Preprocess Text
Dieser Artikel beschreibt eine Komponente im Azure Machine Learning Designer.
Verwenden Sie die Komponente Text vorverarbeiten, um Text zu bereinigen und zu vereinfachen. Es unterstützt diese gängigen Textverarbeitungsvorgänge:
- Entfernen von Stoppwörtern
- Verwenden regulärer Ausdrücke zum Suchen nach und Ersetzen von spezifischen Zielzeichenfolgen
- Lemmatisierung, bei der mehrere verwandte Wörter in eine einzelne kanonische Form konvertiert werden
- Kasusnormalisierung
- Entfernen bestimmter Klassen von Zeichen, z.B. Ziffern, Sonderzeichen und Sequenzen von wiederholten Zeichen (etwa „aaaa“)
- Identifizierung und Entfernung von E-Mails und URLs
Die Komponente Preprocess Text unterstützt derzeit nur Englisch.
Konfigurieren der Textvorverarbeitung
Fügen Sie die Komponente Preprocess Text zu Ihrer Pipeline in Azure Machine Learning hinzu. Sie finden diese Komponente unter Textanalyse.
Stellen Sie eine Verbindung mit einem Dataset her, das mindestens eine Spalte mit Text enthält.
Wählen Sie die Sprache aus der Dropdownliste Language (Sprache) aus.
Text column to clean (Zu bereinigende Textspalte): Wählen Sie die Spalte aus, die Sie vorverarbeiten möchten.
Remove stop words (Stoppwörter entfernen): Wählen Sie diese Option aus, wenn Sie eine vordefinierte Liste mit Stoppwörtern auf die Textspalte anwenden möchten.
Stoppwortlisten sind sprachabhängig und anpassbar.
Lemmatization (Lemmatisierung): Wählen Sie diese Option aus, wenn Sie möchten, dass Wörter in ihrer kanonischen Form dargestellt werden. Diese Option ist nützlich, um die Anzahl eindeutiger Vorkommen von anderweitig ähnlichen Texttoken zu verringern.
Der Lemmatisierungsprozess ist hochgradig sprachabhängig.
Sätze erkennen: Wählen Sie diese Option, wenn Sie möchten, dass die Komponente bei der Durchführung der Analyse eine Satzgrenzenmarkierung einfügt.
Diese Komponente verwendet eine Reihe von drei Pipe-Zeichen
|||, um das Satzende zu repräsentieren.Führen Sie optionale Suchen- und Ersetzen-Vorgänge mithilfe regulärer Ausdrücke aus. Der reguläre Ausdruck wird vor allen anderen integrierten Optionen zuerst verarbeitet.
- Custom regular expression (Benutzerdefinierter regulärer Ausdruck): Definieren Sie den Text, nach dem Sie suchen.
- Custom replacement string (Benutzerdefinierte Ersatzzeichenfolge): Definieren Sie einen einzelnen Ersatzwert.
Normalize case to lowercase (Groß-/Kleinschreibung in Kleinbuchstaben normalisieren): Wählen Sie diese Option aus, wenn Sie ASCII-Großbuchstaben in Kleinbuchstaben umwandeln möchten.
Wenn Zeichen nicht normalisiert werden, wird das gleiche Wort in Groß- und Kleinbuchstaben als zwei verschiedene Wörter betrachtet.
Sie können auch die folgenden Typen von Zeichen oder Zeichensequenzen aus dem verarbeiteten Ausgabetext entfernen:
Remove numbers (Zahlen entfernen): Wählen Sie diese Option aus, um alle numerischen Zeichen für die angegebene Sprache zu entfernen. Identifikationsnummern sind vom Fachgebiet und von der Sprache abhängig. Wenn numerische Zeichen ein integraler Bestandteil eines bekannten Worts sind, wird die Zahl möglicherweise nicht entfernt. Weitere Informationen finden Sie unter Technische Hinweise.
Remove special characters (Sonderzeichen entfernen): Verwenden Sie diese Option, um alle nicht alphanumerischen Sonderzeichen zu entfernen.
Remove duplicate characters (Doppelte Zeichen entfernen): Wählen Sie diese Option aus, um zusätzliche Zeichen in Sequenzen zu entfernen, die sich mehr als zwei Mal wiederholen. Beispielsweise würde eine Sequenz wie „aaaaa“ in „aa“ reduziert.
