Apache Flink-Anwendungsmoduscluster in HDInsight on AKS
Hinweis
Azure HDInsight on AKS wird am 31. Januar 2025 eingestellt. Vor dem 31. Januar 2025 müssen Sie Ihre Workloads zu Microsoft Fabric oder einem gleichwertigen Azure-Produkt migrieren, um eine abruptes Beendigung Ihrer Workloads zu vermeiden. Die verbleibenden Cluster in Ihrem Abonnement werden beendet und vom Host entfernt.
Bis zum Einstellungsdatum ist nur grundlegende Unterstützung verfügbar.
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bestimmungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight on AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
HDInsight on AKS bietet jetzt einen Flink-Anwendungsmoduscluster. Mit diesem Cluster können Sie den Lebenszyklus des Cluster-Flink-Anwendungsmodus mithilfe des Microsoft Azure-Portals mit einer benutzerfreundlichen Schnittstelle und Azure Resource Management REST-APIs verwalten. Cluster im Anwendungsmodus sind für die Unterstützung großer und lang laufender Aufträge mit dedizierten Ressourcen und für ressourcenintensive oder umfangreiche Datenverarbeitungsaufgaben konzipiert.
In diesem Bereitstellungsmodus können Sie bestimmten Flink-Anwendungen dedizierte Ressourcen zuweisen, damit sichergestellt ist, dass sie über genügend Rechenleistung und Arbeitsspeicher verfügen, um große Workloads effizient verarbeiten zu können.

Vorteile
Vereinfachte Clusterbereitstellung mit Job-Jar.
Benutzerfreundliche REST-API: HDInsight on AKS bietet benutzerfreundliche ARM Rest-APIs zum Verwalten von App-Modus-Auftragsvorgängen wie Aktualisieren, Sicherungspunkt, Abbrechen, Löschen.
Einfach zu verwaltende Auftragsaktualisierungen und Zustandsverwaltung: Die systemeigene Integration in das Microsoft Azure-Portal bietet eine problemlose Erfahrung zum Aktualisieren von Aufträgen und zum Wiederherstellen des letzten gespeicherten Zustands (Sicherungspunkt). Diese Funktionalität stellt die Kontinuität und Datenintegrität während des gesamten Auftragslebenszyklus sicher.
Automatisieren Sie Flink-Aufträge mithilfe von Azure Pipelines oder anderen CI/CD-Tools: Mithilfe von HDInsight on AKS haben Flink-Benutzer und -Benutzerinnen Zugriff auf eine benutzerfreundliche ARM-Rest-API. Sie können Flink-Auftragsvorgänge nahtlos in Ihre Azure-Pipeline oder andere CI/CD-Tools integrieren.
Schlüsselfunktionen
Beenden und Starten von Aufträgen mit Sicherungspunkten: Benutzer und Benutzerinnen können ihre Flink-AppMode-Aufträge ordnungsgemäß beenden und von ihrem vorherigen Status (Sicherungspunkt) starten. Savepoints stellen sicher, dass der Auftragsfortschritt erhalten bleibt, sodass nahtlose Wiederaufnahme möglich ist.
Auftragsaktualisierungen: Benutzer und Benutzerinnen können den gerade laufenden AppMode-Auftrag nach der Aktualisierung der Jar-Datei im Speicherkonto aktualisieren. Bei diesem Update wird der Sicherungspunkt automatisch übernommen und der AppMode-Auftrag mit einer neuen Jar-Datei gestartet.
Zustandslose Updates: Die Durchführung eines Neustarts für einen AppMode-Auftrag wird durch zustandslose Updates vereinfacht. Mit dieser Funktion können Benutzer einen sauberen Neustart mit aktualisierten Auftrags-Jar initiieren.
Sicherungspunktverwaltung: Benutzer und Benutzerinnen können jederzeit Sicherungspunkte für ihre laufenden Aufträge erstellen. Diese Sicherungspunkte können aufgelistet und verwendet werden, um den Auftrag nach Bedarf von einem bestimmten Prüfpunkt neu zu starten.
Abbrechen: Dadurch wird der Auftrag dauerhaft abgebrochen.
Löschen: AppMode-Cluster löschen.
