Bewerten von KI-Systemen mithilfe des Dashboards „Verantwortungsvolle KI“
In der Praxis erfordert die Implementierung von verantwortungsvoller KI (künstliche Intelligenz) eine rigorose Entwicklung. Eine rigorose Entwicklung kann jedoch mühsam, manuell und zeitaufwändig sein, wenn nicht die richtigen Tools und die richtige Infrastruktur zur Verfügung stehen.
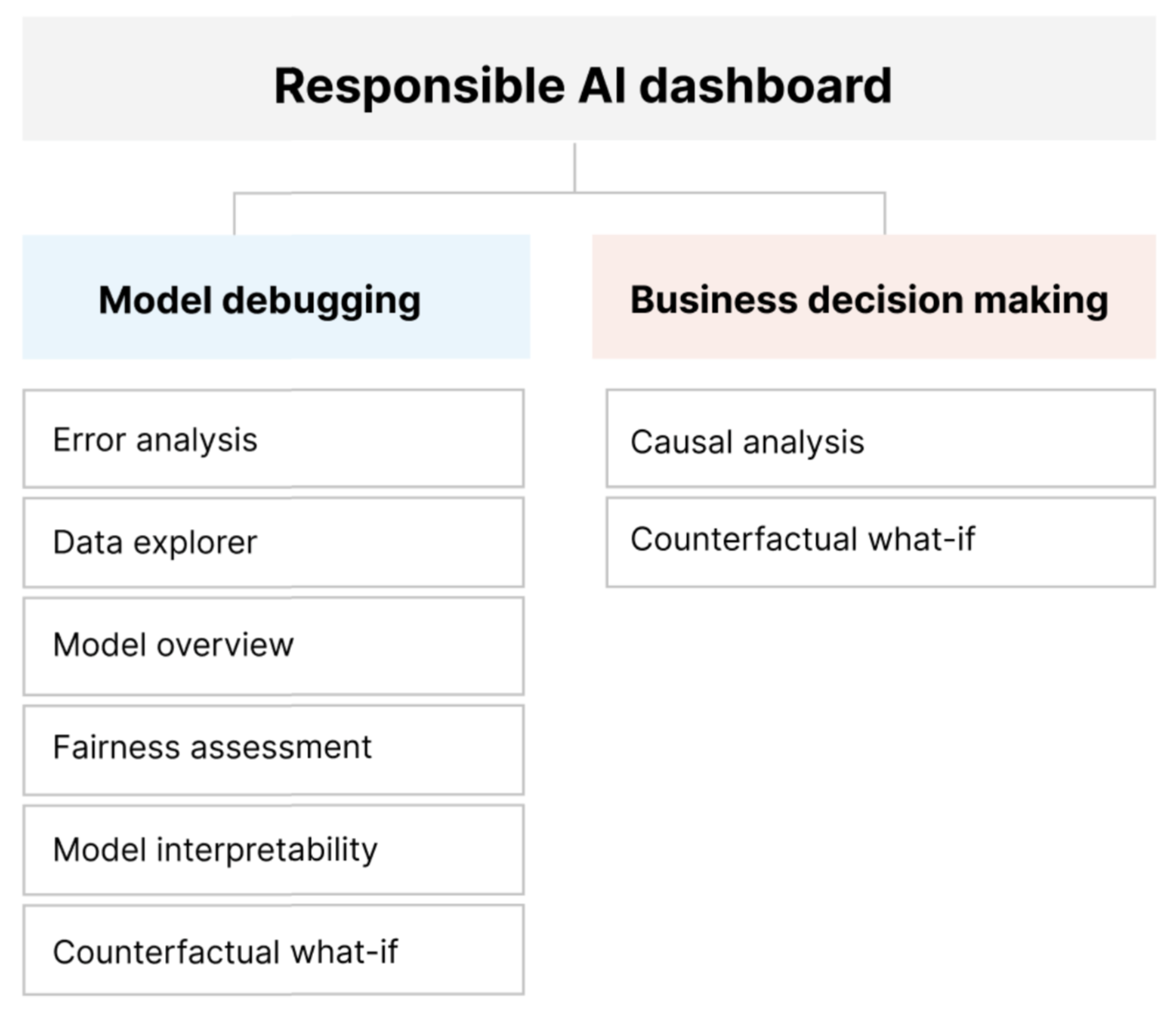
Das Dashboard „Verantwortungsvolle KI“ bietet eine einzige Benutzeroberfläche, die Ihnen dabei hilft, verantwortungsvolle KI in der Praxis effektiv und effizient zu implementieren. Es vereint mehrere ausgereifte Tools für verantwortungsvolle KI in den folgenden Bereichen:
- Bewertung der Modellleistung und Fairness
- Durchsuchen von Daten
- Interpretierbarkeit beim maschinellen Lernen
- Fehleranalyse
- Kontrafaktische Analyse und Störeinflüsse
- Kausaler Rückschluss
Das Dashboard ermöglicht eine ganzheitliche Bewertung und das Debuggen von Modellen, damit Sie fundierte, auf Daten gestützte Entscheidungen treffen können. Der Zugriff auf all diese Tools in einer zentralen Benutzeroberfläche ermöglicht Ihnen folgendes:
Werten Sie Ihre Machine Learning-Modelle aus und debuggen Sie sie, indem Sie Modellfehler und Fairnessprobleme identifizieren, die Ursachen dieser Fehler diagnostizieren und auf Grundlage der gewonnenen Erkenntnisse die Schritte zur Problembehebung bestimmen.
