Verwenden des Azure Machine Learning-Notizbuchs auf Spark
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie in den Azure HDInsight on AKS Vorschauinformationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage an AskHDInsight mit den entsprechenden Details und folgen Sie uns, um weitere Updates zu Azure HDInsight Communityzu erhalten.
Maschinelles Lernen ist eine wachsende Technologie, mit der Computer automatisch aus früheren Daten lernen können. Maschinelles Lernen verwendet verschiedene Algorithmen, um mathematische Modelle zu erstellen und um Vorhersagen zu treffen, indem historische Daten oder Informationen verwendet werden. Wir haben ein Modell, das bis zu einigen Parametern definiert ist, und das Lernen ist die Ausführung eines Computerprogramms, um die Parameter des Modells mithilfe der Schulungsdaten oder -erfahrungen zu optimieren. Das Modell kann prädiktiv sein, um in Zukunft Vorhersagen zu machen, oder beschreibend, um Wissen aus Daten zu gewinnen.
Das folgende Lernprogramm-Notizbuch zeigt ein Beispiel für die Schulung von Machine Learning-Modellen in tabellarischen Daten. Sie können dieses Notizbuch importieren und selbst ausführen.
Hochladen der CSV in Ihren Speicher
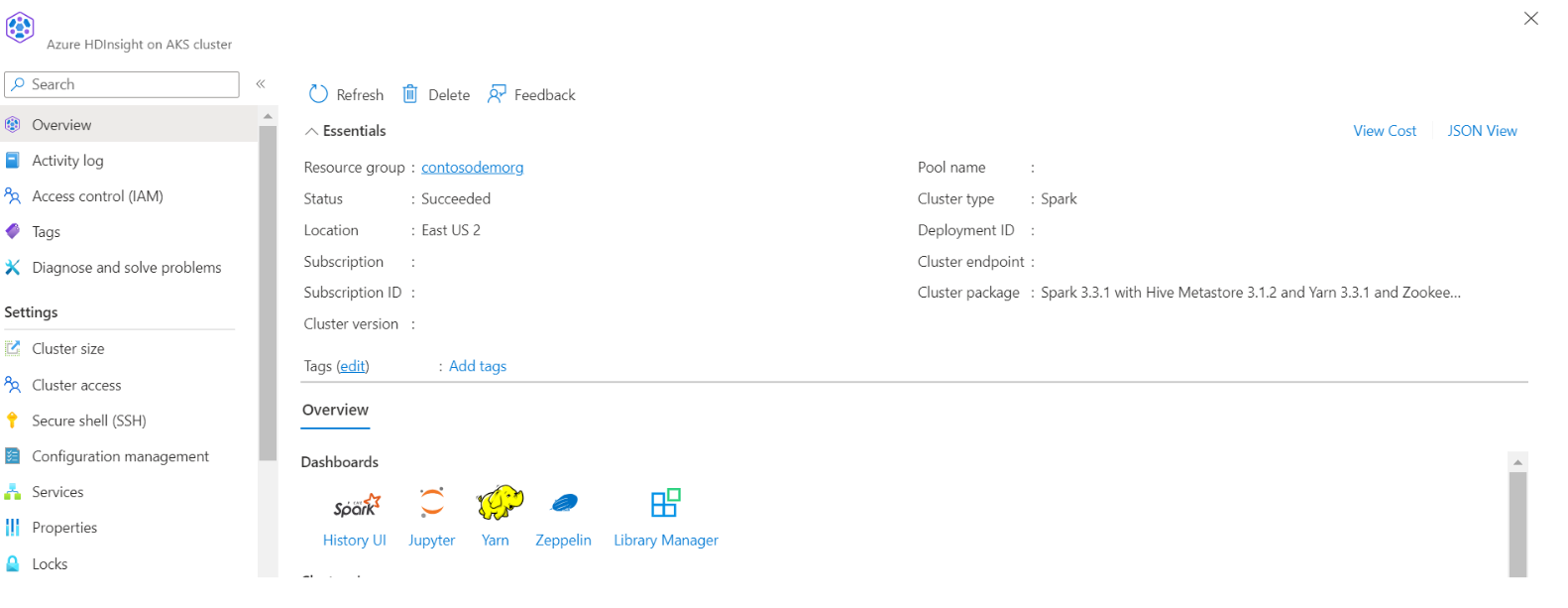
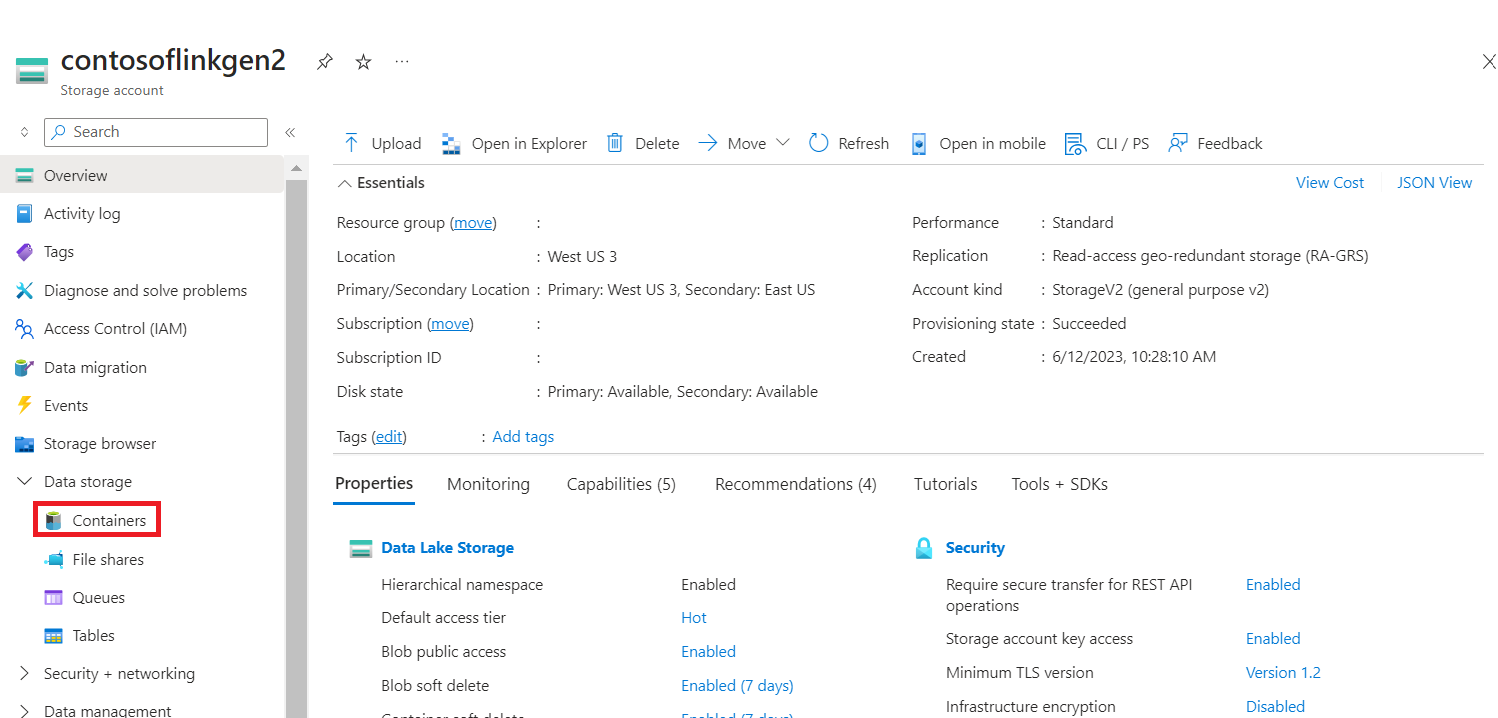
Finden Sie Ihren Speicher- und Containernamen in der JSON-Ansicht des Portals
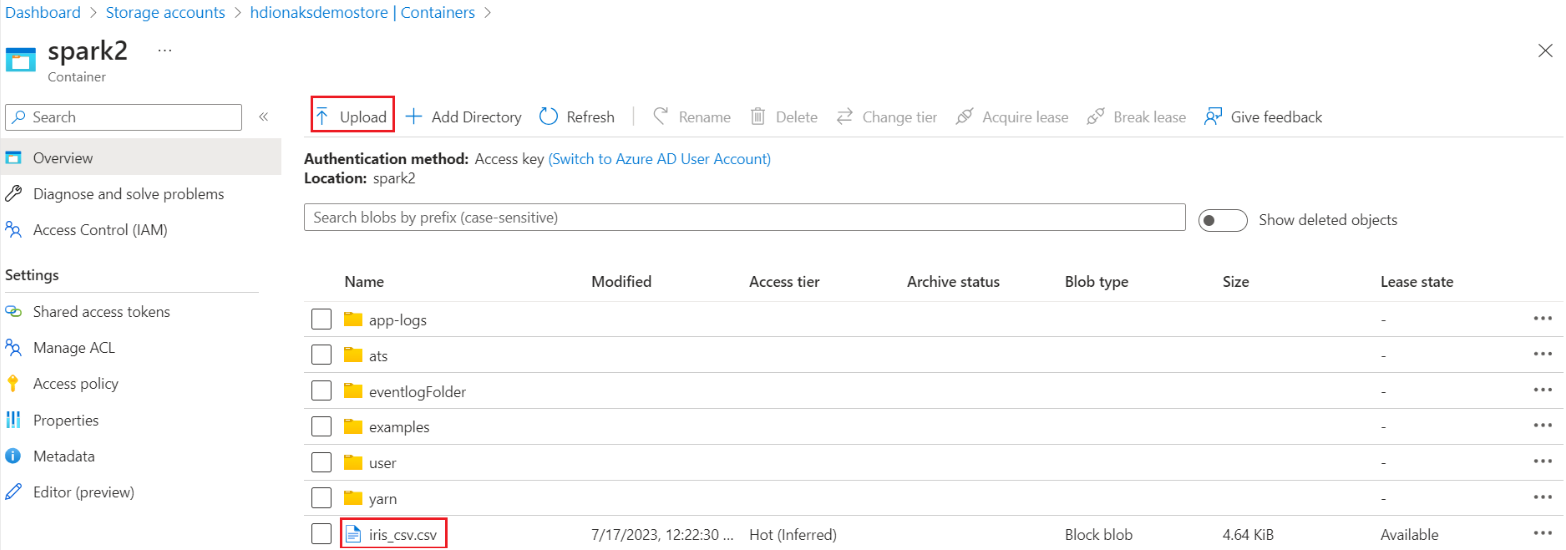
Navigieren Sie zu Ihrem primären HDI-Speicher>Container>Basisordner> und laden Sie die CSV- hoch.
