Erstellen einer Apache Kafka®-Tabelle auf Apache Flink® unter Verwendung von HDInsight auf AKS.
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr darüber in dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Funktionsvorschläge reichen Sie bitte eine Anfrage ein über AskHDInsight mit den Details und folgen Sie uns für weitere Updates von Azure HDInsight Community.
In diesem Beispiel erfahren Sie, wie Sie die Kafka-Tabelle auf Apache FlinkSQL erstellen.
Voraussetzungen
- Apache Kafka Cluster auf HDInsight
- Apache Flink-Cluster auf HDInsight auf AKS (Azure Kubernetes Service)
Kafka SQL Connector auf Apache Flink
Der Kafka-Connector ermöglicht das Lesen und Schreiben von Daten in Kafka-Themen. Weitere Informationen finden Sie unter Apache Kafka SQL Connector.
Erstellen einer Kafka-Tabelle in Flink SQL
Themen und Daten auf HDInsight Kafka vorbereiten
Vorbereiten von Nachrichten mit weblog.py
import random
import json
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://google.com',
'https://facebook.com?id=1',
'https://tmall.com',
'https://baidu.com',
'https://taobao.com',
'https://aliyun.com',
'https://apache.com',
'https://flink.apache.com',
'https://hbase.apache.com',
'https://github.com',
'https://gmail.com',
'https://stackoverflow.com',
'https://python.org'
]
def main():
while True:
if random.randrange(10) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
