Bereitstellungen für mehrere Regionen für die Notfallwiederherstellung in Azure Logic Apps
Dieser Artikel enthält Anleitungen und Strategien zum Einrichten einer Bereitstellung für mehrere Regionen für Ihre Logik-App-Workflows in Azure Logic Apps. Eine Bereitstellung für mehrere Regionen hilft Ihnen beim Schutz von Daten, bei der schnellen Wiederherstellung nach Katastrophen und anderen Störfällen, bei der Wiederherstellung von Ressourcen, die von wichtigen Geschäftsfunktionen benötigt werden, und bei der Aufrechterhaltung der Geschäftskontinuität.
Weitere Informationen zu den Zuverlässigkeitsfeatures in Azure Logic Apps, einschließlich der intraregionalen Resilienz über Verfügbarkeitszonen, finden Sie unter Zuverlässigkeit in Azure Logic Apps.
Überlegungen
Logik-App-Workflows erleichtern das Integrieren und Orchestrieren von Daten zwischen Apps, Clouddiensten und lokalen Systemen, indem sie den zu schreibende Code reduzieren. Wenn Sie Redundanz für mehrere Regionen planen, stellen Sie sicher, dass Sie nicht nur Ihre Logik-Apps, sondern auch die Azure-Ressourcen berücksichtigen, die Sie mit Ihren Logik-Apps verwenden:
Verbindungen, die Sie aus Logik-Apps-Workflows für andere Apps, Dienste und Systeme erstellen. Weitere Informationen finden Sie weiter unten in diesem Thema unter Verbindungen mit Ressourcen.
Lokale Datengateways sind Azure-Ressourcen, die Sie in Ihren Logik-Apps erstellen und für den Zugriff auf Daten in lokalen Systemen verwenden. Jede Gatewayressource stellt eine separate Datengatewayinstallation auf einem lokalen Computer dar. Weitere Informationen finden Sie unter Lokale Datengateways weiter unten in diesem Thema.
Integrationskonten, in denen Sie die Artefakte definieren und speichern, die Logik-Apps für B2B-Unternehmensintegrationsszenarien (Business-to-Business) verwenden. Sie können beispielsweise regionsübergreifende Notfallwiederherstellung für Integrationskonten einrichten.
Weitere Informationen zur Zuverlässigkeit in Azure Logic Apps, einschließlich der intraregionalen Resilienz über Verfügbarkeitszonen und Bereitstellungen für mehrere Regionen, finden Sie unter Zuverlässigkeit in Azure Logic Apps.
Primäre und sekundäre Bereitstellung
Eine Bereitstellung für mehrere Regionen besteht aus einer primären und einer sekundären Logik-App. Die primäre Logik-App ist so konfiguriert, dass sie ein Failover auf die sekundäre Logik-App in einer anderen Region durchführt, in der auch Azure Logic Apps verfügbar sind. Auf diese Weise kann die sekundäre Datenbank die Aufgaben übernehmen, wenn die primäre Datenbank Verluste, Unterbrechungen oder Ausfälle erleidet. Diese Bereitstellungsstrategie erfordert, dass Ihre sekundäre Logik-App und abhängige Ressourcen in der sekundären Region bereits bereitgestellt wurden und bereit sind.
Hinweis
Wenn Ihre Logik-App auch mit B2B-Artefakten (z. B. Handelspartnern, Vereinbarungen, Schemas, Zuordnungen und Zertifikaten) arbeitet, die in einem Integrationskonto gespeichert sind, müssen sowohl Ihr Integrationskonto als auch Ihre Logik-Apps denselben Standort verwenden.
Wenn Sie bewährte DevOps-Praktiken befolgen, verwenden Sie bereits Bicep- oder Azure Resource Manager-Vorlagen, um Ihre Logik-Apps und deren abhängigen Ressourcen zu definieren und bereitzustellen. Mit Bicep- und Resource Manager-Vorlagen haben Sie die Möglichkeit, eine einzelne Bereitstellungsdefinition zu verwenden und dann die für die einzelnen Bereitstellungsziele zu verwendenden Konfigurationswerte mithilfe von Parameterdateien bereitzustellen. Diese Funktion bedeutet, dass Sie dieselbe Logik-App in verschiedenen Umgebungen bereitstellen können, z. B. für Entwicklung, Tests und Produktion. Sie können dieselbe Logik-App auch in verschiedenen Azure-Regionen bereitstellen. Dann werden Bereitstellungen für mehrere Regionen wie für Notfallwiederherstellungsstrategien unterstützt.
Damit das Failover erfolgreich ist, müssen Ihre Logik-Apps und Standorte die folgenden Anforderungen erfüllen:
Die sekundäre Logik-App-Instanz besitzt Zugriff auf dieselben Anwendungen, Dienste und Systeme wie die primäre Logik-App-Instanz.
Beide Logik-App-Instanzen besitzen den gleichen Hosttyp. Daher werden beide Instanzen in Regionen in globalen Azure Logic Apps mit mehreren Mandanten oder Regionen in Azure Logic Apps mit einem Mandanten bereitgestellt. Bewährte Methoden sowie weitere Informationen zur Verwendungen mehrerer Regionen für Geschäftskontinuität und Notfallwiederherstellung (BC/DR) finden Sie unter Regionenübergreifende Replikation in Azure: Geschäftskontinuität und Notfallwiederherstellung.