Gewusst wie: Erstellen eines Flink-Anwendungsclusters
Voraussetzungen
Erfüllen Sie die Voraussetzungen in den folgenden Abschnitten:
Fügen Sie dem Speicherkonto eine Jar-Datei für den Auftrag hinzu.
Bevor Sie einen Flink-Anwendungsmoduscluster einrichten können, müssen Sie mehrere vorbereitende Schritte durchführen. Einer dieser Schritte umfasst das Platzieren der JAR-Datei des Anwendungsmodusauftrags im Speicherkonto des Clusters.
Erstellen Sie ein Verzeichnis für JAR-Datei des Anwendungsmodusauftrags:
Erstellen Sie in den dedizierten Containern ein Verzeichnis, in das Sie die JAR-Datei für den Anwendungsmodusauftrag hochladen. Dieses Verzeichnis dient als Speicherort für die JAR-Dateien, die Sie in den Klassenpfad des Flink-Clusters oder -Auftrags aufnehmen möchten.
Verzeichnis für Sicherungspunkte (optional):
Wenn Benutzer oder Benutzerinnen Sicherungspunkte während der Auftragsausführung übernehmen möchten, erstellen Sie ein separates Verzeichnis innerhalb des Speicherkontos zum Speichern dieser Sicherungspunkte. Dieses Verzeichnis wird zum Speichern von Prüfpunktdaten und Metadaten für Sicherungspunkte verwendet.
Beispielverzeichnisstruktur:
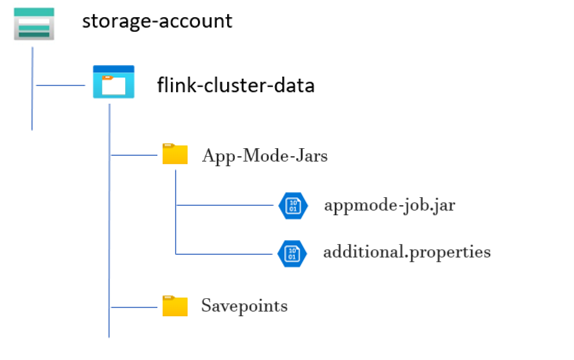

Erstellen eines Flink-Anwendungsmodusclusters
Flink-AppMode-Cluster können erstellt werden, nachdem die Bereitstellung eines Clusterpools abgeschlossen worden ist. Sehen wir uns die Schritte für den Fall an, dass Sie mit einem vorhandenen Clusterpool beginnen.
Geben Sie im Azure-Portal HDInsight-Clusterpools/HDInsight/HDInsight on AKS ein, und wählen Sie Azure HDInsight on AKS-Clusterpools aus, um zur Seite „Clusterpools“ zu navigieren. Wählen Sie auf der Seite „HDInsight on AKS-Clusterpools“ den Clusterpool aus, in dem Sie einen neuen Flink-Cluster erstellen möchten.

Klicken Sie auf der Seite für einen bestimmten Clusterpool auf + Neuer Cluster, und geben Sie die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Abonnement Dieses Feld wird automatisch mit dem Azure-Abonnement ausgefüllt, das für den Clusterpool registriert wurde. Ressourcengruppe Dieses Feld wird automatisch ausgefüllt und zeigt die Ressourcengruppe im Clusterpool an. Region Dieses Feld wird automatisch ausgefüllt und zeigt die für den Clusterpool ausgewählte Ressourcengruppe an. Clusterpool Dieses Feld wird automatisch ausgefüllt und zeigt den Namen des Clusterpools an, in dem der Cluster jetzt erstellt wird. Um einen Cluster in einem anderen Pool zu erstellen, suchen Sie den betreffenden Clusterpool im Portal, und klicken Sie auf „+ Neuer Cluster“. Version des HDInsight on AKS-Pools Dieses Feld wird automatisch