So verwenden Sie Flink/Delta Connector
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr in dieser Ankündigung über.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage auf AskHDInsight mit den Details und folgen Sie uns, um weitere Updates zu Azure HDInsight Communityzu erhalten.
Mithilfe von Apache Flink und Delta Lake können Sie eine zuverlässige und skalierbare Data Lakehouse-Architektur erstellen. Mit dem Flink/Delta Connector können Sie Daten in Delta-Tabellen mit ACID-Transaktionen und genauer einmaliger Verarbeitung schreiben. Dies bedeutet, dass Ihre Datenströme konsistent und fehlerfrei sind, auch wenn Sie die Flink-Pipeline von einem Prüfpunkt neu starten. Der Flink/Delta Connector stellt sicher, dass Ihre Daten nicht verloren oder dupliziert werden, und dass sie mit der Flink-Semantik übereinstimmt.
In diesem Artikel erfahren Sie, wie Sie Flink-Delta Connector verwenden.
- Lesen Sie die Daten aus der Delta-Tabelle.
- Schreiben Sie die Daten in eine Delta-Tabelle.
- Abfrage in Power BI.
Was ist Flink/Delta Connector?
Flink/Delta Connector ist eine JVM-Bibliothek zum Lesen und Schreiben von Daten aus Apache Flink-Anwendungen in Delta-Tabellen mithilfe der eigenständigen Delta JVM-Bibliothek. Der Verbinder bietet genau einmal Liefergarantien.
Flink/Delta Connector umfasst:
DeltaSink zum Schreiben von Daten aus Apache Flink in eine Delta-Tabelle. DeltaSource zum Lesen von Delta-Tabellen mit Apache Flink.
Apache Flink-Delta Connector umfasst:
Abhängig von der Version des Connectors können Sie ihn mit folgenden Apache Flink-Versionen verwenden:
Connector's version Flink's version
0.4.x (Sink Only) 1.12.0 <= X <= 1.14.5
0.5.0 1.13.0 <= X <= 1.13.6
0.6.0 X >= 1.15.3
0.7.0 X >= 1.16.1 --- We use this in Flink 1.17.0
Voraussetzungen
- HDInsight Flink 1.17.0-Cluster auf AKS
- Flink-Delta Connector 0.7.0
- Verwenden von MSI für den Zugriff auf ADLS Gen2
- IntelliJ für die Entwicklung
Lesen von Daten aus der Delta-Tabelle
Delta Source kann in einem von zwei Modi funktionieren, wie folgt beschrieben.
Gebundener Modus geeignet für Batchaufträge, bei denen der Inhalt der Delta-Tabelle nur für bestimmte Tabellenversion gelesen werden soll. Erstellen Sie eine Quelle dieses Modus mithilfe der DeltaSource.forBoundedRowData-API.
Kontinuierlicher Modus Geeignet für Streamingaufträge, wo wir die Delta-Tabelle kontinuierlich auf neue Änderungen und Versionen überprüfen möchten. Erstellen Sie eine Quelle dieses Modus mithilfe der DeltaSource.forContinuousRowData-API.
Beispiel: Erstellen einer Quelle für die Delta-Tabelle, um alle Spalten im gebundenen Modus zu lesen. Geeignet für Batchaufträge. In diesem Beispiel wird die neueste Tabellenversion geladen.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
Schreiben in Delta-Senken
Delta Sink macht derzeit die folgenden Flink-Metriken verfügbar:

Senkenerstellung für nicht partitionierte Tabellen
In diesem Beispiel wird gezeigt, wie Sie ein DeltaSink erstellen und an eine vorhandene org.apache.flink.streaming.api.datastream.DataStreamanschließen.
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
Vollständiger Code
Lesen sie Daten aus einer Delta-Tabelle und sinken Sie in eine andere Delta-Tabelle.
package contoso.example;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.source.DeltaSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
// Execute the Flink job
env.execute("Delta datasource and sink Example");
}
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}
Maven Pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkDeltaDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop-version>3.3.4</hadoop-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-standalone_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Packen Sie ein Jar und übermitteln Sie es an den Flink-Cluster, um es auszuführen.
Laden Sie das Jar in ABFS hoch.
