Übersicht über Azure Storage in HDInsight
Azure Storage stellt eine robuste universelle Speicherlösung dar, die nahtlos mit HDInsight integriert werden kann. In HDInsight kann ein Blobcontainer in Azure Storage als Standarddateisystem für den Cluster verwendet werden. Über eine HDFS-Schnittstelle können sämtliche Komponenten in HDInsight direkt mit strukturierten oder unstrukturierten Daten arbeiten, die als Blobs gespeichert sind.
Es wird empfohlen, separate Speichercontainer für Ihren standardmäßigen Clusterspeicher und Ihre Geschäftsdaten zu verwenden. Diese Vorgehensweise ist sinnvoll, um die HDInsight-Protokolle und temporären Dateien zu isolieren und von Ihren Geschäftsdaten zu trennen. Wir empfehlen, die Standardblobcontainer mit den Anwendungs- und Systemprotokollen nach jeder Verwendung zu löschen, um die Speicherkosten zu verringern. Stellen Sie sicher, dass Sie die Protokolle abrufen, bevor Sie den Container löschen.
Wenn Sie Ihr Speicherkonto mit den Einschränkungen Firewalls und virtuelle Netzwerke unter Ausgewählte Netzwerke schützen, müssen Sie die Ausnahme Vertrauenswürdige Microsoft-Dienste zulassen… aktivieren. Nur so kann HDInsight auf Ihr Speicherkonto zugreifen.
HDInsight-Speicherarchitektur
Das folgende Diagramm bietet eine verallgemeinerte Übersicht über die HDInsight-Architektur von Azure Storage:
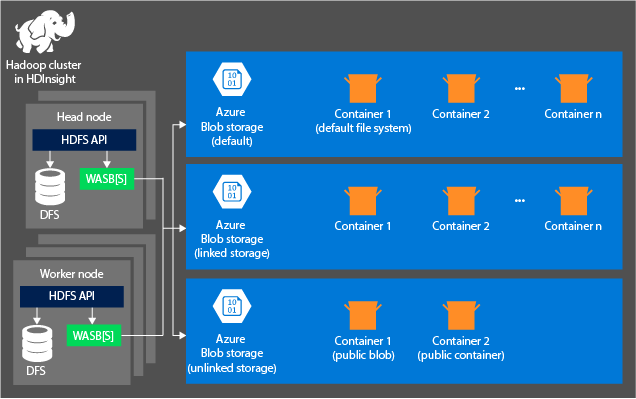
HDInsight bietet Zugang zum verteilten Dateisystem, das lokal an die Rechenknoten angefügt ist. Auf dieses Dateisystem kann über den vollständig qualifizierten URI zugegriffen werden. Zum Beispiel:
hdfs://<namenodehost>/<path>
Mit HDInsight können Sie auch auf Daten in Azure Storage zugreifen. Die Syntax lautet wie folgt:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Für Konten mit einem hierarchischen Namespace (Azure Data Lake Storage Gen2) lautet die Syntax wie folgt:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Berücksichtigen Sie die folgenden Prinzipien, wenn Sie ein Azure Storage-Konto mit HDInsight-Clustern verwenden:
Container in Speicherkonten, die mit einem Cluster verbunden sind: Da Kontoname und Schlüssel dem Cluster bei der Erstellung zugeordnet werden, haben Sie vollständigen Zugriff auf die Blobs in diesen Containern.
Öffentliche Container oder öffentliche Blobs in Speicherkonten, die nicht mit einem Cluster verbunden sind: Sie verfügen über Leserechte für die Blobs in den Containern.
Hinweis
Öffentliche Container erlauben das Abrufen einer Liste aller im Container verfügbaren Blobs und der Container-Metadaten. Auf öffentliche Blobs haben Sie nur Zugriff, wenn Sie die exakte URL kennen. Weitere Informationen finden Sie unter Verwalten des anonymen Lesezugriffs auf Container und Blobs.
Private Container in Speicherkonten, die nicht mit einem Cluster verbunden sind: Sie können nicht auf die Blobs in den Containern zugreifen, es sei denn, Sie definieren beim Senden der WebHCat-Aufträge das Speicherkonto.
Die bei der Erstellung definierten Speicherkonten und ihre Schlüssel werden in der Datei „%HADOOP_HOME%/conf/core-site.xml“ auf den Clusterknoten gespeichert. Standardmäßig verwendet HDInsight die in der Datei „core-site.xml“ definierten Speicherkonten. Sie können diese Einstellung mit Apache Ambari ändern. Weitere Informationen zu den Speicherkontoeinstellungen, die geändert oder in der core-site.xml-Datei platziert werden können, finden Sie in den folgenden Artikeln:
Verschiedene WebHCat-Aufträge, darunter Apache Hive, MapReduce, Apache Hadoop Streaming und Apache Pig, enthalten eine Beschreibung von Speicherkonten und Metadaten. (Bei Pig gilt dies derzeit nur für Speicherkonten, nicht jedoch für Metadaten.) Weitere Informationen finden Sie unter Verwenden eines HDInsight-Clusters mit alternativen Speicherkonten und Metastores.
Blobs können für strukturierte und unstrukturierte Daten verwendet werden. In Blobcontainern werden Daten als Schlüssel-Wert-Paare gespeichert, und es gibt keine Verzeichnishierarchie. Der Schlüsselname kann jedoch einen Schrägstrich (/) enthalten, damit es so aussieht, als wäre eine Datei in einer Verzeichnisstruktur gespeichert. Der Schlüssel eines Blobs kann z.B. input/log1.txt lauten. Es gibt kein Verzeichnis input, aber aufgrund des Schrägstrichs im Namen sieht der Schlüssel wie ein Dateipfad aus.
Vorteile von Azure Storage
Für Computecluster und Speicherressourcen, die sich nicht am selben Ort befinden, fallen implizite Leistungskosten an. Diese Kosten können dadurch verringert werden, dass Computecluster nahe bei den Speicherkontoressourcen innerhalb der Azure-Region erstellt werden. In dieser Region können die Serverknoten effizient über das Hochgeschwindigkeitsnetzwerk in Azure Storage auf die Daten zugreifen.
Wenn Sie die Daten in Azure Storage anstelle von HDFS speichern, erhalten Sie mehrere Vorteile:
Datenwiederverwendung und -freigabe: Die Daten im HDFS befinden sich innerhalb des Computeclusters. Nur die Anwendungen, die Zugriff auf den Rechencluster haben, können die Daten über die HDFS-API verwenden. Auf die Daten in Azure Storage kann im Gegensatz dazu über die HDFS-APIs oder über die Blob Storage-REST-APIs zugegriffen werden. Dadurch kann eine größere Menge von Anwendungen (darunter andere HDInsight-Cluster) und Tools verwendet werden, um die Daten zu produzieren und abzurufen.
Datenarchivierung: Wenn Daten in Azure Storage gespeichert werden, kann der für Berechnungen verwendete HDInsight-Cluster sicher gelöscht werden, ohne Benutzerdaten zu verlieren.
Datenspeicherkosten: Die langfristige Speicherung von Daten in DFS ist kostenintensiver als das Speichern der Daten in Azure Storage. Der Grund dafür ist, dass die Kosten eines Computeclusters höher sind als die Kosten von Azure Storage. Da die Daten nicht für jede Erzeugung eines neues Computeclusters neu geladen werden müssen, sparen Sie außerdem Kosten für das Laden von Daten.
Elastische horizontale Skalierung: Auch wenn HDFS ein horizontal skaliertes Dateisystem bietet, wird die Skalierung durch die Anzahl der Knoten bestimmt, die Sie für Ihren Cluster erstellen. Eine Änderung der Skalierung kann weitaus schwieriger sein, als die Kapazitäten der elastischen Skalierung zu nutzen, die Ihnen Azure Storage automatisch bietet.
Georeplikation: Für Azure Storage kann eine Georeplikation durchgeführt werden. Obwohl die Georeplikation geografische Wiederherstellung und Datenredundanz bietet, wirkt sich ein Failover auf den georeplizierten Standort stark auf die Leistung aus und kann zusätzliche Kosten nach sich ziehen. Sie sollten die Georeplikation mit Bedacht und nur dann auswählen, wenn der Wert der Daten die zusätzlichen Kosten rechtfertigt.
Bestimmte MapReduce-Aufträge und -Pakete können zu Zwischenergebnissen führen, die Sie nicht in Azure Storage speichern möchten. In diesem Fall können Sie die Dateien auch im lokalen HDFS speichern. HDInsight verwendet für einige dieser Zwischenergebnisse in Hive-Aufträge und anderen Prozessen DFS.
Hinweis
Die meisten HDFS-Befehle (z.B. ls, copyFromLocal und mkdir) funktionieren in Azure Storage wie erwartet. Nur die für die native (als DFS bezeichnete) HDFS-Implementierung spezifischen Befehle wie fschk und dfsadmin weisen in Azure Storage ein anderes Verhalten auf.