ausgefüllt und zeigt die Version des Clusterpools an, in dem der Cluster jetzt erstellt wird. HDInsight on AKS-Version Wählen Sie die Neben- oder Patchversion der HDInsight on AKS-Version des neuen Clusters aus. Clustertyp Wählen Sie in der Dropdownliste „Flink“ aus. Clustername Geben Sie den Namen des neuen Clusters ein. Benutzerseitig zugewiesene verwaltete Identität Wählen Sie in der Dropdownliste die verwaltete Identität aus, die mit dem Cluster verwendet werden soll. Wenn Sie der Besitzer oder die Besitzerin der verwalteten Dienstidentität (Managed Service Identity, MSI) sind und die MSI nicht über die Rolle „Operator für verwaltete Identität“ im Cluster verfügt, klicken Sie auf den Link unterhalb des Felds, um die für die MSI des AKS-Agentpools erforderliche Berechtigung zuzuweisen. Wenn die MSI bereits über die richtigen Berechtigungen verfügt, wird kein Link angezeigt. Weitere Rollenzuweisungen, die für die MSI erforderlich sind, finden Sie unter Voraussetzungen. Speicherkonto Wählen Sie in der Dropdownliste das Speicherkonto aus, das dem Flink-Cluster zugeordnet werden soll, und geben Sie den Containernamen an. Der verwalteten Identität wird außerdem mithilfe der Rolle „Besitzer von Speicherblobdaten“ Zugriff auf das angegebene Speicherkonto gewährt. Virtuelles Netzwerk Das virtuelle Netzwerk für den Cluster. Subnet Das virtuelle Subnetz für den Cluster. Aktivieren des Hive-Katalogs für Flink SQL:
Eigenschaft Beschreibung Hive-Katalog verwenden Aktivieren Sie diese Option, um einen externen Hive-Metastore zu verwenden. SQL-Datenbank für Hive Wählen Sie in der Dropdownliste die SQL-Datenbank-Instanz aus, in der Hive-Metastore-Tabellen hinzugefügt werden sollen. SQL-Administratorbenutzername Geben Sie den SQL Server-Administratorbenutzernamen ein. Dieses Konto wird vom Metastore verwendet, um mit SQL-Datenbank zu kommunizieren. Key Vault (Schlüsseltresor) Wählen Sie in der Dropdownliste die Key Vault-Instanz aus, die ein Geheimnis mit Kennwort für den SQL Server-Administratorbenutzernamen enthält. Sie müssen eine Zugriffsrichtlinie mit allen erforderlichen Berechtigungen wie Schlüsselberechtigungen, Geheimnisberechtigungen und Zertifikatberechtigungen für die MSI einrichten, die für die Clustererstellung verwendet wird. Die MSI erfordert die Rolle „Schlüsseltresoradministrator“. Fügen Sie die erforderlichen Berechtigungen mithilfe von IAM hinzu. Name des geheimen SQL-Kennworts Geben Sie den Geheimnisnamen aus der Key Vault-Instanz ein, in der das Kennwort für SQL-Datenbank gespeichert ist. 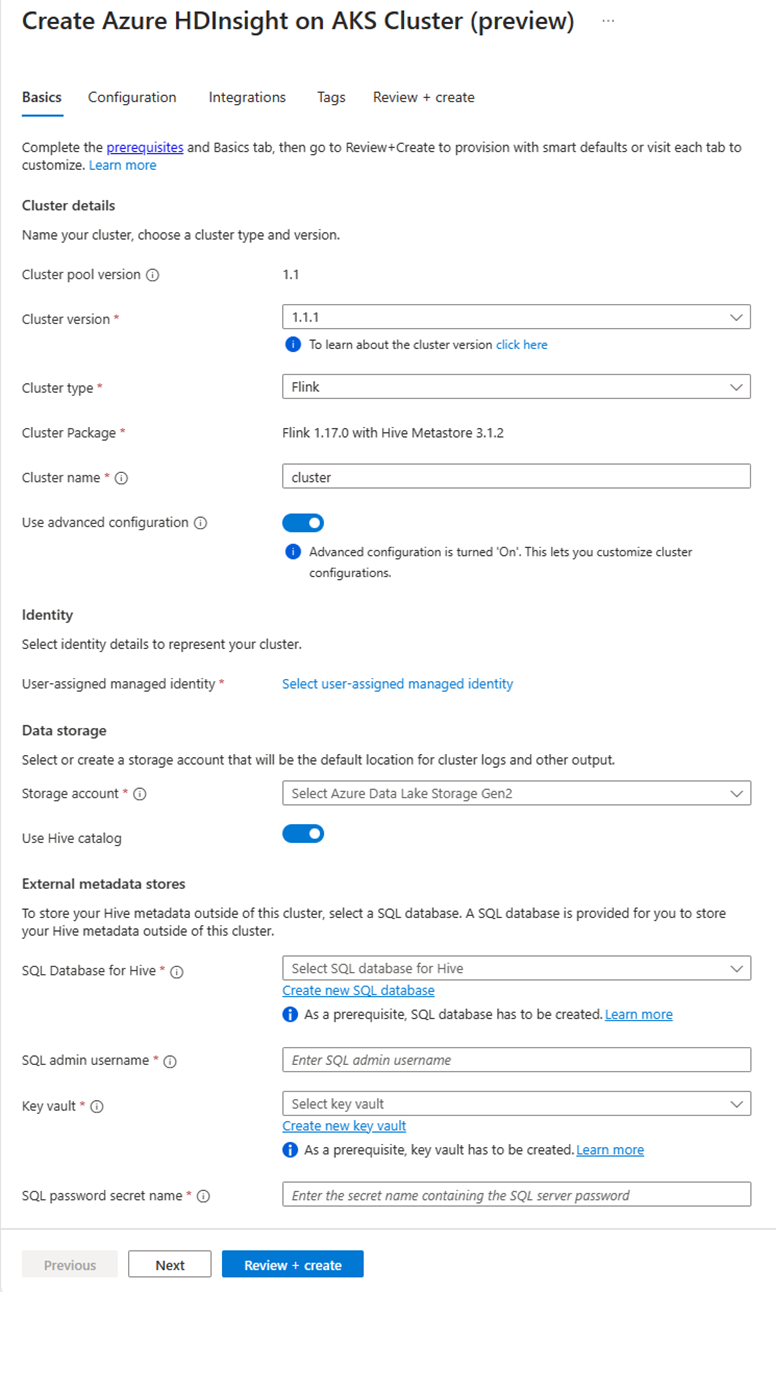
Hinweis