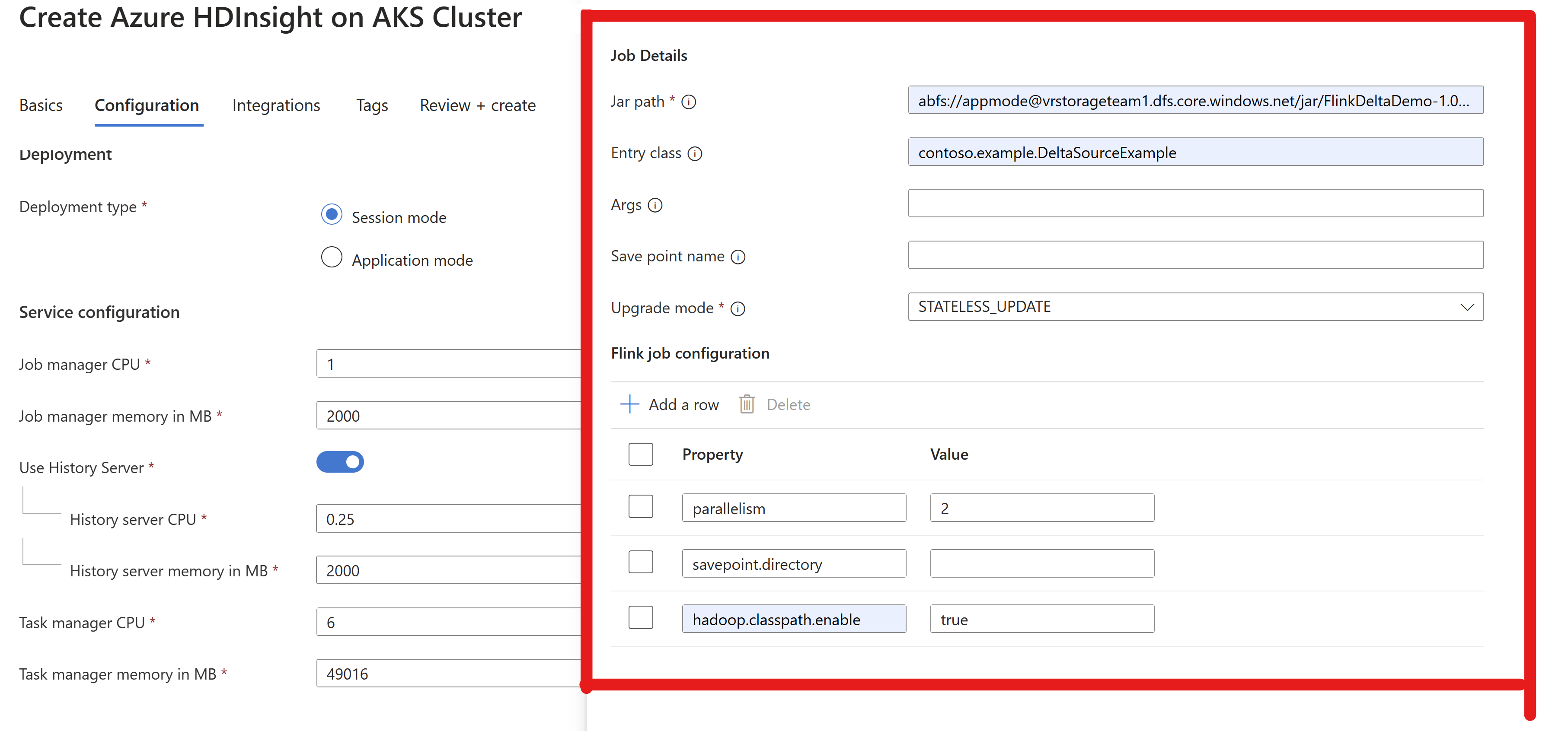
Übergeben Sie die Job-JAR-Informationen im AppMode-Cluster.
Anmerkung
Aktivieren Sie immer
hadoop.classpath.enablebeim Lesen/Schreiben in ADLS.Übermitteln Sie den Cluster, sodass Sie in der Lage sind, den Auftrag in der Flink-Benutzeroberfläche anzuzeigen.
Ergebnisse in ADLS suchen.




Power BI-Integration
Sobald sich die Daten im Delta-Sink befindet, können Sie die Abfrage auf dem Power BI-Desktop ausführen und einen Bericht erstellen.
Öffnen Sie den Power BI-Desktop, um die Daten mithilfe des ADLS Gen2-Connectors abzurufen.
URL des Speicherkontos.

