Erhalten von Azure-Empfehlungen zum Migrieren Ihrer SQL Server-Datenbank
Die Azure SQL-Migrationserweiterung für Azure Data Studio hilft Ihnen dabei, Ihre Datenbankanforderungen zu bewerten, SKU-Empfehlungen mit der richtigen Größe für Azure-Ressourcen zu erhalten und Ihre SQL Server-Datenbank zu Azure zu migrieren.
Hier erfahren Sie, wie Sie diese einheitliche Benutzeroberfläche verwenden und Leistungsdaten aus Ihrer SQL Server-Quellinstanz sammeln, um Azure-Empfehlungen mit der richtigen Größe für Ihre Azure SQL-Ziele zu erhalten.
Übersicht
Vor der Migration zu Azure SQL können Sie die SQL-Migrationserweiterung in Azure Data Studio verwenden, um Empfehlungen mit der richtigen Größe für Azure SQL-Datenbank, Azure SQL Managed Instance und SQL Server auf Azure Virtual Machines-Zielen zu generieren. Mit dem Tool können Sie Leistungsdaten aus Ihrer (lokal oder in einer anderen Cloud ausgeführten) SQL-Quellinstanz sammeln und eine Compute- und Speicherkonfiguration empfehlen, um die Anforderungen Ihrer Workload zu erfüllen.
Im Diagramm ist der Workflow für Azure-Empfehlungen in der Azure SQL-Migrationserweiterung für Azure Data Studio dargestellt:

Hinweis
Die Bewertungs- und Empfehlungsfunktion in der Azure SQL-Migrationserweiterung für Azure Data Studio unterstützen SQL Server-Quellinstanzen, die unter Windows oder Linux ausgeführt werden.
Voraussetzungen
Um mit den Azure-Empfehlungen für Ihre SQL Server-Datenbankmigration loszulegen, müssen Sie die folgenden Voraussetzungen erfüllen:
Installieren der Azure SQL-Migrationserweiterung aus Azure Data Studio Marketplace.
Stellen Sie sicher, dass die Anmeldung, die Sie zum Verbinden der SQL Server-Quellinstanz verwenden, über die Mindestberechtigungen verfügt.
Unterstützte Quellen und Ziele
Azure-Empfehlungen können für die folgenden SQL Server-Versionen generiert werden:
- SQL Server 2008 und höhere Versionen werden unter Windows oder Linux unterstützt.
- Eine auf anderen Clouds ausgeführte SQL Server-Instanz wird möglicherweise unterstützt, die Genauigkeit der Ergebnisse kann jedoch variieren
Azure-Empfehlungen können für die folgenden Azure SQL-Ziele generiert werden:
- Azure SQL-Datenbank
- Hardwarefamilien: Standard-Serie (Gen5)
- Dienstebenen: „Universell“, „Unternehmenskritisch“ und „Hyperscale“
- Azure SQL Managed Instance
- Hardwarefamilien: Standard-Serie (Gen5), Premium-Serie, speicheroptimierte Premium-Serie
- Dienstebenen: „Universell“ und „Unternehmenskritisch“
- SQL Server auf Azure Virtual Machine
- VM-Familien: „Universell“ und „Speicheroptimiert“
- Speicherfamilien: SSD Premium
Sammlung von Leistungsdaten
Bevor Empfehlungen generiert werden können, müssen Leistungsdaten aus Ihrer SQL Server-Quellinstanz gesammelt werden. Während dieses Schritts der Datensammlung werden mehrere dynamische Systemsichten (DMVs) aus Ihrer SQL Server-Instanz abgefragt, um die Leistungsmerkmale Ihrer Workload zu erfassen. Das Tool erfasst Metriken wie CPU, Arbeitsspeicher, Speicher und E/A-Nutzung alle 30 Sekunden und speichert die Leistungsindikatoren lokal auf Ihrem Computer als CSV-Dateien.
