Rückschließen und Auswerten von Vorhersagemodellen
In diesem Artikel werden Konzepte im Zusammenhang mit dem Rückschließen und Auswerten von Modellen bei Vorhersageaufgaben vorgestellt. Anweisungen und Beispiele zum Trainieren von Vorhersagemodellen in AutoML finden Sie unter Einrichten von AutoML zum Trainieren eines Zeitreihen-Vorhersagemodells mit SDK und Befehlszeilenschnittstelle.
Nachdem Sie AutoML zum Trainieren und Auswählen des am besten geeigneten Modells verwendet haben, generieren Sie im nächsten Schritt Vorhersagen. Bewerten Sie danach, falls möglich, ihre Genauigkeit mithilfe von Tests mit Daten, die vom Training ausgeschlossen waren. Weitere Informationen zum Einrichten und Ausführen von Auswertungen von Vorhersagemodellen beim automatisierten maschinellen Lernen finden Sie unter Orchestrieren von Training, Rückschluss und Auswertung.
Rückschlussszenarien
Beim maschinellen Lernen ist der Rückschluss der Prozess, beim dem Modellvorhersagen für neue, nicht im Training verwendete Daten generiert werden. Aufgrund der Zeitabhängigkeit der Daten gibt es mehrere Möglichkeiten, Vorhersagen zu generieren. Das einfachste Szenario ist, dass der Zeitraum des Rückschlusses unmittelbar auf den Zeitraum des Trainings folgt und Sie Vorhersagen bis zum Vorhersagehorizont generieren. Das folgende Diagramm veranschaulicht dieses Szenario:
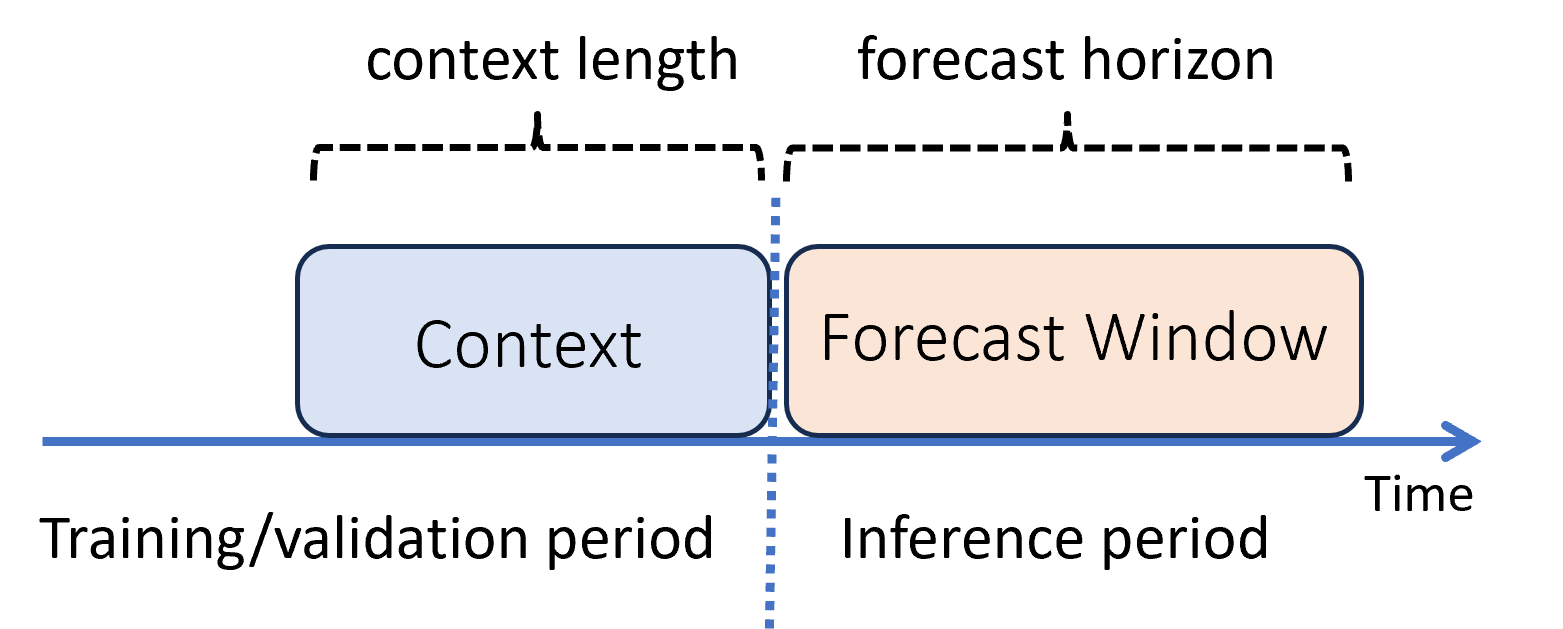
Das Diagramm zeigt zwei wichtige Parameter für den Rückschluss:
- Die Kontextlänge ist der Umfang des Verlaufs, den das Modell für eine Vorhersage benötigt.
