Tutorial: JBoss EAP Application Server zu Azure Virtual Machines migrieren, mit Hochverfügbarkeit und Disaster-Recovery
Dieses Tutorial zeigt Ihnen eine einfache und effektive Implementierung von Hochverfügbarkeit und Disaster-Recovery (HA/DR) für Java mit JBoss EAP auf Azure Virtual Machines (VMs). Die Lösung veranschaulicht, wie Sie ein niedriges Wiederherstellungszeitlimit (RTO) und Wiederherstellungspunktziel (RPO) mit einer einfachen database-gesteuerten Jakarta EE-Anwendung auf dem JBoss EAP-Anwendungsserver erreichen können. HA/DR ist ein komplexes Thema mit vielen möglichen Lösungen. Die beste Lösung hängt von Ihren individuellen Anforderungen ab. Weitere Möglichkeiten zum Implementieren von HA/DR finden Sie in den Ressourcen am Ende dieses Artikels.
In diesem Tutorial erfahren Sie, wie Sie:
- Richten Sie den JBoss EAP Cluster auf Azure VMs ein.
- Verwenden Sie die Azure-optimierten Best Practices, um hohe Verfügbarkeit und Notfallwiederherstellung zu erzielen.
- Richten Sie eine Microsoft Azure SQL-Datenbank-Failovergruppe in gekoppelten Regionen ein.
- Richten Sie die Notfallwiederherstellung für den Cluster mit Azure Site Recovery ein.
- Richten Sie einen Azure Traffic Manager ein.
- Testen Sie den Failover vom primären zum sekundären Standort.
Das folgende Diagramm veranschaulicht die Architektur, die Sie aufbauen:

Azure Traffic Manager überprüft den Status Ihrer Regionen und leitet den Datenverkehr entsprechend an die Anwendungsebene weiter. Die primäre Region verfügt über eine vollständige Bereitstellung des JBoss EAP-Clusters. Nachdem die primäre Region durch Azure Site Recovery geschützt ist, können Sie die sekundäre Region während des Failovers wiederherstellen. Daher bedient die primäre Region aktiv Netzwerkanfragen von Benutzern, während die sekundäre Region passiv ist und erst aktiviert wird, um Datenverkehr zu empfangen, wenn die primäre Region eine Dienstunterbrechung erfährt.
Der Azure Traffic Manager erkennt den Zustand der im JBoss EAP Cluster bereitgestellten App, um das bedingte Routing zu implementieren. Die Geofailover-RTO der Anwendungsebene hängt von der Zeit ab, die zum Herunterfahren des primären Clusters, zum Wiederherstellen des sekundären Clusters, zum Starten von VMs und zum Ausführen des sekundären JBoss EAP-Clusters benötigt wird. Das RPO hängt von der Replikationsrichtlinie von Azure Site Recovery und der Azure SQL Database ab, weil die Clusterdaten im lokalen Speicher der virtuellen Maschinen gespeichert und repliziert werden, während Anwendungsdaten in der Azure SQL-Datenbank-Failovergruppe persistiert und repliziert werden.
Das vorangehende Diagramm zeigt die primäre Region und die sekundäre Region als zwei Regionen, die die HA/DR-Architektur umfassen. Diese Regionen müssen Azure-gekoppelte Regionen sein. Weitere Informationen zu Regionspaaren finden Sie unter Regionsübergreifende Replikation in Azure. Der Artikel verwendet USA, Osten und USA, Westen als die zwei Regionen, aber es kann sich um beliebige Regionspaare handeln, die für Ihr Szenario sinnvoll sind. Eine Liste der Regionspaare finden Sie im Abschnitt Azure-Regionspaare von Regionsübergreifende Replikation in Azure.
Die Datenbankebene besteht aus einer Azure SQL-Datenbank-Failovergruppe mit einem primären Server und einem sekundären Server. Der Lese-/Schreiblistenerendpunkt verweist immer auf den primären Server und ist in den einzelnen Regionen mit dem JBoss EAP-Cluster verbunden. Sowohl bei manueller als auch automatischer Failover-Aktivierung schaltet das Geofailover alle sekundären Datenbanken in der Gruppe zur primären Rolle um. Informationen zu RPOs und RTO für Geofailover der Azure SQL-Datenbank finden Sie unter Übersicht über die Geschäftskontinuität.
Dieses Tutorial wurde mit dem Azure Site Recovery und dem Azure SQL Database Service geschrieben, da es sich auf die HA-Funktionen dieser Dienste stützt. Es sind auch andere Datenbanken möglich, aber die HA-Funktionen der von Ihnen gewählten Datenbank müssen berücksichtigt werden.
Voraussetzungen
- Wenn Sie kein Azure-Abonnement besitzen, erstellen Sie ein kostenloses Konto, bevor Sie beginnen.
- Stellen Sie sicher, dass Sie über die
Contributor-Rolle im Abonnement verfügen. Sie können die Aufgabe überprüfen, indem Sie die Schritte in Auflisten von Azure-Rollenzuweisungen mithilfe des Azure-Portals befolgen. - Bereiten Sie eine lokale Maschine vor, auf der Windows, GNU/Linux oder macOS installiert ist.
- Installieren Sie Git, und richten Sie es ein.
- Installieren Sie eine Java SE-Implementierung, Version 17 oder höher, z. B. der Microsoft-Build von OpenJDK.
- Installieren Sie Maven, Version 3.9.3 oder höher.
Einrichten einer Azure SQL-Datenbank-Failovergruppe in Regionspaaren
In diesem Abschnitt erstellen Sie eine Azure SQL-Datenbank-Failovergruppe in gekoppelten Regionen für die Verwendung mit Ihren JBoss-EAP-Clustern und Ihrer App.
Erstellen Sie zunächst die primäre Azure SQL-Datenbank, indem Sie die Schritte im Azure-Portal in Schnellstart: Erstellen einer Einzeldatenbank – Azure SQL-Datenbank befolgen. Befolgen Sie die Schritte bis zum Abschnitt Ressourcen bereinigen, jedoch nicht einschließlich dieses Abschnitts. Befolgen Sie die folgenden Anweisungen, während Sie den Artikel durchgehen, kehren Sie dann nach dem Erstellen und Konfigurieren der Azure SQL-Datenbank zu diesem Artikel zurück.
Wenn Sie den Abschnitt Erstellen einer Einzeldatenbank erreichen, verwenden Sie die folgenden Schritte:
Notieren Sie in Schritt 4 zum Erstellen einer neuen Ressourcengruppe den Wert Ressourcengruppenname, z. B.
sqlserver-rg-gzh032124.Notieren Sie in Schritt 5 für den Datenbanknamen den Wert Datenbankname, z. B.
mySampleDatabase.Führen Sie in Schritt 6 zum Erstellen des Servers die folgenden Schritte aus:
- Geben Sie einen eindeutigen Servernamen ein, z. B.
sqlserverprimary-gzh032124. - Wählen Sie unter Standort die Option (USA) USA, Osten aus.
- Wählen Sie für Authentifizierungsmethode die Option SQL-Authentifizierung verwenden aus.
- Notieren Sie den Wert Serveradministratoranmeldung, z. B.
azureuser. - Notieren Sie den Wert Kennwort.
- Geben Sie einen eindeutigen Servernamen ein, z. B.
Wählen Sie in Schritt 8 für Workloadumgebung die Option Entwicklung aus. Sehen Sie sich die Beschreibung an und ziehen Sie weitere Optionen für Ihre Arbeitsbelastung in Betracht.
Wählen Sie in Schritt 10 für Computeebene die Ebene Bereitgestellt aus.
Wählen Sie in Schritt 11 für Redundanz für Sicherungsspeicher die Option Lokal redundanter Sicherungsspeicher aus. Ziehen Sie weitere Optionen für Ihre Sicherungen in Betracht. Weitere Informationen finden Sie im Abschnitt Sicherungsspeicherredundanz von Automatisierte Sicherungen in Azure SQL Database.
Wählen Sie in Schritt 14 in der Konfiguration der Firewallregeln für Azure-Diensten und -Ressourcen den Zugriff auf diesen Server erlauben die Option Ja aus.
Wenn Sie den Abschnitt Abfrage der Datenbank erreichen, verwenden Sie die folgenden Schritte anstelle der Schritte im anderen Artikel:
Geben Sie in Schritt 3 Ihre Serveradministrator-Anmeldeinformationen der SQL-Authentifizierung zur Anmeldung ein.
Hinweis
Wenn die Anmeldung mit einer Fehlermeldung ähnlich der folgenden Client mit IP-Adresse 'xx.xx.xx.xx' darf nicht auf den Server zugreifen angezeigt wird, wählen Sie IP xx.xx.xx.xx im Server auf die Positivliste setzen <your-sqlserver-name> am Ende der Fehlernachricht aus. Warten Sie, bis die Serverfirewallregeln die Aktualisierung abgeschlossen haben, und wählen Sie dann erneut OK aus.
Nachdem Sie die Beispielabfrage in Schritt 5 ausgeführt haben, löschen Sie die Inhalte im Editor, und geben Sie die folgende Abfrage ein. Wählen Sie dann erneut Ausführen aus:
CREATE TABLE ispn_entry_sessions_javaee_cafe_war ( id VARCHAR(255) PRIMARY KEY, -- ID Column to hold cache entry ids data VARBINARY(MAX), -- Data Column to hold cache entry data timestamp BIGINT, -- Timestamp Column to hold cache entry timestamps segment INT );Nach einer erfolgreichen Ausführung sollte die Meldung Die Abfrage war erfolgreich: Betroffene Zeilen: 0 angezeigt werden.
Die Datenbanktabelle
ispn_entry_sessions_javaee_cafe_warwird zum Speichern der Sitzungsdaten für Ihren JBoss EAP Cluster verwendet.
Erstellen Sie dann eine Azure SQL-Datenbank-Failovergruppe, indem Sie die Schritte im Azure-Portal unter Konfigurieren einer Failovergruppe für Azure SQL-Datenbankausführen. Sie benötigen lediglich die folgenden Abschnitte: Erstellen einer Failovergruppe und Testen des geplanten Failovers. Führen Sie die folgenden Schritte aus, während Sie den Artikel durchgehen, und kehren Sie nach dem Erstellen und Konfigurieren der Failovergruppe für die Azure SQL-Datenbank zu diesem Artikel zurück.
Wenn Sie den Abschnitt Erstellen einer Failovergruppe erreichen, verwenden Sie die folgenden Schritte:
Geben Sie in Schritt 5 zum Erstellen der Failovergruppe den eindeutigen Namen der Failovergruppe ein, und notieren Sie ihn, z. B.
failovergroup-gzh032124.Wählen Sie in Schritt 5 zum Konfigurieren des Servers die Option zum Erstellen eines neuen sekundären Servers aus, und führen Sie dann die folgenden Schritte aus:
- Geben Sie einen eindeutigen Servernamen ein, z. B.
sqlserversecondary-gzh032124. - Geben Sie denselben Serveradministrator und dasselbe Kennwort wie für Ihren primären Server ein.
- Wählen Sie unter Standort die Option (USA) USA, Westen 2 aus.
- Achten Sie darauf, dass Azure-Diensten Zugriff auf den Server erlauben aktiviert ist.
- Geben Sie einen eindeutigen Servernamen ein, z. B.
Wählen Sie in Schritt 5 zum Konfigurieren der Datenbanken innerhalb der Gruppe die Datenbank aus, die Sie auf dem primären Server erstellt haben – z. B.
mySampleDatabase.
Nachdem Sie alle Schritte im Abschnitt Geplantes Failover testen abgeschlossen haben, lassen Sie die Failovergruppenseite geöffnet, und verwenden Sie sie später für den Failovertest der JBoss EAP-Cluster.
Hinweis
Dieser Artikel hilft Ihnen bei der Erstellung einer einzelnen Azure SQL-Datenbank mit SQL-Authentifizierung aus Gründen der Einfachheit, da die Konfiguration von HA/DR, auf die sich dieser Artikel konzentriert, bereits sehr komplex ist. Eine sicherere Methode ist die Verwendung von Microsoft Entra Authentication for Azure SQL für die Authentifizierung der Verbindung zum Datenbankserver.
Einrichten des primären JBoss EAP Clusters auf Azure VMs
In diesem Abschnitt erstellen Sie die primären JBoss EAP-Cluster auf Azure-VMs mithilfe des Angebots JBoss EAP-Cluster auf VMs. Der sekundäre Cluster wird während des Failovers mithilfe von Azure Site Recovery später aus dem primären Cluster wiederhergestellt.
Bereitstellen des primären JBoss-EAP-Clusters
Öffnen Sie zunächst das Angebot JBoss EAP-Cluster auf VMs in Ihrem Browser, und wählen Sie Erstellen aus. Der Bereich Grundeinstellungen des Angebots sollte angezeigt werden.
Führen Sie die folgenden Schritte aus, um den Bereich Grundeinstellungen auszufüllen:
- Stellen Sie sicher, dass der für Abonnement angezeigte Wert mit dem Wert übereinstimmt, der die im Abschnitt „Voraussetzungen“ aufgeführten Rollen enthält.
- Sie müssen das Angebot in einer leeren Ressourcengruppe bereitstellen. Wählen Sie im Feld Ressourcengruppe die Option Neu erstellen aus, und geben Sie einen eindeutigen Wert für die Ressourcengruppe ein, z. B.
jboss-eap-cluster-eastus-gzh032124. - Wählen Sie unter Instanzdetails für Region die Option USA, Osten aus.
- Geben Sie ein Kennwort für Kennwort ein, und verwenden Sie denselben Wert für Kennwort bestätigen.
- Geben Sie für Anzahl der zu erstellenden virtuellen Computer die Anzahl 3 ein.
- Lassen Sie die anderen Felder auf ihren Standardwerten.
- Wählen Sie Weiter aus, um zum Bereich JBoss EAP-Einstellungen zu wechseln.

