Starten der SQL Client CLI im Gatewaymodus
Hinweis
Azure HDInsight on AKS wird am 31. Januar 2025 eingestellt. Vor dem 31. Januar 2025 müssen Sie Ihre Workloads zu Microsoft Fabric oder einem gleichwertigen Azure-Produkt migrieren, um eine abruptes Beendigung Ihrer Workloads zu vermeiden. Die verbleibenden Cluster in Ihrem Abonnement werden beendet und vom Host entfernt.
Bis zum Einstellungsdatum ist nur grundlegende Unterstützung verfügbar.
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bestimmungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight on AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
In diesem Lernprogramm erfahren Sie, wie Sie die SQL Client CLI im Gatewaymodus in Apache Flink Cluster 1.17.0 auf HDInsight auf AKS starten. Im Gatewaymodus sendet die CLI die SQL an das angegebene Remotegateway, um Anweisungen auszuführen.
./bin/sql-client.sh gateway --endpoint <gateway address>
Hinweis
In Apache Flink Cluster auf HDInsight auf AKS erfolgt jede externe Verbindung über den 443-Port. Intern wird die Anforderung jedoch an den SQL-Gatewaydienst umgeleitet, der auf Port 8083 lauscht.
Überprüfen Sie den SQL-Gatewaydienst auf AKS-Seite:

Was ist SQL Client in Flink?
Die Tabellen- und SQL-API von Flink ermöglicht das Arbeiten mit Abfragen, die in der SQL-Sprache geschrieben wurden, aber diese Abfragen müssen in ein Tabellenprogramm eingebettet werden, das entweder in Java oder Scala geschrieben wurde. Darüber hinaus müssen diese Programme mit einem Buildtool verpackt werden, bevor sie an einen Cluster übermittelt werden. Dieses Feature beschränkt die Verwendung von Flink zu Java/Scala-Programmierern.
Der SQL-Client bietet eine einfache Möglichkeit zum Schreiben, Debuggen und Übermitteln von Tabellenprogrammen an einen Flink-Cluster ohne eine einzige Zeile von Java- oder Scala-Code. Die SQL Client CLI ermöglicht das Abrufen und Visualisieren von Echtzeitergebnissen aus der ausgeführten verteilten Anwendung in der Befehlszeile.
Weitere Informationen finden Sie in der Eingabe des Flink SQL CLI-Clients in Webssh.
Was ist DAS SQL-Gateway in Flink?
Das SQL-Gateway ist ein Dienst, der es mehreren Clients aus der Remote ermöglicht, SQL in Parallelität auszuführen. Es bietet eine einfache Möglichkeit, den Flink-Auftrag zu übermitteln, die Metadaten nachzuschlagen und die Daten online zu analysieren.
Weitere Informationen finden Sie unter SQL Gateway.
Starten der SQL Client CLI im Gatewaymodus in Flink-cli
Starten Sie in Apache Flink Cluster auf HDInsight auf AKS die SQL Client CLI im Gatewaymodus, indem Sie Befehl ausführen:
./bin/sql-client.sh gateway --endpoint host:port
or
./bin/sql-client.sh gateway --endpoint https://fqdn/sql-gateway
Abrufen des Clusterendpunkts (Host oder fqdn) im Azure-Portal.

Testen
Vorbereitung
Flink CLI herunterladen
- Laden Sie Flink CLI von https://aka.ms/hdionaksflink117clilinux einem lokalen Windows-Computer herunter.
Installieren Sie das Windows-Subsystem für Linux, damit dies auf einem lokalen Windows-Computer funktioniert.
Öffnen Sie den Windows-Befehl, und führen Sie den Befehl aus (ersetzen Sie JAVA_HOME- und flink-cli-Pfad durch Ihren eigenen Pfad), um flink-cli herunterzuladen:
Windows Subsystem for Linux --distribution Ubuntu export JAVA_HOME=/mnt/c/Work/99_tools/zulu11.56.19-ca-jdk11.0.15-linux_x64 cd <folder> wget https://hdiconfigactions.blob.core.windows.net/hiloflink17blob/flink-cli.tgz tar -xvf flink-cli.tgzFestlegen von Endpunkt, Mandanten-ID und Port 443 in flink-conf.yaml
user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli$ cd conf user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli/conf$ ls -l total 8 -rwxrwxrwx 1 user user 2451 Feb 26 20:33 flink-conf.yaml -rwxrwxrwx 1 user user 2946 Feb 23 14:13 log4j-cli.properties user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli/conf$ cat flink-conf.yaml rest.address: <flink cluster endpoint on Azure portal> azure.tenant.id: <tenant ID> rest.port: 443Allowlist Local Windows Public IP with port 443 with VPN enabled into HDInsight on AKS cluster Subnet's Network security inbound.