Steigern Sie Ihre Fähigkeiten zur datengestützten Entscheidungsfindung, indem Sie Fragen wie folgende beantworten:
„Was ist die geringste Änderung, die Benutzer an Features vornehmen können, um mit dem Modell ein anderes Ergebnis zu erzielen?“
„Was ist die kausale Auswirkung einer Verringerung oder Erhöhung eines Features (z. B. Verzehr von rotem Fleisch) auf ein reales Ergebnis (z. B. Fortschreiten von Diabetes)?“
Sie können das Dashboard anpassen, um nur die Tools hinzuzufügen, die für Ihren Anwendungsfall relevant sind.
Das Dashboard „Verantwortungsvolle KI“ wird von einer PDF-Scorecard begleitet. Mit der Scorecard können Sie Metadaten für verantwortungsvolle KI sowie Erkenntnisse zu Ihren Daten und Modellen exportieren. Sie können sie dann offline mit den Beteiligten aus den Produkt- und Complianceteams teilen.
Komponenten des Dashboards für verantwortungsbewusste KI
Das Dashboard „Verantwortungsvolle KI“ vereint neue und bereits vorhandene Tools in einer umfassenden Ansicht. Das Dashboard integriert diese Tools in Azure Machine Learning CLI v2, Azure Machine Learning SDK für Python v2 und Azure Machine Learning Studio. Zu diesen Tools zählen:
- Datenanalyse zum Verstehen und Untersuchen der Verteilungen und Statistiken Ihres Datasets.
- Übersicht über das Modell und Fairnessbewertung zum Bewerten der Leistung und von Problemen mit der Gruppenfairness Ihres Modells (wie verschiedene Personengruppen von den Vorhersagen betroffen sind).
- Fehleranalyse zum Anzeigen und Verstehen der Verteilung von Fehlern in Ihrem Dataset.
- Interpretierbarkeit von Modellen (Relevanzwerte für aggregierte und individuelle Features) zum Verstehen der Vorhersagen Ihres Modells und der Art und Weise, wie diese allgemeinen und individuellen Vorhersagen getroffen werden.
- Kontrafaktische Was-wäre-wenn-Annahme zum Beobachten der potenziellen Auswirkung von Featurestöreinflüssen auf Ihre Modellvorhersagen und Bereitstellen der nächstgelegenen Datenpunkte mit entgegengesetzten oder unterschiedlichen Modellvorhersagen.
- Ursachenanalyse zur Verwendung historischer Daten zum Anzeigen der kausalen Auswirkungen von Behandlungsfeatures auf das reale Ergebnis.
Zusammen ermöglichen Ihnen diese Tools das Debuggen von Machine Learning-Modellen, während sie gleichzeitig Informationen zum Treffen daten- und modellgestützter Entscheidungen liefern. Das folgende Diagramm zeigt, wie Sie die Tools in Ihren KI-Lebenszyklus integrieren können, um Ihre Modelle zu verbessern und solide Datenerkenntnisse zu gewinnen.
