Konfigurieren von Brokereinstellungen für Hochverfügbarkeit, Skalierung und Speicherauslastung
Die Broker-Ressource ist die Hauptressource, die die allgemeinen Einstellungen für MQTT-Broker definiert. Sie bestimmt auch die Anzahl und den Typ der Pods, die die Broker-Konfiguration ausführen, z. B. die Front-Ends und die Back-Ends. Sie können auch die Brokerressource verwenden, um ihr Speicherprofil zu konfigurieren. In den Broker sind Selbstreparaturmechanismen integriert, und er kann häufig automatisch nach Komponentenausfällen wiederhergestellt werden. Beispiel: Ein Knoten fällt in einem für Hochverfügbarkeit konfigurierten Kubernetes-Cluster aus.
Sie können den MQTT-Broker horizontal skalieren, indem Sie weitere Front-End-Replikate und Back-End-Partitionen hinzufügen. Die Front-End-Replikate sind für die Annahme von MQTT-Verbindungen von Clients und deren Weiterleitung an die Back-End-Partitionen zuständig. Die Back-End-Partitionen sind für das Speichern und Übermitteln von Nachrichten an die Clients verantwortlich. Die Front-End-Pods verteilen den Datenverkehr auf die Back-End-Pods, und der Back-End-Redundanzfaktor bestimmt die Anzahl der Datenkopien, um die Resilienz gegen Knotenausfälle im Cluster zu gewährleisten.
Eine Liste der verfügbaren Einstellungen finden Sie in der API-Referenz zum Broker.
Konfigurieren von Skalierungseinstellungen
Wichtig
Diese Einstellung erfordert das Ändern der Brokerressource und kann nur bei der erstmaligen Bereitstellung mithilfe der Azure CLI oder des Azure-Portals konfiguriert werden. Eine neue Bereitstellung ist erforderlich, wenn Änderungen an der Broker-Konfiguration erforderlich sind. Weitere Informationen finden Sie unter Anpassen des Standardbrokers.
Um die Skalierungseinstellungen des MQTT-Brokers zu konfigurieren, geben Sie die Kardinalitätsfelder in der Spezifikation der Broker-Ressource während der Azure IoT Einsatz-Bereitstellung an.
Kardinalität bei der automatischen Bereitstellung
Um die anfängliche Kardinalität während der Bereitstellung automatisch zu ermitteln, lassen Sie das Kardinalitätsfeld in der Broker-Ressource leer.
Die automatische Kardinalität wird noch nicht unterstützt, wenn Sie Azure IoT Einsatz über das Azure-Portal bereitstellen. Sie können den Clusterbereitstellungsmodus jedoch manuell als Einzelner Knoten oder Mehrere Knoten angeben. Weitere Informationen finden Sie unter Bereitstellen von Azure IoT-Vorgängen.
Der Operator für den MQTT-Broker stellt die entsprechende Anzahl von Pods basierend auf der Anzahl der Knoten automatisch bereit, die zur Bereitstellungszeit verfügbar sind. Dies ist nützlich für Nichtproduktionsszenarien, in denen Sie keine Hochverfügbarkeit oder Skalierung benötigen.
Dies ist jedoch keine automatische Skalierung. Der Operator skaliert die Anzahl der Pods basierend auf der Last nicht automatisch. Der Operator bestimmt nur die anfängliche Anzahl von Pods, die basierend auf der Clusterhardware bereitgestellt werden sollen. Wie oben erwähnt, kann die Kardinalität nur bei der erstmaligen Bereitstellung festgelegt werden, Wenn die Kardinalitätseinstellungen geändert werden müssen, ist eine neue Bereitstellung erforderlich.
Direktes Konfigurieren der Kardinalität
Um die Kardinalitätseinstellungen direkt zu konfigurieren, geben Sie die einzelnen Kardinalitätsfelder an.
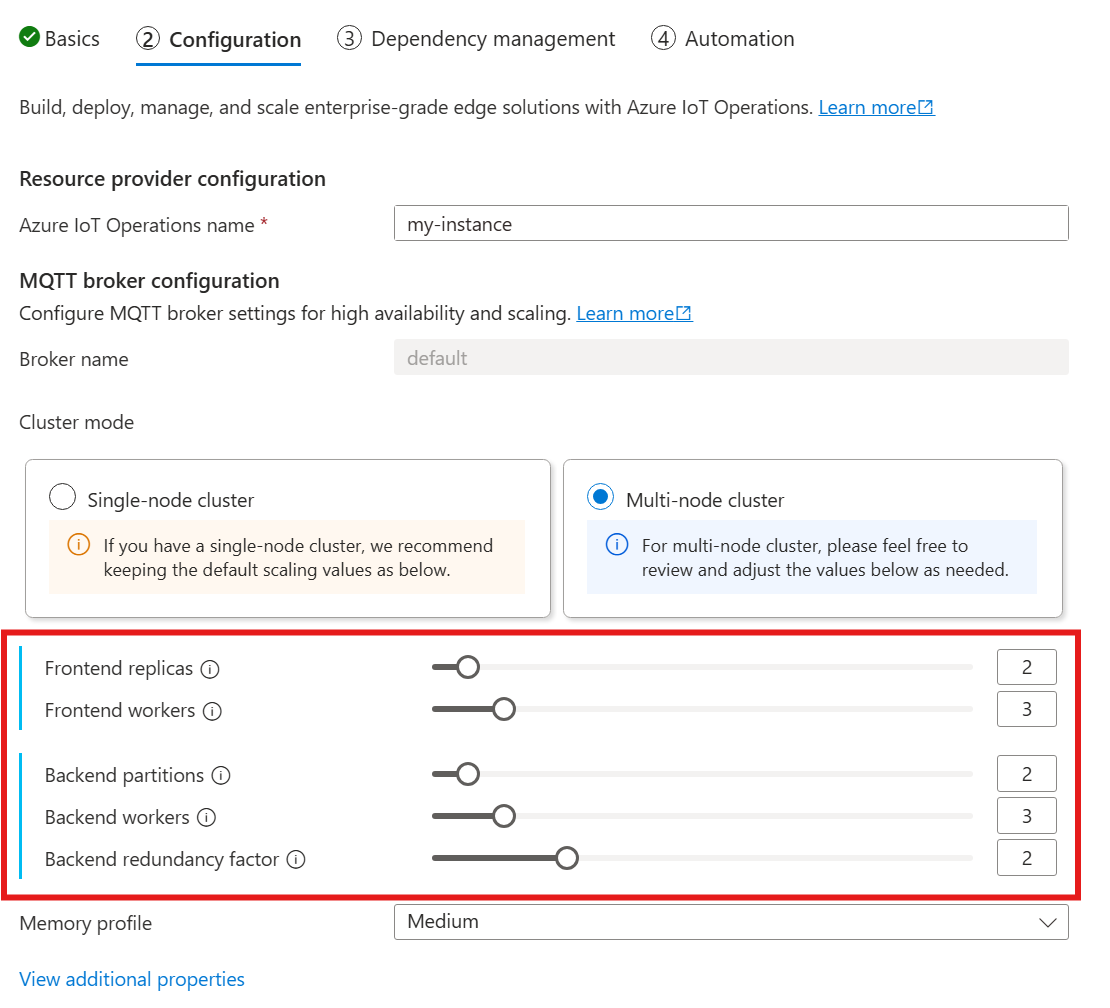
Wenn Sie den folgenden Leitfaden zum Bereitstellen von Azure IoT Einsatz befolgen, schauen Sie im Abschnitt Konfiguration unter MQTT-Brokerkonfiguration nach. Hier können Sie die Anzahl der Front-End-Replikate, Back-End-Partitionen und Back-End-Worker angeben.
Grundlegendes zur Kardinalität
Kardinalität steht für die Anzahl von Instanzen einer bestimmten Entität in einer Gruppe. Im Kontext des MQTT-Brokers bezieht sich die Kardinalität auf die Anzahl der Front-End-Replikate, Back-End-Partitionen und Back-End-Worker, die bereitgestellt werden sollen. Die Kardinalitätseinstellungen werden verwendet, um den Broker horizontal zu skalieren und Hochverfügbarkeit zu verbessern, wenn Pod- oder Knotenfehler auftreten.
Das Kardinalitätsfeld ist ein geschachteltes Feld mit Unterfeldern für Front-End und Back-End-Kette. Jedes dieser Unterfelder verfügt über eigene Einstellungen.
Front-End
Im Front-End-Unterfeld legen Sie die Einstellungen für die Front-End-Pods fest. Die beiden Haupteinstellungen sind:
Replikate: Die Anzahl der bereitzustellenden Front-End-Replikate (Pods) Das Erhöhen der Anzahl der Front-End-Replikate bietet Hochverfügbarkeit, falls einer der Front-End-Pods ausfüllt.
Worker: Die Anzahl der logischen Front-End-Worker pro Replikat Jeder Worker kann höchstens bis zu einem CPU-Kern verbrauchen.
Back-End-Kette
Das Unterfeld der Back-End-Kette definiert die Einstellungen für die Back-End-Partitionen. Die drei Haupteinstellungen sind:
Partitionen: Die Anzahl der bereitzustellenden Partitionen. Durch einen Prozess namens Sharding ist jede Partition für einen Teil der Nachrichten verantwortlich, getrennt nach Themen-ID und Sitzungs-ID. Die Front-End-Pods verteilen den Nachrichtendatenverkehr auf die Partitionen. Durch das Erhöhen der Anzahl von Partitionen erhöht sich auch die Anzahl der Nachrichten, die der Broker verarbeiten kann.
Redundanzfaktor: Die Anzahl der Back-End-Replikate (Pods), die pro Partition bereitgestellt werden sollen Durch das Erhöhen des Redundanzfaktors erhöht sich die Anzahl der Datenkopien, um Resilienz gegenüber Knotenfehlern im Cluster zu ermöglichen.
Worker: Die Anzahl der bereitzustellenden Worker pro Back-End-Replikat Durch das Erhöhen der Anzahl der Worker pro Back-End-Replikat erhöht sich die Anzahl der Nachrichten, die der Back-End-Pod verarbeiten kann. Jeder Worker kann höchstens zwei CPU-Kerne nutzen. Achten Sie daher bei der Erhöhung der Anzahl der Worker pro Replikat darauf, dass die Anzahl der CPU-Kerne im Cluster nicht überschritten wird.
Überlegungen
Wenn Sie die Kardinalitätswerte erhöhen, verbessert sich im Allgemeinen die Fähigkeit des Brokers, mehr Verbindungen und Nachrichten zu verarbeiten, und es wird die Hochverfügbarkeit bei Pod- oder Knotenausfällen erhöht. Dies führt jedoch auch zu einem höheren Ressourcenverbrauch. Berücksichtigen Sie also beim Anpassen von Kardinalitätswerten die Speicherprofileinstellungen und die CPU-Ressourcenanforderungen des Brokers. Das Erhöhen der Anzahl der Worker pro Front-End-Replikat kann dazu beitragen, die Auslastung der CPU-Kerne zu erhöhen, wenn Sie feststellen, dass die Front-End-CPU-Auslastung einen Engpass darstellt. Das Erhöhen der Anzahl der Back-End-Worker kann den Nachrichtendurchsatz verbessern, wenn die Back-End-CPU ein Engpass ist.
Wenn Ihr Cluster beispielsweise drei Knoten mit acht CPU-Kernen aufweist, legen Sie die Anzahl der Front-End-Replikate so fest, dass sie mit der Anzahl der Knoten (3) übereinstimmt, und legen Sie die Anzahl der Worker auf 1 fest. Legen Sie die Anzahl der Back-End-Partitionen so fest, dass sie der Anzahl der Knoten (3) entspricht, und legen Sie Back-End-Worker auf 1 fest. Legen Sie den Redundanzfaktors nach Bedarf (2 oder 3) fest. Erhöhen Sie die Anzahl der Front-End-Worker, wenn Sie feststellen, dass die Front-End-CPU einen Engpass darstellt. Denken Sie daran, dass Back-End- und Front-End-Worker möglicherweise miteinander um CPU-Ressourcen und andere Pods konkurrieren können.
Konfigurieren des Arbeitsspeicherprofils
Wichtig
Diese Einstellung erfordert das Ändern der Brokerressource und kann nur bei der erstmaligen Bereitstellung mithilfe der Azure CLI oder des Azure-Portals konfiguriert werden. Eine neue Bereitstellung ist erforderlich, wenn Änderungen an der Broker-Konfiguration erforderlich sind. Weitere Informationen finden Sie unter Anpassen des Standardbrokers.
Um die Speicherprofileinstellungen für MQTT-Broker zu konfigurieren, geben Sie die Speicherprofilfelder in der Spezifikation der Broker-Ressource während der Azure IoT Einsatz-Bereitstellung an.
Im folgenden Leitfaden zum Bereitstellen von Azure IoT Einsatz finden Sie im Abschnitt Konfiguration unter MQTT-Brokerkonfiguration, und suchen Sie nach der Einstellung für das Speicherprofil. Hier stehen in einer Dropdownliste verfügbare Speicherprofile zur Auswahl.
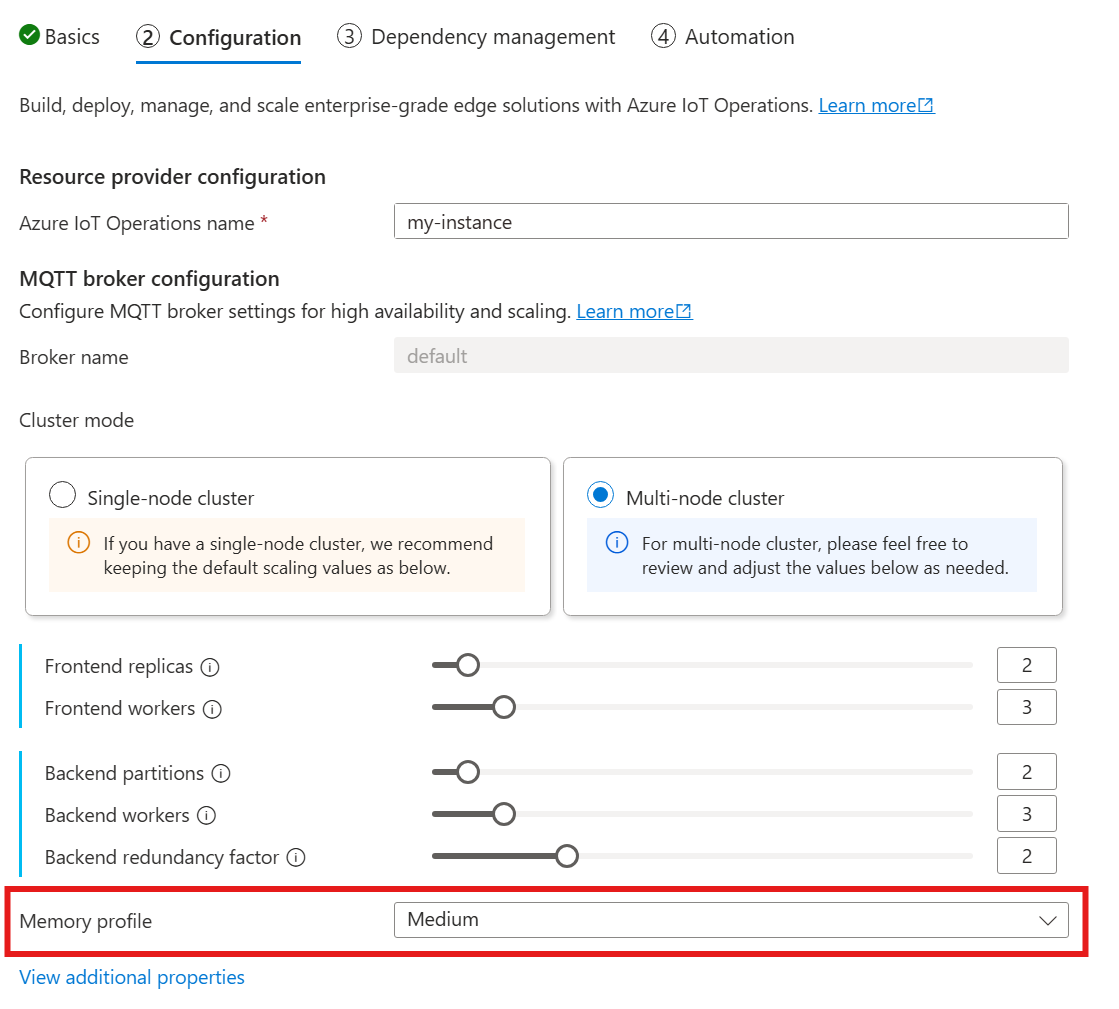
Es stehen einige Speicherprofile zur Auswahl, die jeweils über unterschiedlichen Speicherauslastungsmerkmale verfügen.
Sehr klein
Bei Verwendung dieses Profils:
- Die maximale Speicherauslastung jedes Front-End-Replikats beträgt etwa 99 MiB, aber die tatsächliche maximale Speicherauslastung kann höher sein.
- Die maximale Speicherauslastung jedes Back-End-Replikats beträgt etwa 102 MiB multipliziert mit der Anzahl der Back-End-Worker, aber die tatsächliche maximale Speicherauslastung kann höher sein.
Empfehlungen bei Verwendung dieses Profils:
- Es sollte nur ein Front-End verwendet werden.
- Clients sollten keine großen Pakete senden. Sie sollten nur Pakete senden, die kleiner als 4 MiB sind.
Niedrig
Bei Verwendung dieses Profils:
- Die maximale Speicherauslastung jedes Front-End-Replikats beträgt etwa 387 MiB, aber die tatsächliche maximale Speicherauslastung kann höher sein.
- Die maximale Speicherauslastung jedes Back-End-Replikats beträgt etwa 390 MiB multipliziert mit der Anzahl der Back-End-Worker, aber die tatsächliche maximale Speicherauslastung kann höher sein.
Empfehlungen bei Verwendung dieses Profils:
- Es sollten nur ein oder zwei Front-Ends verwendet werden.
- Clients sollten keine großen Pakete senden. Sie sollten nur Pakete senden, die kleiner als 10 MiB sind.
Medium
„Mittel“ ist das Standardprofil.
- Die maximale Speicherauslastung jedes Front-End-Replikats beträgt etwa 1,9 GiB, aber die tatsächliche maximale Speicherauslastung kann höher sein.
- Die maximale Speicherauslastung jedes Back-End-Replikats beträgt etwa 1,5 GiB multipliziert mit der Anzahl der Back-End-Worker, aber die tatsächliche maximale Speicherauslastung kann höher sein.
Hoch
- Die maximale Speicherauslastung jedes Front-End-Replikats beträgt etwa 4,9 GiB, aber die tatsächliche maximale Speicherauslastung kann höher sein.
- Die maximale Speicherauslastung jedes Back-End-Replikats beträgt etwa 5,8 GiB multipliziert mit der Anzahl der Back-End-Worker, aber die tatsächliche maximale Speicherauslastung kann höher sein.
Ressourcenbeschränkungen für Kardinalität und Kubernetes
Um Verhungern von Ressourcen im Cluster zu verhindern, wird der Broker standardmäßig so konfiguriert, dass Kubernetes CPU-Ressourcengrenzwerte angefordert werden. Durch die Skalierung der Anzahl von Replikaten oder Workern erhöht sich die Menge an erforderlichen CPU-Ressourcen proportional. Es wird ein Bereitstellungsfehler ausgegeben, wenn im Cluster nicht genügend CPU-Ressourcen verfügbar sind. Dadurch können Situationen vermieden werden, in denen die angeforderte Brokerkardinalität nicht über genügend Ressourcen für ein optimales Ausführungsverhalten verfügt. Es trägt auch zur Vermeidung potenzieller CPU-Konflikte und Pod-Räumungen bei.
MQTT-Broker fordert derzeit eine (1.0) CPU-Einheit pro Front-End-Worker und zwei (2,0) CPU-Einheiten pro Back-End-Worker an. Weitere Informationen finden Sie unter Kubernetes CPU-Ressourceneinheiten.
Die folgende Kardinalität würde beispielsweise die folgenden CPU-Ressourcen anfordern:
- Für Front-Ends: 2 CPU-Einheiten pro Front-End-Pod insgesamt 6 CPU-Einheiten.
- Für Back-Ends: 4 CPU-Einheiten pro Back-End-Pod (für zwei Back-End-Worker), Mal 2 (Redundanzfaktor), Mal 3 (Anzahl der Partitionen), insgesamt 24 CPU-Einheiten.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Um diese Einstellung zu deaktivieren, legen Sie das Feld generateResourceLimits.cpu in der Brokerressource auf Disabled fest.
Das Feld generateResourceLimits kann im Azure-Portal nicht geändert werden. Verwenden Sie die Azure CLI, um diese Einstellung zu deaktivieren.
Bereitstellung mit mehreren Knoten
Um hohe Verfügbarkeit und Resilienz mit Bereitstellungen mit mehreren Knoten sicherzustellen, legt der MQTT-Broker von Azure IoT Einsatz automatisch Antiaffinitätsregeln für Back-End-Pods fest.
Diese Regeln sind vordefiniert und können nicht geändert werden.
Zweck von Antiaffinitätsregeln
Die Antiaffinitätsregeln stellen sicher, dass Back-End-Pods aus derselben Partition nicht auf demselben Knoten ausgeführt werden. Dies erleichtert das Verteilen der Last und bietet Resilienz gegen Knotenfehler. Insbesondere haben Back-End-Pods aus derselben Partition eine Antiaffinität zueinander.
Überprüfen von Antiaffinitätseinstellungen
Verwenden Sie den folgenden Befehl, um die Antiaffinitätseinstellungen für einen Back-End-Pod zu überprüfen:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
Die Ausgabe zeigt die Antiaffinitätskonfiguration an, die der folgenden ähnelt:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Dies sind die einzigen Antiaffinitätsregeln, die für den Broker festgelegt werden.