Beispiel: Mehrmandantenfähige Azure-Umgebung
In diesem Beispiel werden primäre und sekundäre Logik-App-Instanzen gezeigt, die in separaten Regionen in einer globalen mehrmandantenfähigen Azure-Umgebung bereitgestellt werden. Eine einzelne Resource Manager-Vorlage definiert sowohl die Logik-App-Instanzen als auch die abhängigen Ressourcen, die von diesen Logik-Apps benötigt werden. Separate Parameterdateien geben die Konfigurationswerte an, die für jeden Bereitstellungsort verwendet werden sollen:
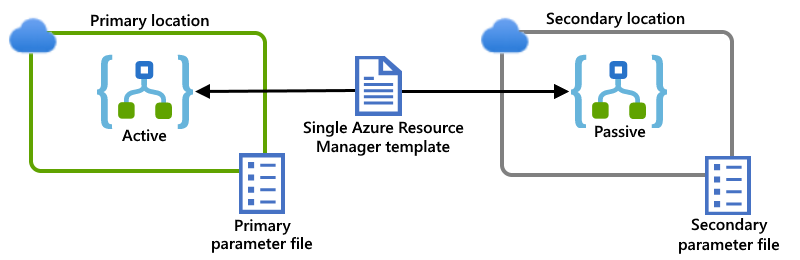
Verbindungen mit Ressourcen
Azure Logic Apps bietet Vorgänge für über 1.000 Connectors, die ihr Logik-App-Workflow für die Zusammenarbeit mit anderen Apps, Diensten, Systemen und anderen Ressourcen wie Azure Storage Konten, SQL Server Datenbanken, Geschäfts-, Schul- oder Uni-Konten usw. verwenden kann. Wenn Ihre Logik-App Zugriff auf diese Ressourcen benötigt, erstellen Sie Verbindungen, die den Zugriff auf diese Ressourcen authentifizieren. Jede Verbindung ist eine separate Azure-Ressource, die an einem bestimmten Standort vorhanden ist und nicht von Ressourcen an anderen Standorten verwendet werden kann.
Berücksichtigen Sie für Ihre Redundanzstrategie in mehreren Regionen die Standorte, an denen abhängige Ressourcen in Bezug auf Ihre Logik-App-Instanzen vorhanden sind:
Ihre primäre Instanz und abhängige Ressourcen sind an verschiedenen Standorten vorhanden. In diesem Fall kann die sekundäre Instanz eine Verbindung mit denselben abhängigen Ressourcen oder Endpunkten herstellen. Allerdings sollten Sie Verbindungen speziell für Ihre sekundäre Instanz erstellen. Wenn Ihr primärer Standort nicht mehr verfügbar ist, sind die Verbindungen des sekundären Standorts auf diese Weise nicht betroffen.
Angenommen, Ihre primäre Logik-App stellt eine Verbindung mit einem externen Dienst wie Salesforce her. Normalerweise sind die Verfügbarkeit und der Speicherort des externen Diensts unabhängig von der Verfügbarkeit ihrer Logik-App. In diesem Fall kann die sekundäre Instanz eine Verbindung mit dem gleichen Dienst herstellen, sollte jedoch über eine eigene Verbindung in Ihrer sekundären Region verfügen.
Ihre primäre Instanz und abhängige Ressourcen sind am gleichen Standort vorhanden. In diesem Fall sollten abhängige Ressourcen Sicherungen oder replizierte Versionen an einem anderen Standort aufweisen, damit die sekundäre Instanz weiterhin auf diese Ressourcen zugreifen kann.
Angenommen, Ihre primäre Logik-App stellt eine Verbindung mit einem Dienst her, der sich am selben Standort oder in der gleichen Region befindet, z. B. mit Azure SQL-Datenbank. Wenn diese gesamte Region nicht mehr verfügbar ist, ist der Azure SQL-Datenbank-Dienst in dieser Region wahrscheinlich auch nicht verfügbar. In diesem Fall möchten Sie, dass Ihre sekundäre Instanz eine replizierte oder Sicherungsdatenbank in der sekundären Region zusammen mit einer separaten Verbindung mit dieser Datenbank verwendet.
Lokale Datengateways
Wenn Ihre Logik-App in einer mehrmandantenfähigen Azure-Umgebung ausgeführt wird und Zugriff auf lokale Ressourcen wie SQL Server-Datenbanken benötigt, müssen Sie das lokale Datengateway auf einem lokalen Computer installieren. Anschließend können Sie im Azure-Portal eine Datengatewayressource erstellen, damit Ihre Logik-App das Gateway verwenden kann, wenn Sie eine Verbindung mit der Ressource herstellen.
Die Datengatewayressource ist einem Standort oder einer Azure-Region zugeordnet, genau wie Ihre Logik-App-Ressource. Stellen Sie in Ihrer Redundanzstrategie für mehrere Regionen sicher, dass das Datengateway für die Verwendung durch Ihre Logik-App weiterhin verfügbar ist. Sie können Hochverfügbarkeit für Ihr Gateway aktivieren, wenn Sie über mehrere Gatewayinstallationen verfügen.