Standardmäßig verwenden wir für den Hive-Katalog dasselbe Speicherkonto und denselben Container, die auch bei der Clustererstellung verwendet wurden.
Klicken Sie auf Weiter: Konfiguration, um fortzufahren.
Geben Sie auf der Seite Konfiguration die folgenden Informationen ein:
Eigenschaft Beschreibung Knotengröße Wählen Sie die Knotengröße aus, die für die Haupt- und Workerknoten der Flink-Knoten verwendet werden soll. Anzahl von Knoten Wählen Sie die Anzahl der Knoten für den Flink-Cluster aus. Standardmäßig sind zwei Hauptknoten festgelegt. Die Größe der Workerknoten hilft bei der Ermittlung der Task-Manager-Konfigurationen für Flink. Der Auftragsmanager und die Verlaufsserver befinden sich auf Hauptknoten. Wählen Sie im Abschnitt „Bereitstellung“ den Bereitstellungstyp Anwendungsmodus aus, und stellen Sie die folgenden Informationen bereit:
Eigenschaft Beschreibung Jar-Pfad Geben Sie dem ABFS-Pfad (Storage) für die Jar-Datei Ihres Auftrags an. Beispiel: abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarEntry-Klasse (optional) Main-Klasse für ihren Anwendungsmoduscluster Beispiel: com.microsoft.testjob Args (Optional) Argument für die main-Klasse Ihres Auftrags. Name des Sicherungspunkts Name des alten Sicherungspunkts, den Sie zum Starten des Auftrags verwenden möchten Upgrademodus Wählen Sie die Standardoption „Upgrade“ aus. Diese Option wird verwendet, wenn für den Cluster ein Upgrade der Hauptversion durchgeführt wird. Es sind drei Optionen verfügbar. UPDATE: Wird verwendet, wenn ein Benutzer oder eine Benutzerin nach dem Upgrade eine Wiederherstellung vom letzten Sicherungspunkt durchführen möchte. STATELESS_UPDATE: Wird verwendet, wenn ein Benutzer oder eine Benutzerin möchte, dass der Auftrag nach dem Upgrade neu gestartet wird. LAST_STATE_UPDATE: Wird verwendet, wenn ein Benutzer oder eine Benutzerin den Auftrag nach dem Upgrade vom letzten Prüfpunkt wiederherstellen möchte. Konfiguration des Flink-Auftrags Fügen Sie weitere Konfiguration hinzu, die für den Flink-Auftrag erforderlich ist. Wählen Sie „Auftragsprotokollaggregation“ aus. Aktivieren Sie das Kontrollkästchen, wenn Sie Ihr Auftragsprotokoll in den Remotespeicher hochladen möchten. Dies erleichtert das Debuggen von Problemen mit dem Auftrag. Der Standardspeicherort für das Auftragsprotokoll lautet „StorageAccount/Container/DeploymentId/logs“. Sie können das Standardprotokollverzeichnis ändern, indem Sie „pipeline.remote.log.dir“ konfigurieren. Das Standardintervall für die Protokollsammlung beträgt 600 Sek. Der Benutzer oder die Benutzerin kann dies ändern, indem er bzw. sie „pipeline.log.aggregation.interval“ konfiguriert.
