Apache Flink® Konfigurationsmanagement in HDInsight auf AKS
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight in AKS Vorschauinformationen. Für Fragen oder Funktionsvorschläge bitten wir Sie darum, eine Anfrage an AskHDInsight mit den Details zu senden und folgen Sie uns für weitere Aktualisierungen auf Azure HDInsight Community.
HDInsight auf AKS bietet eine Reihe von Standardkonfigurationen von Apache Flink für die meisten Eigenschaften und einige basierend auf allgemeinen Anwendungsprofilen. Falls Sie jedoch Flink-Konfigurationseigenschaften optimieren müssen, um die Leistung für bestimmte Anwendungen mit Statusnutzung, Parallelität oder Speichereinstellungen zu verbessern, können Sie die Flink-Auftragskonfiguration mithilfe des Flink Jobs Section in HDInsight im AKS-Cluster ändern.
Wechseln Sie zu "Einstellungen" > "Flink-Aufträge", > Klicken Sie auf "Aktualisieren".
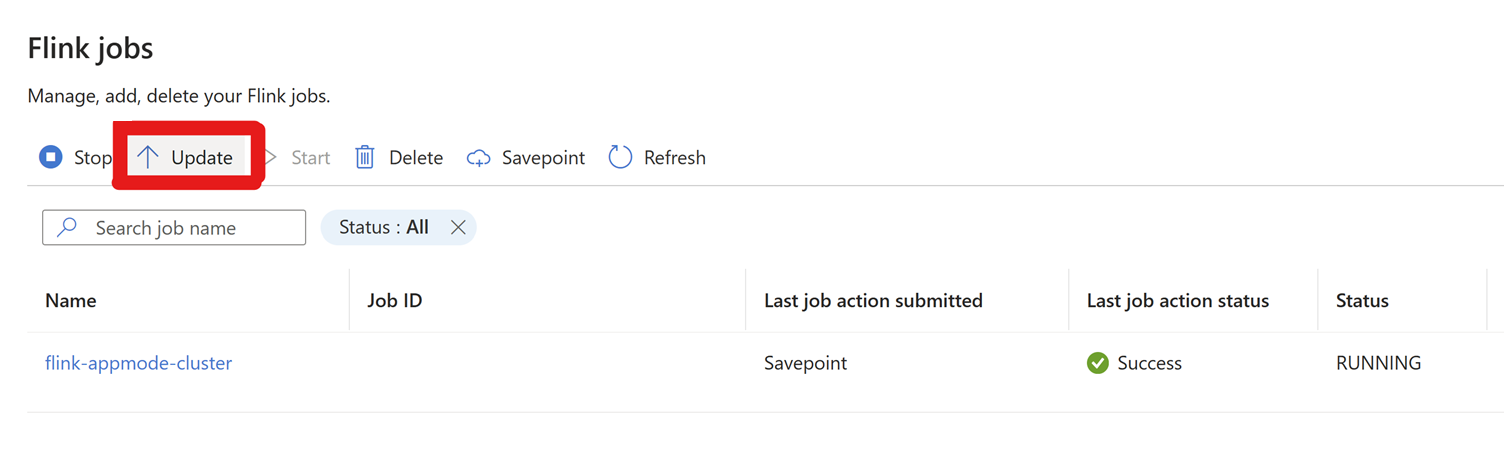
Klicken Sie auf + Zeile hinzufügen, um die Konfiguration zu bearbeiten.