Aktiv-Aktiv- vs. Aktive-Passiv-Rollen
Sie können Ihre primären und sekundären Standorte so einrichten, dass Ihre Logik-App-Instanzen an diesen Standorten folgende Rollen übernehmen können:
| Primäre sekundäre Rolle | BESCHREIBUNG |
|---|---|
| Aktiv/Aktiv | Die primären und sekundären Logik-App-Instanzen an beiden Standorten verarbeiten Anforderungen aktiv, indem sie eines der folgenden Muster verwenden: - Lastenausgleich: Beide Instanzen können an einem Endpunkt lauschen und bei Bedarf einen Lastenausgleich für den Datenverkehr für jede Instanz ausführen. - Konkurrierende Consumer: Beide Instanzen können als konkurrierende Consumer fungieren, damit die Instanzen um Nachrichten aus einer Warteschlange konkurrieren. Wenn eine Instanz ausfällt, übernimmt die andere Instanz die Workload. |
| Aktiv/Passiv | Die primäre Logik-App-Instanz verarbeitet die gesamte Workload aktiv, während die sekundäre Instanz passiv (deaktiviert oder inaktiv) ist. Die sekundäre Instanz wartet auf ein Signal, dass das primäre Instanz nicht verfügbar ist oder aufgrund einer Unterbrechung oder eines Fehlers nicht funktioniert und übernimmt die Workload als aktive Instanz. |
| Kombination | Einige Logik-Apps nehmen eine Aktiv/Aktiv-Rolle ein, während andere Logik-Apps eine Aktiv/Passiv-Rolle spielen. |
Aktiv/Aktiv-Beispiele
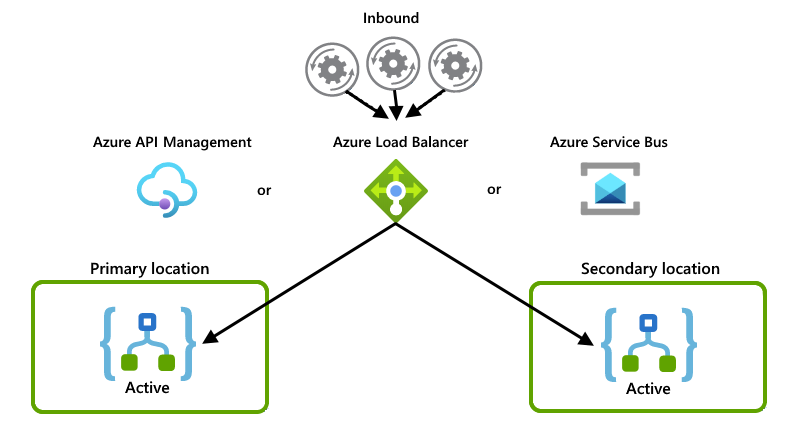
Diese Beispiele zeigen das Aktiv/Aktiv-Setup, bei dem beide Logik-App-Instanzen aktiv Anforderungen oder Nachrichten verarbeiten. Einige andere Systeme oder Dienste verteilen die Anforderungen oder Nachrichten zwischen Instanzen, indem z. B. eine der folgenden Optionen verwendet wird:
Ein „physischer“ Lastenausgleich, z. B. ein Hardwaregerät, das Datenverkehr weiterleitet
Ein „weicher“ Lastenausgleich wie Azure Load Balancer oder Azure API Management. Mit API Management können Sie Richtlinien angeben, die bestimmen, wie der Lastenausgleich für eingehenden Datenverkehr durchgeführt wird. Oder Sie können einen Dienst verwenden, der Zustandsnachverfolgung unterstützt, z. B. Azure Service Bus.
Obwohl in diesem Beispiel hauptsächlich Azure Load Balancer angezeigt wird, können Sie die Option verwenden, die den Anforderungen Ihres Szenarios am besten entspricht:
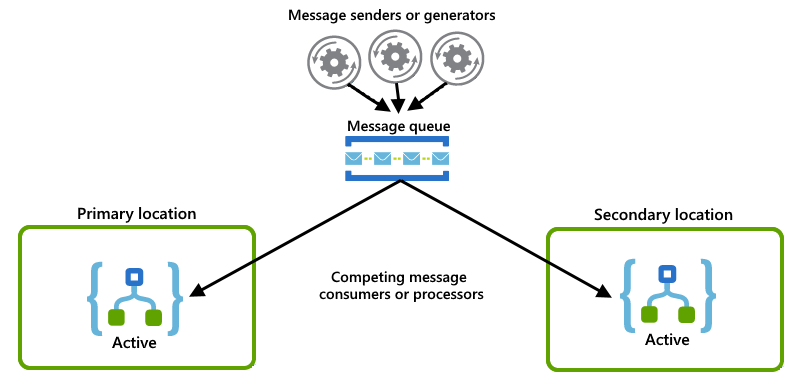
Jede Logik-App-Instanz fungiert als Consumer, und beide Instanzen konkurrieren um Nachrichten aus einer Warteschlange:
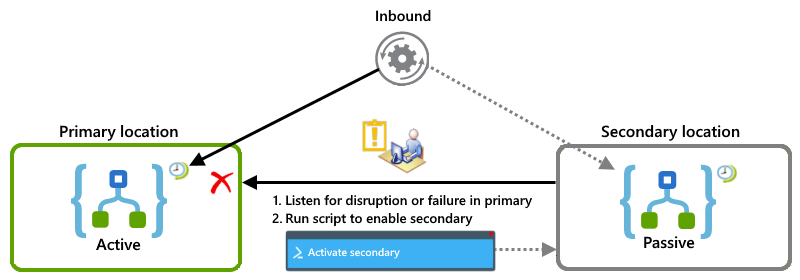
Aktiv/Passiv-Beispiele
Dieses Beispiel zeigt das Aktiv/Passiv-Setup, bei dem die primäre Logik-App-Instanz an einem Standort aktiv ist, während die sekundäre Instanz an einem anderen Standort inaktiv bleibt. Wenn bei der primären Instanz eine Unterbrechung oder ein Fehler auftritt, kann ein Operator ein Skript ausführen, mit dem die sekundäre Instanz für die Übernahme der Workload aktiviert wird.
