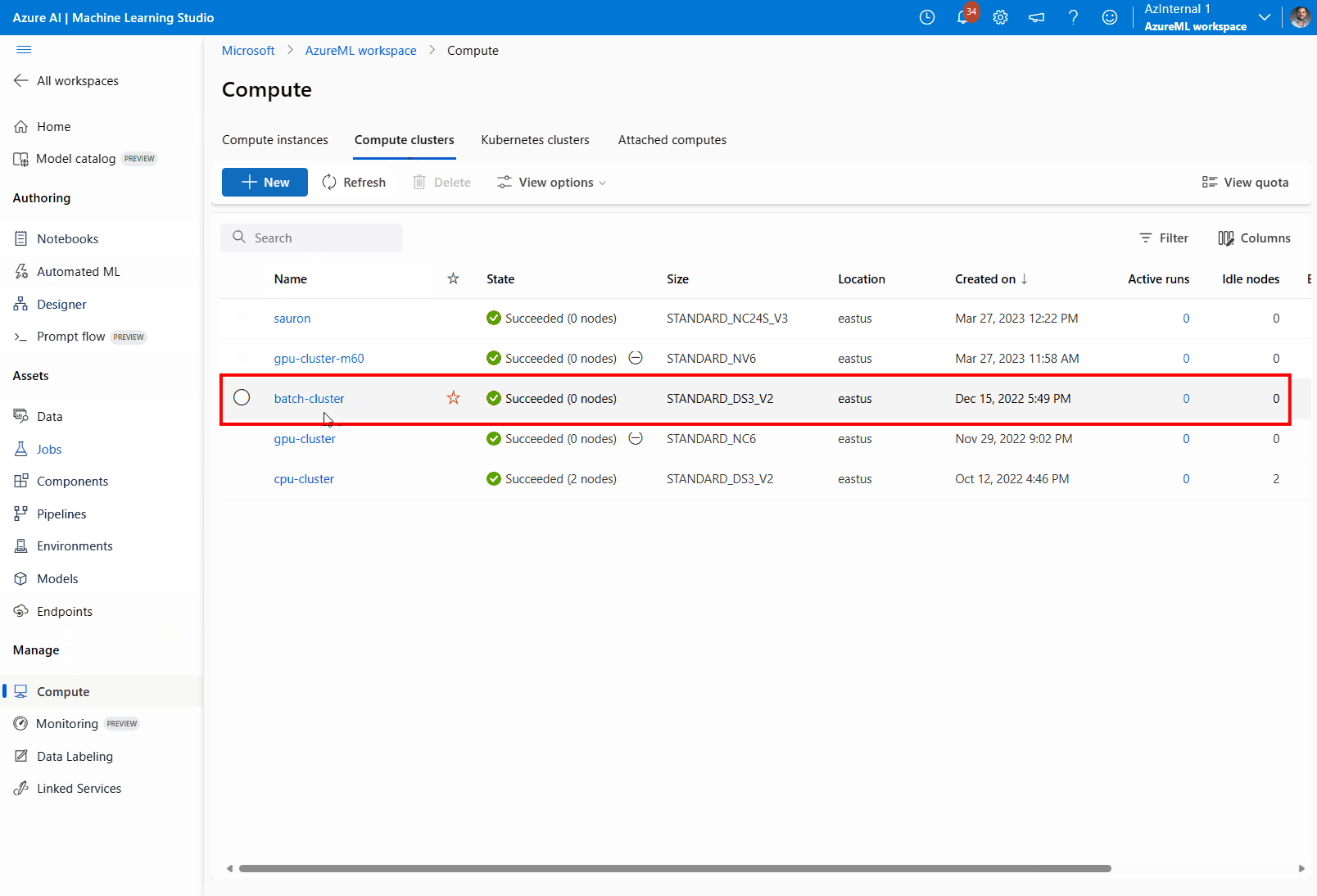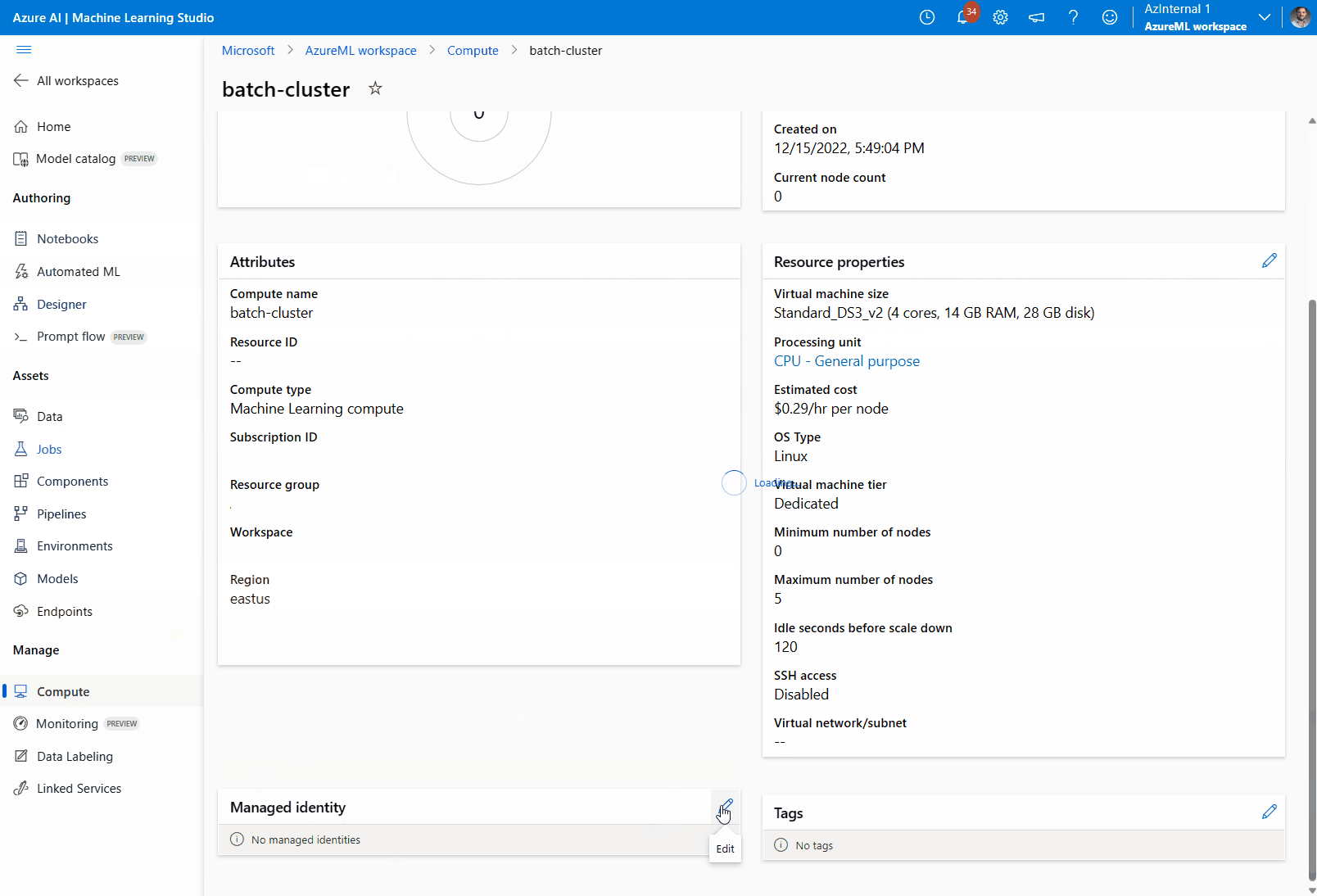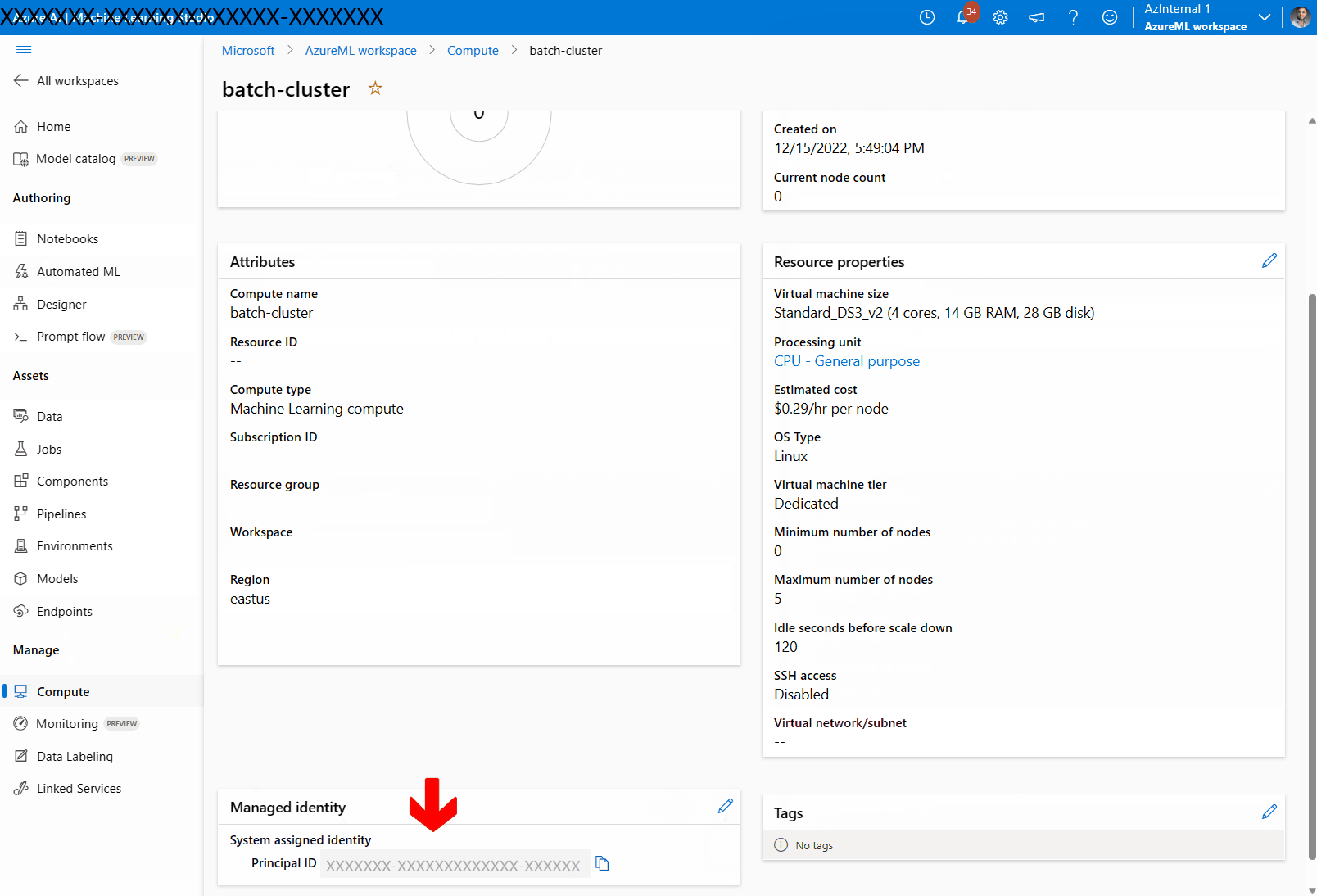
Navigieren Sie zu Compute und dann zu Computecluster, und wählen Sie den Computecluster aus, den Ihre Bereitstellung verwendet.
Weisen Sie dem Computecluster eine verwaltete Identität zu:
Überprüfen Sie im Abschnitt Verwaltete Identität, ob der Computeressource eine verwaltete Identität zugewiesen wurde. Wenn nicht, wählen Sie die Option Bearbeiten aus.
Wählen Sie Verwaltete Identität zuweisen aus, und konfigurieren Sie sie nach Bedarf. Sie können eine systemseitig zugewiesene verwaltete Identität oder eine benutzerseitig zugewiesene verwaltete Identität verwenden. Wenn Sie eine systemseitig zugewiesene verwaltete Identität verwenden, erhält sie den Namen „[Arbeitsbereichsname]/computes/[Computeclustername]“.
Speichern Sie die Änderungen.