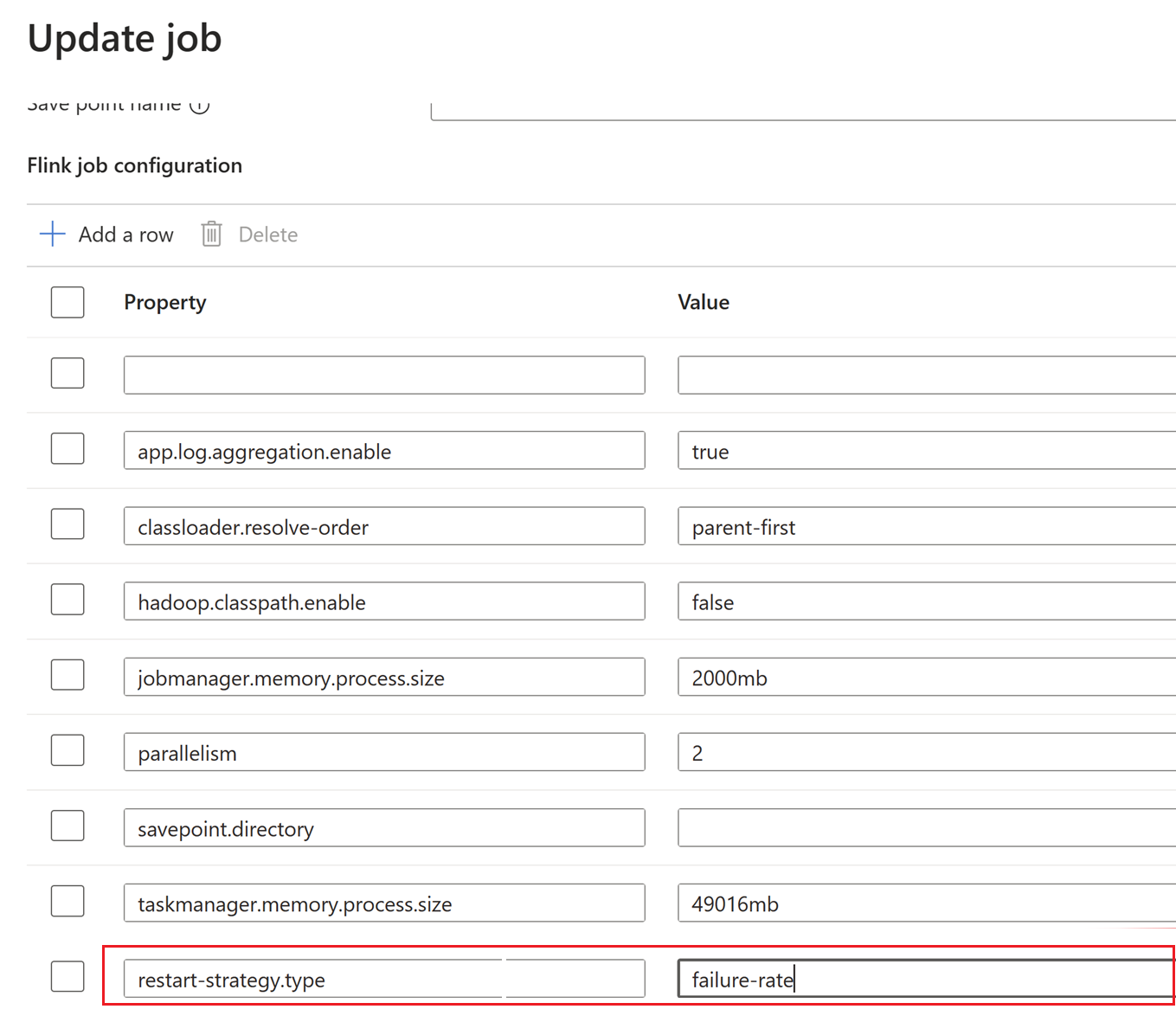
Hier wird das Prüfpunktintervall auf Clusterebenegeändert.
Aktualisieren Sie die Änderungen, indem Sie auf OK- klicken und dann Speichern.
Nach dem Speichern werden die neuen Konfigurationen in einigen Minuten aktualisiert (~5 Minuten).
Konfigurationen, die mithilfe von Konfigurationsverwaltungseinstellungen aktualisiert werden können.
processMemory size:Die Standardeinstellungen für die Größe des Prozessspeichers oder des Auftragsmanagers und des Task-Managers wären der vom Benutzer während der Clustererstellung konfigurierte Speicher.
Diese Größe kann mithilfe der folgenden Konfigurationseigenschaft konfiguriert werden. Verwenden Sie diese Konfiguration, um den Speicher des Task-Managers zu ändern.
taskmanager.memory.process.size : <value>Beispiel:
taskmanager.memory.process.size : 2000mbFür Jobmanager
jobmanager.memory.process.size : <value>Anmerkung
Der maximal konfigurierbare Prozessspeicher entspricht dem für
jobmanager/taskmanagerkonfigurierten Speicher.


Prüfpunktintervall
Das Prüfpunktintervall bestimmt, wie oft Flink einen Prüfpunkt auslöst. Definiert in Millisekunden und kann mithilfe der folgenden Konfigurationseigenschaft festgelegt werden:
execution.checkpoint.interval: <value>
Die Standardeinstellung ist 60.000 Millisekunden (1 Min.), dieser Wert kann wie gewünscht geändert werden.
Zustands-Backend
Das State-Backend bestimmt, wie Flink den Zustand Ihrer Anwendung verwaltet und speichert. Es wirkt sich auf die Speicherung von Prüfpunkten aus. Sie können das Zustandsbackend mit der folgenden Eigenschaft konfigurieren:
state.backend: <value>
Standardmäßig verwenden Apache Flink-Cluster in HDInsight auf AKS Rocks DB.
Speicherpfad des Prüfpunkts
Standardmäßig lassen wir persistente Prüfpunkte zu, indem die Prüfpunkte in abfs Speicher gespeichert werden, wie vom Benutzer konfiguriert. Auch wenn der Job fehlschlägt, da die Checkpoints beibehalten werden, kann er problemlos mit dem neuesten Checkpoint gestartet werden.
state.checkpoints.dir: <path> Ersetzen Sie <path> durch den gewünschten Pfad, in dem die Prüfpunkte gespeichert sind.