Instanzebene planen
Diese Leistungsdaten werden für jede SQL Server-Instanz einmal gesammelt:
| Leistungsdimension | Beschreibung | Dynamische Verwaltungssicht (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Die vom SQL Server-Prozess beanspruchte CPU-Leistung als Prozentsatz | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Der Gesamtspeicherbedarf des SQL Server-Prozesses | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Die Arbeitsspeicherauslastung der SQL Server-Instanz | sys.dm_os_process_memory |
Datenbankebene
| Leistungsdimension | Beschreibung | Dynamische Verwaltungssicht (DMV) |
|---|---|---|
DatabaseCpuPercent |
Der Gesamtprozentsatz der von einer Datenbank beanspruchten CPU-Leistung | sys.dm_exec_query_stats |
CachedSizeInMb |
Die Gesamtgröße des von einer Datenbank verwendeten Caches in Megabyte | sys.dm_os_buffer_descriptors |
Dateiebene
| Leistungsdimension | Beschreibung | Dynamische Verwaltungssicht (DMV) |
|---|---|---|
ReadIOInMb |
Die Gesamtmenge der aus dieser Datei gelesenen Megabyte | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Die Gesamtmenge der in diese Datei geschriebenen Megabyte | sys.dm_io_virtual_file_stats |
NumOfReads |
Die Gesamtzahl der für diese Datei ausgegebenen Lesevorgänge | sys.dm_io_virtual_file_stats |
NumOfWrites |
Die Gesamtzahl der für diese Datei ausgegebenen Schreibvorgänge | sys.dm_io_virtual_file_stats |
ReadLatency |
Die E/A-Leselatenz für diese Datei | sys.dm_io_virtual_file_stats |
WriteLatency |
Die E/A-Schreiblatenz für diese Datei | sys.dm_io_virtual_file_stats |
Eine Datensammlung von mindestens 10 Minuten ist erforderlich, bevor eine Empfehlung generiert werden kann. Zur genauen Bewertung Ihrer Workload wird jedoch empfohlen, die Datensammlung über einen ausreichend langen Zeitraum laufen zu lassen, um sowohl die Nutzung während der Spitzen- als auch der Nebenzeiten zu erfassen.
Um den Datensammlungsprozess zu initiieren, verbinden Sie sich zunächst mit Ihrer SQL-Quellinstanz in Azure Data Studio und starten Sie dann den SQL-Migrationsassistenten. In Schritt 2 wählen Sie „Azure-Empfehlung erhalten“ aus. Wählen Sie „Leistungsdaten jetzt sammeln“ aus, und wählen Sie dann einen Ordner auf Ihrem Computer aus, in dem die gesammelten Daten gespeichert werden sollen.
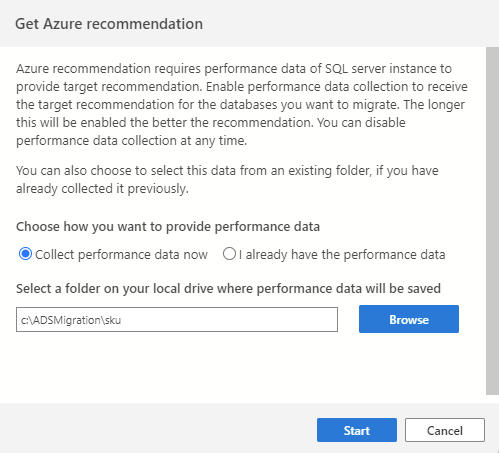
Der Datensammlungsprozess wird zehn Minuten lang ausgeführt, um die erste Empfehlung zu generieren. Es ist wichtig, mit der Datensammlung zu beginnen, wenn Ihre aktive Datenbankworkload der Auslastung während Ihrer Produktionsszenarios entspricht.
Nachdem die erste Empfehlung generiert wurde, können Sie den Datensammlungsprozess fortsetzen, um die Empfehlungen zu präzisieren. Diese Option ist insbesondere nützlich, wenn Ihr Nutzungsverhalten im Laufe der Zeit variiert.
Der Datensammlungsprozess beginnt, nachdem Sie Starten ausgewählt haben. Alle 10 Minuten werden die gesammelten Datenpunkte aggregiert, und der Höchstwert, der Mittelwert und die Varianz jedes Zählers werden auf der Festplatte in drei CSV-Dateien gespeichert.
In der Regel werden im ausgewählten Ordner CSV-Dateien mit den folgenden Suffixen angezeigt:
SQLServerInstance_CommonDbLevel_Counters.csv: Enthält statische Konfigurationsdaten zum Layout und zu den Metadaten der Datenbankdatei.SQLServerInstance_CommonInstanceLevel_Counters.csv: Enthält statische Daten zur Hardwarekonfiguration der Serverinstanz.SQLServerInstance_PerformanceAggregated_Counters.csv: Enthält aggregierte Leistungsdaten, die häufig aktualisiert werden.
Lassen Sie Azure Data Studio währenddessen geöffnet, Sie können aber mit anderen Vorgängen fortfahren. Sie können den Datensammlungsprozess jederzeit beenden, indem Sie zu dieser Seite zurückkehren und Datensammlung beenden auswählen.
Generieren von Empfehlungen mit der richtigen Größe
Wenn Sie bereits Leistungsdaten aus einer vorherigen Sitzung gesammelt oder ein anderes Tool (z. B. Datenbankmigrations-Assistent) verwendet haben, können Sie vorhandene Leistungsdaten importieren, indem Sie die Option Ich habe die Leistungsdaten bereits auswählen. Wählen Sie nun den Ordner aus, in dem Ihre Leistungsdaten (drei CSV-Dateien) gespeichert sind, und wählen Sie Starten aus, um den Empfehlungsprozess zu initiieren.