Kombination aus Aktiv/Aktiv und Aktiv/Passiv
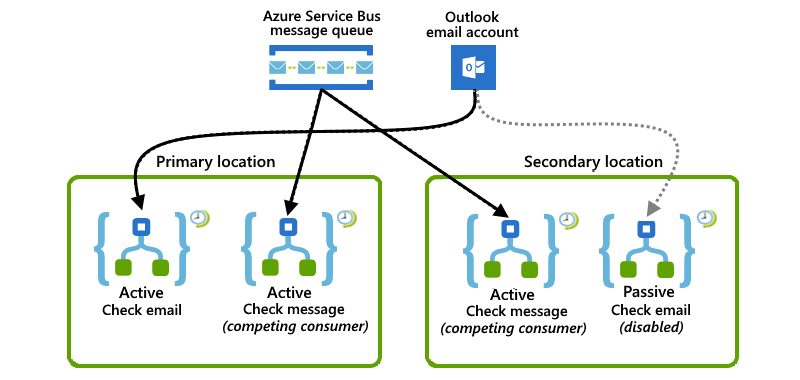
Dieses Beispiel zeigt ein kombiniertes Setup, bei dem der primäre Standort über beide aktiven Logik-App-Instanzen verfügt, während der sekundäre Speicherort Aktiv/Passiv-Logik-App-Instanzen aufweist. Wenn am primären Standort eine Unterbrechung oder ein Fehler auftritt, kann die aktive Logik-App am sekundären Standort, der bereits eine partielle Workload verarbeitet, die gesamte Workload übernehmen.
Am primären Standort lauscht eine aktive Logik-App auf eine Azure Service Bus-Warteschlange für Nachrichten, während eine andere aktive Logik-App auf E-Mails prüft, indem ein Abfragetrigger von Office 365 Outlook verwendet wird.
Am sekundären Standort arbeitet eine aktive Logik-App mit der Logik-App am primären Speicherort zusammen, indem sie auf Nachrichten aus derselben Service Bus-Warteschlange lauscht und um diese konkurriert. In der Zwischenzeit wartet eine passive inaktive Logik-App im Standbymodus, um auf E-Mails zu prüfen, wenn der primäre Standort nicht mehr verfügbar ist. Sie ist aber deaktiviert, um das erneute Lesen von E-Mails zu vermeiden.
Status und Verlauf der Logik-App
Wenn Ihre Logik-App ausgelöst und ihre Ausführung gestartet wird, wird der Status der App am gleichen Standort gespeichert, an dem die App gestartet wurde, und kann nicht an einen anderen Standort übertragen werden. Wenn ein Fehler oder eine Unterbrechung auftritt, werden alle aktuell ausgeführten Workflowinstanzen abgebrochen. Wenn ein primärer und ein sekundärer Standort eingerichtet ist, werden neue Workflowinstanzen am sekundären Standort gestartet.
Verringern abgebrochener aktueller Instanzen
Um die Anzahl der abgebrochenen Workflowinstanzen zu minimieren, können Sie aus verschiedenen Nachrichtenmustern auswählen, die Sie implementieren können, beispielsweise:
-
Dieses Unternehmensnachrichtenmuster unterteilt einen Geschäftsprozess in kleinere Phasen. Für jede Phase richten Sie eine Logik-App ein, die die Workload für diese Phase verarbeitet. Um miteinander zu kommunizieren, verwenden Ihre Logik-Apps ein asynchrones Messagingprotokoll, z. B. Azure Service Bus-Warteschlangen oder -Themen. Wenn Sie einen Prozess in kleinere Phasen aufteilen, verringern Sie die Anzahl von Geschäftsprozessen, die möglicherweise aufgrund einer fehlerhaften Logik-App-Instanz nicht verarbeitet werden. Weitere allgemeine Informationen zu diesem Muster finden Sie unter Unternehmensintegrationsmuster: Routing Slip.
Dieses Beispiel zeigt ein Routing Slip-Muster, bei dem jede Logik-App eine Phase darstellt und eine Service Bus-Warteschlange verwendet, um mit der nächsten Logik-App im Prozess zu kommunizieren.