Standardmäßig im Vom Benutzer konfigurierten Speicherkonto (ABFS) gespeichert. Dieser Wert kann auf einen beliebigen Pfad geändert werden, solange die Flink-Pods darauf zugreifen können.
Maximale Anzahl gleichzeitiger Prüfpunkte
Sie können die maximale Anzahl gleichzeitiger Prüfpunkte einschränken, indem Sie die folgende Eigenschaft festlegen: checkpoint.max-concurrent-checkpoints: <value>
Ersetzen Sie <value> durch die gewünschte maximale Anzahl gleichzeitiger Prüfpunkte. Beispielsweise 1, um jeweils nur einen Prüfpunkt zuzulassen.
Maximal aufbewahrte Prüfpunkte
Sie können die maximale Anzahl von Prüfpunkten einschränken, die beibehalten werden sollen, indem Sie die folgende Eigenschaft festlegen:
state.checkpoints.num-retained: <value> Ersetzen Sie <value> durch die gewünschte maximale Anzahl. Standardmäßig behalten wir maximal fünf Prüfpunkte bei.
Speicherpfad von Savepoint
Standardmäßig lassen wir persistente Speicherpunkte zu, indem die Speicherpunkte im abfs Speicher gespeichert werden (wie vom Benutzer konfiguriert). Wenn der Benutzer den Job an einem bestimmten Speicherpunkt stoppen und später fortsetzen möchte, kann er diesen Speicherort konfigurieren.
state.checkpoints.dir: <path> Ersetzen Sie <path> durch den gewünschten Pfad, in dem die Speicherpunkte gespeichert sind.
Standardmäßig im Speicherkonto gespeichert, das vom Benutzer konfiguriert ist. (Wir unterstützen ABFS). Dieser Wert kann auf einen beliebigen Pfad geändert werden, solange die Flink-Pods darauf zugreifen können.
Hohe Verfügbarkeit des Job-Managers
In HDInsight auf AKS verwendet Flink Kubernetes als Back-End. Auch wenn der Job-Manager aufgrund eines bekannten oder unbekannten Problems fehlschlägt, wird der Pod innerhalb von Sekunden neu gestartet. Selbst wenn der Auftrag aufgrund dieses Problems neu gestartet wird, wird der Auftrag vom neuesten Prüfpunktwiederhergestellt.
Häufig gestellte Fragen
Warum tritt der Auftragsfehler zwischendurch auf? Auch wenn die Aufträge abrupt fehlschlagen, wenn die Prüfpunkte kontinuierlich ausgeführt werden, wird der Auftrag standardmäßig vom neuesten Prüfpunkt neu gestartet.
Ändern Sie die Jobstrategie dazwischen? Es gibt Anwendungsfälle, in denen der Auftrag während der Produktion aufgrund eines Fehlers auf Auftragsebene geändert werden muss. Während dieser Zeit kann der Benutzer den Auftrag stoppen, wodurch automatisch ein Speicherpunkt erstellt und am Speicherort gespeichert wird.
Klicken Sie auf
savepoint, und warten Sie, bissavepointabgeschlossen ist.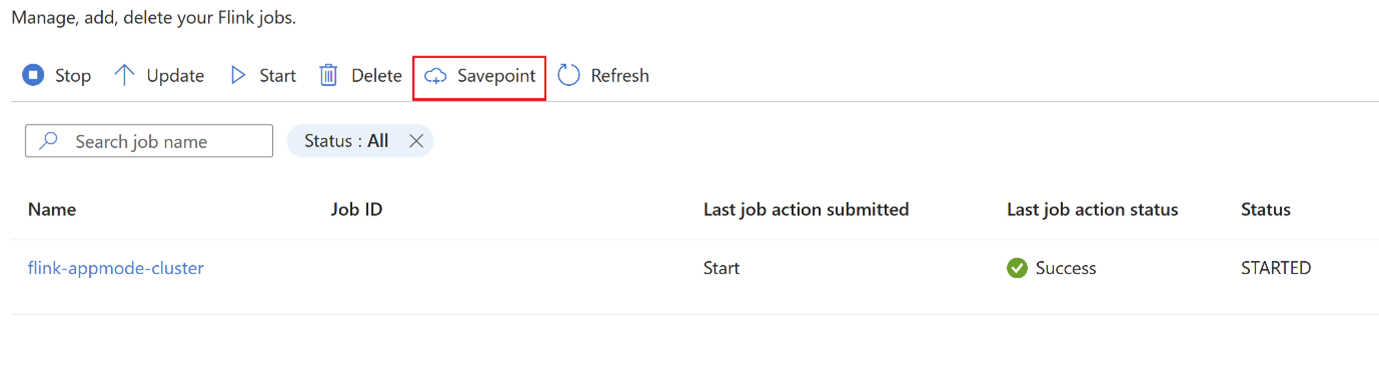
Klicken Sie nach Abschluss des Speicherpunkts auf "Start", und die Registerkarte "Auftrag starten" wird angezeigt. Wählen Sie den Namen des Speicherpunkts aus der Dropdownliste aus. Bearbeiten Sie bei Bedarf konfigurationen. Klicken Sie auf OK.