- Der Vorhersagehorizont gibt an, wie weit in die Zukunft das Vorhersagemodul trainiert wird, um Vorhersagen zu treffen.
Vorhersagemodelle verwenden in der Regel einige Verlaufsinformationen – den Kontext –, um Vorhersagen für die Zeit bis zum Vorhersagehorizont zu treffen. Wenn der Kontext Teil der Trainingsdaten ist, speichert AutoML die für die Vorhersage erforderlichen Daten. Sie müssen daher nicht explizit angegeben werden.
Es gibt zwei weitere Rückschlussszenarien, die komplizierter sind:
- Generieren von Vorhersagen, die weiter in die Zukunft reichen als der Vorhersagehorizont
- Abrufen von Vorhersagen, wenn zwischen Training und Rückschluss eine Lücke besteht
In den folgenden Unterabschnitten werden diese Fälle beschrieben.
Vorhersagen über den Vorhersagehorizont hinaus: Rekursive Vorhersage
Wenn Sie Vorhersagen über den Horizont hinaus benötigen, wendet AutoML das Modell rekursiv über den Rückschlusszeitraum an. Die Vorhersagen des Modells werden als Eingabe zurückgeführt, um Vorhersagen für nachfolgende Vorhersagefenster zu generieren. Das folgende Diagramm zeigt ein einfaches Beispiel:
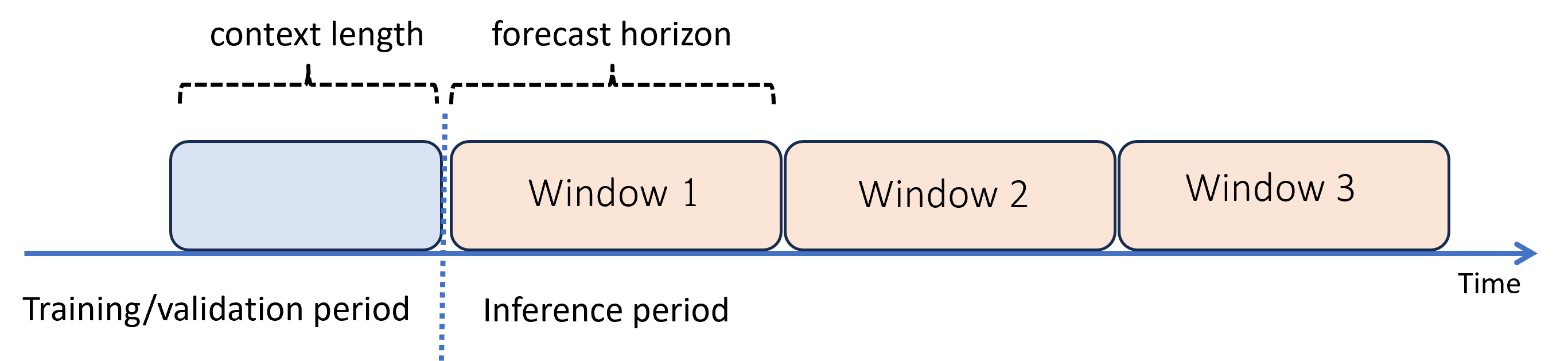
Hier generieren Sie mit dem maschinellen Lernen Vorhersagen für einen Zeitraum, der dreimal so lang ist wie der Vorhersagehorizont. Dabei werden Vorhersagen aus einem Fenster als Kontext für das nächste Fenster genutzt.
