Verbindung von Apache Flink® auf HDInsight auf AKS mit Azure Event Hubs für Apache Kafka®
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr über mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage auf AskHDInsight mit den Details und folgen Sie uns, um weitere Updates von Azure HDInsight Communityzu erhalten.
Ein bekannter Anwendungsfall für Apache Flink ist Stream Analytics. Die beliebte Wahl vieler Benutzer, die Datenströme zu verwenden, die mit Apache Kafka aufgenommen werden. Typische Installationen von Flink und Kafka beginnen mit Ereignisströmen, die an Kafka gesendet werden und von Flink-Aufträgen genutzt werden können. Azure Event Hubs stellt einen Apache Kafka-Endpunkt auf einem Event Hub bereit, mit dem Benutzer mithilfe des Kafka-Protokolls eine Verbindung mit dem Event Hub herstellen können.
In diesem Artikel wird erläutert, wie Sie Azure Event Hubs mit Apache Flink auf HDInsight auf AKS verbinden und die folgenden Themen abdecken:
- Erstellen eines Event Hubs-Namespaces
- Erstellen Sie ein HDInsight auf einem AKS-Cluster mit Apache Flink.
- Flink-Produzent ausführen
- Package Jar für Apache Flink
- Validierung der Auftragsabgabe &
Erstellen von Event Hubs-Namespaces und Event Hubs
Um Event Hubs-Namespaces und Event Hubs zu erstellen, siehe hier

Einrichten eines Flink-Clusters auf HDInsight in AKS
Mit vorhandenem HDInsight im AKS-Clusterpool können Sie einen Flink-Cluster erstellen
Führen Sie den Flink-Produzenten aus, der die bootstrap.servers und die
producer.configInformationen hinzufügt.bootstrap.servers={YOUR.EVENTHUBS.FQDN}:9093 client.id=FlinkExampleProducer sasl.mechanism=PLAIN security.protocol=SASL_SSL sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="$ConnectionString" \ password="{YOUR.EVENTHUBS.CONNECTION.STRING}";Ersetzen Sie