Debuggen des Models
Bewertung und Debuggen von Machine Learning-Modellen sind entscheidend für die Zuverlässigkeit, Interpretierbarkeit, Fairness und Konformität der Modelle. Es hilft herauszufinden, wie und warum sich KI-Systeme auf eine bestimmte Weise verhalten. Dieses Wissen können Sie dann zur Verbesserung der Modellleistung nutzen. Das Debuggen von Modellen besteht aus drei Phasen:
Identifizieren, um Modellfehler und/oder Fairnessprobleme zu verstehen und zu erkennen, indem die folgenden Fragen gestellt werden:
„Welche Arten von Fehlern weist mein Modell auf?“
„In welchen Bereichen treten Fehler am häufigsten auf?“
Diagnostizieren, um die Ursachen für die identifizierten Fehler zu erkunden, indem Folgendes behandelt wird:
„Was sind die Ursachen für diese Fehler?“
„Worauf sollten sich meine Ressourcen konzentrieren, um mein Modell zu verbessern?“
Entschärfen, um die Erkenntnisse aus den vorangegangenen Phasen zur Identifizierung und Diagnose zu nutzen, um gezielte Schritte zur Problembehebung zu ergreifen und Fragen wie die folgenden zu beantworten:
„Wie kann ich mein Modell verbessern?“
„Welche sozialen oder technischen Lösungen gibt es für diese Probleme?“

In der folgenden Tabelle wird beschrieben, wann Sie die Komponenten des Dashboards „Verantwortungsvolle KI“ verwenden, um das Debuggen von Modellen zu unterstützen:
| Phase | Komponente | BESCHREIBUNG |
|---|---|---|
| Identify | Fehleranalyse | Die Komponente „Fehleranalyse“ hilft Ihnen, ein tieferes Verständnis der Modellfehlerverteilung zu erlangen und fehlerhafte Kohorten (Untergruppen) von Daten schnell zu identifizieren. Die Funktionen dieser Komponente des Dashboards stammen aus dem Paket Fehleranalyse. |
| Identify | Fairnessanalyse | Die Komponente „Fairness“ definiert Gruppen anhand von vertraulichen Attributen wie Geschlecht, Rasse und Alter. Anschließend bewertet sie, wie diese Gruppen von Ihren Modellvorhersagen betroffen sind und wie Abweichungen minimiert werden können. Sie bewertet die Leistung Ihres Modells, indem sie die Verteilung Ihrer Vorhersagewerte und die Werte Ihrer Modellleistungsmetriken über verschiedene Gruppen hinweg untersucht. Die Funktionen dieser Komponente des Dashboards stammen aus dem Paket Fairlearn. |
| Identify | Übersicht über das Modell | Die Komponente „Übersicht über das Modell“ aggregiert Metriken zur Modellbewertung in einer allgemeinen Übersicht über die Verteilung der Modellvorhersagen, um eine bessere Untersuchung der Leistung zu ermöglichen. Die Komponente ermöglicht auch eine Bewertung der Gruppenfairness, indem sie die Aufschlüsselung der Modellleistung in Bezug auf sensible Gruppen hervorhebt. |
| Diagnose | Datenanalyse | Die Datenanalyse visualisiert Datasets auf der Grundlage von vorhergesagten und tatsächlichen Ergebnissen, Fehlergruppen und spezifischen Features. Anschließend können Sie Probleme der Über- und Unterrepräsentation identifizieren und sehen, wie Daten im Dataset gruppiert sind. |
| Diagnose | Interpretierbarkeit von Modellen | Die Komponente „Interpretierbarkeit von Modellen“ generiert für Menschen verständliche Erklärungen zu den Vorhersagen eines Machine Learning-Modells. Es bietet mehrere Einblicke in das Verhalten eines Modells: - Globale Erklärungen (z. B. welche Features das Gesamtverhalten eines Kreditvergabemodells beeinflussen) - Lokale Erklärungen (z. B. warum der Kreditantrag eines Kunden genehmigt oder abgelehnt wurde) Die Funktionen dieser Komponente des Dashboards stammen aus dem Paket InterpretML. |
| Diagnose | Kontrafaktische Analyse und Was-wäre-wenn | Die Komponente „Kontrafaktische Analyse und Was-wäre-wenn“ besteht aus zwei Funktionen zur besseren Fehlerdiagnose: - Generieren einer Reihe von Beispielen, die durch minimale Änderungen an einem bestimmten Punkt die Vorhersage des Modells ändern. Die Beispiele zeigen also die nächstgelegenen Datenpunkte mit entgegengesetzten Modellvorhersagen. - Ermöglichen interaktiver und benutzerdefinierter Was-wäre-wenn-Störungen für einzelne Datenpunkte, um zu verstehen, wie das Modell auf Featureänderungen reagiert. Die Funktionen dieser Komponente des Dashboards stammen aus dem Paket DiCE. |
Schritte zur Problembehebung sind über eigenständige Tools wie Fairlearn verfügbar. Weitere Informationen finden Sie in der Beschreibung der Algorithmen zur Vermeidung von Unfairness.