Warnung
Modellierungsfehler werden bei rekursiven Vorhersagen verstärkt. Die Vorhersagen werden umso ungenauer, je weiter sie vom ursprünglichen Vorhersagehorizont entfernt sind. Möglicherweise finden Sie ein genaueres Modell, wenn Sie das Training mit einem längeren Horizont wiederholen.
Vorhersagen mit einer Lücke zwischen Training und Rückschluss
Angenommen, Sie haben ein Modell trainiert und möchten es danach verwenden, um Vorhersagen aus neuen Beobachtungen zu generieren, die während des Trainings noch nicht verfügbar waren. In diesem Fall gibt es eine zeitliche Lücke zwischen dem Training und dem Rückschluss:
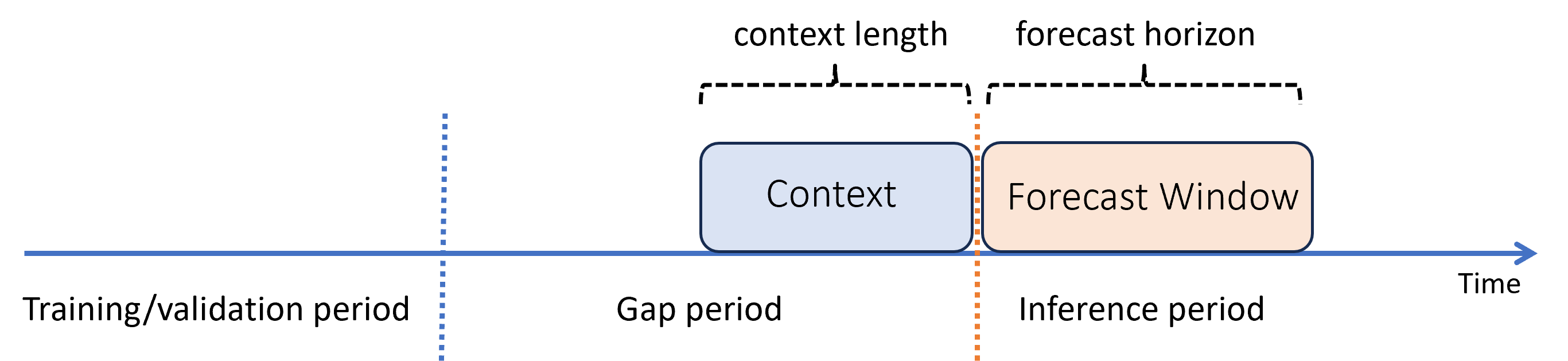
AutoML unterstützt dieses Rückschlussszenario, aber Sie müssen die Kontextdaten im Lückenzeitraum bereitstellen, wie im Diagramm gezeigt. Die an die Rückschlusskomponente übergebenen Vorhersagedaten benötigen Werte für Features und beobachtete Zielwerte in der Lücke und fehlende Werte oder NaN-Werte für das Ziel im Rückschlusszeitraum. Die folgende Tabelle zeigt ein Beispiel für dieses Muster:
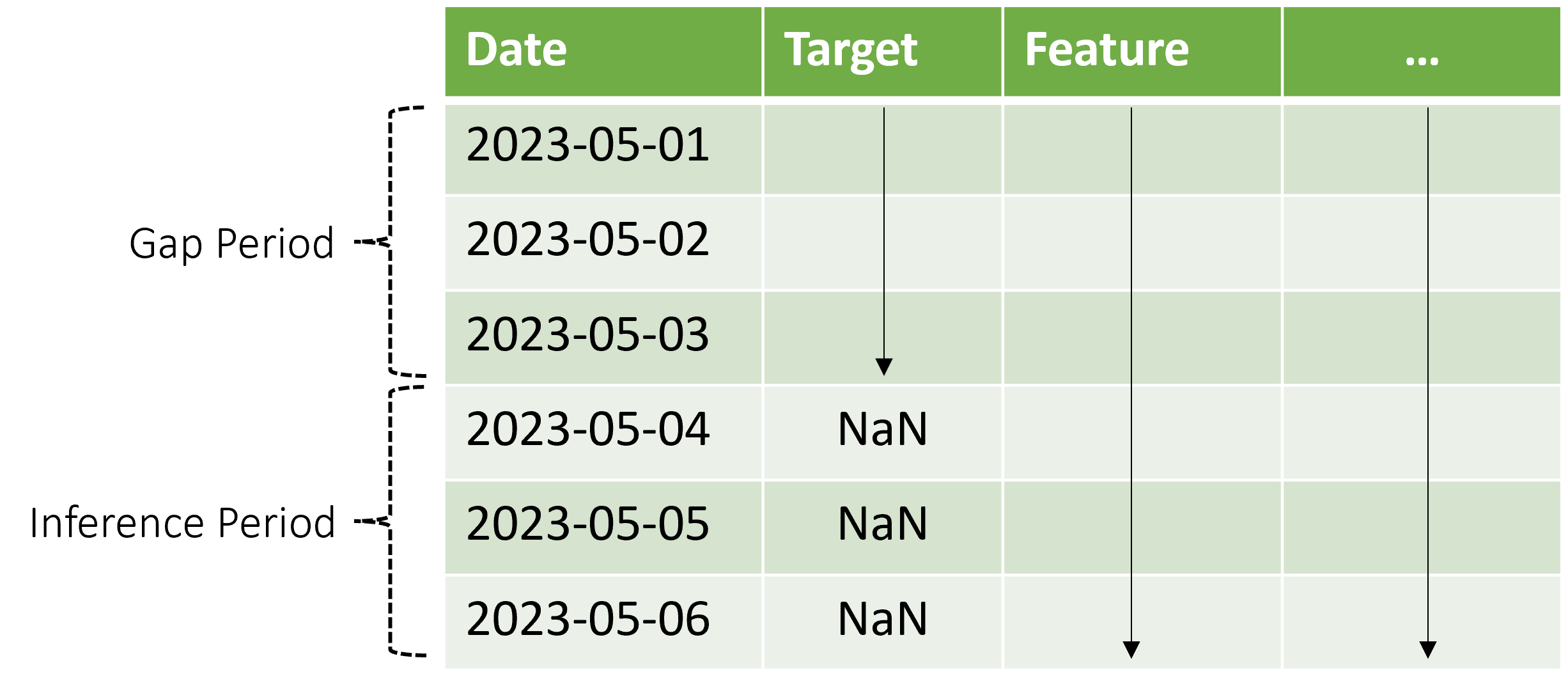
Es werden bekannte Werte des Ziels und Features für den Zeitraum vom 2023-05-01 bis 2023-05-03 angegeben. Fehlende Zielwerte ab dem 2023-05-04 zeigen an, dass der Rückschluss an diesem Datum beginnt.
AutoML verwendet die neuen Kontextdaten, um Verzögerungs- und andere Rückblickfeatures sowie auch Modelle wie ARIMA zu aktualisieren, die einen internen Zustand beibehalten. Bei diesem Vorgang werden die Modellparameter nicht aktualisiert oder erneut angepasst.
Modellauswertung
Bei der Auswertung werden Vorhersagen anhand eines Testsatzes generiert, der aus den Trainingsdaten herausgehalten wurde, und Metriken aus diesen Vorhersagen berechnet, die als Entscheidungshilfe für die Modellimplementierung dienen. Dementsprechend gibt es einen Rückschlussmodus, der für die Modellauswertung geeignet ist – eine rollierende Vorhersage.
