So verwenden Sie Azure Pipelines mit Apache Flink® auf HDInsight auf AKS
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Vorschläge für Features senden Sie bitte eine Anfrage an AskHDInsight mit den Details und folgen Sie uns, um weitere Updates zur Azure HDInsight Communityzu erhalten.
In diesem Artikel erfahren Sie, wie Sie Azure-Pipelines mit HDInsight auf AKS verwenden, um Flink-Aufträge mit der REST-API des Clusters zu übermitteln. Wir führen Sie durch den Prozess mithilfe einer Beispiel-YAML-Pipeline und eines PowerShell-Skripts, die beide die Automatisierung der REST-API-Interaktionen optimieren.
Voraussetzungen
Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, erstellen Sie ein kostenloses Konto.
Ein GitHub-Konto, in dem Sie ein Repository erstellen können. Eins kostenlos erstellen.
Erstellen Sie das
.pipeline-Verzeichnis, kopieren Sie flink-azure-pipelines.yml und flink-job-azure-pipeline.ps1.Azure DevOps-Organisation. Erstellen Sie eine kostenlos. Wenn Ihr Team bereits über eins verfügt, stellen Sie sicher, dass Sie ein Administrator des Azure DevOps-Projekts sind, das Sie verwenden möchten.
Möglichkeit zum Ausführen von Pipelines auf von Microsoft gehosteten Agenten. Um von Microsoft gehostete Agents zu verwenden, muss Ihre Azure DevOps-Organisation Zugriff auf von Microsoft gehostete parallele Aufträge haben. Sie können entweder einen parallelen Auftrag erwerben oder eine freie Förderung beantragen.
Ein Flink-Cluster. Falls Sie keinen haben, erstellen Sie einen Flink-Cluster in HDInsight auf AKS.
Erstellen Sie ein Verzeichnis im Clusterspeicherkonto, um Auftrags jar zu kopieren. Dieses Verzeichnis müssen Sie später in der Pipeline-YAML für den Ort des Job-Jar (<JOB_JAR_STORAGE_PATH>) konfigurieren.
Schritte zum Einrichten der Pipeline
Einen Dienstprinzipal für Azure-Pipelines erstellen
Erstellen Sie Microsoft Entra-Dienstprinzipal für den Zugriff auf Azure – Erteilen Sie die Berechtigung für den Zugriff auf HDInsight auf einem AKS-Cluster mit der Rolle 'Mitwirkender', und machen Sie sich Notizen zu appId, Kennwort und Mandant aus der Antwort.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Beispiel:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Referenz
Anmerkung
Apache, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).
Schlüsselverwaltung erstellen
Erstellen Sie Azure Key Vault. Sie können diesem Lernprogramm folgen, um einen neuen Azure Key Vault zu erstellen.
Erstellen Sie drei Geheimnisse
Clusterspeicherschlüssel für Speicherschlüssel.
Service-Principal-Key für die Principal-Client-ID oder AppId.
Dienstprinzipal-Schlüssel für principal secret.
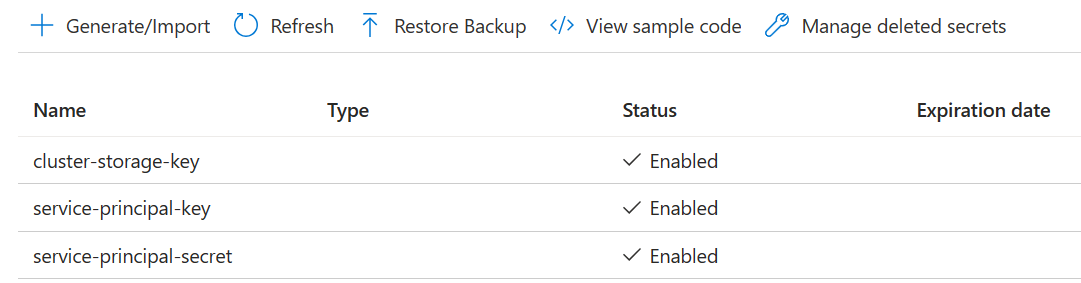
Erteilen Sie dem Dienstprinzipal die Berechtigung, auf den Azure Key Vault mit der Rolle "Key Vault Secrets Officer" zuzugreifen.

Pipeline einrichten
Navigieren Sie zu Ihrem Projekt, und klicken Sie auf "Projekteinstellungen".
Scrollen Sie nach unten, und wählen Sie "Dienstverbindungen" und dann "Neue Dienstverbindung" aus.
Wählen Sie Azure Resource Manager aus.