Führen Sie die folgenden Schritte aus, um den Bereich JBoss EAP-Einstellungen auszufüllen:
- Geben Sie unter JBoss EAP-Kennwort ein JBoss EAP-Kennwort an. Verwenden Sie denselben Wert zum Bestätigen des Passworts. Notieren Sie sich den Wert für die spätere Verwendung.
- Lassen Sie die anderen Felder auf ihren Standardwerten.
- Wählen Sie Weiter aus, um zum Bereich Azure Application Gateway zu wechseln.

Verwenden Sie die folgenden Schritte, um den Bereich Azure Application Gateway auszufüllen:
- Wählen Sie für Mit Azure Application Gateway verbinden? die Option Ja aus.
- Lassen Sie die anderen Felder auf ihren Standardwerten.
- Wählen Sie Weiter aus, um zum Bereich Netzwerk zu wechseln.

Ihnen sollten alle Felder mit den Standardwerten im Bereich Netzwerk angezeigt werden. Wählen Sie Weiter aus, um zum Bereich Datenbank zu wechseln.

Führen Sie die folgenden Schritte aus, um den Bereich Datenbank auszufüllen:
- Wählen Sie unter Mit Datenbank verbinden? die Option Ja aus.
- Wählen Sie für Datenbanktyp auswählen die Option Microsoft SQL Server aus.
- Geben Sie für JNDI-Name den Namen java:jboss/datasources/JavaEECafeDB ein.
- Ersetzen Sie für Datenquellen-Verbindungszeichenfolge (jdbc:sqlserver://<host>:<port>;database=<database>) die Platzhalter durch die Werte, die Sie im vorherigen Abschnitt für die Failovergruppe von Azure SQL-Datenbank notiert haben, z. B.
jdbc:sqlserver://failovergroup-gzh032124.database.windows.net:1433;database=mySampleDatabase. - Geben Sie für Datenbankbenutzername den Serveradministrator-Anmeldenamen und den Failovergruppennamen ein, die Sie im vorherigen Abschnitt notiert haben, z. B.
azureuser@failovergroup-gzh032124. - Geben Sie das Kennwort für die Anmeldung beim Serveradministrator ein, das Sie zuvor für Datenbankkennwort notiert haben. Geben Sie denselben Wert für Kennwort bestätigen ein.
- Klicken Sie auf Überprüfen + erstellen.
- Warten Sie, bis Abschließende Überprüfung wird ausgeführt... erfolgreich abgeschlossen ist. Wählen Sie dann Erstellen aus.

