Evaluate Model Komponente
Dieser Artikel beschreibt eine Komponente im Azure Machine Learning Designer.
Verwenden Sie diese Komponente, um die Genauigkeit eines trainierten Modells zu messen. Sie stellen ein Dataset zur Verfügung, das die anhand eines Modells generierten Ergebnisse enthält. Anschließend berechnet die Komponente Evaluate Model eine Reihe branchenüblicher Auswertungsmetriken.
Die Metriken, die vom Modul Evaluate Model zurückgegeben werden, hängen vom Typ des Modells ab, das Sie auswerten möchten:
- Klassifizierungsmodelle
- Regressionsmodelle
- Clusteringmodelle
Tipp
Wenn Sie mit der Modellauswertung noch nicht vertraut sind, empfehlen wir Ihnen die Videoreihe von Dr. Stephen Elston im Rahmen des Kurses zum maschinellen Lernen von EdX.
Verwenden von Evaluate Model
Verbinden Sie die Bewertetes Dataset-Ausgabe des Bewertungsmodells oder die Ergebnisdataset-Ausgabe von Zuweisen von Daten zu Clustern mit dem linken Eingangsport von Evaluate Model (Bewerten eines Modells).
Hinweis
Wenn Sie Komponenten wie „Select Columns in Dataset“ (Spalten im Dataset auswählen) verwenden, um einen Teil des Eingabedatasets auszuwählen, stellen Sie sicher, dass die Spalte „Actual label“ (im Training verwendet), die Spalte „Scored Probabilities“ und die Spalte „Scored Labels“ vorhanden sind, um Metriken wie AUC, Genauigkeit für binäre Klassifizierung/Anomalieerkennung zu berechnen. Die Spalten „Actual label“ und „Scored Labels“ sind vorhanden, um Metriken für die mehrklassige Klassifizierung/Regression zu berechnen. Die Spalte „Assignments“ und die Spalten „DistancesToClusterCenter no.X“ (X ist der Schwerpunktindex, der von 0 bis zur Anzahl der Schwerpunkte minus 1 reicht) sind vorhanden, um Metriken für das Clustering zu berechnen.
Wichtig
- Um die Ergebnisse auszuwerten, sollte das Ausgabedataset bestimmte Bewertungsspaltennamen enthalten, welche die Anforderungen der Evaluate Model-Komponente erfüllen.
- Es wird angenommen, dass die Spalte
Labelsdie tatsächlichen Bezeichnungen enthält. - Für die Regressionsaufgabe muss das auszuwertende Dataset über eine Spalte mit dem Namen
Regression Scored Labelsverfügen, die bewertete Bezeichnungen darstellt. - Für die binäre Klassifizierungsaufgabe muss das auszuwertende Dataset über zwei Spalten mit den Namen
Binary Class Scored LabelsundBinary Class Scored Probabilitiesverfügen, die bewertete Bezeichnungen bzw. Wahrscheinlichkeiten darstellen. - Für die Mehrfachklassifizierungsaufgabe muss das auszuwertende Dataset über eine Spalte mit dem Namen
Multi Class Scored Labelsverfügen, die bewertete Bezeichnungen darstellt. Wenn die Ausgaben der Upstreamkomponente diese Spalten nicht enthalten, müssen Sie entsprechend den oben genannten Anforderungen Änderungen vornehmen.
[Optional] Verbinden Sie die Bewertetes Dataset-Ausgabe des Bewertungsmodells oder die Ergebnisdataset-Ausgabe von „Zuweisen von Daten zu Clustern“ für das zweite Modell mit dem rechten Eingangsport von Evaluate Model (Bewerten eines Modells). Sie können die Ergebnisse zweier verschiedener Modelle auf der Grundlage derselben Daten einfach vergleichen. Die beiden Eingabealgorithmen sollten denselben Algorithmustyp aufweisen. Sie können auch Ergebnisse zweier verschiedener Ausführungen über dieselben Daten mit unterschiedlichen Parametern vergleichen.