Verantwortungsvolle Entscheidungsfindung
Die Entscheidungsfindung ist eines der größten Versprechen des maschinellen Lernens. Das Dashboard „Verantwortungsvolle KI“ kann Ihnen wie folgt helfen, fundierte Geschäftsentscheidungen zu treffen:
Datengestützte Erkenntnisse, die helfen, kausale Behandlungseffekte für ein Ergebnis zu verstehen, wobei ausschließlich historische Daten verwendet werden. Zum Beispiel:
„Wie würde sich ein Medikament auf den Blutdruck eines Patienten auswirken?“
„Wie würde sich die Bereitstellung von Werbeangeboten für bestimmte Kunden auf den Umsatz auswirken?“
Solche Erkenntnisse werden durch die Komponente Kausaler Rückschluss des Dashboards ermöglicht.
Modellgestützte Erkenntnisse, um die Fragen der Benutzer zu beantworten (Beispiel: „Was kann ich tun, um beim nächsten Mal ein anderes Ergebnis von Ihrer KI zu erhalten?“), damit die Benutzer Maßnahmen ergreifen können. Diese Erkenntnisse werden wissenschaftlichen Fachkräften für Daten über die Komponente Kontrafaktische Was-wäre-wenn-Annahme zur Verfügung gestellt.

Funktionen für explorative Datenanalyse, kausalen Rückschluss und kontrafaktische Analyse können Sie dabei unterstützen, fundierte modell- und datengestützte Entscheidungen verantwortungsvoll zu treffen.
Die folgenden Komponenten des Dashboards „Verantwortungsvolle KI“ unterstützen eine verantwortungsvolle Entscheidungsfindung:
Datenanalyse: Sie können die Komponente „Datenanalyse“ an dieser Stelle wiederverwenden, um Datenverteilungen zu verstehen sowie Über- und Unterrepräsentation zu identifizieren. Die Untersuchung von Daten ist ein wichtiger Bestandteil der Entscheidungsfindung, da es nicht möglich ist, fundierte Entscheidungen über eine Kohorte zu treffen, die in den Daten unterrepräsentiert ist.
Kausaler Rückschluss: Die Komponente „Kausaler Rückschluss“ schätzt, wie sich ein reales Ergebnis durch einen Eingriff verändern kann. Außerdem hilft sie, vielversprechende Interventionen zu erstellen, indem Featureantworten auf unterschiedliche Interventionen simuliert und Regeln erstellt werden, um zu bestimmen, welche Kohorten der Grundgesamtheit von einer bestimmten Intervention profitieren würden. Mit diesen Funktionen können Sie neue Richtlinien anwenden und Veränderungen in der Praxis bewirken.
Die Funktionen dieser Komponente stammen aus dem Paket EconML, das mithilfe des maschinellen Lernens heterogene Behandlungseffekte anhand von Beobachtungsdaten abschätzt.
Kontrafaktische Analyse: Sie können die Komponente „Kontrafaktische Analyse“ an dieser Stelle wiederverwenden, um minimale Änderungen zu generieren, die auf die Features eines Datenpunkts angewendet werden und zu entgegengesetzten Modellvorhersagen führen. Beispiel: Taylor hätte die Kreditgenehmigung von der KI erhalten, wenn ihr Jahreseinkommen 10.000 USD höher wäre und sie zwei Kreditkarten weniger hätte.
Die Bereitstellung dieser Informationen für Benutzer beeinflusst ihre Perspektive. Sie erfahren, mit welcher Aktion sie in Zukunft das gewünschte Ergebnis von der KI erhalten können.
Die Funktionen dieser Komponente stammen aus dem Paket DiCE.
Gründe für die Verwendung des Dashboards „Verantwortungsvolle KI“
Obwohl Fortschritte bei einzelnen Tools für bestimmte Bereiche der verantwortungsvollen KI erzielt wurden, müssen wissenschaftliche Fachkräfte für Daten häufig verschiedene Tools verwenden, um ihre Modelle und Daten ganzheitlich auszuwerten. Beispielsweise müssen sie möglicherweise die Interpretierbarkeit von Modellen und die Fairnessbewertung zusammen verwenden.
Wenn eine wissenschaftliche Fachkraft für Daten mit einem Tool ein Fairnessproblem entdeckt, muss sie ein anderes Tool verwenden, um zu verstehen, welche Daten oder Modellfaktoren dem Problem zugrunde liegen, bevor sie Schritte zur Problembehebung unternehmen kann. Die folgenden Faktoren erschweren diesen anspruchsvollen Prozess zusätzlich:
- Es gibt keinen zentralen Ort, an dem die Tools entdeckt und getestet werden können, was den Zeitaufwand für die Recherche und das Erlernen neuer Techniken erhöht.
- Die verschiedenen Tools kommunizieren nicht miteinander. Wissenschaftliche Fachkräfte für Daten müssen sich mit den Datasets, Modellen und anderen Metadaten auseinandersetzen, wenn sie diese zwischen den Tools übergeben.
- Die Metriken und Visualisierungen lassen sich nicht problemlos vergleichen, und die Ergebnisse sind schwer zu teilen.
Das Dashboard „Verantwortungsvolle KI“ hinterfragt diesen Status quo. Es ist ein umfassendes und doch anpassbares Tool, das fragmentierte Funktionen an einem zentralen Ort vereint. Es ermöglicht Ihnen die nahtlose Integration eines einzelnen anpassbaren Frameworks für das Debuggen von Modellen und die datengestützte Entscheidungsfindung.
Mithilfe des Dashboards „Verantwortungsvolle KI“ können Sie Datasetkohorten erstellen, diese Kohorten an alle unterstützten Komponenten übergeben und die Modellintegrität für die identifizierten Kohorten beobachten. Sie können Erkenntnisse aus allen unterstützten Komponenten für eine Vielzahl vordefinierter Kohorten vergleichen, um disaggregierte Analysen durchzuführen und die Schwachpunkte Ihres Modells zu finden.
Wenn Sie bereit sind, diese Erkenntnisse mit anderen Beteiligten zu teilen, können Sie sie mithilfe der PDF-Scorecard für verantwortungsvolle KI ganz einfach extrahieren. Fügen Sie den PDF-Bericht an Ihre Konformitätsberichte an, oder teilen Sie ihn mit Kollegen, um Vertrauen aufzubauen und ihre Zustimmung zu erlangen.
Möglichkeiten zum Anpassen des Dashboards „Verantwortungsvolle KI“
Die Stärke des Dashboards „Verantwortungsvolle KI“ liegt in seiner Anpassungsfähigkeit. Es ermöglicht es den Benutzern, angepasste, End-to-End-Workflows für das Debuggen von Modellen und die Entscheidungsfindung zu entwerfen, die ihren speziellen Anforderungen entsprechen.
Wünschen Sie sich Inspiration? Im Folgenden finden Sie einige Beispiele dafür, wie die Dashboardkomponenten zusammengesetzt werden können, um Szenarien auf unterschiedliche Weise zu analysieren:
| Dashboard „Verantwortungsvolle KI“: Flow | Anwendungsfall |
|---|---|
| Übersicht über das Modell > Fehleranalyse > Datenanalyse | So identifizieren und diagnostizieren Sie Modellfehler, indem Sie die zugrunde liegende Datenverteilung verstehen |
| Übersicht über das Modell > Fairnessbewertung > Datenanalyse | So identifizieren und diagnostizieren Sie Probleme mit der Modellfairness, indem Sie die zugrunde liegende Datenverteilung verstehen |
| Übersicht über das Modell > Fehleranalyse > Kontrafaktische Analyse und Was-wäre-wenn | So diagnostizieren Sie Fehler in einzelnen Instanzen mit kontrafaktischen Analysen (minimale Änderung, um zu einer anderen Modellvorhersage zu führen) |
| Übersicht über das Modell > Datenanalyse | So verstehen Sie die Grundursache von Fehlern und Fairnessproblemen, die über unausgeglichene Daten oder fehlende Repräsentation einer bestimmten Datenkohorte eingeführt wurden |
| Übersicht über das Modell > Interpretierbarkeit | So diagnostizieren Sie Modellfehler, indem Sie verstehen, wie das Modell seine Vorhersagen getroffen hat |
| Datenanalyse > Kausaler Rückschluss | So unterscheiden Sie zwischen Korrelationen und Ursachen in den Daten oder entscheiden sich für die besten Behandlungen zum Erreichen eines positiven Ergebnisses |
| Interpretierbarkeit > Kausaler Rückschluss | So erfahren Sie, ob die Faktoren, die das Modell für die Vorhersage verwendet hat, Auswirkungen auf das reale Ergebnis haben |
| Datenanalyse > Kontrafaktische Analyse und Was-wäre-wenn | So beantworten Sie Kundenfragen dazu, wie sie beim nächsten Mal vorgehen können, um ein anderes Ergebnis von einem KI-System zu erhalten |
Personen, die das Dashboard „Verantwortungsvolle KI“ verwenden sollten
Das Dashboard „Verantwortungsvolle KI“ und die dazugehörige Scorecard für verantwortungsvolle KI können von den folgenden Personen genutzt werden, um Vertrauen in KI-Systeme zu schaffen:
- Machine Learning-Experten und wissenschaftliche Fachkräfte für Daten, die daran interessiert sind, ihre Machine Learning-Modelle vor der Bereitstellung zu debuggen und zu verbessern
- Machine Learning-Experten und wissenschaftliche Fachkräfte für Daten, die daran interessiert sind, ihre Modelldaten mit Produktmanagern und Beteiligten im Unternehmen zu teilen, um Vertrauen aufzubauen und Bereitstellungsberechtigungen zu erhalten
- Produktmanager und Beteiligte im Unternehmen, die Machine Learning-Modelle vor der Bereitstellung überprüfen
- Risikobeauftragte, die Machine Learning-Modelle überprüfen, um Fragen der Fairness und Zuverlässigkeit zu verstehen
- Anbieter von KI-Lösungen, die Benutzern Modellentscheidungen erklären oder ihnen helfen möchten, das Ergebnis zu verbessern
- Experten in stark regulierten Branchen, die Machine Learning-Modelle mit Regulierungsstellen und Prüfern überprüfen müssen
Unterstützte Szenarien und Einschränkungen
- Das Dashboard „Verantwortungsvolle KI“ unterstützt derzeit Regressionsmodelle und Klassifizierungsmodelle (binär und mit mehreren Klassen), die mit tabellarischen strukturierten Daten trainiert wurden.
- Das Dashboard „Verantwortungsvolle KI“ unterstützt derzeit nur MLflow-Modelle, die in Azure Machine Learning mit einer sklearn-Variante (scikit-learn) registriert sind. Die scikit-learn-Modelle sollten
predict()/predict_proba()-Methoden implementieren, oder das Modell sollte in einer Klasse, diepredict()/predict_proba()-Methoden implementiert, umschlossen sein. Die Modelle müssen in der Komponentenumgebung geladen werden können und auswählbar sein. - Das Dashboard „Verantwortungsvolle KI“ visualisiert derzeit bis zu 5.000 Ihrer Datenpunkte auf der Dashboardbenutzeroberfläche. Sie sollten Ihr Dataset per Downsampling auf maximal 5.000 Datenpunkte reduzieren, bevor Sie es an das Dashboard übergeben.
- Die Dataseteingaben im Dashboard „Verantwortungsvolle KI“ müssen Pandas-Datenrahmen im Parquet-Format sein. NumPy- und SciPy-Daten mit geringer Dichte werden derzeit nicht unterstützt.
- Das Dashboard „Verantwortungsvolle KI“ unterstützt derzeit numerische oder kategorische Features. Für kategorische Features muss der Benutzer die Featurenamen explizit angeben.
- Das Dashboard „Verantwortungsvolle KI“ unterstützt derzeit keine Datasets mit mehr als 10.000 Spalten.
- Das Dashboard für verantwortungsvolle KI unterstützt derzeit kein AutoML MLFlow-Modell.
- Das Dashboard für verantwortungsvolle KI unterstützt derzeit keine registrierten AutoML-Modelle über die Benutzeroberfläche.
Nächste Schritte
- Erfahren Sie, wie Sie das Dashboard für verantwortungsbewusste künstliche Intelligenz über CLI und SDK oder die Azure Machine Learning Studio-Benutzeroberfläche generieren.
- Erfahren Sie, wie Sie eine Scorecard für verantwortungsvolle KI auf Grundlage der im Dashboard „Verantwortungsvolle KI“ beobachteten Erkenntnisse generieren.