Was ist Apache Spark™ in HDInsight auf AKS? (Vorschau)
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage an AskHDInsight und geben Sie die Details an. Folgen Sie uns für weitere Updates zu Azure HDInsight Community.
Apache Spark™ ist ein paralleles Verarbeitungsframework, das die In-Memory-Verarbeitung unterstützt, um die Leistung von Big Data-Analyseanwendungen zu steigern.
Apache Spark™ stellt Grundtypen für in-Memory Cluster Computing bereit. Ein Spark-Auftrag kann Daten in den Arbeitsspeicher laden und zwischenspeichern und wiederholt abfragen. In-Memory-Computing ist schneller als datenträgerbasierte Anwendungen wie Hadoop, die Daten über das verteilte Hadoop-Dateisystem (HDFS) austauschen. Apache Spark ermöglicht die Integration in die Programmiersprachen Scala und Python, damit Sie verteilte Datasets wie lokale Sammlungen bearbeiten können. Es ist nicht erforderlich, alles als Map- und Reduce-Operationen zu strukturieren.
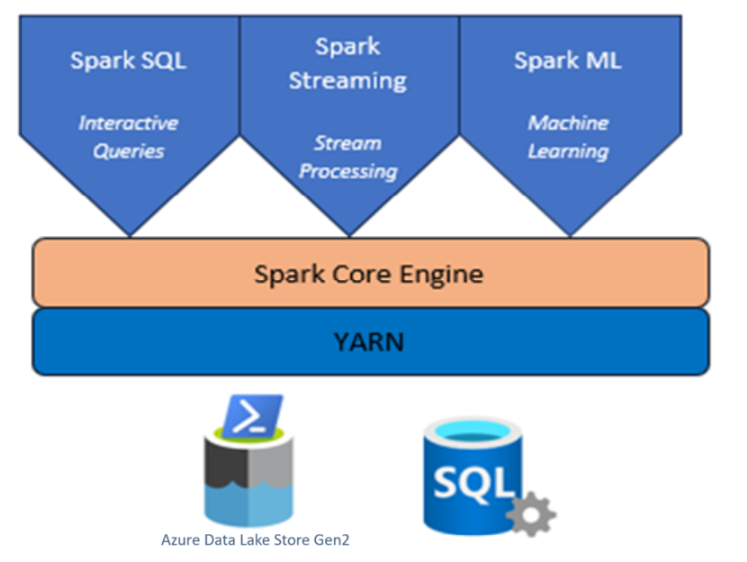
Apache Spark-Cluster mit HDInsight auf AKS
Azure HDInsight ist ein verwalteter, vollständiger, open-source-Analysedienst für Unternehmen.
Apache Spark™ in Azure HDInsight auf AKS ist der verwaltete Spark-Dienst in Microsoft Azure. Mit Apache Spark in Azure HDInsight auf AKS können Sie Ihre Daten in Azure speichern und verarbeiten. Spark-Cluster in HDInsight sind mit oder Azure Data Lake Storage Gen2kompatibel, sodass Sie Spark-Verarbeitung auf Ihre vorhandenen Datenspeicher anwenden können.
Das Apache Spark-Framework für HDInsight auf AKS ermöglicht schnelle Datenanalysen und Cluster computing mit in-Memory-Verarbeitung. Mit Jupyter-Notizbuch können Sie mit Ihren Daten interagieren, Code mit Markdowntext kombinieren und einfache Visualisierungen ausführen.
Apache Spark auf AKS in HDInsight besteht aus mehreren Komponenten als Pods.
Cluster-Controller
Clustercontroller sind für die Installation und Verwaltung der jeweiligen Dienste verantwortlich. Verschiedene Controller werden in einem Spark-Cluster installiert und verwaltet.
Apache Spark-Dienstkomponenten
Zookeeper-Dienst: Ein drei Knoten Zookeeper-Cluster dient als verteilter Koordinator oder Hochverfügbarkeitsspeicher für andere Dienste.
Yarn-Dienst: Auf dem Hadoop Yarn-Cluster werden Spark-Jobs im Cluster als Yarn-Anwendungen geplant.
Benutzerschnittstellen: Apache Spark-Cluster in HDInsight auf AKS bieten verschiedene Benutzerschnittstellen. Livy Server, Jupyter Notebook, Spark History Server, bietet Spark-Dienste für HDInsight für AKS-Benutzer.
Referenz
- Apache, Apache Spark, Spark und verbundene Open-Source-Projektnamen sind Marken der Apache Software Foundation (ASF).