Hive-Dialekt in Apache Flink®-Clustern auf HDInsight auf AKS
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS Vorschauinformationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage über AskHDInsight mit den entsprechenden Details und folgen Sie uns, um über Azure HDInsight Communityauf dem Laufenden zu bleiben.
In diesem Artikel erfahren Sie, wie Sie den Hive-Dialekt in Apache Flink-Clustern auf HDInsight auf AKS verwenden.
Einleitung
Der Benutzer kann den Standard-flink-Dialekt nicht in den Hive-Dialekt für deren Verwendung in HDInsight auf AKS-Clustern ändern. Alle SQL-Vorgänge schlagen fehl, sobald sie in den Hive-Dialekt geändert werden, wobei der folgende Fehler auftritt.
*java.lang.ClassCastException: class jdk.internal.loader.ClassLoaders$AppClassLoader can't be cast to class java.net.URLClassLoader*
Der Grund für dieses Problem liegt an einer offenen Hive Jira. Derzeit geht Hive davon aus, dass das Systemklassenladeprogramm eine Instanz von URLClassLoader ist. In Java 11ist diese Annahme nicht der Fall.
So verwenden Sie den Hive-Dialekt in Flink
Führen Sie die folgenden Schritte in websshaus:
- Entfernen Sie den vorhandenen flink-sql-connector-hive*jar im lib-Verzeichnis.
rm /opt/flink-webssh/lib/flink-sql-connector-hive*jar - Laden Sie den folgenden Jar in
websshPod herunter, und fügen Sie es unter dem /opt/flink-webssh/lib wget https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner-loader/1.17.0hinzu. (Das obige "Hive Jar" hat den Fix https://issues.apache.org/jira/browse/HIVE-27508)
mv /opt/flink-webssh/lib/flink-table-planner-loader-1.17.0-*.*.*.*.jar /opt/flink-webssh/opt/ mv /opt/flink-webssh/opt/flink-table-planner_2.12-1.17.0-*.*.*.*.jar /opt/flink-webssh/lib/- Fügen Sie die folgenden Schlüssel in der Konfigurationsverwaltung
flinkim Abschnitt core-site.xml hinzu:fs.azure.account.key.<STORAGE>.dfs.core.windows.net: <KEY> flink.hadoop.fs.azure.account.key.<STORAGE>.dfs.core.windows.net: <KEY>
- Entfernen Sie den vorhandenen flink-sql-connector-hive*jar im lib-Verzeichnis.
Hier ist eine Übersicht über Hive-Dialekt-Abfragen
- Ausführen des Hive-Dialekts in Flink ohne Partitionierung