Hinweis
Als Algorithmustyp sind zweiklassige Klassifizierung, mehrklassige Klassifizierung, Regression oder Clustering unter den Algorithmen für maschinelles Lernen möglich.
Übermitteln Sie die Pipeline, um die Bewertungsscores zu generieren.
Ergebnisse
Nachdem Sie Evaluate Model (Bewerten eines Modells) ausgeführt haben, wählen Sie die Komponente, um den Evaluate Model-Navigationsbereich auf der rechten Seite zu öffnen. Wählen Sie dann die Registerkarte Ausgaben und Protokolle aus. Auf der Registerkarte weist der Abschnitt Datenausgaben verschiedene Symbole auf. Das Symbol Visualisieren besitzt ein Balkendiagrammsymbol und stellt eine erste Möglichkeit dar, um die Ergebnisse anzuzeigen.
Bei einer binären Klassifizierung können Sie nach dem Klicken auf das Symbol Visualisieren die binäre Konfusionsmatrix visualisieren. Bei einer Multiklassifizierung befindet sich die Plotdatei der Konfusionsmatrix auf der Registerkarte Ausgaben und Protokolle:
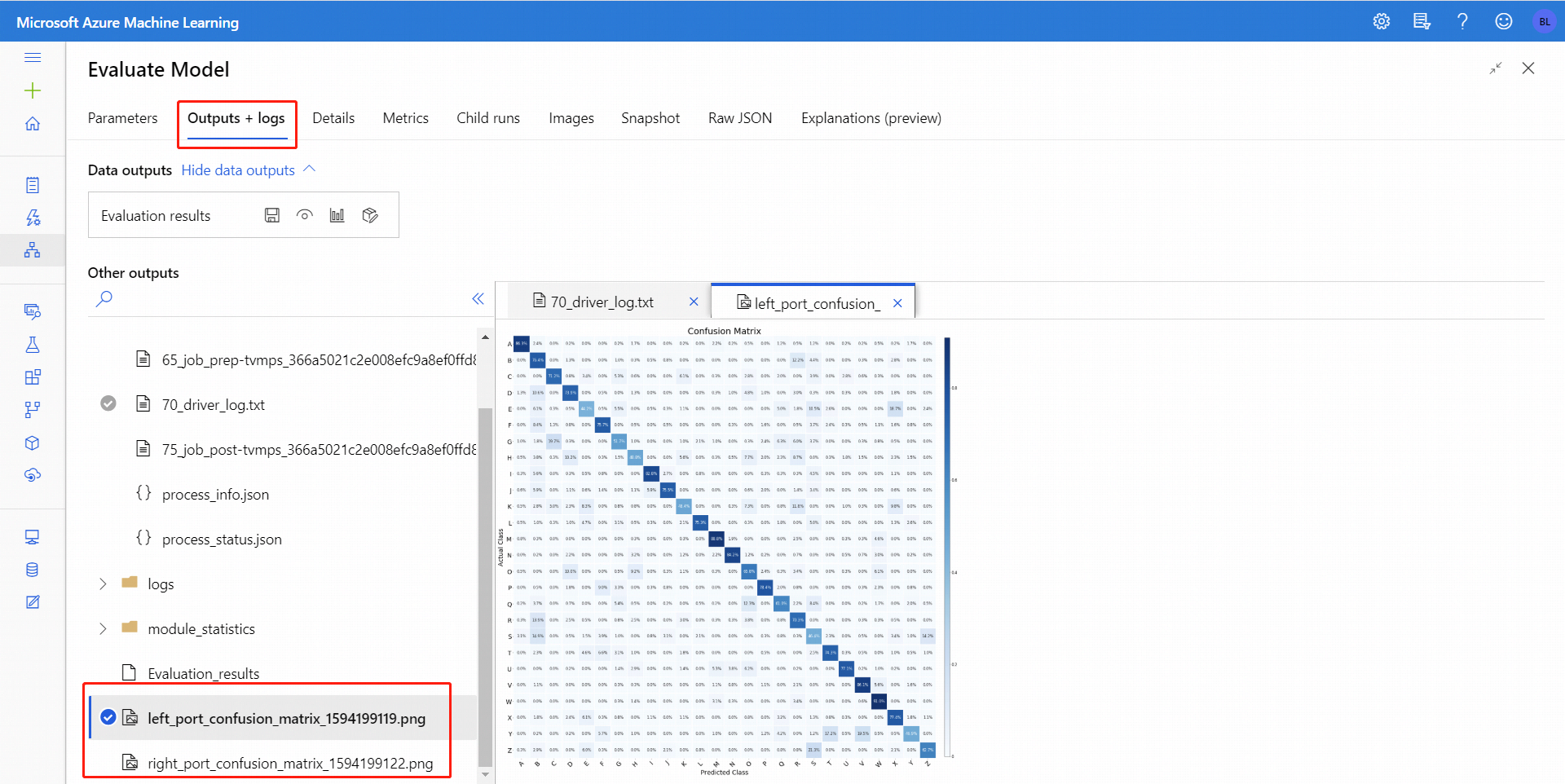
Wenn Sie Datasets mit beiden Eingaben von Evaluate Model verbinden, enthalten die Ergebnisse Metriken für beide Datasets bzw. beide Modelle. Das Modell oder die Daten, die an den linken Port angefügt wurden, werden zuerst im Bericht dargestellt, gefolgt von den Metriken für das Dataset oder das Modell, das an den rechten Port angefügt wurde.