{YOUR.EVENTHUBS.CONNECTION.STRING}durch die Verbindungszeichenfolge für den Event Hubs-Namespace. Eine Anleitung zum Abrufen der Verbindungszeichenfolge finden Sie unter den Details zum Abrufen einer Event Hubs-Verbindungszeichenfolge.Zum Beispiel
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="Endpoint=sb://mynamespace.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";
Packen des JAR für Flink
Package com.example.app
package contoso.example; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.io.FileReader; import java.util.Properties; public class AzureEventHubDemo { public static void main(String[] args) throws Exception { // 1. get stream execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); ParameterTool parameters = ParameterTool.fromArgs(args); String input = parameters.get("input"); Properties properties = new Properties(); properties.load(new FileReader(input)); // 2. generate stream input DataStream<String> stream = createStream(env); // 3. sink to eventhub KafkaSink<String> sink = KafkaSink.<String>builder().setKafkaProducerConfig(properties) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("topic1") .setValueSerializationSchema(new SimpleStringSchema()) .build()) .build(); stream.sinkTo(sink); // 4. execute the stream env.execute("Produce message to Azure event hub"); } public static DataStream<String> createStream(StreamExecutionEnvironment env){ return env.generateSequence(0, 200) .map(new MapFunction<Long, String>() { @Override public String map(Long in) { return "FLINK PRODUCE " + in; } }); } }Fügen Sie den Codeausschnitt hinzu, um den Flink Producer auszuführen.
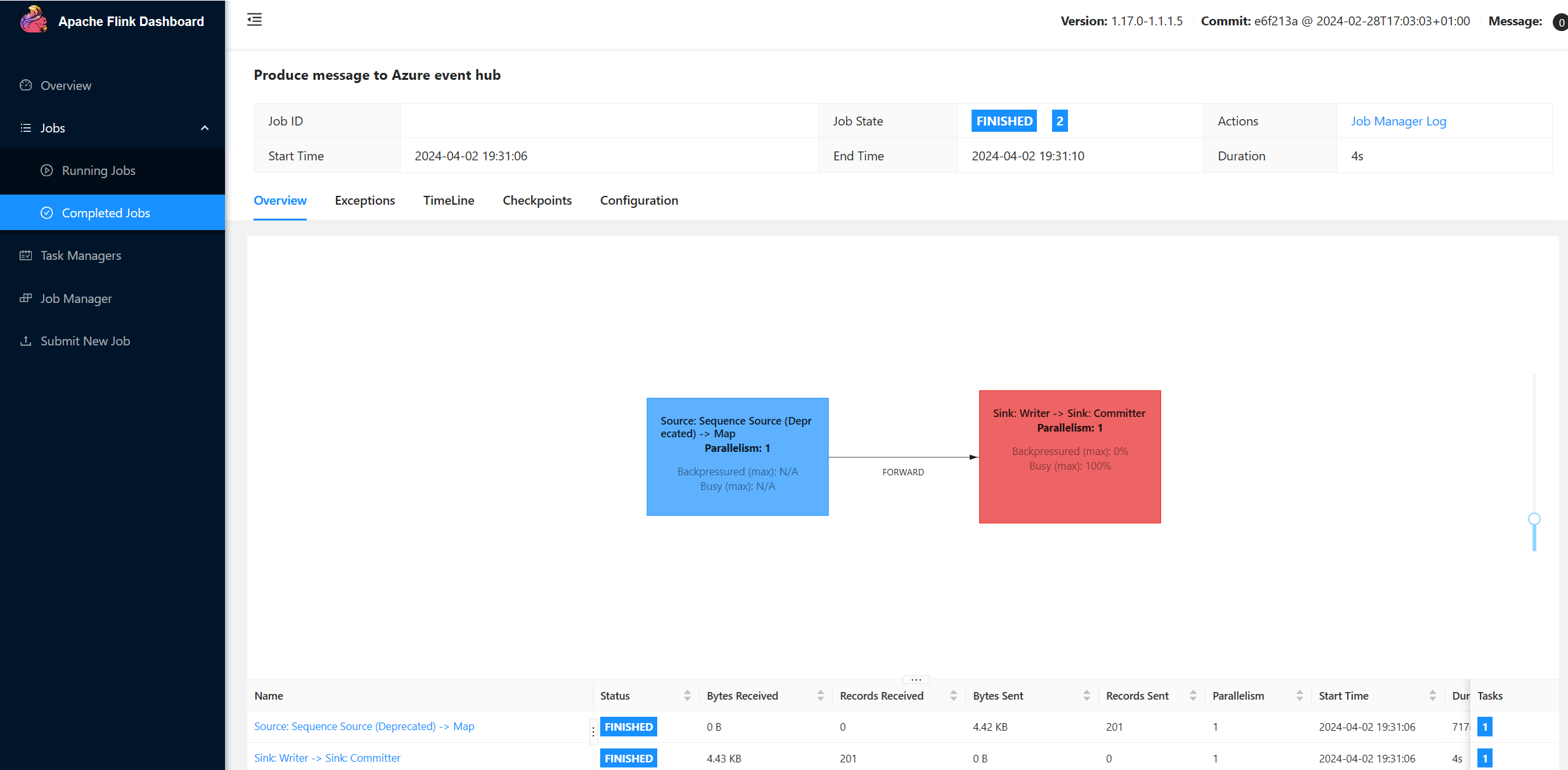
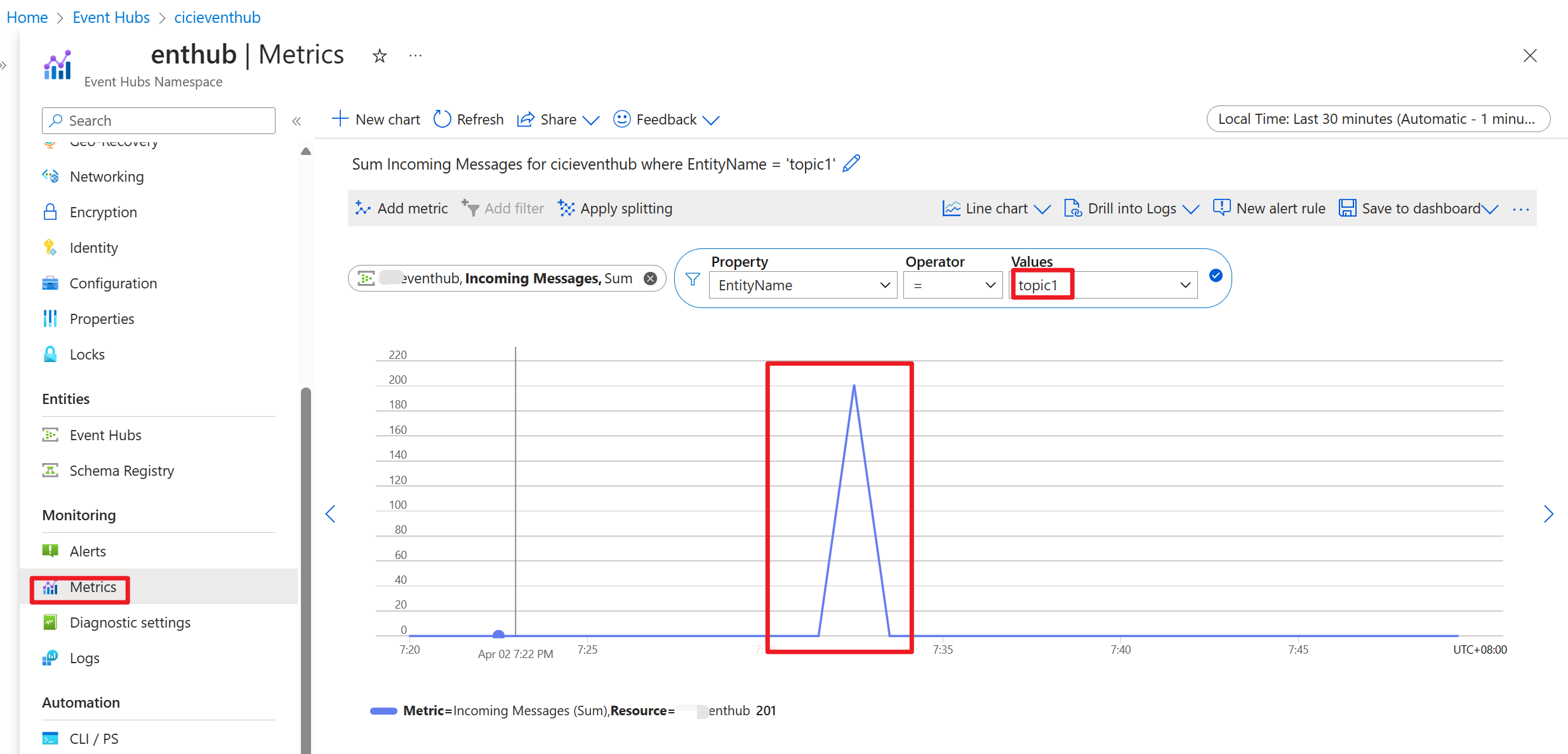
Sobald der Code ausgeführt wird, werden die Ereignisse im Topic "topic1" gespeichert.


Referenz
- Apache Flink Website
- Apache, Apache Kafka, Kafka, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).