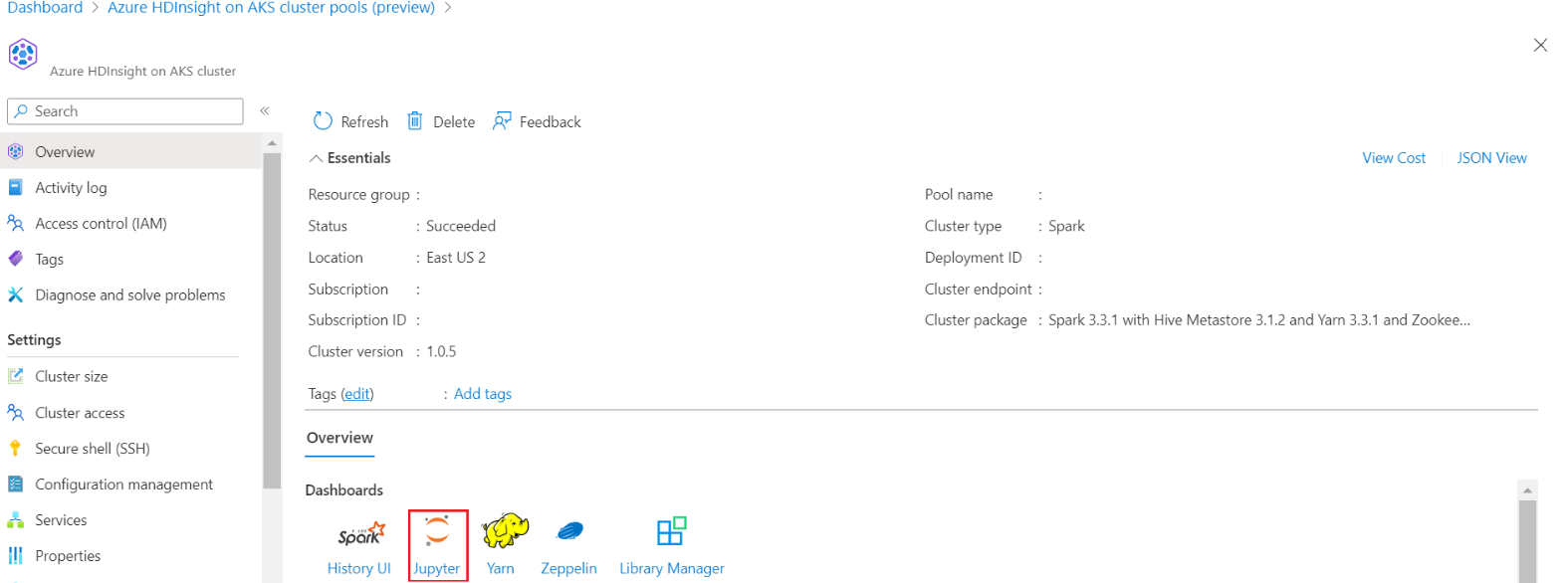
Melden Sie sich bei Ihrem Cluster an, und öffnen Sie das Jupyter-Notizbuch.
Importieren von Spark MLlib-Bibliotheken zum Erstellen der Pipeline
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Lese die CSV in einen Spark-Datenframe ein.
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)Teilen der Daten für Schulungen und Tests
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)Erstellen der Pipeline und Trainieren des Modells
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
Die Genauigkeit des Modells bewerten.
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))