So stellt beispielsweise die folgende Abbildung einen Vergleich der Ergebnisse zweier Clusteringmodelle dar, die anhand derselben Daten, aber mit unterschiedlichen Parametern erstellt wurden.
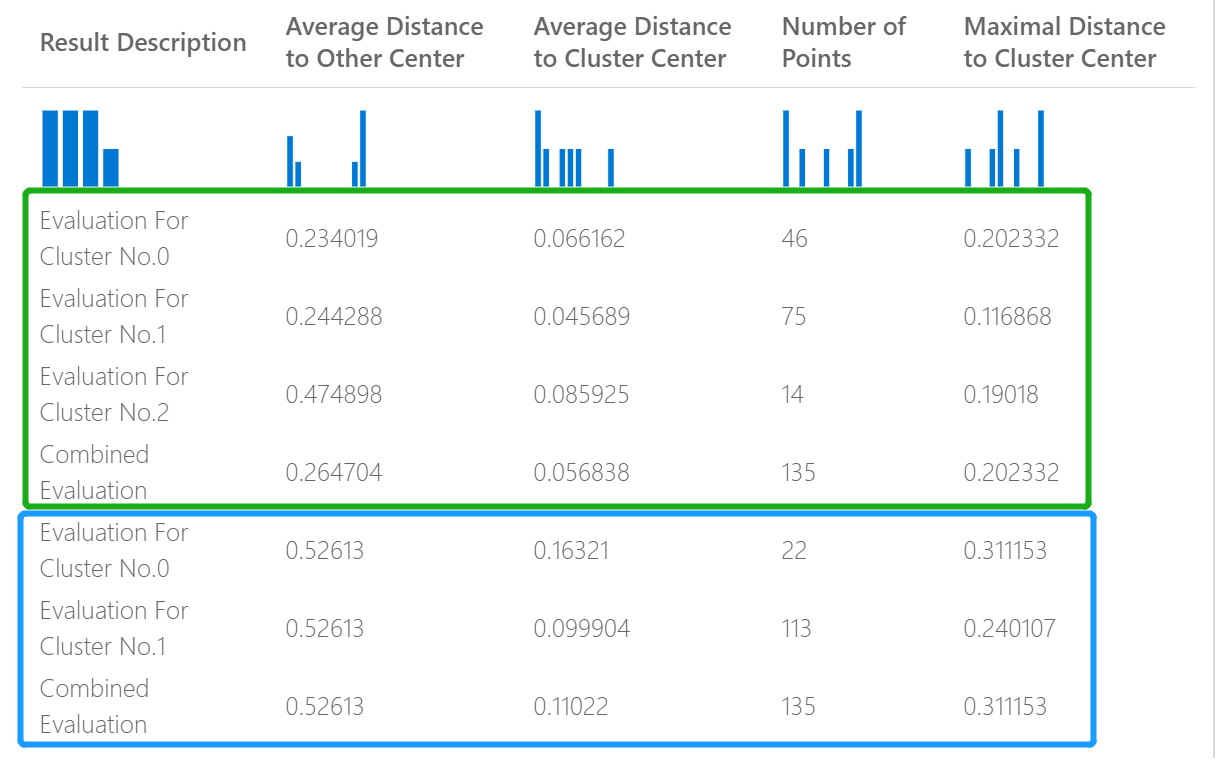
Da es sich um ein Clusteringmodell handelt, sind die Auswertungsergebnisse anders als wenn Sie Ergebnisse zweier Regressionsmodelle vergleichen oder zwei Klassifizierungsmodelle miteinander vergleichen. Die Gesamtpräsentation ist jedoch identisch.
Metriken
Dieser Abschnitt beschreibt die Metriken, die für die bestimmten Arten von Modellen zurückgegeben werden, die für den Einsatz mit Evaluate Model unterstützt werden:
Metriken für Klassifizierungsmodelle
Bei der Auswertung binärer Klassifizierungsmodellen werden folgende Metriken gemeldet:
Accuracy (Treffergenauigkeit) misst die Güte eines Klassifizierungsmodells als das Verhältnis der wahren Ergebnisse zur Gesamtheit der Fälle.
Precision (Genauigkeit) ist der Anteil wahrer Ergebnisse an allen positiven Ergebnissen. Precision = TP/(TP+FP)
Recall (Trefferquote) ist der Bruchteil der Gesamtmenge relevanter Instanzen, die tatsächlich abgerufen wurden. Recall = TP/(TP+FN)