Navigieren Sie zum Azure-Portal und dann zum zugeordneten Speicherkonto, in dem sich die Daten befinden. Wenn es sich bei der Dateneingabe um eine Datenressource oder einen Datenspeicher handelt, suchen Sie nach dem Speicherkonto, in dem diese Ressourcen platziert werden.
Weisen Sie die Zugriffsebene „Storage-Blobdatenleser“ im Speicherkonto zu:
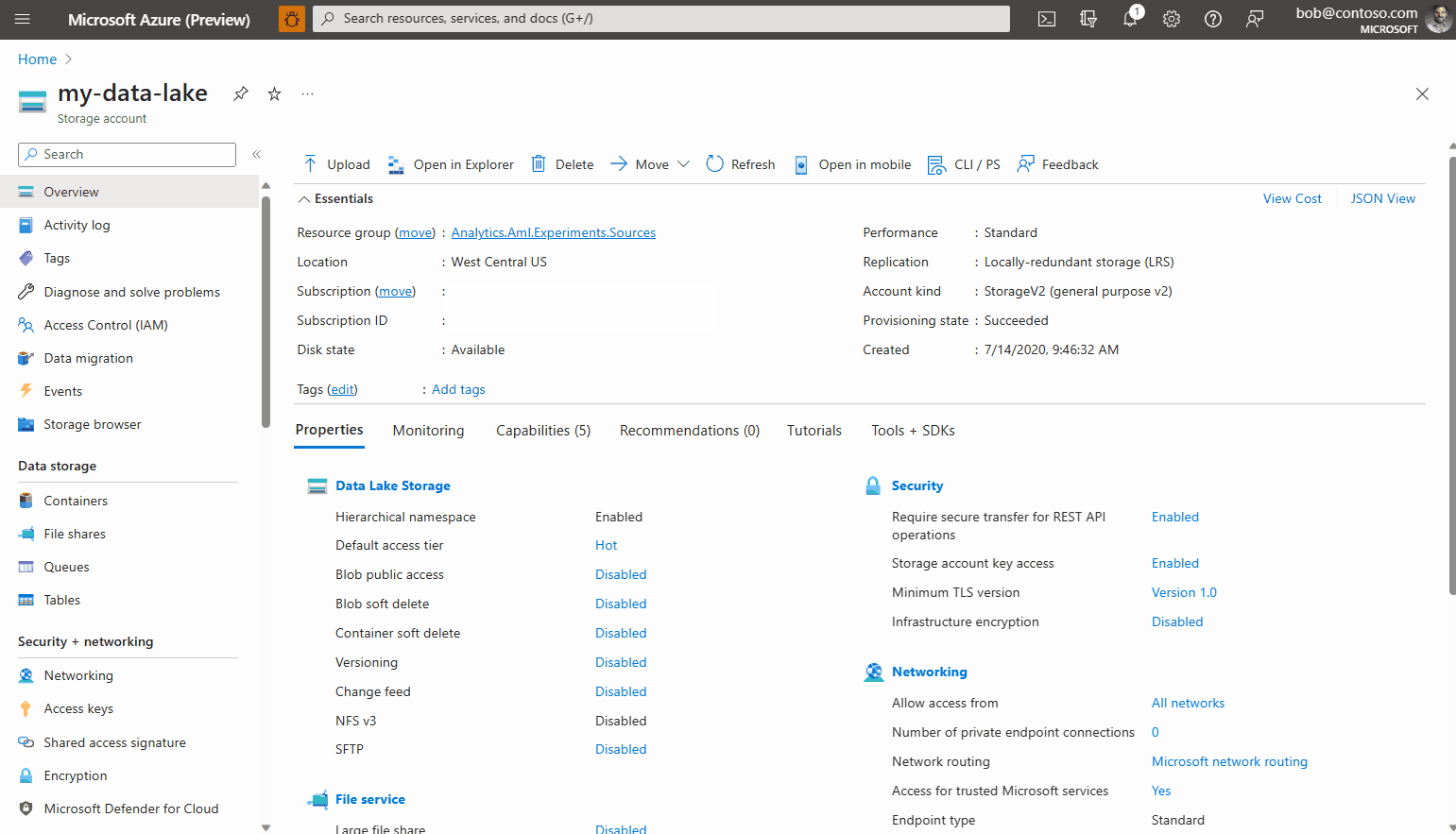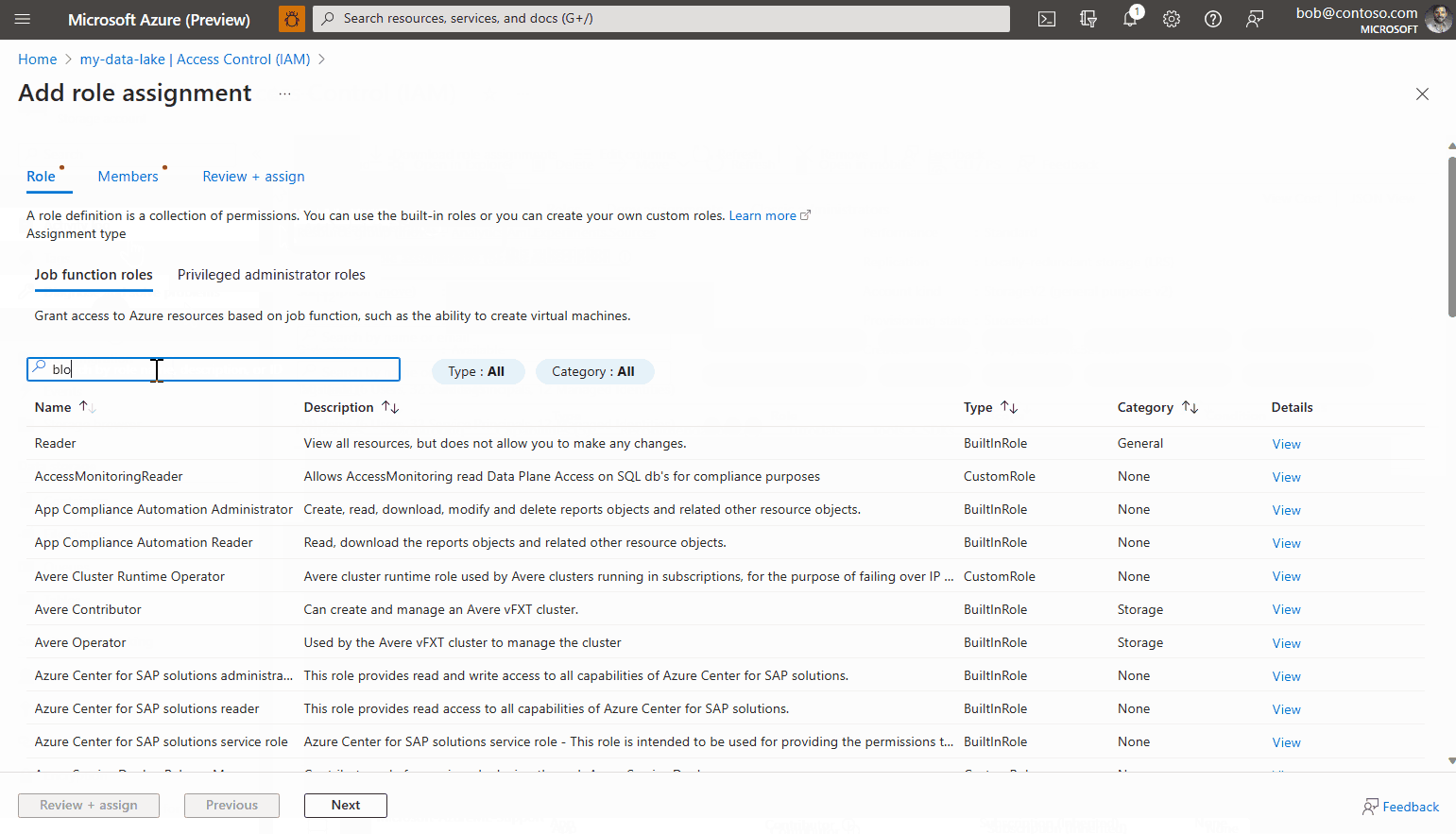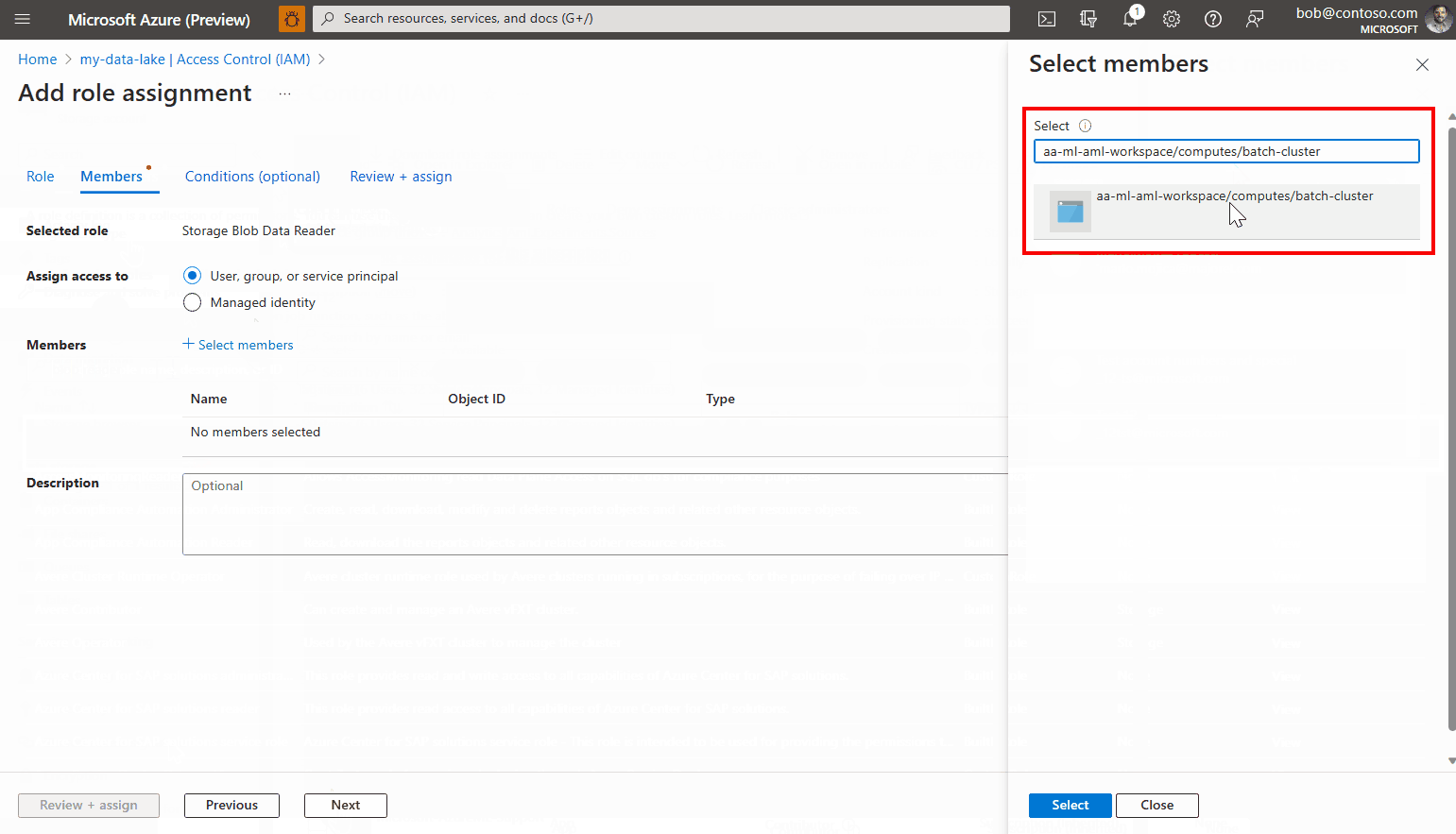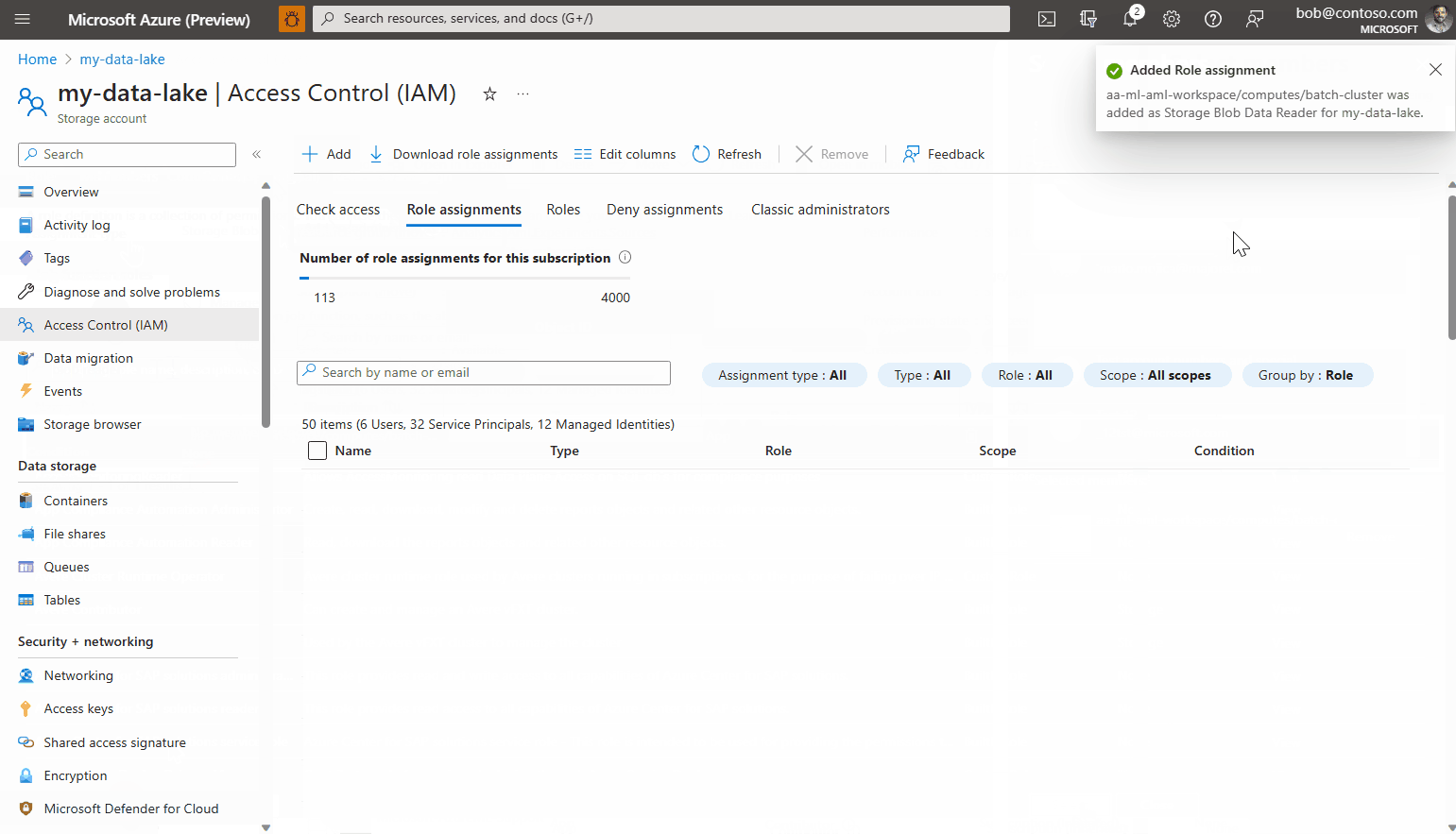
Wechseln Sie zum Abschnitt Zugriffssteuerung (IAM).
Wählen Sie die Registerkarte Rollenzuweisung aus, und klicken Sie dann auf Hinzufügen>Rollenzuweisung.
Suchen Sie nach der Rolle namens Storage-Blobdatenleser, wählen Sie sie aus, und klicken Sie auf Weiter.
Klicken Sie auf Mitglieder auswählen.
Suchen Sie die erstellte verwaltete Identität. Wenn Sie eine systemseitig zugewiesene verwaltete Identität verwenden, erhält sie den Namen [Arbeitsbereichsname]/computes/[Computeclustername].
Fügen Sie das Konto hinzu, und schließen Sie den Assistenten ab.
Ihr Endpunkt ist bereit, Aufträge und Eingabedaten aus dem ausgewählten Speicherkonto zu erhalten.