Tabellen-API und SQL in Apache Flink-Clustern® auf HDInsight auf AKS
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr über durch diese Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage an AskHDInsight mit den Details und folgen Sie uns, um weitere Updates zu erhalten von Azure HDInsight Community.
Apache Flink verfügt über zwei relationale APIs – die Tabellen-API und SQL – für die einheitliche Datenstrom- und Batchverarbeitung. Die Tabellen-API ist eine sprachintegrale Abfrage-API, die die Komposition von Abfragen aus relationalen Operatoren wie Auswahl, Filter und intuitive Verknüpfung ermöglicht. Die SQL-Unterstützung von Flink basiert auf Apache Calcite, das den SQL-Standard implementiert.
Die Tabellen-API und SQL-Schnittstellen integrieren sich nahtlos ineinander und die DataStream-API von Flink. Sie können ganz einfach zwischen allen APIs und Bibliotheken wechseln, die darauf aufbauen.
Apache Flink SQL
Wie andere SQL-Engines werden Flink-Abfragen über Tabellen ausgeführt. Es unterscheidet sich von einer herkömmlichen Datenbank, da Flink keine ruhenden Daten lokal verwaltet. Stattdessen werden die Abfragen kontinuierlich über externe Tabellen ausgeführt.
Flink-Datenverarbeitungspipelines beginnen mit Quelltabellen und enden mit Sinktabellen. Quelltabellen erzeugen Zeilen, die während der Abfrageausführung verarbeitet werden; sie sind die Tabellen, auf die in der FROM Klausel einer Abfrage verwiesen wird. Connectors können vom Typ HDInsight Kafka, HDInsight HBase, Azure Event Hubs, Datenbanken, Dateisysteme oder ein anderes System sein, dessen Connector sich im Klassenpfad befindet.
Verwenden des Flink SQL-Clients in HDInsight auf AKS-Clustern
In diesem Artikel erfahren Sie, wie Sie CLI über Secure Shell im Azure-Portal verwenden. Hier finden Sie einige kurze Beispiele für die ersten Schritte.
So starten Sie den SQL-Client
./bin/sql-client.shSo übergeben Sie eine SQL-Initialisierungsdatei, die zusammen mit sql-client ausgeführt werden soll
./sql-client.sh -i /path/to/init_file.sqlSo legen Sie eine Konfiguration in sql-client fest
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL unterstützt die folgenden CREATE-Anweisungen.
- TABELLE ERSTELLEN
- DATENBANK ERSTELLEN
- KATALOG ERSTELLEN
Im Folgenden sehen Sie eine Beispielsyntax zum Definieren einer Quelltabelle mithilfe eines JDBC-Connectors, um eine Verbindung mit MSSQL herzustellen, mit den Spalten id und name in einer CREATE TABLE-Anweisung.
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE:
CREATE DATABASE students;
CREATE CATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
Sie können fortlaufende Abfragen oben in diesen Tabellen ausführen.
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Schreiben Sie in Senktabelle von Quelltabelle:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Hinzufügen von Abhängigkeiten
JAR-Anweisungen werden verwendet, um Benutzer-JARs zum Klassenpfad hinzuzufügen, Benutzer-JARs aus dem Klassenpfad zu entfernen oder hinzugefügte JARs während der Laufzeit im Klassenpfad anzuzeigen.
Flink SQL unterstützt die folgenden JAR-Anweisungen:
- ADD JAR
- JARS ANZEIGEN
- JAR ENTFERNEN
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Hive-Metastore in Apache-Flink-Clustern auf HDInsight auf AKS
Kataloge stellen Metadaten bereit, z. B. Datenbanken, Tabellen, Partitionen, Ansichten und Funktionen und Informationen, die für den Zugriff auf in einer Datenbank oder anderen externen Systemen gespeicherte Daten erforderlich sind.
In HDInsight auf AKS unterstützt Flink zwei Katalogoptionen:
GenericInMemoryCatalog
Die GenericInMemoryCatalog ist eine Speicherimplementierung eines Katalogs. Alle Objekte sind nur für die Lebensdauer der SQL-Sitzung verfügbar.