Geben Sie im Abschnitt Serverkonfiguration die folgenden Informationen ein:
Eigenschaft Beschreibung Task-Manager-CPU Integer. Geben Sie die Größe der Task-Manager-CPUs (in Kernen) ein. Task-Manager-Speicher in MB Geben Sie die Größe des Task-Manager-Speichers in MB ein. Min. 1.800 MB. Auftrags-Manager-CPU Integer. Geben Sie die Anzahl der CPUs für den Auftrags-Manager (in Kernen) ein. Speicher des Auftrags-Managers in MB Geben Sie die Speichergröße in MB an. Min. 1.800 MB. Verlaufsserver-CPU Integer. Geben Sie die Anzahl der CPUs für den Auftrags-Manager (in Kernen) ein. Verlaufsserverspeicher in MB Geben Sie die Speichergröße in MB an. Min. 1.800 MB. 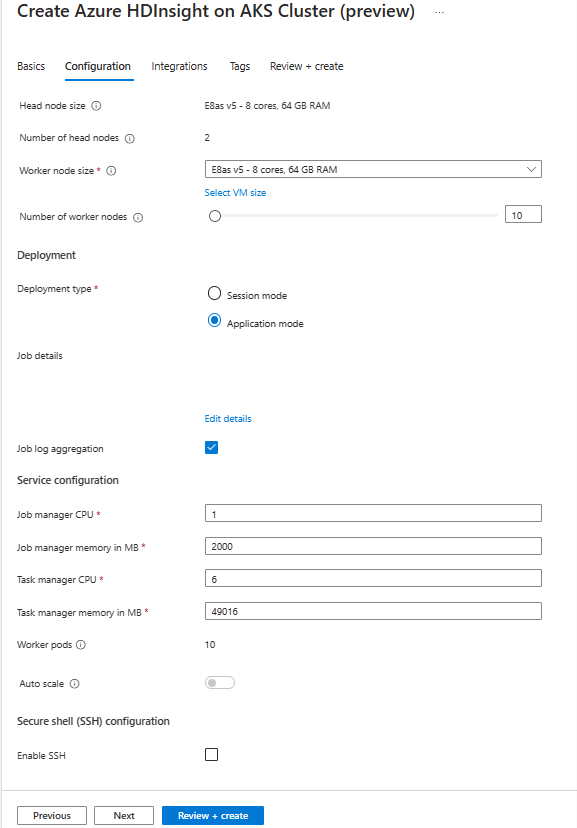
Klicken Sie auf die Schaltfläche „Weiter: Integration“, um auf der nächsten Seite fortzufahren.