Remove email addresses (E-Mail-Adressen entfernen): Wählen Sie diese Option aus, um eine beliebige Sequenz im Format
<string>@<string>zu entfernen.Remove URLs (URLs entfernen): Wählen Sie diese Option aus, um alle Sequenzen zu entfernen, die die folgenden URL-Präfixe enthalten:
http,https,ftp,www
Expand verb contractions (Verbverschmelzungen erweitern): Diese Option gilt nur für Sprachen, die Verbverschmelzungen verwenden (zurzeit nur für Englisch).
Wenn Sie diese Option auswählen, können Sie beispielsweise die Phrase „wouldn't stay there“ durch „would not stay there“ ersetzen.
Normalize backslashes to slashes (Umgekehrte Schrägstriche in Schrägstriche normalisieren): Wählen Sie diese Option aus, um alle Instanzen von
\\/zuzuordnen.Split tokens on special characters (Token für Sonderzeichen aufteilen): Wählen Sie diese Option aus, wenn Sie Wörter bei Zeichen wie
&,-usw. aufteilen möchten. Mit dieser Option können auch Sonderzeichen verringert werden, wenn sie mehr als zwei Mal wiederholt werden.Beispielsweise würde die Zeichenfolge
MS---WORDin drei Token aufgeteilt:MS,-undWORD.Übermitteln Sie die Pipeline.
Technische Hinweise
Die Komponente Preprocess-Text in Studio(classic) und Designer verwenden unterschiedliche Sprachmodelle. Für den Designer wird ein mehrstufiges Modell mit CNN-Training von spaCy verwendet. Bei der Verwendung unterschiedlicher Modelle werden verschiedene Tokenizer und Verfahren für die Satzteilmarkierung genutzt, und dies führt zu anderen Ergebnissen.
Nachstehend sind einige Beispiele aufgeführt:
| Konfiguration | Ausgabeergebnis |
|---|---|
| Mit Auswahl aller Optionen Erläuterung: In Fällen wie „3test“ in „WC-3 3test 4test“ entfernt der Designer das gesamte Wort „3test“. Der Grund ist, dass das Token „3test“ von der Satzteilmarkierung in diesem Kontext als Zahl markiert wird und vom Modul entsprechend entfernt wird. |
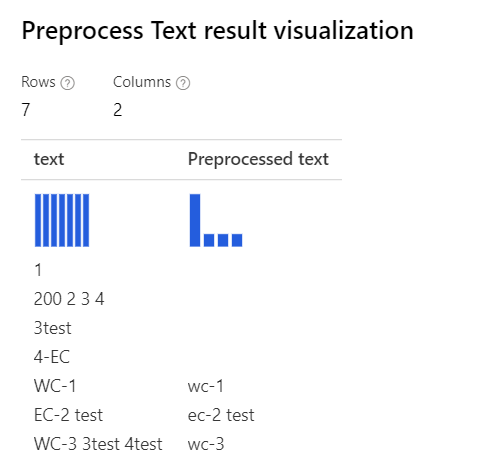
|
Nur Auswahl von Removing numberErläuterung: „3test“ und „4-EC“ werden vom Tokenizer des Designers nicht unterteilt und als gesamte Token behandelt. Daher werden die Zahlen in diesen Wörtern nicht entfernt. |

|
Sie können auch einen regulären Ausdruck verwenden, um angepasste Ergebnisse auszugeben:
| Konfiguration | Ausgabeergebnis |
|---|---|
| Alle Optionen haben den benutzerdefinierten regulären Ausdruck ausgewählt : (\s+)*(-|\d+)(\s+)* Benutzerdefinierte Ersetzungszeichenfolge: \1 \2 \3 |

|
Removing number Nur ausgewählter benutzerdefinierter regulärer Ausdruck: (\s+)*(-|\d+)(\s+)* Benutzerdefinierte Ersetzungszeichenfolge: \1 \2 \3 |
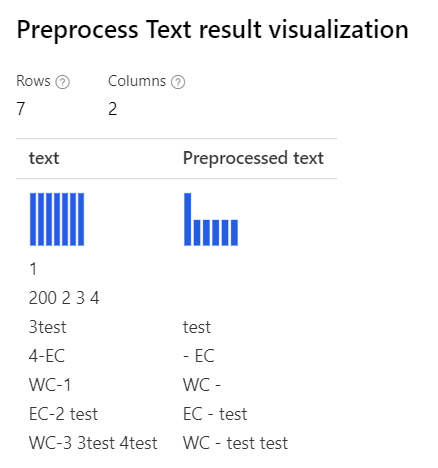
|
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.