HiveCatalog
Die HiveCatalog- dient zwei Zwecken; als beständiger Speicher für reine Flink-Metadaten und als Schnittstelle zum Lesen und Schreiben vorhandener Hive-Metadaten.
Anmerkung
HDInsight auf AKS-Clustern verfügt über eine integrierte Option von Hive Metastore für Apache Flink. Sie können sich für den Hive-Metastore während der Clustererstellung entscheiden.
Wie man Flink-Datenbanken in Datenkataloge erstellt und registriert
In diesem Artikel erfahren Sie, wie Sie CLI verwenden und mit dem Flink SQL-Client von Secure Shell im Azure-Portal beginnen.
Sitzung
sql-client.shstarten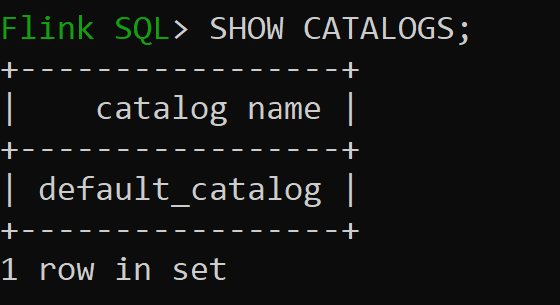
Default_catalog ist der Standardmäßige Speicherkatalog
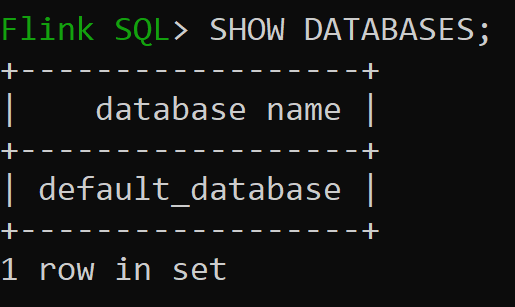
Lassen Sie uns jetzt die Standarddatenbank des Speicherkatalogs überprüfen
Lassen Sie uns den Hive-Katalog von Version 3.1.2 erstellen und verwenden.
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Anmerkung
HDInsight auf AKS unterstützt Hive 3.1.2 und Hadoop 3.3.2. Die
hive-conf-dirist auf den Standort/opt/hive-conffestgelegt.Lassen Sie uns eine Datenbank im Hive-Katalog erstellen und als Standard für die Sitzung festlegen, es sei denn, sie wird geändert.
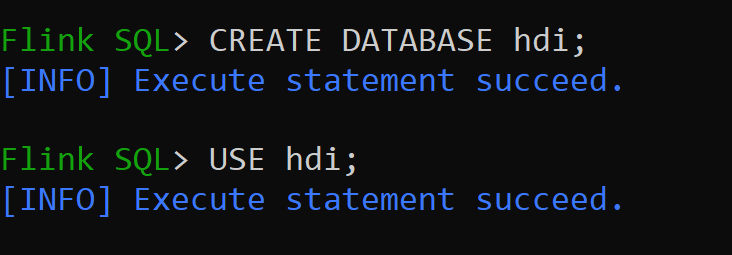
Erstellen und Registrieren von Hive-Tabellen zum Hive-Katalog
Folgen Sie den Anweisungen in zur Erstellung und Registrierung von Flink-Datenbanken im Katalog.
Lassen Sie uns eine Flink-Tabelle vom Verbindungstyp "Hive" ohne Partition erstellen.
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Daten in hive_table einfügen
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Lesen von Daten aus der "hive_table"
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsAnmerkung
Hive Warehouse Directory befindet sich im festgelegten Container des während der Apache Flink-Cluster-Erstellung ausgewählten Speicherkontos, unter dem Verzeichnis hive/warehouse/ zu finden.
Lasst uns eine Flink-Tabelle vom Verbindertyp Hive mit Partition erstellen.
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Wichtig
Es gibt eine bekannte Einschränkung in Apache Flink. Die letzten 'n'-Spalten werden für Partitionen ausgewählt, unabhängig von der benutzerdefinierten Partitionsspalte. FLINK-32596 Der Partitionsschlüssel wird falsch sein, wenn Sie den Flink-Dialekt zum Erstellen einer Hive-Tabelle verwenden.
Referenz
- Apache Flink Table API & SQL
- Apache, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).