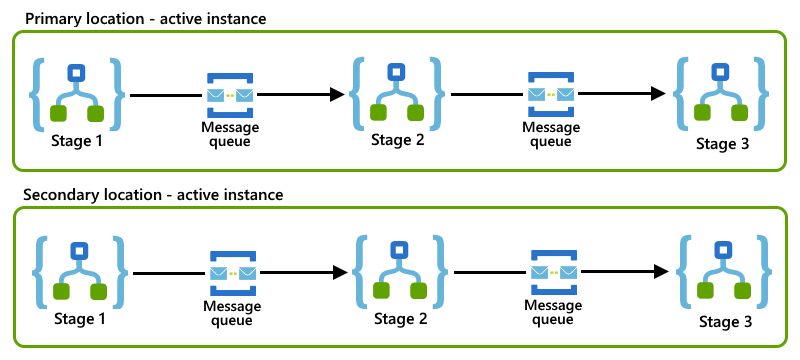
Wenn sowohl primäre als auch sekundäre Logik-App-Instanzen das gleiche Routing Slip-Muster an ihren Standorten verwenden, können Sie das Muster für konkurrierende Consumer implementieren, indem Sie Aktiv/Aktiv-Rollen für diese Instanzen einrichten.
Zugriff auf Trigger und Ausführungsverlauf
Um weitere Informationen zu den bisherigen Workflowausführungen ihrer Logik-App zu erhalten, können Sie den Trigger und Ausführungsverlauf der App überprüfen. Der Ausführungsverlauf einer Logik-App wird am gleichen Standort oder in der gleichen Region gespeichert, in der die Logik-App ausgeführt wurde. Dies bedeutet, dass Sie diesen Verlauf nicht zu einem anderen Standort migrieren können. Wenn für die primäre Instanz ein Failover auf eine sekundäre Instanz durchgeführt wird, können Sie nur auf den Trigger und den Ausführungsverlauf jeder Instanz an den jeweiligen Standorten zugreifen, an denen diese Instanzen ausgeführt wurden. Sie können jedoch ortsunabhängige Informationen zum Verlauf ihrer Logik-App erhalten, indem Sie Ihre Logik-Apps so einrichten, dass Diagnoseereignisse an einen Azure Log Analytics-Arbeitsbereich gesendet werden. Anschließend können Sie die Integrität und den Verlauf in Logik-Apps überprüfen, die an mehreren Standorten ausgeführt werden.
Hinweise zum Triggertyp
Der Triggertyp, den Sie in Ihren Logik-Apps verwenden, bestimmt Ihre Optionen, wie Sie Logik-Apps an Standorten in einer Notfallwiederherstellungsstrategie einrichten können. Die folgenden verfügbaren Triggertypen können in Logik-App-Workflows verwendet werden:
Recurrence-Trigger
Der Wiederholungstrigger ist unabhängig von einem bestimmten Dienst oder Endpunkt und wird ausschließlich basierend auf einem bestimmten Zeitplan und keinen anderen Kriterien ausgelöst, z. B.:
- Eine angegebene Häufigkeit und ein festes Intervall (z. B. alle 10 Minuten)
- Ein erweiterter Zeitplan, z. B. am letzten Montag jeden Monats um 17:00 Uhr
Wenn Ihre Logik-App mit einem Wiederholungstrigger gestartet wird, müssen Sie Ihre primären und sekundären Logik-App-Instanzen mit den Aktiv/Passiv-Rollen einrichten. Um den RTO.Wert (Recovery Time Objective) zu verringern, der sich auf die Zieldauer für die Wiederherstellung eines Geschäftsprozesses nach einer Unterbrechung oder einem Notfall bezieht, können Sie Ihre Logik-App-Instanzen mit einer Kombination aus Aktiv/Passiv-Rollen und Passiv/Aktiv-Rollen einrichten. In diesem Setup teilen Sie den Zeitplan zwischen Standorten auf.
Angenommen, Sie verfügen über eine Logik-App, die alle 10 Minuten ausgeführt werden muss. Sie können Ihre Logik-Apps und Standorte so einrichten, dass der sekundäre Standort die Aufgaben übernehmen kann, wenn der primäre Standort nicht mehr verfügbar ist:
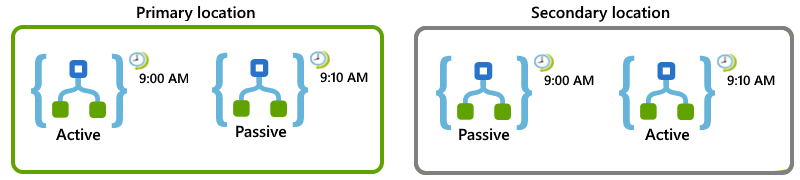
Richten Sie am primären Standort Aktiv/Passiv-Rollen für diese Logik-Apps ein:
Legen Sie für die aktive aktivierte Logik-App fest, dass der Wiederholungstrigger zur vollen Stunde gestartet und alle 20 Minuten wiederholt wird (z. B um 9:00 Uhr, 9:20 Uhr usw.).
Legen Sie für die passive deaktivierte Logik-App den Wiederholungstrigger auf den gleichen Zeitplan fest, starten Sie aber 10 Minuten nach der vollen Stunde mit Wiederholungen alle 20 Minuten (z. B um 9:10 Uhr, 9:30 Uhr usw.).