Eine bewährte Methode zur Auswertung eines Vorhersagemodells besteht darin, das trainierte Vorhersagemodul zeitlich über den Testsatz zu rollieren und die Fehlermetriken über mehrere Vorhersagefenster zu mitteln. Dieses Verfahren wird manchmal als Backtest (Rückvergleich) bezeichnet. Im Idealfall ist der Testsatz für die Auswertung relativ zum Vorhersagehorizont des Modells lang. Schätzungen von Vorhersagefehlern können andernfalls statistisch beeinträchtigend und daher weniger zuverlässig sein.
Das folgende Diagramm zeigt ein einfaches Beispiel mit drei Vorhersagefenstern:
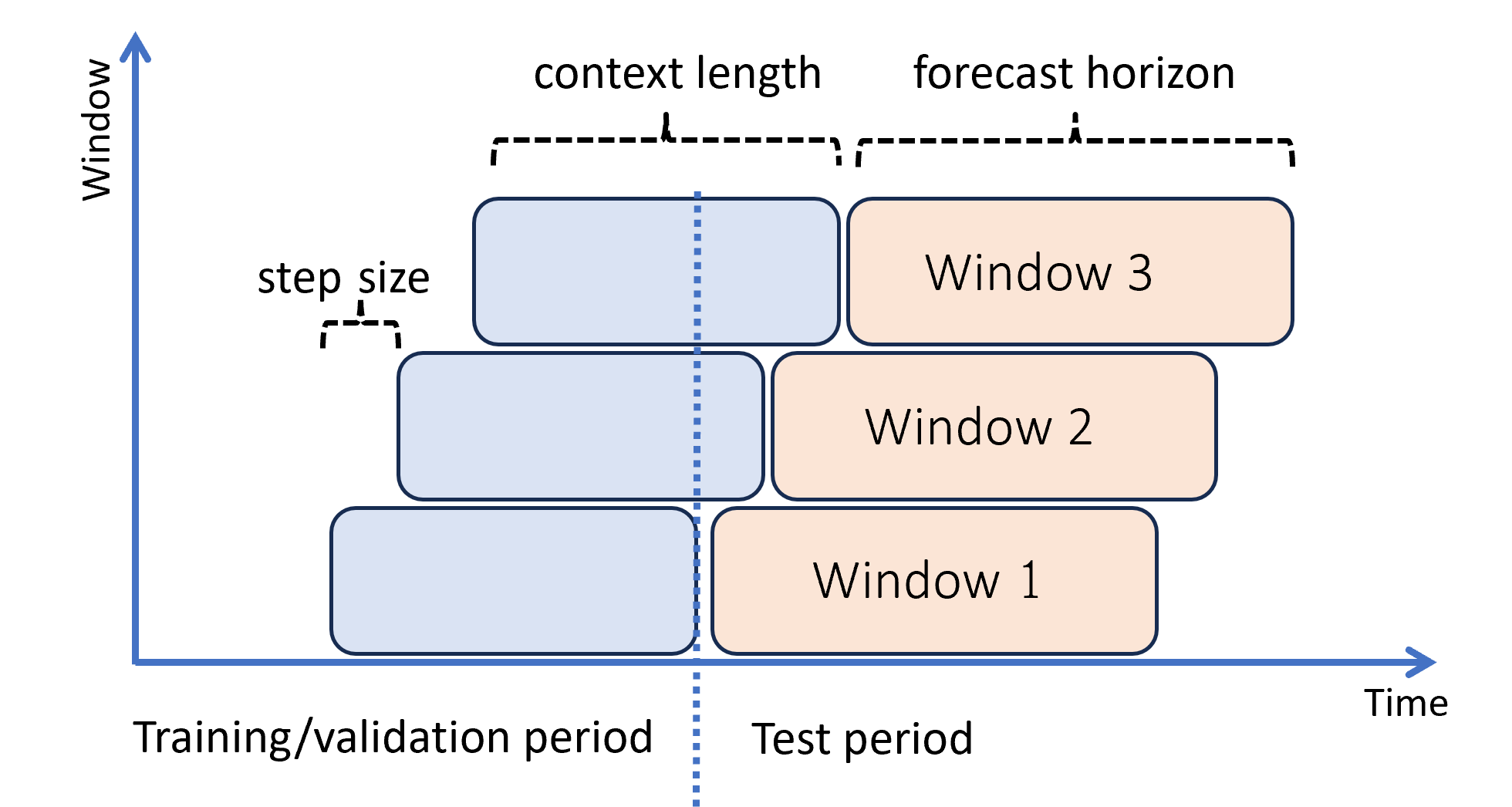
Das Diagramm veranschaulicht drei rollierende Auswertungsparameter:
- Die Kontextlänge ist der Umfang des Verlaufs, den das Modell für eine Vorhersage benötigt.