root [ ~ ]# ./bin/sql-client.sh Flink SQL> Flink SQL> create catalog myhive with ('type' = 'hive', 'hive-conf-dir' = '/opt/hive-conf'); [INFO] Execute statement succeed. Flink SQL> use catalog myhive; [INFO] Execute statement succeed. Flink SQL> load module hive; [INFO] Execute statement succeed. Flink SQL> use modules hive,core; [INFO] Execute statement succeed. Flink SQL> set table.sql-dialect=hive; [INFO] Session property has been set. Flink SQL> set sql-client.execution.result-mode=tableau; [INFO] Session property has been set. Flink SQL> select explode(array(1,2,3));Hive Session ID = 6ba45be2-360e-4bee-8842-2765c91581c8 > [!WARNING] > An illegal reflective access operation has occurred > [!WARNING] > Illegal reflective access by org.apache.hadoop.hive.common.StringInternUtils (file:/opt/flink-webssh/lib/flink-sql-connector-hive-3.1.2_2.12-1.16-SNAPSHOT.jar) to field java.net.URI.string > [!WARNING] > Please consider reporting this to the maintainers of org.apache.hadoop.hive.common.StringInternUtils > [!WARNING] > `Use --illegal-access=warn` to enable warnings of further illegal reflective access operations > [!WARNING] > All illegal access operations will be denied in a future release select explode(array(1,2,3)); +----+-------------+ | op | col | +----+-------------+ | +I | 1 | | +I | 2 | | +I | 3 | +----+-------------+ Received a total of 3 rows Flink SQL> create table tttestHive Session ID = fb8b652a-8dad-4781-8384-0694dc16e837 [INFO] Execute statement succeed. Flink SQL> insert into table tttestHive Session ID = f239dc6f-4b58-49f9-ad02-4c73673737d8),(3,'c'),(4,'d'); [INFO] Submitting SQL update statement to the cluster... [INFO] SQL update statement has been successfully submitted to the cluster: Job ID: d0542da4c4252f9494298666ff4e9f8e Flink SQL> set execution.runtime-mode=batch; [INFO] Session property has been set. Flink SQL> select * from tttestHive Session ID = 61b6eb3b-90a6-499c-aced-0598366c5b31 +-----+-------+ | key | value | +-----+-------+ | 1 | a | | 1 | a | | 2 | b | | 3 | c | | 3 | c | | 3 | c | | 4 | d | | 5 | e | +-----+-------+ 8 rows in set Flink SQL> QUIT;Hive Session ID = 2dadad92-436e-426e-a88c-66eafd740d98 [INFO] Exiting Flink SQL CLI Client... Shutting down the session... done. root [ ~ ]# exitDie Daten werden im gleichen Container gespeichert, der im Hive-/Warehouse-Verzeichnis konfiguriert ist.
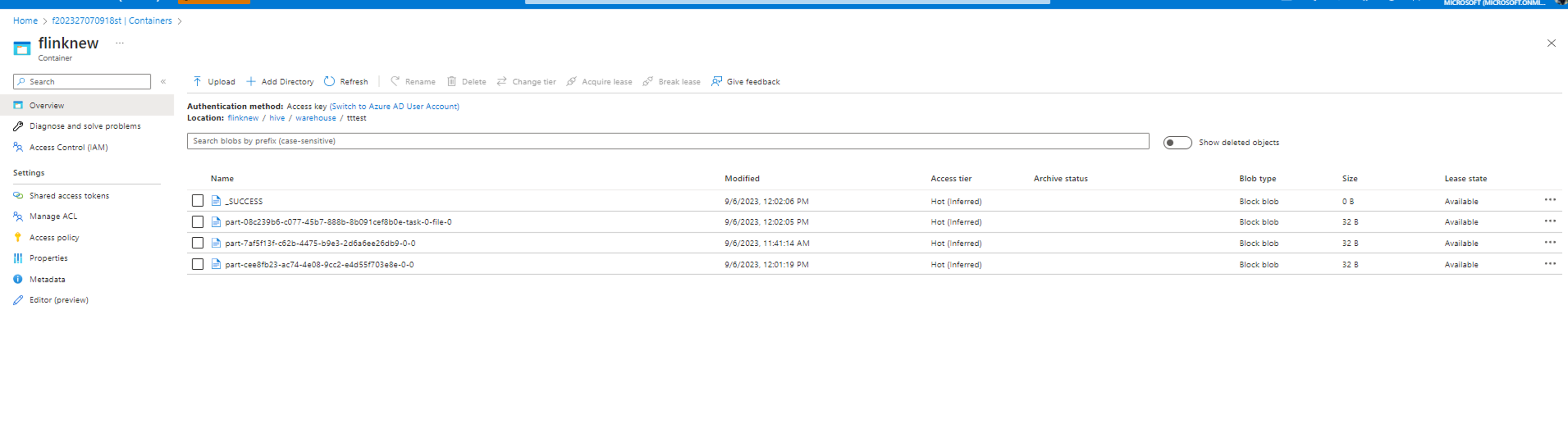
- Ausführen des Hive-Dialekts in Flink mit Partitionen

create table tblpart2 (key int, value string) PARTITIONED by ( part string ) tblproperties ('sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
insert into table tblpart2 Hive Session ID = 78fae85f-a451-4110-bea6-4aa1c172e282),(2,'b','d'),(3,'c','d'),(3,'c','a'),(4,'d','e');


Referenz
- Hive Dialekt in Apache Flink
- Apache, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).