Richten Sie am sekundären Standort Passiv/Aktiv für diese Logik-Apps ein:
Legen Sie für die passive deaktivierte Logik-App den Wiederholungstrigger auf denselben Zeitplan wie für die aktive Logik-App am primären Standort fest, der zur vollen Stunde beginnt und alle 20 Minuten wiederholt wird, z. B. um 9:00 Uhr, 9:10 Uhr usw.
Legen Sie für die aktive aktivierte Logik-App den Wiederholungstrigger auf denselben Zeitplan wie für die passive Logik-App am primären Standort fest, der 10 Minuten nach der vollen Stunde gestartet und alle 20 Minuten wiederholt wird, z. B. um 9:10 Uhr, 9:20 Uhr usw.
Wenn nun ein Störereignis am primären Standort auftritt, aktivieren Sie die passive Logik-App am alternativen Standort. Wenn das Auffinden des Fehlers eine Weile dauert, schränkt dieses Setup die Anzahl der verpassten Wiederholungen während dieser Verzögerung ein.
Abfragetrigger
Um regelmäßig zu überprüfen, ob neue Daten für die Verarbeitung von einem bestimmten Dienst oder Endpunkt verfügbar sind, kann Ihre Logik-App einen Abfragetrigger verwenden, der den Dienst oder den Endpunkt auf der Grundlage eines festgelegten Wiederholungszeitplans wiederholt aufruft. Die Daten, die der Dienst oder Endpunkt bereitstellt, können einen der folgenden Typen aufweisen:
- Statische Daten, die Daten beschreiben, die immer zum Lesen verfügbar sind.
- Flüchtige Daten, die Daten beschreiben, die nach dem Lesen nicht mehr verfügbar sind.
Um das wiederholte Lesen der gleichen Daten zu vermeiden, muss sich Ihre Logik-App merken, welche Daten zuvor durch Beibehalten des Zustands entweder auf der Clientseite oder auf dem Server, vom Dienst oder auf der Systemseite gelesen wurden.
Logik-Apps, die mit dem clientseitigen Status arbeiten, verwenden Trigger, die den Zustand beibehalten können.
Beispielsweise erfordert ein Trigger, der eine neue Nachricht aus einem E-Mail-Posteingang liest, dass der Trigger sich die zuletzt gelesene Nachricht merken kann. Auf diese Weise startet der Trigger die Logik-App nur dann, wenn die nächste ungelesene Nachricht eingeht.
Logik-Apps, die mit dem server-, dienst- oder systemseitigen Status arbeiten, verwenden Eigenschaftswerte oder Einstellungen auf der Server-, Dienst- oder Systemseite.
Beispielsweise erfordert ein abfragebasierter Trigger, der eine Zeile aus einer Datenbank liest, dass die Zeile eine
isRead-Spalte aufweist, die aufFALSEfestgelegt ist. Jedes Mal, wenn der Trigger eine Zeile liest, aktualisiert die Logik-App diese Zeile, indem dieisRead-Spalte vonFALSEinTRUEgeändert wird.Dieser serverseitige Ansatz funktioniert ähnlich für Service Bus-Warteschlangen oder -Themen, in denen eine Warteschlangensemantik vorhanden ist, in der ein Trigger eine Nachricht lesen und sperren kann, während die Logik-App die Nachricht verarbeitet. Wenn die Logik-App die Verarbeitung beendet, löscht der Trigger die Nachricht aus der Warteschlange oder dem Thema.
Aus der Perspektive der Notfallwiederherstellung sollten Sie beim Einrichten der primären und sekundären Instanzen Ihrer Logik-App sicherstellen, dass Sie diese Verhaltensweisen berücksichtigen, je nachdem, ob Ihre Logik-App den Status auf der Client- oder auf der Serverseite nachverfolgt:
Bei einer Logik-App, die mit dem clientseitigen Status arbeitet, stellen Sie sicher, dass Ihre Logik-App die gleiche Nachricht nicht mehr als ein Mal liest. Nur ein Standort kann zu einem bestimmten Zeitpunkt über eine aktive Logik-App-Instanz verfügen. Stellen Sie sicher, dass die Logik-App-Instanz am alternativen Speicherort inaktiv oder deaktiviert ist, bis die primäre Instanz ein Failover zum alternativen Standort durchführt.
Beispielsweise behält der Office 365 Outlook-Trigger den clientseitigen Status bei und verfolgt den Zeitstempel für die zuletzt gelesene E-Mail nach, um das Lesen eines Duplikats zu vermeiden.
Für eine Logik-App, die mit dem serverseitigen Status arbeitet, können Sie Ihre Logik-App-Instanzen so einrichten, dass sie entweder Aktiv/Aktiv-Rollen ausüben, in denen sie als konkurrierende Consumer fungieren, oder Aktiv/Passiv-Rollen spielen, wobei die alternative Instanz wartet, bis die primäre Instanz ein Failover auf den alternativen Standort ausführt.