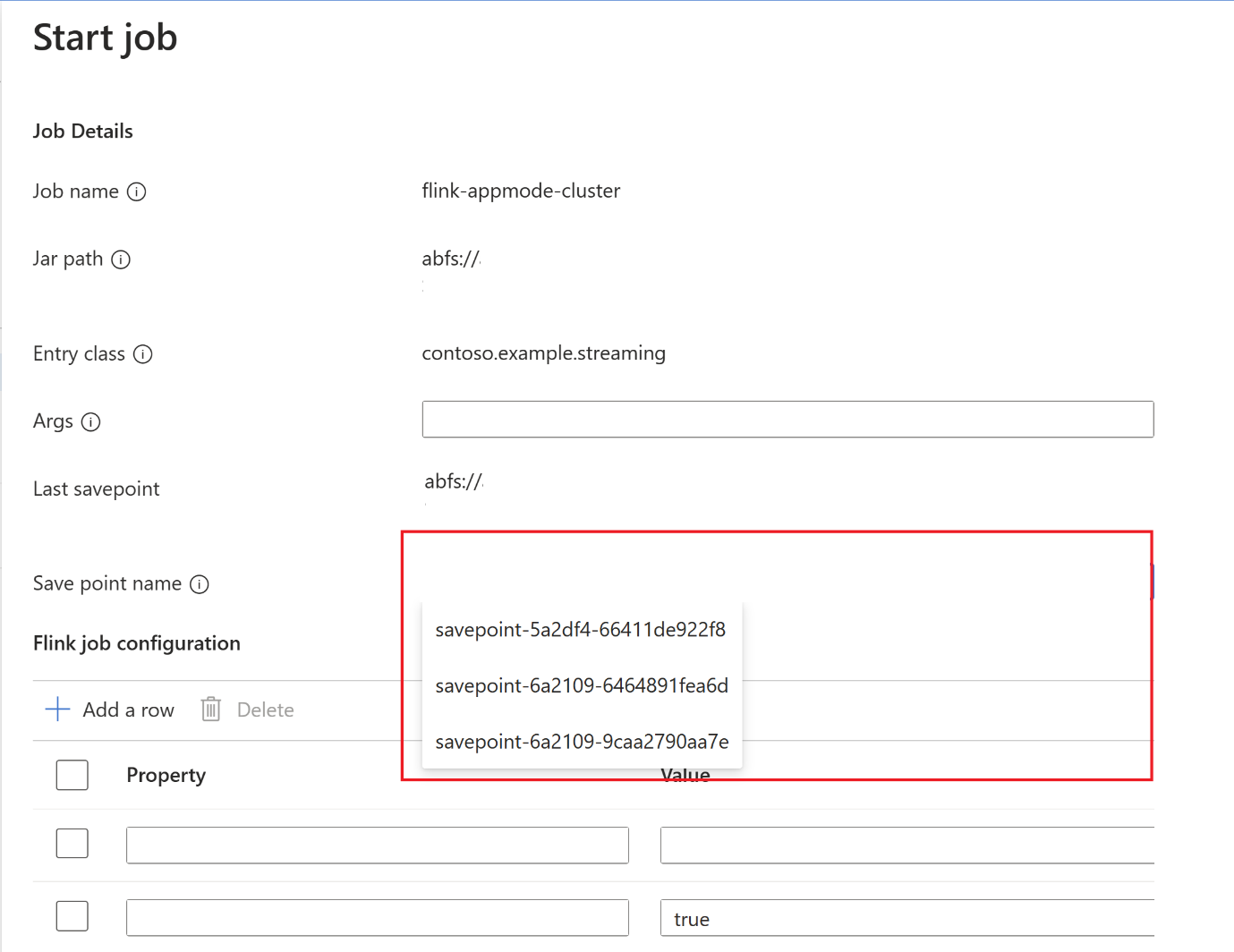


Da ein Speicherpunkt im Auftrag bereitgestellt wird, weiß Flink, wo es mit der Verarbeitung der Daten beginnen soll.
Referenz
- Apache Flink-Konfigurationen
- Apache, Apache Kafka, Kafka, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).