Nach einiger Zeit sollte die Seite Bereitstellung angezeigt werden, auf der Bereitstellung wird ausgeführt angezeigt wird.
Hinweis
Wenn bei Abschließende Überprüfung wird ausgeführt... Probleme auftreten, beheben Sie diese, und versuchen Sie es erneut.
Abhängig von den Netzwerkbedingungen und anderen Aktivitäten in der ausgewählten Region kann die Bereitstellung bis zu 35 Minuten dauern. Danach sollte auf der Bereitstellungsseite der Text Ihre Bereitstellung wurde abgeschlossen. angezeigt werden.
Überprüfen der Funktionsfähigkeit der Bereitstellung
Überprüfen Sie mithilfe der folgenden Schritte die Funktionsfähigkeit der Bereitstellung für einen JBoss EAP-Cluster auf Azure-VMs. Verwenden Sie dazu die Red Hat JBoss Enterprise Application Platform-Verwaltungskonsole:
Wählen Sie auf der Seite Ihre Bereitstellung ist abgeschlossen. die Option Ausgaben aus.
Wählen Sie das Kopiersymbol neben adminConsole aus.
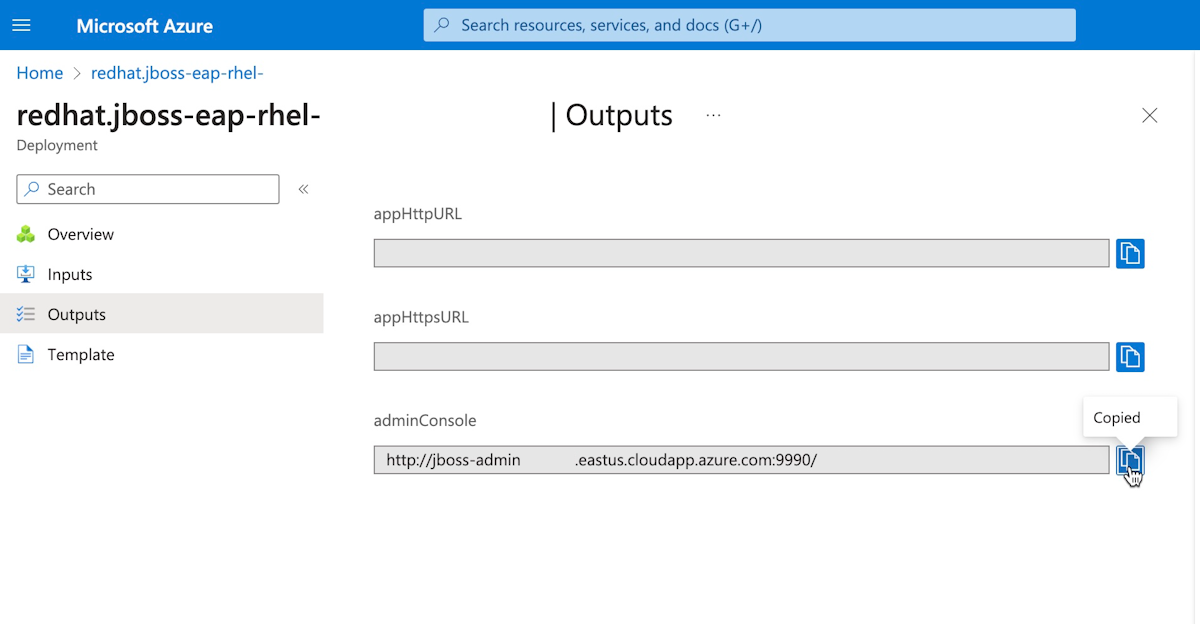
Fügen Sie die URL in einen mit dem Internet verbundenen Webbrowser ein, und drücken Sie anschließend die EINGABETASTE. Wie im folgenden Screenshot dargestellt, sollte der vertraute Anmeldebildschirm der Red Hat JBoss Enterprise Application Platform-Verwaltungskonsole angezeigt werden.
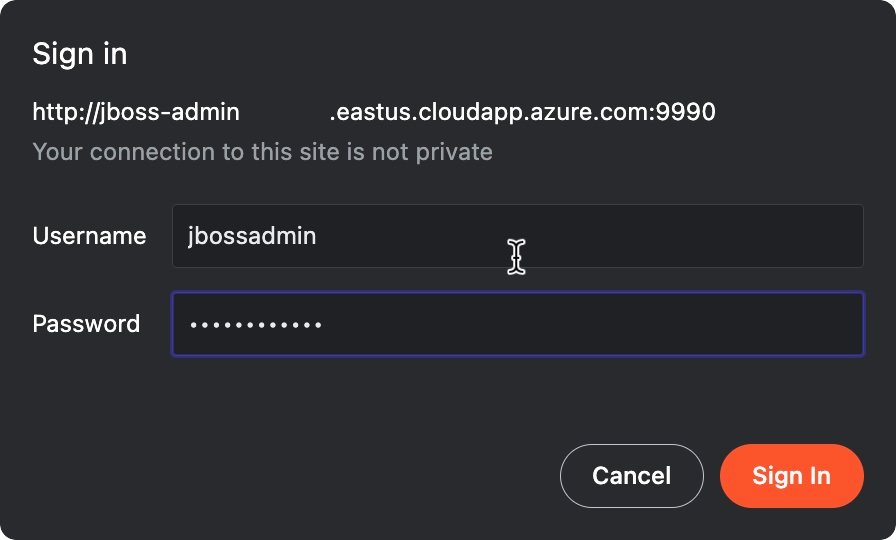
Geben Sie jbossadmin für den JBoss EAP-Administratorbenutzernamen ein. Geben Sie dann den Wert für das JBoss EAP-Kennwort ein, das Sie zuvor für das Passwordangegeben haben, und wählen Sie dann Anmeldenaus.
Wie im folgenden Screenshot gezeigt, sollte die vertraute Red Hat JBoss Enterprise Application Platform Willkommensseite der Verwaltungskonsole angezeigt werden.

Wählen Sie die Registerkarte Runtime aus. Wählen Sie im Navigationsbereich die Option Topology aus. Sie sollten sehen, dass der Cluster einen Domänencontroller Master und zwei Worker Nodes enthält, wie im folgenden Screenshot gezeigt:
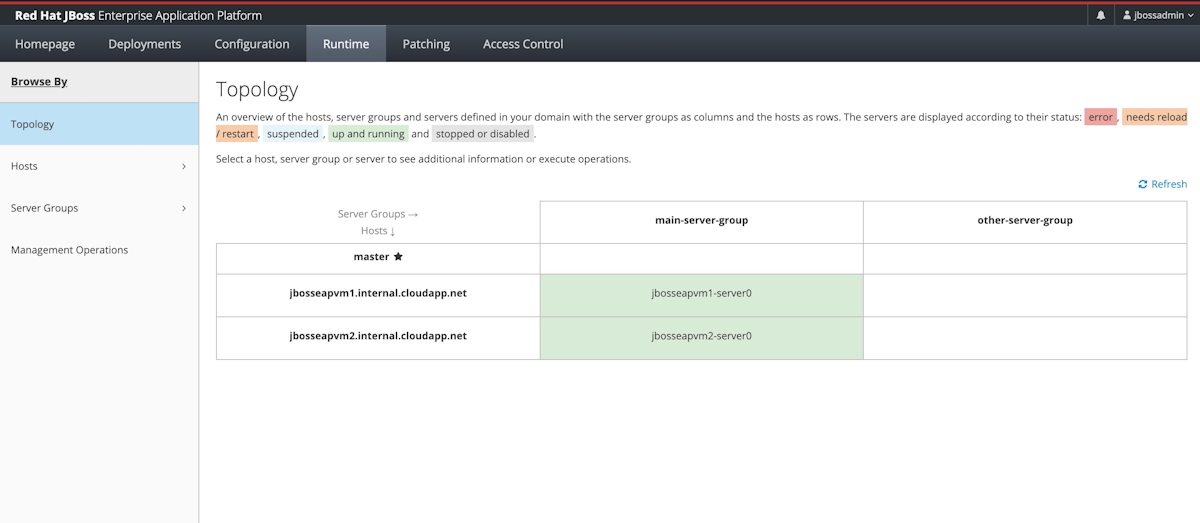