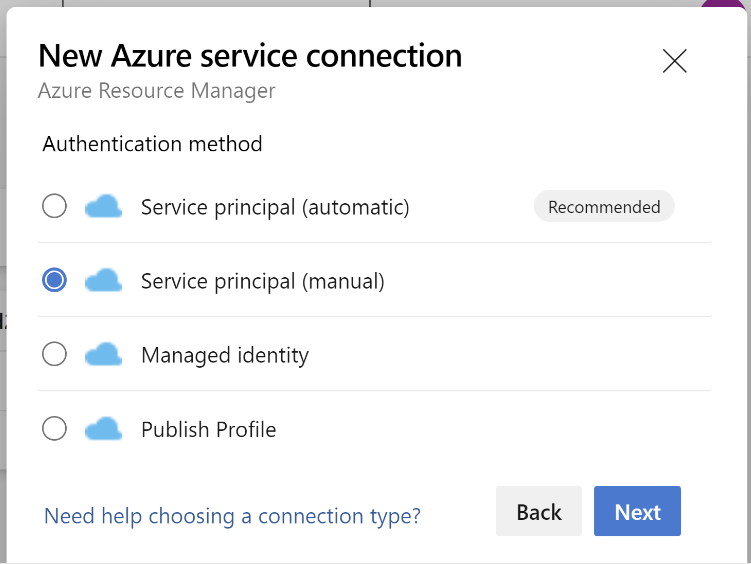
Wählen Sie in der Authentifizierungsmethode den Dienstprinzipal (manuell) aus.
Bearbeiten Sie die Dienstverbindungseigenschaften. Wählen Sie den Dienstprinzipal aus, den Sie kürzlich erstellt haben.
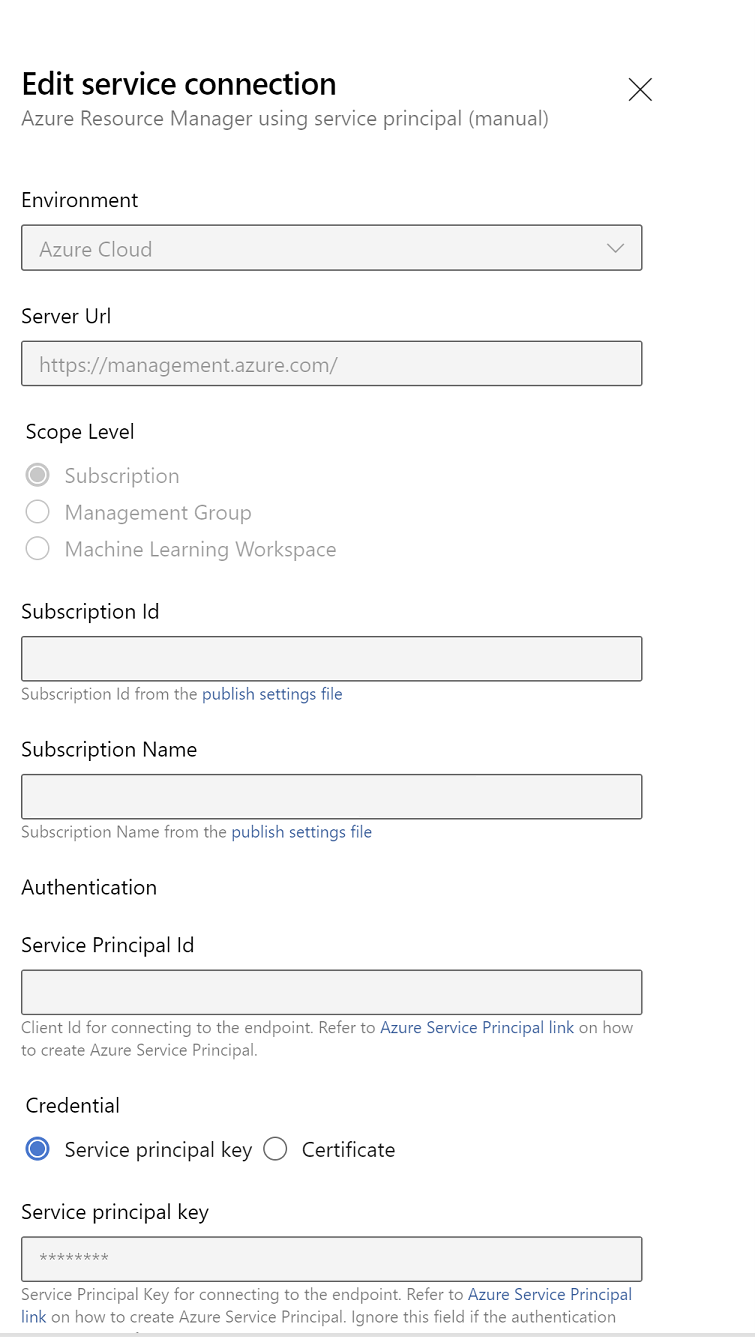
Klicken Sie auf "Überprüfen", um zu überprüfen, ob die Verbindung ordnungsgemäß eingerichtet wurde. Wenn der folgende Fehler auftritt:

Anschließend müssen Sie dem Abonnement die Reader-Rolle zuweisen.