Beispielsweise wird durch das Lesen aus einer Nachrichtenwarteschlange (z. B. einer Azure Service Bus-Warteschlange) der serverseitige Zustand verwendet, da der Warteschlangendienst Sperren für Nachrichten verwaltet, um zu verhindern, dass andere Clients dieselben Nachrichten lesen.
Hinweis
Wenn Ihre Logik-App Nachrichten in einer bestimmten Reihenfolge lesen muss (z. B. aus einer Service Bus-Warteschlange), können Sie das Muster der konkurrierenden Consumer verwenden. Dies gilt aber nur in Kombination mit Service Bus-Sitzungen und wird auch als sequenzielles Konvoimuster bezeichnet. Andernfalls müssen Sie Ihre Logik-App-Instanzen mit den Aktiv/Passiv-Rollen einrichten.
Anforderungstrigger
Der Anforderungstrigger bewirkt, dass Ihre Logik-App von anderen Apps, Diensten und Systemen aufgerufen werden kann. Er wird in der Regel verwendet, um die folgenden Funktionen bereitzustellen:
Eine direkte REST-API für Ihre Logik-App, die von anderen Komponenten aufgerufen werden kann.
Verwenden Sie den Anforderungstrigger beispielsweise, um Ihre Logik-App zu starten, damit andere Logik-Apps den Trigger mithilfe der Aktion Workflow aufrufen: Logic Apps aufrufen können.
Einen Webhook oder Rückrufmechanismus für Ihre Logik-App.
Eine Möglichkeit, Benutzervorgänge oder Routinen manuell auszuführen, um Ihre Logik-App aufzurufen, z. B. mithilfe eines PowerShell-Skripts, das eine bestimmte Aufgabe ausführt.
Aus Sicht der Notfallwiederherstellung ist der Anforderungstrigger ein passiver Empfänger, da die Logik-App keine Arbeiten durchführt und wartet, bis ein anderer Dienst oder ein anderes System den Triggern explizit aufruft. Als passiven Endpunkt können Sie Ihre primären und sekundären Instanzen auf folgende Weise einrichten:
Aktiv/Aktiv: Beide Instanzen verarbeiten Anforderungen oder Aufrufe aktiv. Der Aufrufer oder Router gleicht die Datenverkehrslast zwischen diesen Instanzen aus oder verteilt sie.
Aktiv/Passiv: Nur die primäre Instanz ist aktiv und verarbeitet alle Aufgaben, während die sekundäre Instanz wartet, bis die primäre Instanz unterbrochen wird oder ausfällt. Der Aufrufer oder Router bestimmt, wann die sekundäre Instanz aufgerufen werden soll.
Als empfohlene Architektur können Sie Azure API Management als Proxy für die Logik-Apps verwenden, die Anforderungstrigger verwenden. API Management bietet integrierte regionsübergreifende Resilienz und die Möglichkeit, Datenverkehr über mehrere Endpunkte weiterzuleiten.
Webhooktrigger
Ein Webhooktrigger bietet die Möglichkeit, dass Ihre Logik-App einen Dienst abonnieren kann, indem sie eine Rückruf-URL an diesen Dienst übergibt. Ihre Logik-App kann dann lauschen und warten, bis ein bestimmtes Ereignis an diesem Dienstendpunkt auftritt. Wenn das Ereignis eintritt, ruft der Dienst den Webhooktrigger mit der Rückruf-URL auf, der dann die Logik-App ausführt. Wenn diese Option aktiviert ist, abonniert der Webhooktrigger den Dienst. Wenn diese Option deaktiviert ist, kündigt der Webhooktrigger das Abonnement des Diensts.
Richten Sie unter dem Aspekt der Notfallwiederherstellung primäre und sekundäre Instanzen ein, die Webhooktrigger verwenden, um aktive/passive Rollen zu spielen, da nur eine Instanz Ereignisse oder Nachrichten vom abonnierten Endpunkt empfangen soll.
Überprüfen der Integrität der primären Instanz
Damit Ihre Failoverstrategie für mehrere Regionen funktioniert, benötigt Ihre Lösung Möglichkeiten zum Ausführen dieser Aufgaben:
- Überprüfen der Verfügbarkeit der primären Instanz
- Überwachen der Integrität der primären Instanz
- Aktivieren der sekundären Instanz
In diesem Abschnitt wird eine Lösung beschrieben, die Sie unverändert oder auch als Grundlage für Ihren eigenen Entwurf verwenden können. Dies ist eine visuelle Übersicht auf hohem Niveau für diese Lösung:
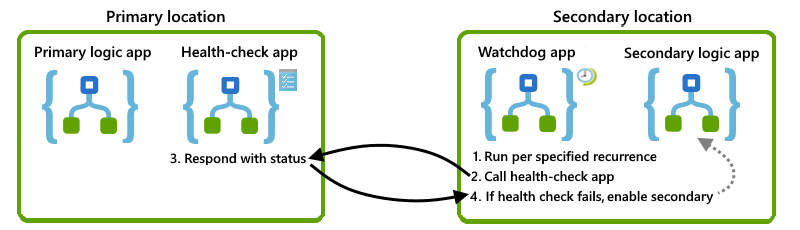
Überprüfen der Verfügbarkeit der primären Instanz
Um zu ermitteln, ob die primäre Instanz verfügbar ist, ausgeführt wird und funktionsfähig ist, können Sie eine Logik-App für die Integritätsüberprüfung erstellen, die sich am gleichen Standort wie die primäre Instanz befindet. Sie können diese Integritätsüberprüfungs-App dann von einem anderen Standort aufrufen. Wenn die Integritätsüberprüfungs-App erfolgreich antwortet, ist die zugrunde liegende Infrastruktur für den Azure Logic Apps-Dienst in dieser Region verfügbar und arbeitet ordnungsgemäß. Wenn die Integritätsüberprüfungs-App nicht antwortet, können Sie davon ausgehen, dass der Standort nicht mehr fehlerfrei ist.