Lassen Sie die Verwaltungskonsole geöffnet. Sie verwenden es, um eine Beispielanwendung im JBoss-EAP-Cluster im nächsten Abschnitt bereitzustellen.
Konfigurieren des Clusters
Führen Sie die folgenden Schritte aus, um verteilte Datenbanksitzungen für alle Anwendungsserver zu konfigurieren:
Wählen Sie im Navigationsbereich die Option Configuration aus. Wählen Sie dann Profiles>ha>Infinspan>Web aus.
Wählen Sie in der Spalte Cache die Option Add Distributed Cache aus.
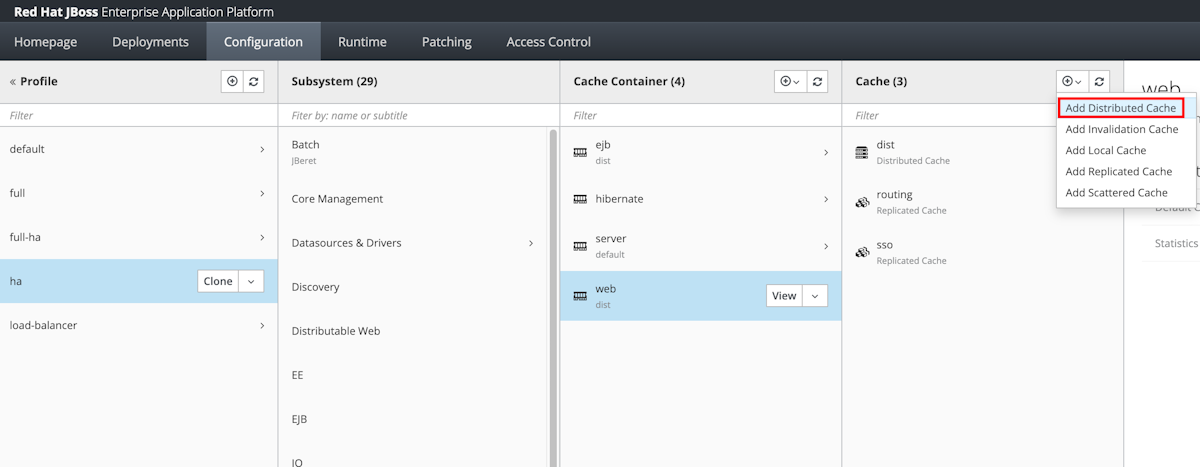
Geben Sie für Name den Namen azure-session ein, und wählen Sie dann Add aus.
Die Meldung Distributed Cache azure-session successfully added sollte angezeigt werden. Wenn Sie diese Nachricht nicht sehen, überprüfen Sie das Notification Center. Sie müssen diese Nachricht sehen, bevor Sie fortfahren.
Nachdem der Cache hinzugefügt wurde, wählen Sie azure-session>View aus.
Wählen Sie Store.
Ändern Sie das Dropdownmenü, um JDBC anzuzeigen, und wählen Sie dann Add aus.
Wählen Sie für Data source die Option dataSource-mssqlserver und dann Add aus.
Die folgende Meldung sollte angezeigt werden: JDBC successfully added. Wenn Sie diese Nachricht nicht sehen, überprüfen Sie das Notification Center. Sie müssen diese Nachricht sehen, bevor Sie fortfahren.
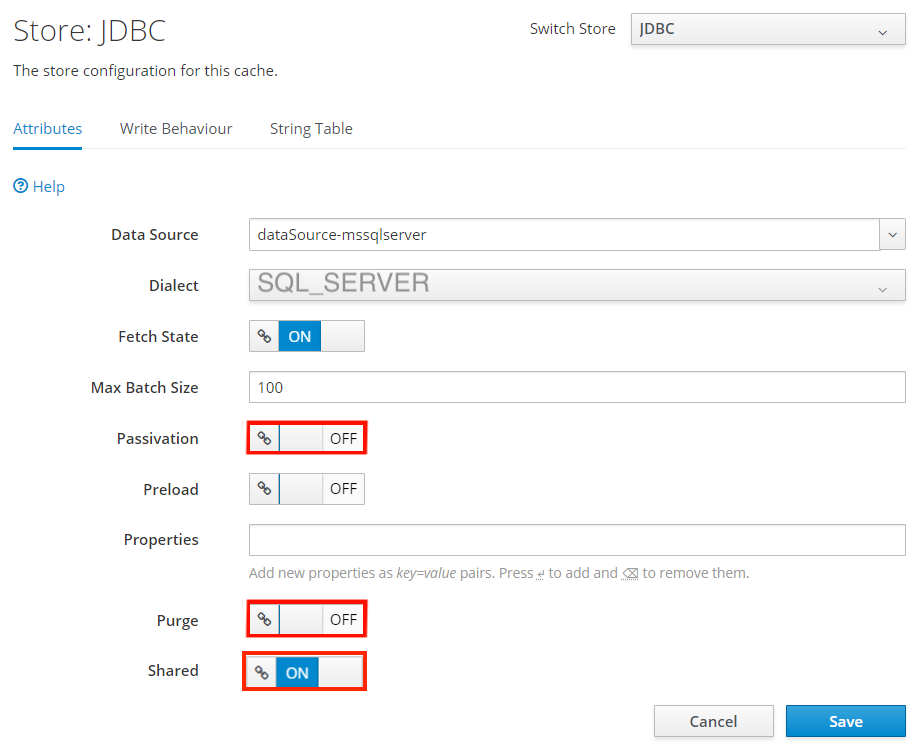
Wählen Sie auf der Seite Store: JDBC die Option Edit aus. Legen Sie die folgenden Eigenschaftswerte fest:
- Legen Sie Dialect auf SQL_SERVER fest.
- Legen Sie Passivation auf OFF fest.
- Legen Sie Purge auf OFF fest.
- Legen Sie Shared auf ON fest.
Wählen Sie Speichern.
Die folgende Meldung sollte angezeigt werden: JDBC successfully modified. Wenn Sie diese Nachricht nicht sehen, überprüfen Sie das Notification Center. Sie müssen diese Nachricht sehen, bevor Sie fortfahren.
Bearbeiten Sie die Zeichenfolgentabelle, indem Sie String Table>Edit auswählen. Geben Sie die folgenden Werte ein, und wählen Sie dann Save aus:
- Legen Sie Prefix auf den Wert ispn_entry_sessions fest.
- Legen Sie ID Column / ID Column Name auf id fest.
- Legen Sie ID Column / ID Column Typ auf VARCHAR(255) fest.
- Legen Sie Data Column / Data Column Name auf data fest.
- Legen Sie Data Column / Data Column Type auf VARBINARY(MAX) fest.
- Legen Sie Timestamp Column / Timestamp Column Name auf timestamp fest.
- Legen Sie Timestamp Column / Timestamp Column Type auf BIGINT fest.