- Der Vorhersagehorizont gibt an, wie weit in die Zukunft das Vorhersagemodul trainiert wird, um Vorhersagen zu treffen.
- Die Schrittweite gibt an, wie weit das rollierende Fenster bei jeder Iteration im Testsatz vorrückt.
Der Kontext schreitet zusammen mit dem Vorhersagefenster voran. Es werden tatsächliche Werte aus dem Testsatz für Vorhersagen verwendet, wenn sie in das aktuelle Kontextfenster fallen. Das späteste Datum der für ein bestimmtes Vorhersagefenster verwendeten tatsächlichen Werte wird als Ursprungszeit des Fensters bezeichnet. Die folgende Tabelle zeigt eine Beispielausgabe der rollierenden Drei-Fenster-Vorhersage mit einem Horizont von drei Tagen und einer Schrittweite von einem Tag:
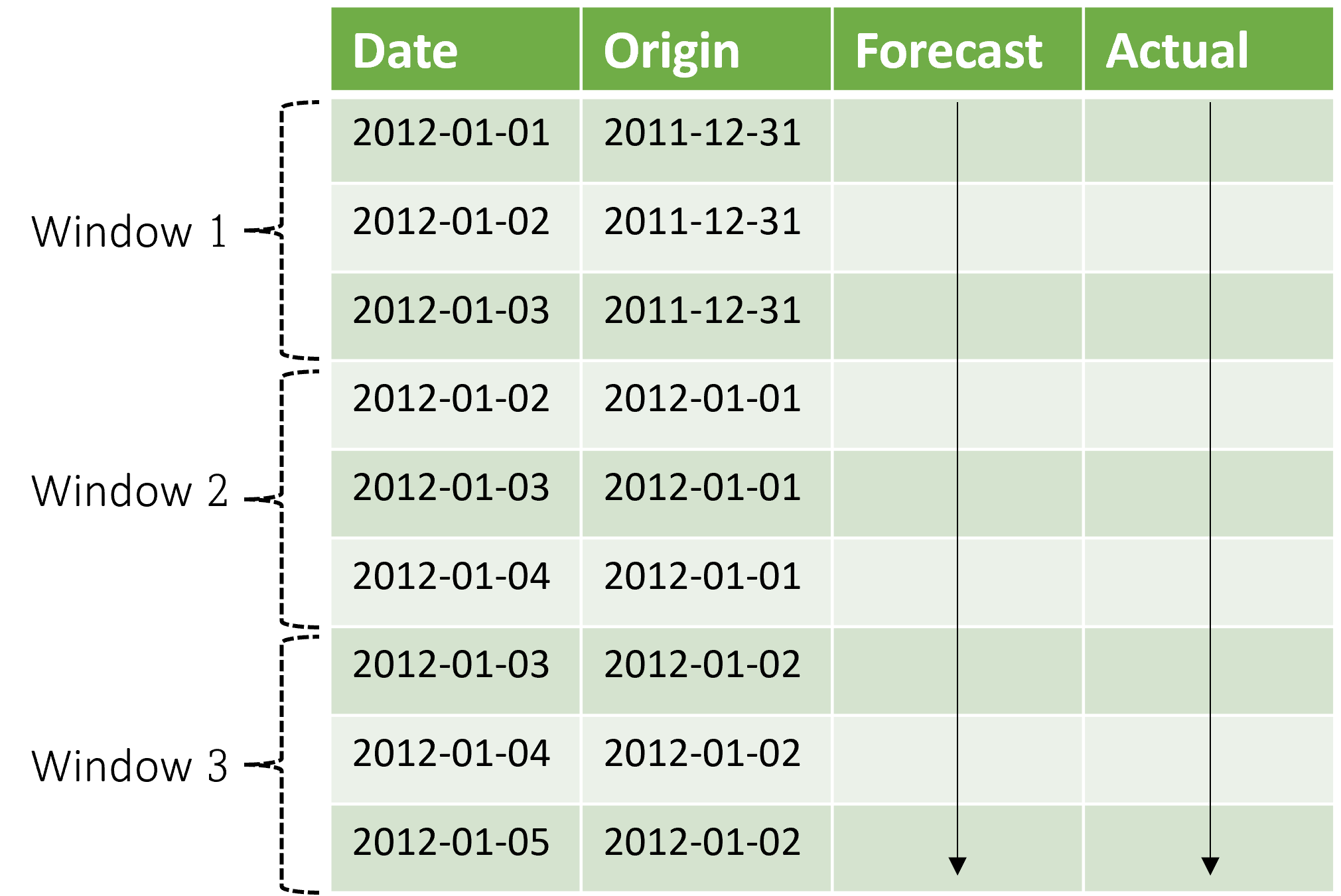
Mit einer Tabelle wie dieser können Sie die Vorhersagen im Vergleich zu den tatsächlichen Werten visualisieren und die gewünschten Auswertungsmetriken berechnen. AutoML-Pipelines können rollierende Vorhersagen für einen Testsatz mit einer Rückschlusskomponente generieren.
Hinweis
Wenn der Testzeitraum die gleiche Länge wie der Vorhersagehorizont hat, liefert eine rollierende Vorhersage ein einziges Fenster mit Vorhersagen bis zum Zeithorizont.
Auswertungsmetriken