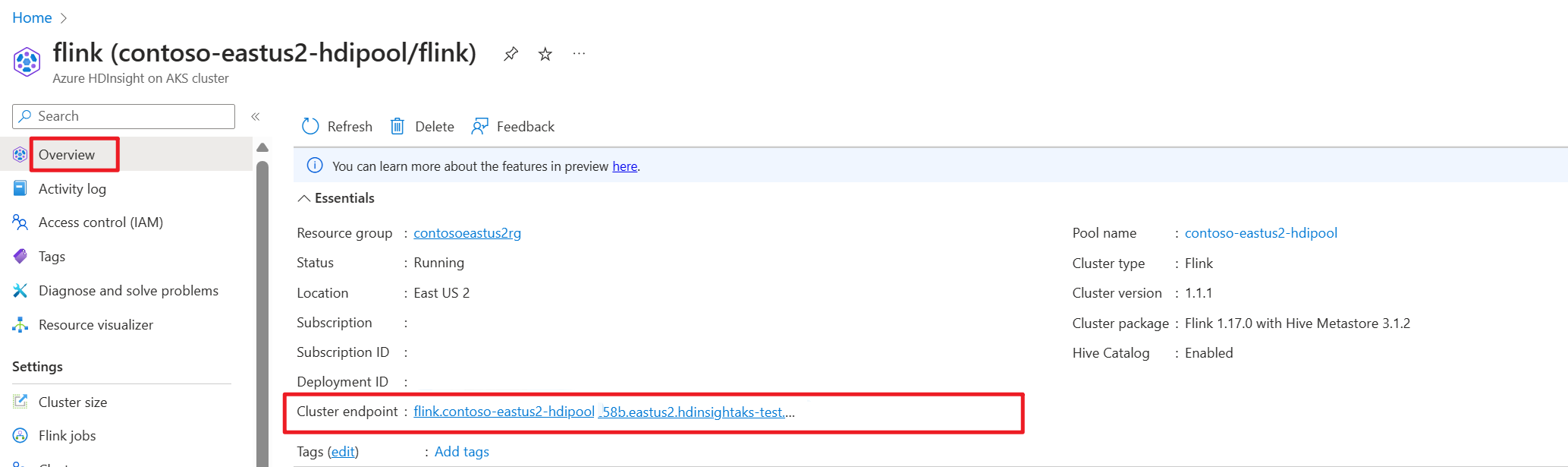
Führen Sie die sql-client.sh im Gatewaymodus auf Flink-cli zu Flink SQL aus.
bin/sql-client.sh gateway --endpoint https://fqdn/sql-gatewayBeispiel
user@MININT-481C9TJ:/mnt/c/Users/user/flink-cli$ bin/sql-client.sh gateway --endpoint https://fqdn/sql-gateway ▒▓██▓██▒ ▓████▒▒█▓▒▓███▓▒ ▓███▓░░ ▒▒▒▓██▒ ▒ ░██▒ ▒▒▓▓█▓▓▒░ ▒████ ██▒ ░▒▓███▒ ▒█▒█▒ ░▓█ ███ ▓░▒██ ▓█ ▒▒▒▒▒▓██▓░▒░▓▓█ █░ █ ▒▒░ ███▓▓█ ▒█▒▒▒ ████░ ▒▓█▓ ██▒▒▒ ▓███▒ ░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░ ▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒ ███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒ ░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒ ███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░ ██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓ ▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒ ▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒ ▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█ ██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █ ▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓ █▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓ ██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓ ▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒ ██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒ ▓█ ▒█▓ ░ █░ ▒█ █▓ █▓ ██ █░ ▓▓ ▒█▓▓▓▒█░ █▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█ ██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓ ▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██ ░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓ ░▓██▒ ▓░ ▒█▓█ ░░▒▒▒ ▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░ ______ _ _ _ _____ ____ _ _____ _ _ _ BETA | ____| (_) | | / ____|/ __ \| | / ____| (_) | | | |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_ | __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __| | | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_ |_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__| Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit. Command history file path: /home/user/.flink-sql-historyBereiten Sie vor dem Abfragen einer Tabelle mit externer Quelle die zugehörigen Jars vor. Die folgenden Beispiele für die Abfrage kafka-Tabelle, mysql-Tabelle in Flink SQL. Laden Sie den Jar herunter, und legen Sie es in Flink-Cluster angefügten Azure Data Lake Storage Gen2-Speicher.