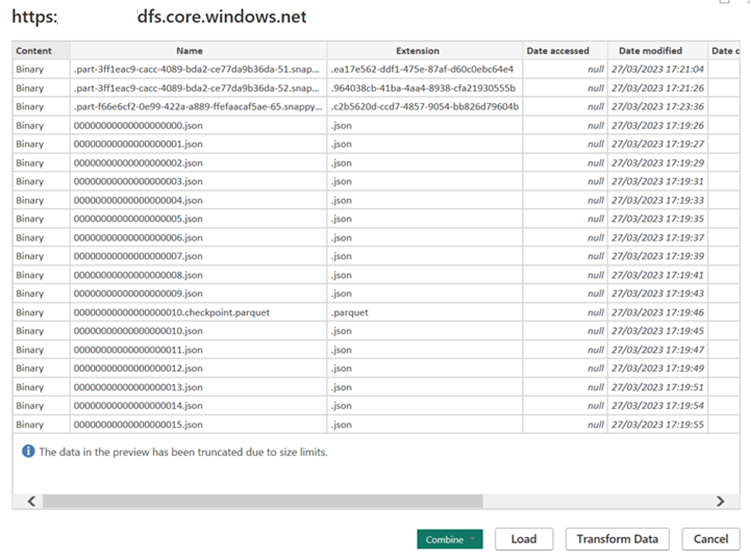
Erstellen Sie M-Abfrage für die Quelle, und rufen Sie die Funktion auf, die die Daten aus dem Speicherkonto abfragt.
Sobald die Daten sofort verfügbar sind, können Sie Berichte erstellen.
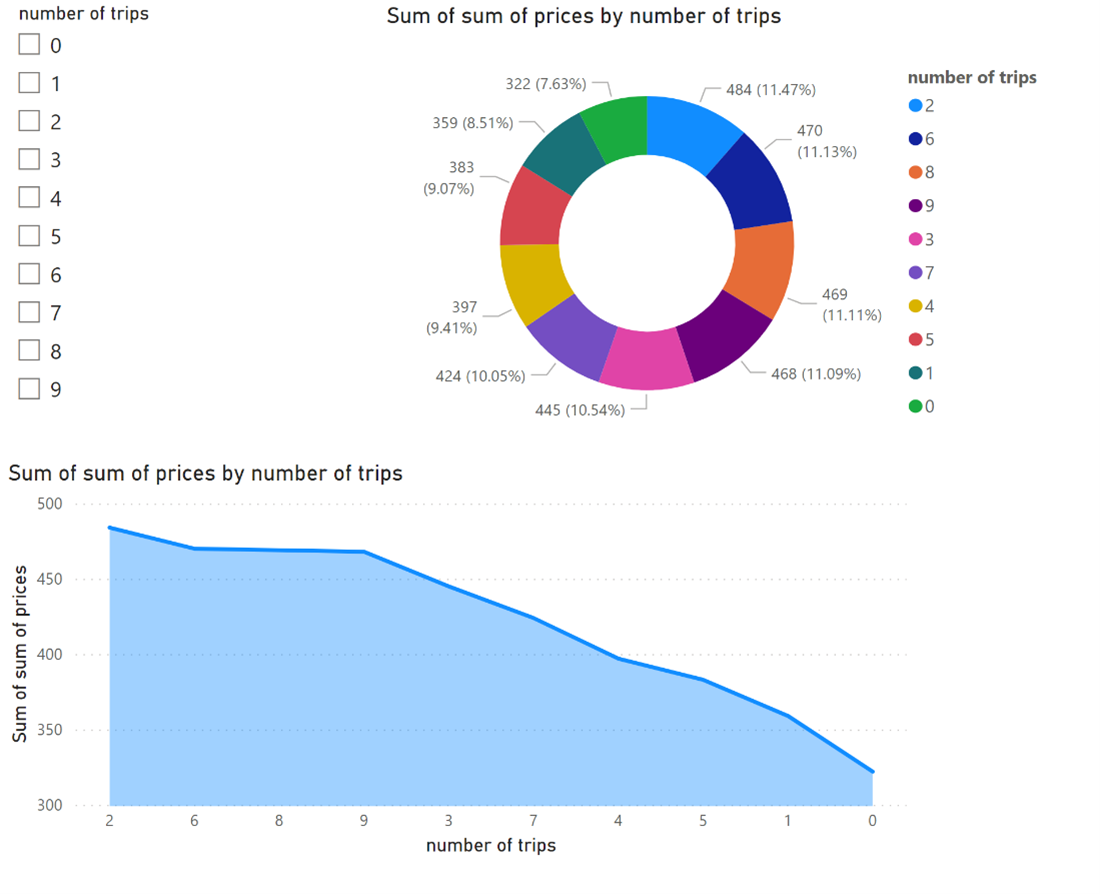
Referenzen
- Apache, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).