Jeder Tippfehler hier führt zum Ausfall des gesamten Systems. Überprüfen Sie die eingegebenen Werte sorgfältig, bevor Sie fortfahren.
Wählen Sie Speichern.
Die Meldung String Table successfully modified sollte angezeigt werden. Wenn Sie diese Nachricht nicht sehen, überprüfen Sie das Notification Center. Sie müssen diese Nachricht sehen, bevor Sie fortfahren.
Wählen Sie im oberen Navigationsbereich die Option Configuration aus. Wählen Sie dann Profiles>ha>Distributable Web>View aus.
Wählen Sie Infinspan SSO>default>Edit aus.

Legen Sie den Wert von Cache auf azure-session fest, und wählen Sie dann Save aus.
Die Meldung Infinispan Single Sign On Management default successfully modified sollte angezeigt werden. Wenn Sie diese Nachricht nicht sehen, überprüfen Sie das Notification Center. Sie müssen diese Nachricht sehen, bevor Sie fortfahren.
Verwenden Sie die Topologie, um betroffene Server neu zu laden oder neu zu starten.
Wählen Sie im Navigationsbereich die Option Runtime und dann die Option Topology aus.
Wählen Sie für jede Zeile in der Spalte main-server-group den Server und dann Reload aus.
Die neu geladenen Zellen sollten jetzt die Farbe Grün anzeigen.







Stellen Sie die App im JBoss EAP-Cluster bereit
Führen Sie die folgenden Schritte aus, um die JavaEE Cafe Beispielanwendung auf dem Red Hat JBoss EAP Cluster bereitzustellen:
Führen Sie zum Erstellen des Java EE Cafe-Beispiels die folgenden Schritte aus. Diese Schritte setzen voraus, dass Sie über eine lokale Umgebung mit installiertem Git und Maven verfügen.
Verwenden Sie den folgenden Befehl, um den Quellcode von GitHub zu klonen, und sehen Sie sich das Tag an, das dieser Version des Artikels entspricht:
git clone https://github.com/Azure/rhel-jboss-templates.git --branch 20240904 --single-branchSollte eine Fehlermeldung mit dem Hinweis
You are in 'detached HEAD' stateangezeigt werden, können Sie sie problemlos ignorieren.Verwenden Sie den folgenden Befehl, um den Quellcode zu erstellen:
mvn clean install --file rhel-jboss-templates/eap-coffee-app/pom.xmlMit diesem Befehl wird die Datei rhel-jboss-templates/eap-coffee-app/target/javaee-cafe.war erstellt. Diese Datei laden Sie im nächsten Schritt hoch.
Führen Sie die folgenden Schritte in der Red Hat JBoss Enterprise Application Platform-Verwaltungskonsole aus, um die Datei javaee-cafe.war in das Inhaltsrepository hochzuladen:
Wählen Sie auf der Registerkarte Deployments im Navigationsbereich der Red Hat JBoss EAP-Verwaltungskonsole die Option Content Repository aus.
Wählen Sie Add und anschließend Upload Content aus.

Verwenden Sie Dateiauswahl des Browsers, um die Datei javaee-cafe.war auszuwählen.
Wählen Sie Weiter aus.
Übernehmen Sie auf dem nächsten Bildschirm die Standardwerte, und wählen Sie anschließend Finish aus.
Wählen Sie View content aus.
Führen Sie die folgenden Schritte aus, um eine Anwendung auf
main-server-groupbereitzustellen:Wählen Sie unter Content Repository die Option javaee-cafe.war aus.
Öffnen Sie das Dropdownmenü, und wählen Sie dann Deploy aus.
Wählen Sie main-server-group als Servergruppe für die Bereitstellung von javaee-cafe.war aus.
Wählen Sie Bereitstellen aus, um die Bereitstellung zu starten. Sie sollten eine Meldung wie im folgenden Screenshot sehen:



Sie haben nun die Bereitstellung der JavaEE-Anwendung abgeschlossen. Führen Sie die folgenden Schritte aus, um auf die Anwendung zuzugreifen und alle Einstellungen zu überprüfen:
Geben Sie im Azure-Portal oben in das Suchfeld Ressourcengruppen ein, und wählen Sie Ressourcengruppen in den Suchergebnissen aus.
Wählen Sie den Namen der Ressourcengruppe - zum Beispiel
jboss-eap-cluster-eastus-gzh032124.Wählen Sie die Ressource Application Gateway in der Ressourcengruppe aus.
Kopieren Sie den Wert für Öffentliche Front-End-IP-Adresse im Bereich Übersicht.
Konstruieren Sie eine URL mit der IP-Adresse und dem Pfad - zum Beispiel
http://40.88.26.22/javaee-cafe.Fügen Sie die URL in die Adressleiste eines Webbrowsers ein, und drücken Sie dann die EINGABETASTE. Sie sollten die Startseite der JavaEE Cafe-Anwendung sehen.
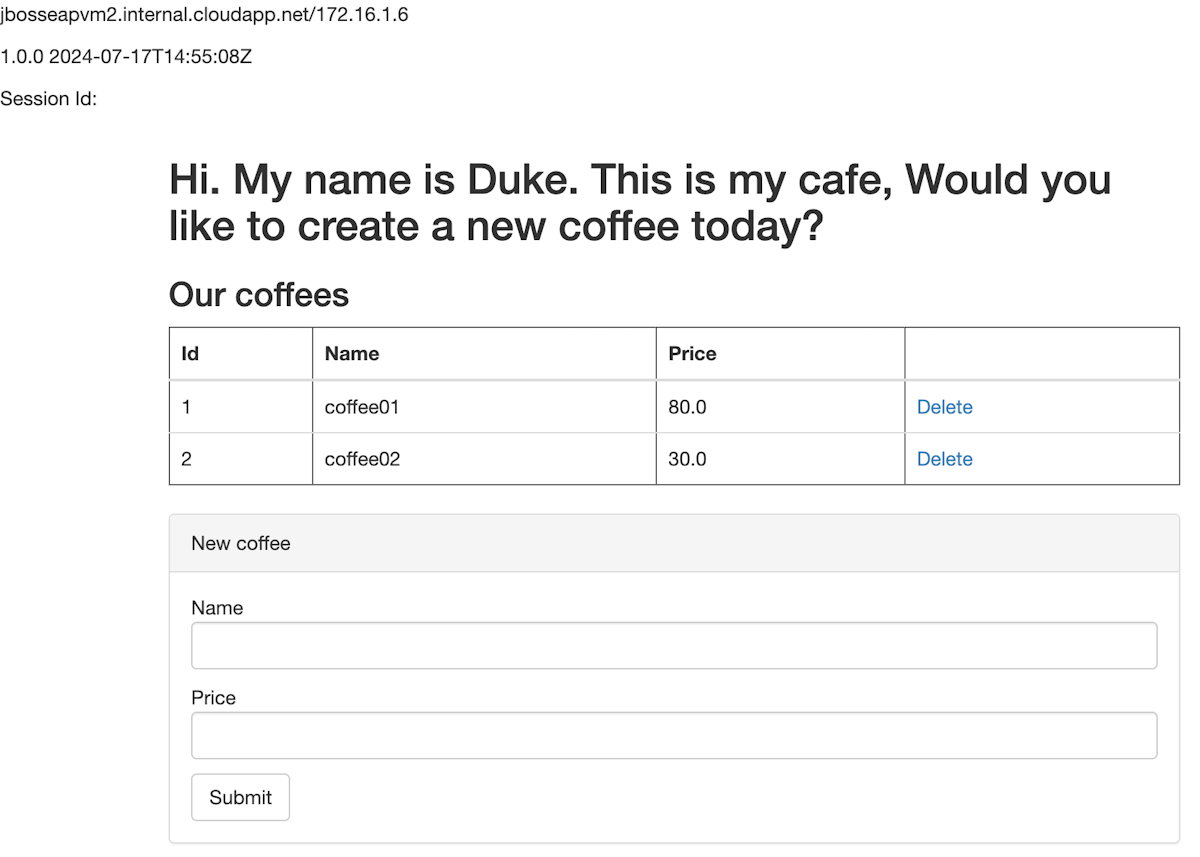
Erstellen Sie zwei Kaffees mit unterschiedlichen Namen und Preisen. Im folgenden Screenshot sollten Sie eine Seite sehen, die ähnlich ist:

Einrichten des sekundären JBoss EAP Clusters auf Azure VMs
Bereitstellen des sekundären JBoss-EAP-Clusters
Führen Sie die Schritte unter Bereitstellen des primären JBoss EAP-Clusters aus, um den sekundären JBoss EAP-Cluster in der gekoppelten Region bereitzustellen. In diesem Beispiel wird USA, Westen 2 verwendet. Wenn Sie das Angebot nutzen, wird der sekundäre JBoss EAP Cluster so konfiguriert, dass Sie Azure Site Recovery zur Wiederherstellung der Topologie verwenden können.
Öffnen Sie das Angebot JBoss EAP-Cluster auf VMs in Ihrem Browser, und wählen Sie Erstellen aus. Der Bereich Grundeinstellungen des Angebots sollte angezeigt werden.
Führen Sie die folgenden Schritte aus, um den Bereich Grundeinstellungen auszufüllen:
Wählen Sie im Feld Ressourcengruppe die Option Neu erstellen aus, und geben Sie einen eindeutigen Wert für die Ressourcengruppe ein, z. B.
jboss-eap-cluster-westus-gzh032124.Wählen Sie unter Instanzdetails für Region die Option USA, Westen 2 aus.
Übernehmen Sie für die anderen Optionen die gleichen Einstellungen wie für den primären Cluster.
Übernehmen Sie im Bereich JBoss EAP-Einstellungen die gleichen Einstellungen wie für den primären Cluster.
Verwenden Sie im Bereich Azure Application Gateway die gleichen Einstellungen wie für den primären Cluster.
Öffnen Sie im Bereich Netzwerk die Einstellung Virtuelles Netzwerk, und geben Sie den Adressraum ein. Der Wert ist mit dem Wert für den primären Cluster identisch.