F1 score (F1-Score) wird als gewichteter Durchschnitt von Genauigkeit und Trefferquote zwischen „0“ und „1“ berechnet, wobei „1“ der ideale Wert für den F1-Score ist.
AUC (Fläche unter der Kurve) misst den Bereich unter der Kurve, der mit wahren positiven Werten auf der y-Achse und falschen positiven Werten auf der x-Achse gezeichnet wurde. Diese Metrik ist nützlich, da sie einen einzelnen Wert liefert, mit dem Sie Modelle verschiedener Typen vergleichen können. AUC ist hinsichtlich des Klassifizierungsschwellenwerts invariant. Es misst die Qualität der Vorhersagen des Modells, unabhängig davon, welcher Klassifikationsschwellenwert gewählt wird.
Metriken für Regressionsmodelle
Die für Regressionsmodelle zurückgegebenen Metriken sind so gestaltet, dass sie die Fehlerquote schätzen. Ein Modell passt gut zu den Daten, wenn der Unterschied zwischen beobachteten und vorhergesagten Werten gering ist. Wenn Sie sich jedoch das Muster der Residuen (die Differenz zwischen einem beliebigen vorhergesagten Punkt und seinem entsprechenden Istwert) ansehen, können Sie viel über eine mögliche Verzerrung im Modell erfahren.
Die folgenden Metriken werden für die Auswertung linearer Regressionsmodelle gemeldet. Andere Re-Gressionsmodelle wie fast Forest Quantile Regression können unterschiedliche Metriken aufweisen.