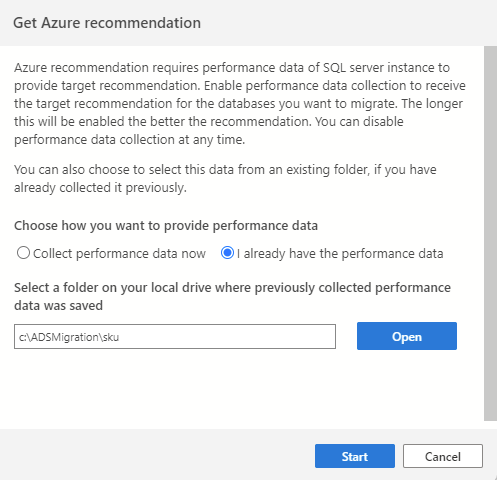
In Schritt 1 des SQL-Migrationsassistenten werden Sie aufgefordert, eine Reihe von Datenbanken auszuwählen, die bewertet werden sollen. Dies sind die einzigen Datenbanken, die während des Empfehlungsprozesses berücksichtigt werden.
Bei der Leistungsdatensammlung werden jedoch Leistungszähler nicht nur für die ausgewählten, sondern für alle Datenbanken der SQL Server-Quellinstanz erfasst.
Dies bedeutet, dass zuvor gesammelte Leistungsdaten verwendet werden können, um wiederholt Empfehlungen für eine andere Teilmenge von Datenbanken wiederholt erneut zu generieren, indem in Schritt 1 eine andere Liste angegeben wird.
Empfehlungsparameter
Es gibt mehrere konfigurierbare Einstellungen, die sich auf Ihre Empfehlungen auswirken können.

Wählen Sie die Option Parameter bearbeiten aus, um diese Parameter entsprechend Ihren Anforderungen anzupassen.
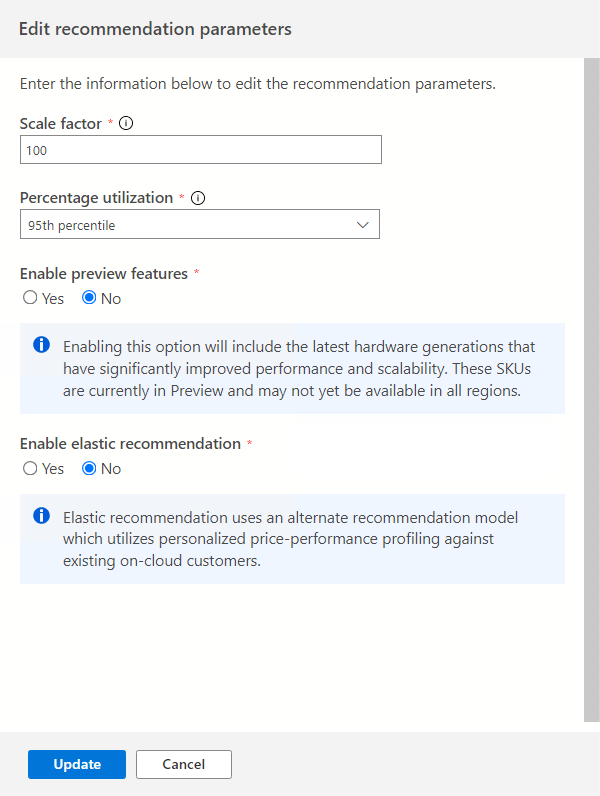
Skalierungsfaktor:
Mit dieser Option können Sie einen Puffer bereitstellen, der auf jede Leistungsdimension angewendet werden soll. Hierbei werden Aspekte wie saisonale Nutzung, ein kurzer Leistungsverlauf und eine voraussichtliche Zunahme der zukünftigen Nutzung berücksichtigt. Wenn Sie beispielsweise feststellen, dass eine CPU-Anforderung von vier virtuellen Kernen einen Skalierungsfaktor von 150 % aufweist, beträgt die tatsächliche CPU-Anforderung sechs virtuelle Kerne.
Das Volumen des Standardskalierungsfaktors beträgt 100 %.
Prozentuale Auslastung:
Das Perzentil der Datenpunkte, die während der Aggregation der Leistungsdaten verwendet werden sollen.
Der Standardwert ist das 95. Perzentil.
Vorschaufeatures aktivieren:
Mit dieser Option können Konfigurationen empfohlen werden, die möglicherweise noch nicht für alle Benutzer in allen Regionen verfügbar sind.