Jars in Azure Data Lake Storage gen2 im Azure-Portal:
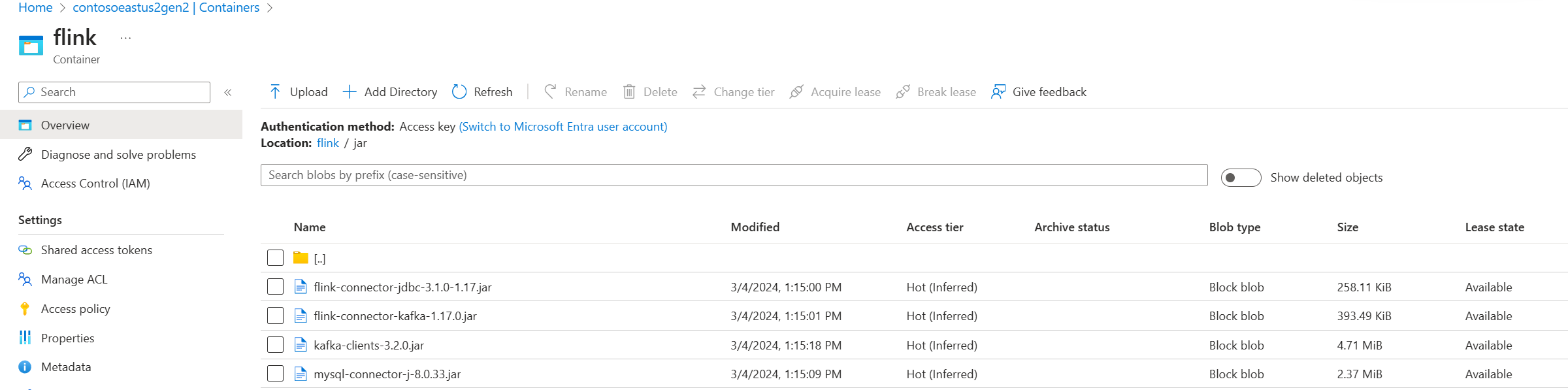
Verwenden Sie die bereits erstellte Tabelle, und fügen Sie sie in den Hive-Metaspeicher für die Verwaltung ein, und führen Sie dann die Abfrage aus.
Hinweis
In diesem Beispiel werden alle JAR-Dateien in HDInsight auf AKS auf den Standardwert Azure Data Lake Storage Gen2 gesetzt. Der Container und das Speicherkonto müssen nicht die gleichen sein, die während der Clustererstellung angegeben wurde. Falls erforderlich, können Sie ein anderes Speicherkonto angeben und der verwalteten Identität des Clusterbenutzers die Rolle „Speicherblob-Datenbesitzer“ auf der Azure Data Lake Storage Gen2-Seite zuweisen.
CREATE CATALOG myhive WITH ( 'type' = 'hive' ); USE CATALOG myhive; // ADD jar into environment ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-jdbc-3.1.0-1.17.jar'; ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/mysql-connector-j-8.0.33.jar'; ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/kafka-clients-3.2.0.jar'; ADD JAR 'abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-kafka-1.17.0.jar'; Flink SQL> show jars; ----------------------------------------------------------------------------------------------+ | jars | +----------------------------------------------------------------------------------------------+ | abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-kafka-1.17.0.jar | | abfs://<container>@<storage name>.dfs.core.windows.net/jar/flink-connector-jdbc-3.1.0-1.17.jar | | abfs://<container>@<storage name>.dfs.core.windows.net/jar/kafka-clients-3.2.0.jar | | abfs://<container>@<storage name>.dfs.core.windows.net/jar/mysql-connector-j-8.0.33.jar | +----------------------------------------------------------------------------------------------+ 4 rows in set Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau'; [INFO] Execute statement succeed. Flink SQL> show tables; +----------------------+ | table name | +----------------------+ | flightsintervaldata1 | | kafka_user_orders | | kafkatable | | mysql_user_orders | | orders | +----------------------+ 5 rows in set // mysql cdc table Flink SQL> select * from mysql_user_orders; +----+-------------+----------------------------+-------------+--------------------------------+--------------+-------------+--------------+ | op | order_id | order_date | customer_id | customer_name | price | product_id | order_status | +----+-------------+----------------------------+-------------+--------------------------------+--------------+-------------+--------------+ | +I | 10001 | 2023-07-16 10:08:22.000000 | 1 | Jark | 50.00000 | 102 | FALSE | | +I | 10002 | 2023-07-16 10:11:09.000000 | 2 | Sally | 15.00000 | 105 | FALSE | | +I | 10003 | 2023-07-16 10:11:09.000000 | 3 | Sally | 25.00000 |


Verweis
Apache Flink® Command-Line Interface (CLI) in HDInsight auf AKS-Clustern