Mean absolute error (MAE) (mittlerer absoluter Fehler) misst, wie nah die Vorhersagen an den tatsächlichen Ergebnissen sind, weshalb ein niedrigerer Wert besser ist.
Root mean squared error (RMSE) (mittlere quadratische Abweichung ) erzeugt einen Einzelwert, der den Fehler im Modell zusammenfasst. Durch die Quadrierung der Differenz ignoriert die Metrik den Unterschied zwischen Über- und Unterprognose.
Relative absolute error (RAE) (relativer absoluter Fehler) ist die relative absolute Differenz zwischen erwartetem und tatsächlichem Wert; relativ, weil die mittlere Differenz durch das arithmetische Mittel dividiert wird.
Relative squared error (RSE) (relativer quadratischer Fehler) normalisiert ebenfalls den gesamten quadrierten Fehler der vorhergesagten Werte durch Division durch den gesamten quadrierten Fehler der Istwerte.
Coefficient of determination (Bestimmtheitsmaß), oft auch als R2 bezeichnet, stellt die Vorhersagekraft des Modells als Wert von 0 bis 1 dar. 0 bedeutet, dass das Modell zufällig ist (also nichts erklärt). 1 bedeutet, dass es eine perfekte Anpassung gibt. Bei der Interpretation der R2-Werte ist jedoch Vorsicht geboten, da niedrige Werte völlig normal und hohe Werte verdächtig sein können.
Metriken für Clusteringmodelle
Da sich Clusteringmodelle in vielerlei Hinsicht deutlich von Klassifizierungs- und Regressionsmodellen unterscheiden, gibt Evaluate Model (Modell bewerten) auch eine andere Menge an Statistiken für Clusteringmodelle zurück.
Die für ein Clusteringmodell zurückgegebene Statistik beschreibt, wie viele Datenpunkte jedem Cluster zugeordnet wurden, wie groß die Trennung zwischen den Clustern ist und wie eng die Datenpunkte innerhalb jedes Clusters gebündelt sind.
Die Statistiken für das Clusteringmodell werden über das gesamte Dataset gemittelt, wobei clusterbezogene Statistiken in zusätzlichen Zeilen enthalten sind.
Die folgenden Metriken werden für die Auswertung von Clusteringmodellen herangezogen.
Die Werte in der Spalte Average Distance to Other Center (Durchschnittlicher Abstand zum anderen Zentrum) geben an, wie nahe jeder Punkt im Cluster im Durchschnitt an den Schwerpunkten aller anderen Cluster liegt.
Die Werte in der Spalte Average Distance to Cluster Center (Durchschnittlicher Abstand zum Clusterzentrum) stellen die Nähe aller Punkte in einem Cluster zum Schwerpunkt dieses Clusters dar.
Die Spalte Number of Points (Anzahl der Punkte) zeigt, wie viele Datenpunkte jedem Cluster zugewiesen wurden, sowie die Gesamtanzahl der Datenpunkte in jedem Cluster.
Wenn die Anzahl der den Clustern zugeordneten Datenpunkte geringer ist als die Gesamtanzahl der verfügbaren Datenpunkte, bedeutet dies, dass die Datenpunkte keinem Cluster zugeordnet werden konnten.
Die Werte in der Spalte Maximal Distance to Cluster Center (Maximaler Abstand zum Clusterzentrum) stellen die maximalen Abstände zwischen jedem Punkt und dem Schwerpunkt des Clusters des betreffenden Punkts dar.
Wenn dieser Wert hoch ist, kann dies bedeuten, dass der Cluster weit verstreut ist. Überprüfen Sie diese Statistik zusammen mit Average Distance to Cluster Center (Durchschnittlicher Abstand zum Clusterzentrum), um die Streuung des Clusters zu ermitteln.
Der Wert Combined Evaluation (Kombinierte Bewertung) am Ende jedes Ergebnisabschnitts listet die gemittelten Werte für die in diesem bestimmten Modell erstellten Cluster auf.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.