Danach sollte die Überprüfung erfolgreich sein.
Speichern Sie die Dienstverbindung.

Navigieren Sie zu Pipelines, und klicken Sie auf "Neue Pipeline".
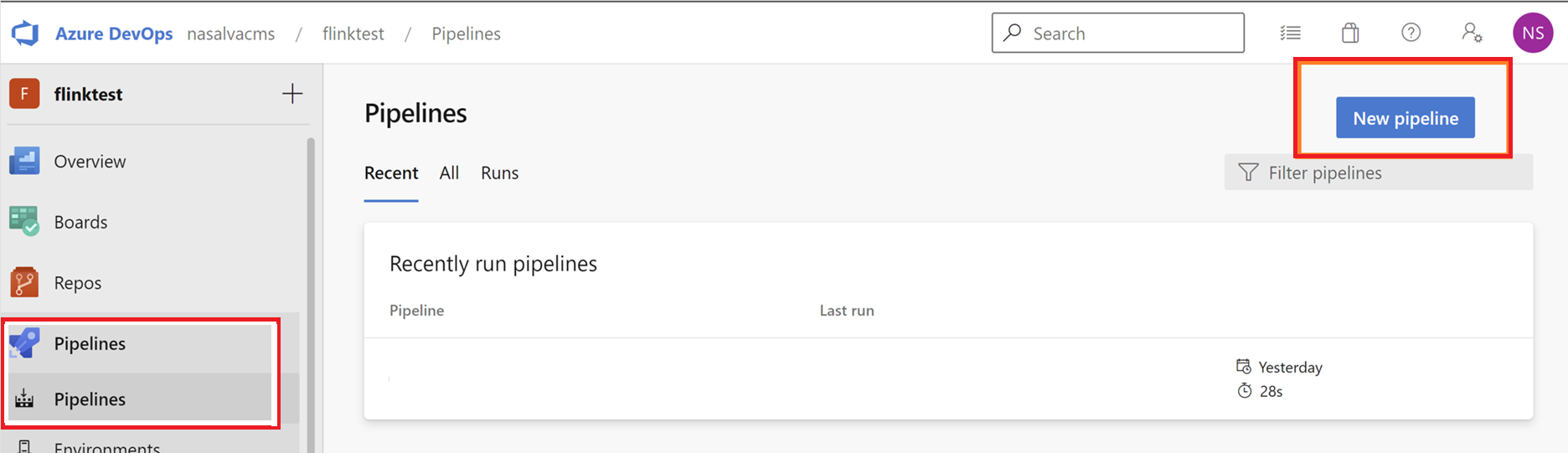
Wählen Sie GitHub als Speicherort Ihres Codes aus.
Wählen Sie das Repository aus. Informationen zum Erstellen eines Repositorys in GitHub finden Sie unter. wählen-GitHub-Repository-Bild.