Geben Sie auf der Seite Integration die folgenden Informationen ein:
Eigenschaft Beschreibung Log Analytics Dieses Feature ist nur verfügbar, wenn dem Clusterpool ein Log Analytics-Arbeitsbereich zugeordnet ist. Nach der Aktivierung können Sie die Protokolle, die erfasst werden sollen, auswählen. Azure Prometheus Dieses Feature dient dazu, Erkenntnisse und Protokolle direkt im Cluster anzuzeigen, indem Sie Metriken und Protokolle an einen Azure Monitor-Arbeitsbereich senden. 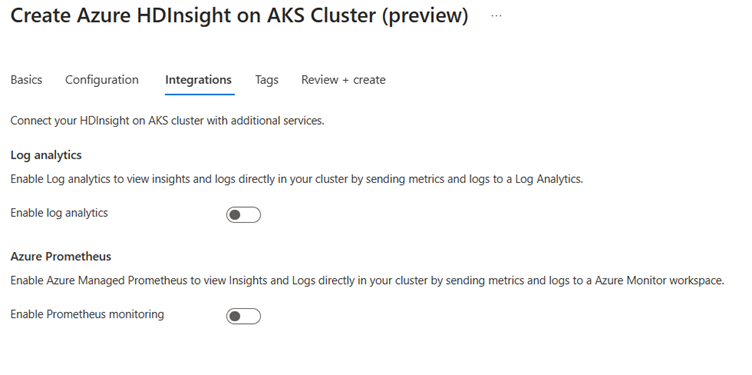
Klicken Sie auf die Schaltfläche Weiter: Tags, um auf der nächsten Seite fortzufahren.
Geben Sie auf der Seite Tags die folgenden Informationen ein:
Eigenschaft Beschreibung Name Optional. Geben Sie einen Namen wie „HDInsight on AKS“ ein, um einfach alle Ressourcen zu identifizieren, die Ihren Clusterressourcen zugeordnet sind. Wert Kann leer bleiben. Ressource Wählen Sie „Alle Ressourcen ausgewählt“ aus. Wählen Sie zum Fortfahren Next. Review + create (Weiter: Überprüfen + erstellen) aus.
Suchen Sie am oberen Seitenrand der Seite „Überprüfen + erstellen“ nach der Meldung Validierung erfolgreich, und klicken Sie dann auf „Erstellen“.




Die Seite „Bereitstellung wird gerade durchgeführt“ wird mit dem Cluster angezeigt, der gerade erstellt wird. Die Erstellung des Clusters dauert fünf bis zehn Minuten. Nachdem der Cluster erstellt wurde, wird die Meldung Ihre Bereitstellung wurde abgeschlossen. angezeigt. Wenn Sie von der Seite weg navigieren, können Sie Ihre Benachrichtigungen auf den aktuellen Status überprüfen.
Verwalten des Anwendungsauftrags über das Portal
HDInsight on AKS bietet Möglichkeiten zum Verwalten von Flink-Aufträgen. Sie können einen fehlgeschlagenen Auftrag neu starten. Starten Sie den Auftrag über das Portal neu.
Um den Flink-Auftrag über das Portal auszuführen, wechseln Sie zu:
Portal > HDInsight on AKS-Clusterpool > Flink-Cluster > Einstellungen > Flink-Aufträge

Stop: Zum Anhalten des Auftrags waren keine Parameter erforderlich. Der Benutzer oder die Benutzerin kann den Auftrag beenden, indem er die Aktion auswählt. Sobald der Auftrag gestoppt wurde, lautet der Auftragsstatus im Portal „STOPPED“.
Start: Startet den Auftrag vom Sicherungspunkt aus. Um den Auftrag zu starten, wählen Sie den gestoppten Auftrag aus, und starten Sie ihn.
Update: Update hilft beim Neustart von Aufträgen mit aktualisiertem Auftragscode. Benutzer müssen die neuesten Auftrags-Jar am Speicherort aktualisieren und den Auftrag über das Portal aktualisieren. Dieses Update stoppt den Auftrag beim Sicherungspunkt und startet ihn erneut mit der neuesten Jar-Datei.
Zustandsloses Update: Ein zustandsloses Update ist wie ein Update, erfordert jedoch einen neuen Neustart des Auftrags mit dem neuesten Code. Sobald der Auftrag aktualisiert worden ist, lautet der Auftragsstatus im Portal Wird ausgeführt.
Sicherungspunkt: Den Sicherungspunkt für den Flink-Auftrag übernehmen.
Abbrechen: Beendet den Auftrag.
Löschen: Löscht den AppMode-Cluster.
Auftragsdetails anzeigen: Um die Auftragsdetails anzuzeigen, kann der Benutzer oder die Benutzerin auf den Auftragsnamen klicken. Daraufhin werden Details zum Auftrag und zum letzten Aktionsergebnis angezeigt.


Bei fehlgeschlagenen Aktionen enthält diese JSON-Ansicht detaillierte Ausnahmen und Gründe für den Fehler.