Die Wahl der Auswertungszusammenfassung oder -metrik richtet sich in der Regel nach dem jeweiligen Geschäftsszenario. Einige gängige Optionen sind die folgenden Beispiele:
- Plots der beobachteten Zielwerte im Vergleich zu den prognostizierten Werten, um zu überprüfen, ob bestimmte Dynamiken der Daten vom Modell erfasst werden
- MAPE (mittlere absolute prozentuale Abweichung) zwischen tatsächlichen und vorhergesagten Werten
- RMSE (mittlere quadratische Gesamtabweichung), möglicherweise mit einer Normalisierung, zwischen tatsächlichen und vorhergesagten Werten
- MAE (mittlere absolute Abweichung), möglicherweise mit einer Normalisierung, zwischen tatsächlichen und vorhergesagten Werten
Je nach Geschäftsszenario gibt es viele weitere Möglichkeiten. Möglicherweise müssen Sie Ihre eigenen Hilfsprogramme für die Nachverarbeitung erstellen, um Auswertungsmetriken aus den Ergebnissen von Rückschlüssen oder rollierenden Vorhersagen zu berechnen. Weitere Informationen zu Metriken finden Sie unter Regressions-/Vorhersagemetriken.
Zugehöriger Inhalt
- Erfahren Sie mehr über das Einrichten von AutoML zum Trainieren eines Zeitreihenvorhersagemodells.
- Erfahren Sie mehr über die Verwendung von maschinellem Lernen in AutoML zum Erstellen von Vorhersagemodellen.
- Antworten auf häufig gestellte Fragen zu Vorhersagen mit automatisiertem maschinellem Lernen finden Sie hier.