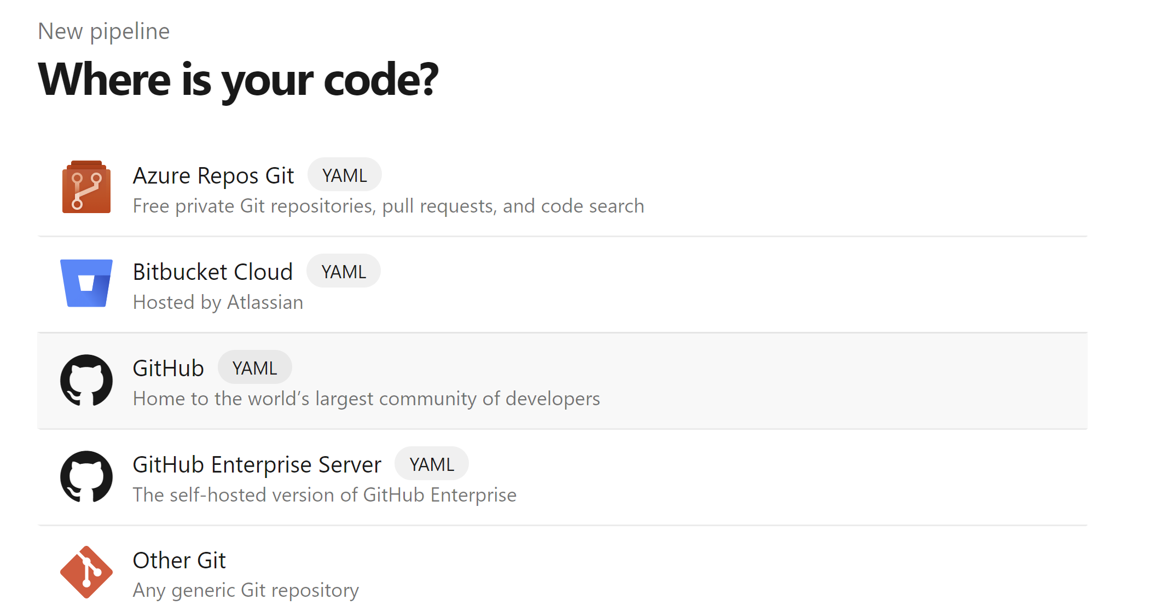
Wählen Sie das Repository aus. Weitere Informationen finden Sie unter „Wie man ein Repository auf GitHub erstellt“.
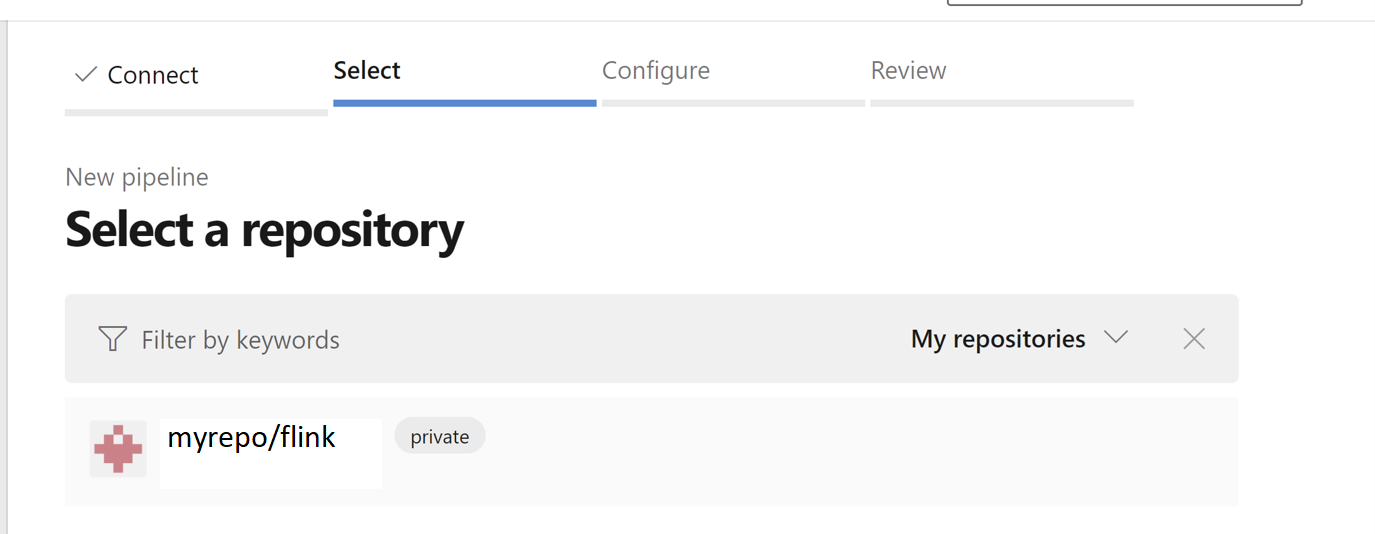
Aus der Konfiguration Ihrer Pipelineoption können Sie vorhandene Azure Pipelines YAML-Dateiauswählen. Wählen Sie Verzweigungs- und Pipelineskript aus, das Sie zuvor kopiert haben. (.pipeline/flink-azure-pipelines.yml)
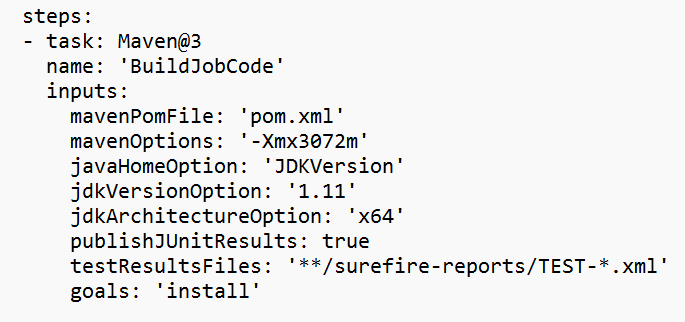
Ersetzen Sie den Wert im Variablenabschnitt.