Erstellen Sie für diese Aufgabe eine grundlegende Integritätsüberprüfungs-Logik-App, die die folgenden Aufgaben ausführt:
Empfangen eines Aufrufs von der Watchdog-App mithilfe des Anforderungstriggers.
Antworten mit einem Status, der angibt, ob die überprüfte Logik-App noch funktioniert, indem die Antwortaktion verwendet wird.
Wichtig
Die Integritätsüberprüfungs-Logik-App muss eine Antwortaktion verwenden, damit die App synchron und nicht asynchron antwortet.
Um weiter zu bestimmen, ob der primäre Standort fehlerfrei ist, können Sie optional die Integrität aller anderen Dienste berücksichtigen, die mit der Ziel-Logik-App an diesem Standort interagieren. Erweitern Sie einfach die Integritätsüberprüfungs-Logik-App, um die Integrität auch für diese anderen Dienste zu bewerten.
Erstellen einer Watchdog-Logik-App
Um die Integrität der primären Instanz zu überwachen und die Integritätsüberprüfungs-Logik-App aufzurufen, erstellen Sie eine „Watchdog“-Logik-App an einem alternativen Standort. Beispielsweise können Sie die Watchdog-Logik-App so einrichten, dass die Watchdog-App eine Warnung an Ihr Betriebsteam senden kann, wenn der Aufruf der Integritätsüberprüfungslogik fehlschlägt, damit dieses den Fehler untersuchen und ermitteln kann, warum die primäre Instanz nicht antwortet.
Wichtig
Stellen Sie sicher, dass sich Ihre Watchdog-Logik-App an einem Standort befindet, der sich vom primären Standort unterscheidet. Wenn Azure Logic Apps am primären Standort Probleme hat, wird Ihre Watchdog-Logik-App möglicherweise nicht ausgeführt.
Erstellen Sie für diese Aufgabe am sekundären Standort eine Watchdog-Logik-App, die die folgenden Aufgaben ausführt:
Ausführung auf der Grundlage einer festen oder geplanten Wiederholung mithilfe des Wiederholungstriggers.
Sie können für die Wiederholung einen Wert festlegen, der unter der Toleranzebene für den RTO-Wert (Recovery Time Objective) liegt.
Rufen Sie die Integritätsüberprüfung des Logik-App-Workflows am primären Standort mithilfe der HTTP-Aktion auf.
Sie können auch eine komplexere Watchdog-Logik-App erstellen, die nach einer Reihe von Fehlern eine andere Logik-App aufruft, die automatisch den Wechsel zum sekundären Standort verarbeitet, wenn der primäre Standort fehlschlägt.
Aktivieren der sekundären Instanz
Zum automatischen Aktivieren der sekundären Instanz können Sie eine Logik-App erstellen, die die Management API aufruft, z. B. den Azure Resource Manager-Connector, um die entsprechenden Logik-Apps am sekundären Standort zu aktivieren. Nachdem eine bestimmte Anzahl von Fehlern aufgetreten ist, können Sie Ihre Watchdog-App erweitern, um diese Aktivierungs-Logik-App aufzurufen.
Erfassen von Diagnosedaten
Sie können Protokollierung für Ihre Logik-App-Ausführungen einrichten und die sich ergebenden Diagnosedaten an Dienste wie Azure Storage, Azure Event Hubs und Azure Log Analytics senden, um sie weiter zu verarbeiten und zu untersuchen.
Wenn Sie diese Daten mit Azure Log Analytics verwenden möchten, können Sie die Daten für die primären und sekundären Standorte zur Verfügung stellen, indem Sie die Diagnoseeinstellungen Ihrer Logik-App einrichten und die Daten an mehrere Log Analytics-Arbeitsbereiche senden. Weitere Informationen finden Sie unter Einrichten von Azure Monitor-Protokollen und Sammeln von Diagnosedaten für Azure Logic Apps.
Wenn Sie die Daten an Azure Storage oder Azure Event Hubs senden möchten, können Sie die Daten für die primären und sekundären Standorte verfügbar machen, indem Sie Georedundanz einrichten. Weitere Informationen und Beispiele finden Sie in diesen Artikeln:
Nächste Schritte
- Entwerfen zuverlässiger Azure-Anwendungen
- Checkliste für Resilienz für bestimmte Azure-Dienste
- Datenverwaltung für Resilienz in Azure
- Sicherung und Notfallwiederherstellung von Azure-Anwendungen
- Wiederherstellung nach einer regionsweiten Dienstunterbrechung
- Vereinbarungen zum Servicelevel (SLAs) für Azure-Dienste