Pipeline zu Kafka-Thema
sshuser@hn0-contsk:~$ python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Andere Befehle:
-- create topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- consume topic
sshuser@hn0-contsk:~$ /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Tom", "visitURL": "https://stackoverflow.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Chunck", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Chunck", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Andrew", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Pick", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Mike", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Zheng Hu", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Luke", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:44"}
Apache Flink SQL-Client
Ausführliche Anweisungen zur Nutzung von Secure Shell für Flink SQL-Client.
Herunterladen der Kafka-SQL-Connector-&-Abhängigkeiten über SSH
Wir verwenden die Kafka 3.2.0 Abhängigkeiten im folgenden Schritt. Sie müssen den Befehl basierend auf Ihrer Kafka-Version im HDInsight-Cluster aktualisieren.
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.2.0/kafka-clients-3.2.0.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.17.0/flink-connector-kafka-1.17.0.jar
Herstellen einer Verbindung mit Apache Flink SQL Client
Nun stellen wir eine Verbindung mit dem Flink SQL-Client mit Kafka SQL-Client-Jars her.
msdata@pod-0 [ /opt/flink-webssh ]$ bin/sql-client.sh -j flink-connector-kafka-1.17.0.jar -j kafka-clients-3.2.0.jar
Kafka-Tabelle in Apache Flink SQL erstellen
Erstellen wir nun die Kafka-Tabelle in Flink SQL, und wählen Sie die Kafka-Tabelle in Flink SQL aus.
Sie müssen Ihre Kafka-Bootstrap-Server-IPs im folgenden Codeausschnitt aktualisieren.
CREATE TABLE KafkaTable (
`userName` STRING,
`visitURL` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'click_events',
'properties.bootstrap.servers' = '<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092',
'properties.group.id' = 'my_group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
select * from KafkaTable;
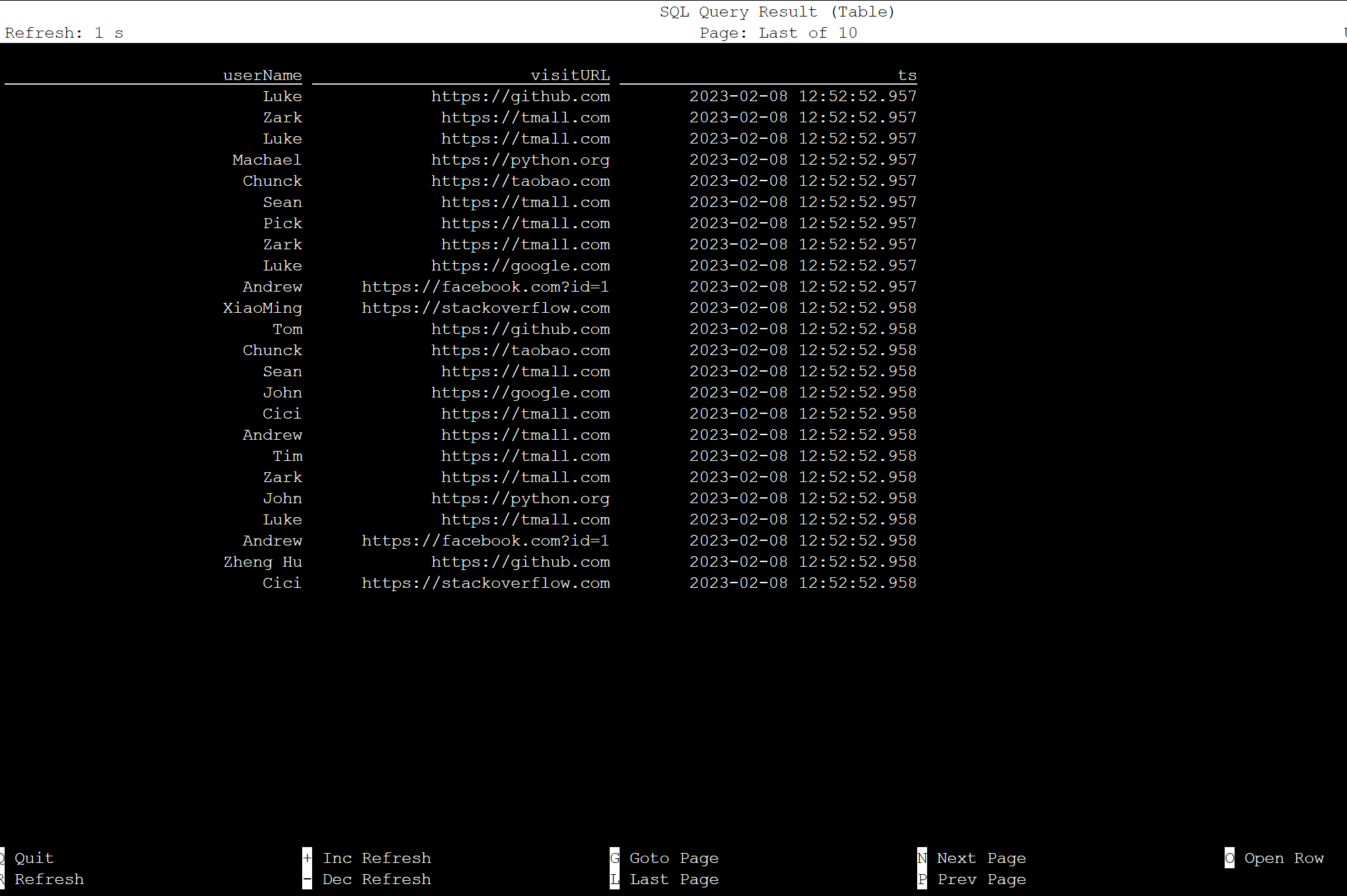
Erstellen von Kafka-Nachrichten
Lassen Sie uns nun Kafka-Nachrichten zum gleichen Thema mithilfe von HDInsight Kafka erstellen.
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
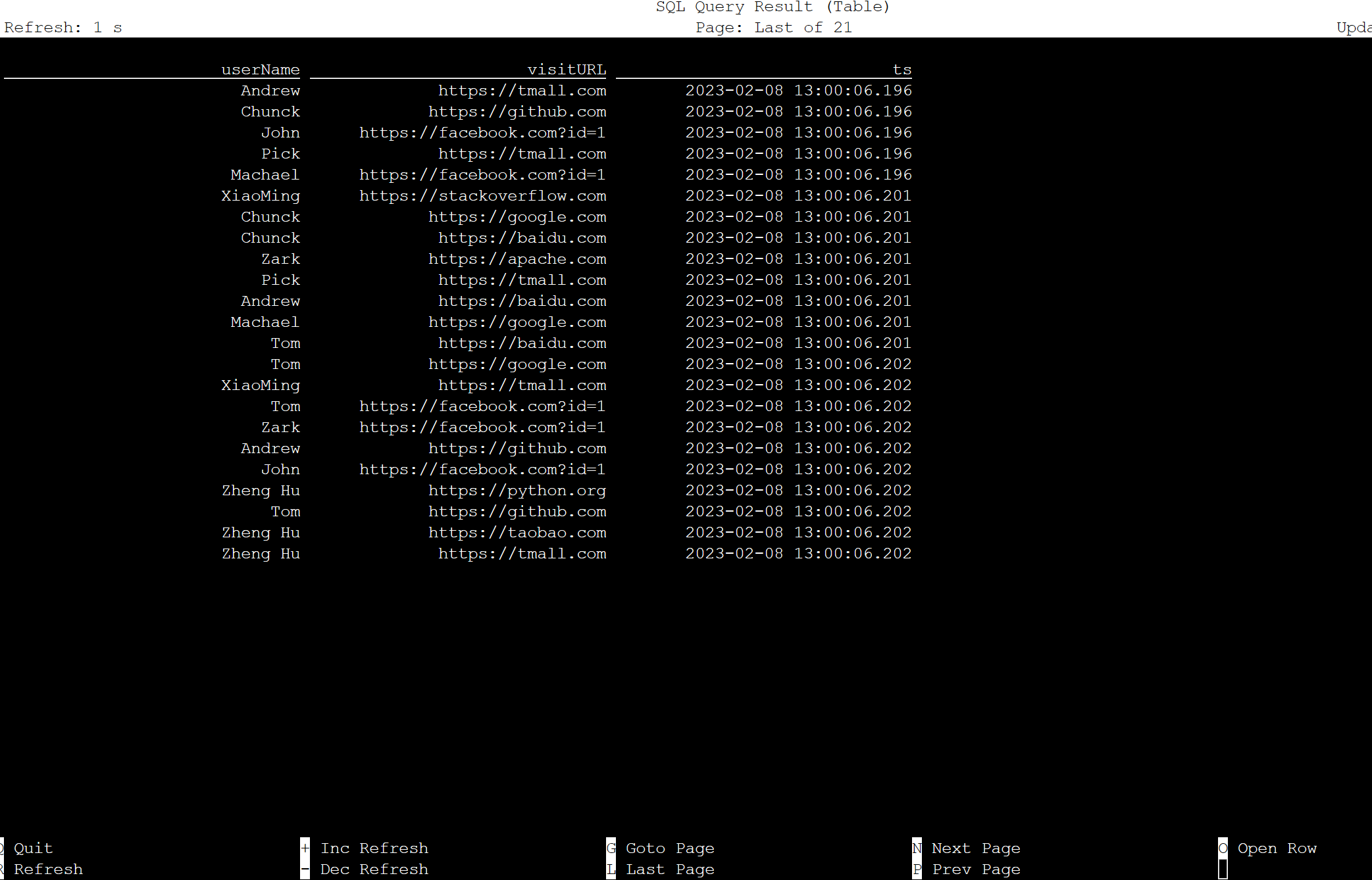
Tabelle für Apache Flink SQL
Sie können die Tabelle in Flink SQL überwachen.
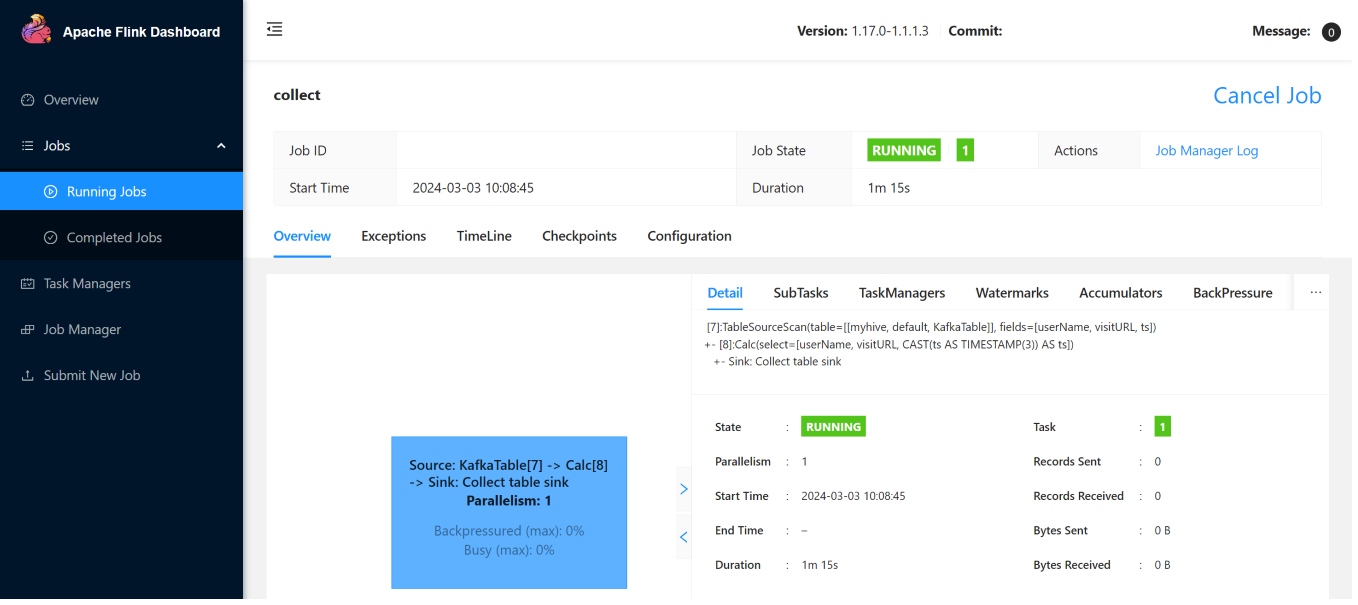
Hier sind die Streamingaufträge auf der Flink Web UI.
Referenz
- Apache Kafka SQL Connector
- Apache, Apache Kafka, Kafka, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).