Korrigieren Sie den Code-Build-Abschnitt basierend auf Ihrer Anforderung, und konfigurieren Sie <JOB_JAR_LOCAL_PATH> im Variablenabschnitt für den lokalen Pfad des Job-JAR.
Fügen Sie die Pipelinevariable "action" hinzu, und konfigurieren Sie den Wert "RUN".
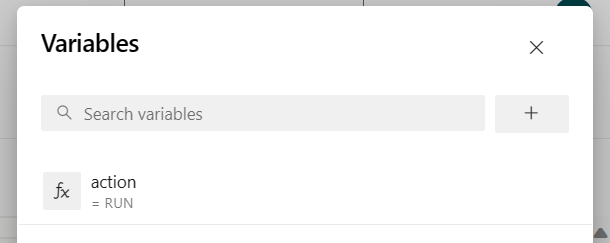
Sie können die Werte der Variablen vor dem Ausführen der Pipeline ändern.
NEU: Dieser Wert ist Standard. Er startet eine neue Aufgabe und wenn die Aufgabe bereits bearbeitet wird, aktualisiert er die bearbeitende Aufgabe mit der neuesten Version der Jar-Datei.
SAVEPOINT: Dieser Wert übernimmt den Speicherpunkt für den ausgeführten Auftrag.
DELETE: Abbrechen oder Löschen des laufenden Auftrags.
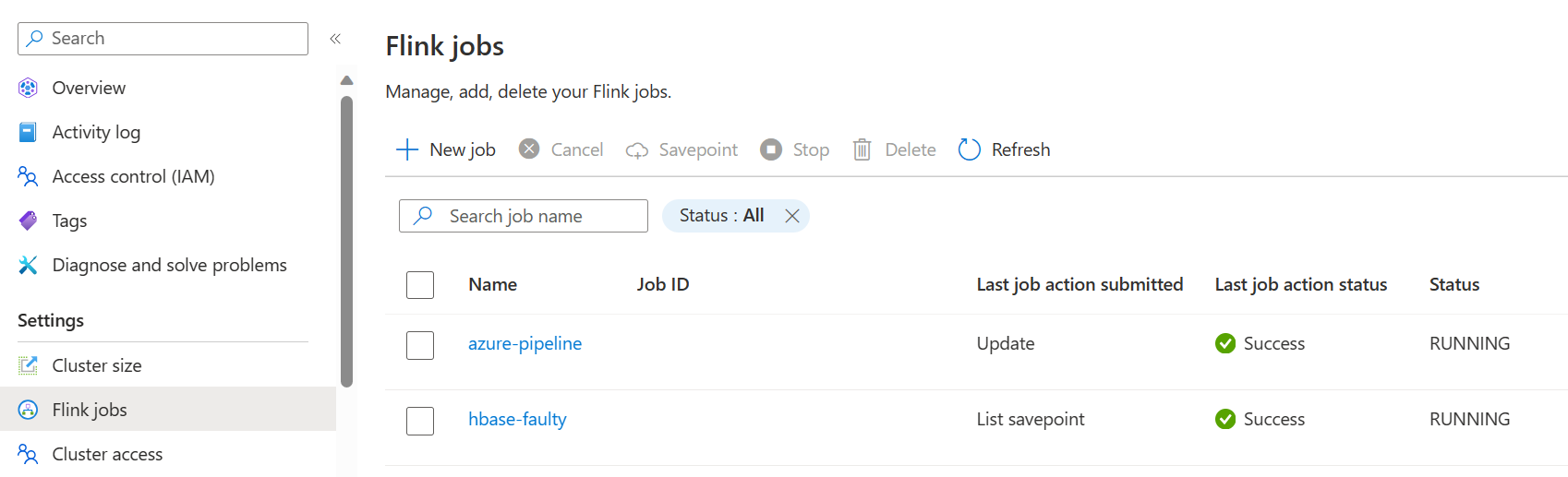
Speichern Sie die Pipeline und führen Sie sie aus. Sie können den laufenden Auftrag im Abschnitt "Flink Job" des Portals anzeigen.








Anmerkung
Dies ist ein Beispiel zum Übermitteln eines Auftrags mithilfe einer Pipeline. Sie können dem Flink-REST-API-Dokument folgen, um Ihren eigenen Code zum Senden eines Auftrags zu schreiben.