Standardmäßig ist diese Option deaktiviert.
Elastische Empfehlung aktivieren:
Bei dieser Option wird ein alternatives Empfehlungsmodell verwendet, das eine personalisierte Preis-Leistungs-Profilerstellung für vorhandene Kunden in der Cloud verwendet.
Standardmäßig ist diese Option deaktiviert.
Der Prozess der Datensammlung wird beendet, wenn Sie Azure Data Studio schließen. Die bis zu diesem Zeitpunkt gesammelten Daten werden in Ihrem Ordner gespeichert.
Wenn Sie Azure Data Studio während der Datensammlung schließen, verwenden Sie eine der folgenden Optionen, um die Datensammlung neu zu starten:
Öffnen Sie Azure Data Studio erneut, und importieren Sie die Datendateien, die in Ihrem lokalen Ordner gespeichert sind. Generieren Sie dann eine Empfehlung aus den gesammelten Daten.
Öffnen Sie Azure Data Studio erneut, und starten Sie die Datensammlung mithilfe des Migrations-Assistenten erneut.
Mindestberechtigungen
Zur Abfrage der erforderlichen Systemsichten für die Leistungsdatensammlung sind bestimmte Berechtigungen für die für diese Aufgabe verwendete SQL Server-Anmeldung erforderlich. Mit dem folgenden Skript können Sie einen Benutzer mit minimalen Berechtigungen für die Bewertung und Leistungsdatenerfassung erstellen:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Nicht unterstützte Szenarien und Einschränkungen
Azure-Empfehlungen enthalten keine Preisschätzungen, da die Situation je nach Region, Währung und Rabatten wie dem Azure-Hybridvorteilvariieren kann. Um Preisschätzungen zu erhalten, verwenden Sie den Azure-Preisrechner, oder erstellen Sie eine SQL-Bewertung in Azure Migrate.
Empfehlungen für die Azure SQL-Datenbank mit dem DTU-basierten Kaufmodell werden nicht unterstützt.
Derzeit werden Azure-Empfehlungen für die serverlose Azure SQL-Datenbank-Computeebene und Pools für elastische Datenbanken nicht unterstützt.
Problembehandlung
- Keine Empfehlungen generiert
- Wenn keine Empfehlungen generiert wurden, könnte dies bedeuten, dass keine Konfigurationen identifiziert wurden, die die Leistungsanforderungen Ihrer Quellinstanz vollständig erfüllen können. Gehen Sie wie folgt vor, um die Gründe zu erfahren, warum eine bestimmte Größe, Dienstebene oder Hardwarefamilie disqualifiziert wurde:
- Greifen Sie auf die Protokolle von Azure Data Studio zu, indem Sie auf „Hilfe“ > „Alle Befehle anzeigen“ gehen > und den Ordner mit den Erweiterungsprotokollen öffnen.
- Navigieren Sie zu Microsoft.mssql > SqlAssessmentLogs, > und öffnen Sie SkuRecommendationEvent.log.
- Das Protokoll enthält eine Ablaufverfolgung jeder potenziellen Konfiguration, die bewertet wurde, und den Grund, warum es (nicht) als berechtigte Konfiguration angesehen wurde:
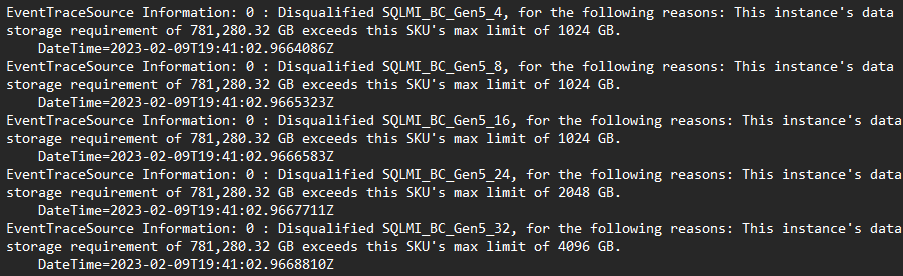
- Versuchen Sie, die Empfehlung mit aktivierter Option Elastische Empfehlung erneut zu generieren. Bei dieser Option wird ein alternatives Empfehlungsmodell verwendet, das eine personalisierte Preis-Leistungs-Profilerstellung für vorhandene Kunden in der Cloud verwendet.
- Wenn keine Empfehlungen generiert wurden, könnte dies bedeuten, dass keine Konfigurationen identifiziert wurden, die die Leistungsanforderungen Ihrer Quellinstanz vollständig erfüllen können. Gehen Sie wie folgt vor, um die Gründe zu erfahren, warum eine bestimmte Größe, Dienstebene oder Hardwarefamilie disqualifiziert wurde:
