Modell-Sweeping und -Auswahl für Vorhersagen mit automatisiertem maschinellem Lernen
Dieser Artikel beschreibt, wie automatisiertes maschinelles Lernen (AutoML) in Azure Machine Learning nach Vorhersagemodellen sucht und diese auswählt. Wenn Sie mehr über die Prognosemethodik in AutoML erfahren möchten, lesen Sie Übersicht über Prognosemethoden in AutoML. Informationen zu Trainingsbeispielen für Prognosemodelle in AutoML finden Sie unter Einrichten von AutoML zum Trainieren eines Zeitreihenprognosemodells mit dem SDK und CLI.
Modell-Sweeping in automatisiertem ML
Die zentrale Aufgabe des automatisierten maschinellen Lernens besteht darin, mehrere Modelle zu trainieren und auszuwerten und das beste Modell für die angegebene primäre Metrik auszuwählen. Das Wort „Modell“ bezieht sich in diesem Fall sowohl auf die Modellklasse, z. B. ARIMA oder zufällige Gesamtstruktur, als auch auf die spezifischen Hyperparametereinstellungen, die Modelle innerhalb einer Klasse unterscheiden. ARIMA bezieht sich beispielsweise auf eine Klasse von Modellen mit einer gemeinsamen mathematischen Vorlage und einer Reihe gemeinsamer statistischer Annahmen. Für das Training oder die Anpassung eines ARIMA-Modells ist eine Liste von positiven ganzen Zahlen erforderlich, welche die genaue mathematische Form des Modells angeben. Diese Werte sind die Hyperparameter. Die Modelle ARIMA(1, 0, 1) und ARIMA(2, 1, 2) gehören zur selben Klasse, haben aber unterschiedliche Hyperparameter. Diese Definitionen können separat mit den Trainingsdaten abgeglichen und gegeneinander ausgewertet werden. Suchvorgänge – oder Sweeps – für automatisiertes ML über verschiedene Modellklassen und innerhalb von Klassen durch Variieren von Hyperparametern.
Hyperparameter-Sweepingmethoden
Die folgende Tabelle enthält die verschiedenen Methoden für das Hyperparameter-Sweeping, die das automatisierte maschinelle Lernen für verschiedene Modellklassen verwendet:
| Modellklassengruppe | Modelltyp | Methode für das Hyperparameter-Sweeping |
|---|---|---|
| „Naiv“, „Saisonal naiv“, „Durchschnitt“, „Saisonaler Durchschnitt“ | Zeitreihe | Kein Sweeping innerhalb der Klasse aufgrund der Einfachheit des Modells |
| „Exponentielle Glättung“, „ARIMA(X)“ | Zeitreihe | Rastersuche für Sweeping innerhalb der Klasse |
| Prophet | Regression | Kein Sweeping innerhalb der Klasse |
| „Stochastisches Gradientenabstiegsverfahren (SGD)“, „LARS LASSO“, „Elastisches Netz“, „K-Pixelwiederholung“, „Entscheidungsstruktur“, „Zufällige Gesamtstruktur“, „Extremely Randomized Trees“, „Gradient-Boosted-Strukturen“, „LightGBM“, „XGBoost“ | Regression | Der Modellempfehlungsdienst des automatisierten maschinellen Lernens untersucht Hyperparameterräume dynamisch. |
| ForecastTCN | Regression | Statische Liste der Modelle, gefolgt von einer Zufallssuche nach Netzwerkgröße, Dropout-Verhältnis und Lernrate |
Eine Beschreibung der verschiedenen Modelltypen finden Sie im Abschnitt Vorhersagemodelle beim automatisierten maschinellen Lernen des Artikels „Übersicht über Vorhersagemethoden“.
Der Umfang des Sweepings durch automatisiertes ML hängt von der Konfiguration des Vorhersageauftrags ab. Sie können die Beendigungskriterien als Zeitlimit oder als Limit für die Anzahl der Versuche oder die entsprechende Anzahl von Modellen angeben. Die Logik für die frühzeitige Beendigung kann in beiden Fällen verwendet werden, um das Sweeping zu beenden, wenn sich die primäre Metrik nicht verbessert.
Modellauswahl in automatisiertem ML
Automatisiertes ML folgt einem dreistufigen Prozess, um nach Vorhersagemodellen zu suchen und sie auszuwählen:
Phase 1: Suchen Sie über Zeitreihenmodelle und wählen Sie das beste Modell aus jeder Klasse aus, indem Sie Methoden zur Maximalen Wahrscheinlichkeitsschätzung verwenden.
Phase 2: Suchen Sie über Regressionsmodelle und bewerten diese, zusammen mit den besten Zeitreihenmodellen aus Phase 1, anhand ihrer Werte für die primäre Metrik aus Validierungsgruppen.
Phase 3: Erstellen Sie ein Ensemblemodells aus den am besten bewerteten Modellen, berechnen Sie dessen Validierungsmetrik, und bewerten Sie es mit anderen Modellen.
Das Modell, das am Ende von Phase 3 über den am höchsten bewerteten Metrikwert verfügt, wird als das beste Modell betrachtet.
Wichtig
In Phase 3 berechnet automatisiertes ML immer Metriken für Daten außerhalb der Stichprobe, die nicht zum Abgleichen der Modelle verwendet werden. Dieser Ansatz trägt zum Schutz vor Überanpassung bei.
Validierungskonfigurationen
Automatisiertes ML verfügt über zwei Validierungskonfigurationen: Kreuzvalidierung und explizite Validierungsdaten.
Bei der Kreuzvalidierung verwendet das automatisierte maschinelle Lernen die Eingabekonfiguration, um Daten in Trainings- und Validierungsfaltungen aufzuteilen. Die zeitliche Reihenfolge muss in diesen Splits beibehalten werden. Automatisiertes ML verwendet die sogenannte Rolling Origin Cross Validation (Kreuzvalidierung mit rollendem Ursprung), welche die Datenreihen mithilfe eines Ursprungszeitpunkts in Trainings- und Validierungsdaten aufteilt. Wenn der Ursprung zeitlich verschoben wird, werden Teilmengen für die Kreuzvalidierung erstellt. Jede Validierungsfaltung enthält den nächsten Horizont von Beobachtungen, die unmittelbar auf die Position des Ursprungs für die angegebene Faltung folgen. Mit dieser Strategie wird die Datenintegrität von Zeitreihen beibehalten und das Risiko von Informationsabfluss verringert.
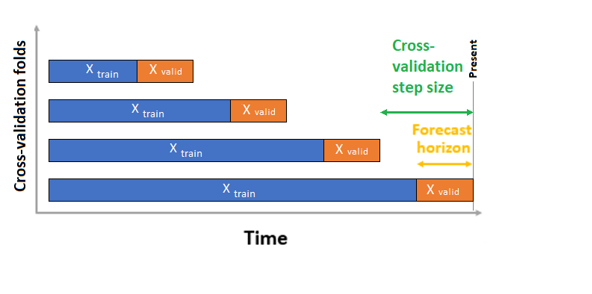
Das automatisierte maschinelle Lernen folgt dem üblichen Kreuzvalidierungsverfahren: Es trainiert ein separates Modell für jede Faltung und berechnet den Durchschnitt der Validierungsmetriken aus allen Faltungen.
Zum Konfigurieren der Kreuzvalidierung für Vorhersageaufträge wird die Anzahl von Kreuzvalidierungsfaltungen und optional die Anzahl von Zeiträumen zwischen zwei aufeinanderfolgenden Kreuzvalidierungsfaltungen festgelegt. Weitere Informationen und ein Beispiel für das Konfigurieren der Kreuzvalidierung für Vorhersagen finden Sie unter Benutzerdefinierte Einstellungen für die Kreuzvalidierung.
Sie können auch Ihre eigenen Validierungsdaten verwenden. Weitere Informationen finden Sie unter Konfigurieren von Trainings-, Validierungs-, Kreuzvalidierungs- und Testdaten in automatisiertem ML (SDK v1).