Führen Sie im Bereich Datenbank die folgenden Schritte aus:
- Verwenden Sie die gleichen Einstellungen wie für den primären Cluster.
- Klicken Sie auf Überprüfen + erstellen.
- Warten Sie, bis Abschließende Überprüfung wird ausgeführt... erfolgreich abgeschlossen ist. Wählen Sie dann Erstellen aus.
Nach einiger Zeit sollte die Seite Bereitstellung angezeigt werden, auf der Bereitstellung wird ausgeführt angezeigt wird.
Unbenutzte Ressourcen in der sekundären Region bereinigen
Verwenden Sie die folgenden Schritte, um Ressourcen in der Ressourcengruppe mit dem Namen jboss-eap-cluster-westus-gzh032124 zu bereinigen, die nicht verwendet werden und später vom Azure Site Recovery Dienst in der primären Region repliziert werden sollen. Diese Vorgehensweise mag verschwenderisch erscheinen, aber sie stellt sicher, dass die sekundäre Ressourcengruppe die gleiche Konfiguration wie die primäre hat. Eine produktionsreife Lösung würde mehr Infrastructure-as-Code-Technologien verwenden, um eine identische Konfiguration sicherzustellen, dies liegt jedoch außerhalb des Umfangs dieses Artikels.
Geben Sie im Suchfeld oben im Azure-Portal Ressourcengruppen ein, und wählen Sie dann in den Suchergebnissen Ressourcengruppen aus.
Wählen Sie den Namen der Ressourcengruppe für Ihre neu erstellte sekundäre Region.
Wählen Sie neben dem Textbereich Nach einem beliebigen Feld filtern... das X aus, um alle Filter zu entfernen.
Klicken Sie auf Filter hinzufügen. Legen Sie Filter auf Typ fest. Legen Sie Operator auf Ist gleich fest.
Wählen Sie das Dropdownmenü neben dem Feld Wert aus.
Schalten Sie das Kontrollkästchen Alle auswählen um, bis keine Werte mehr ausgewählt sind.
Stellen Sie sicher, dass alle der folgenden Typen ausgewählt sind:
- Virtueller Computer
- Datenträger
- Privater Endpunkt
- Netzwerkschnittstelle
- Storage-Konto
Wählen Sie das Dropdownmenü neben dem Feld Wert aus, um das Dropdownmenü zu schließen. Für den Wert Wert muss 5 Ressourcentypen angezeigt werden.
Wählen Sie Übernehmen.
Aktivieren Sie das Kontrollkästchen neben der Bezeichnung Name oben in der gefilterten Liste.
Klicken Sie auf Löschen.
Geben Sie Löschen ein, um den Löschvorgang zu bestätigen und wählen Sie dann Löschen. Überwachen Sie den Prozess in Benachrichtigungen, bis er abgeschlossen ist.
Einrichten der Notfallwiederherstellung für den Cluster mit Azure Site Recovery
In diesem Abschnitt richten Sie die Notfallwiederherstellung für Azure-VMs im primären Cluster ein, indem Sie die Schritte im Tutorial "Einrichten der Notfallwiederherstellung für Azure-VMs"mithilfe von Azure Site Recovery befolgen. Sie benötigen nur die folgenden Abschnitte: Erstellen eines Recovery Services-Tresor und Aktivieren der Replikation. Achten Sie beim Lesen des Artikels auf die folgenden Schritte und kehren Sie zu diesem Artikel zurück, nachdem der primäre Cluster geschützt ist:
Wenn Sie den Abschnitt Erstellen eines Recovery Services-Tresors erreichen, führen Sie die folgenden Schritte aus:
Erstellen Sie in Schritt 5 für Ressourcengruppeeine neue Ressourcengruppe mit einem eindeutigen Namen in Ihrem Abonnement, z. B.
recovery-service-westus-gzh032124.Geben Sie in Schritt 6 für Tresorname einen Tresornamen ein, z. B.
recovery-service-vault-westus-gzh032124.Wählen Sie in Schritt 7 für Region die Option USA, Westen 2 aus.
Bevor Sie in Schritt 8 Überprüfen und erstellen auswählen, wählen Sie Weiter: Redundanz aus. Wählen Sie im Bereich Redundanz die Option Georedundant für Redundanz für Sicherungsspeicher und Aktivieren für Regionsübergreifende Wiederherstellung aus.
Hinweis
Wählen Sie unbedingt Georedundant für Redundanz für Sicherungsspeicher und Aktivieren für Regionsübergreifende Wiederherstellung im Bereich Redundanz aus. Andernfalls kann der Storage des primären Clusters nicht in die sekundäre Region repliziert werden.
Aktivieren Sie Site Recovery, indem Sie die Schritte in Abschnitt Site Recovery aktivieren ausführen.
Wenn Sie den Abschnitt Aktivieren der Replikation erreichen, verwenden Sie die folgenden Schritte:
Verwenden Sie die folgenden Schritte, um die Quelleinstellungen festzulegen:
Wählen Sie als Region die Option USA, Osten aus.
Wählen Sie für Ressourcengruppe die Ressource aus, in der der primäre Cluster bereitgestellt wird, z. B.
jboss-eap-cluster-eastus-gzh032124.Hinweis
Wenn die gewünschte Ressourcengruppe nicht aufgeführt ist, können Sie zuerst West US 2 für Region auswählen und dann zurück zu Ost USwechseln.
Lassen Sie die anderen Felder auf ihren Standardwerten.
Wählen Sie die VMs aus. In Virtuelle Maschinenwählen Sie alle aufgeführten virtuellen Computer aus - zum Beispiel werden 3 VMs im primären Cluster für dieses Tutorial bereitgestellt.
Verwenden Sie die folgenden Schritte, wenn Sie die Einstellungen für die Replikation überprüfen:
Wählen Sie unter Zielstandort die Option USA, Westen 2 aus.
Wählen Sie für Zielressourcengruppe die Ressourcengruppe aus, in der der Dienstwiederherstellungstresor bereitgestellt wird, z. B.
jboss-eap-cluster-westus-gzh032124.Wenn die erwartete Ressourcengruppe nicht angezeigt wird, wählen Sie eine andere Region und kehren Sie dann zu USA, Westen 2 zurück.
Notieren Sie sich das neue virtuelle Failover-Netzwerk und das Failover-Subnetz, die denen in der primären Region zugeordnet sind.
Übernehmen Sie in den restlichen Feldern die Standardwerte.
Führen Sie für Verwalten die folgenden Schritte aus:
Verwenden Sie für Aufbewahrungsrichtlinie die Standardrichtlinie 24-Stunden-Aufbewahrungsrichtlinie. Sie können auch eine neue Richtlinie für Ihr Unternehmen erstellen.
Übernehmen Sie in den restlichen Feldern die Standardwerte.
Führen Sie für Überprüfen die folgenden Schritte aus:
Beachten Sie nach dem Auswählen von Replikation aktivieren die Nachricht Azure-Ressourcen werden erstellt. Dieses Blatt nicht schließen., die unten auf der Seite angezeigt wird. Tun Sie nichts und warten Sie, bis das Fenster automatisch geschlossen wird. Sie werden zur Seite Site Recovery weitergeleitet.
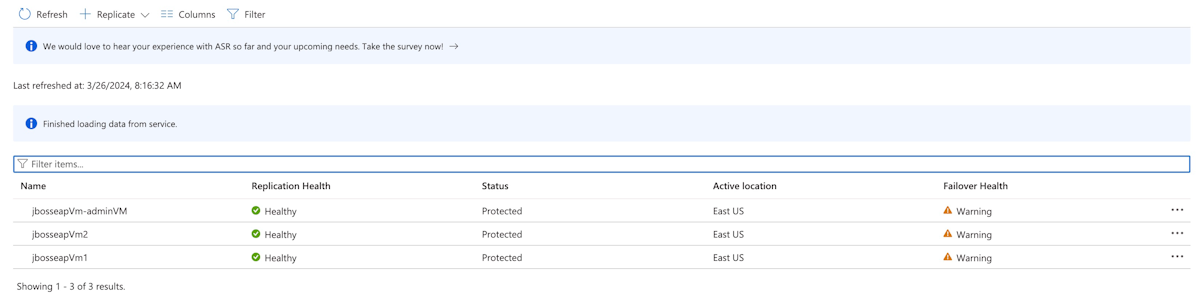
Klicken Sie unter Geschützte Elemente auf Replizierte Elemente. Zunächst sind keine Elemente aufgelistet, da die Replikation noch ausgeführt wird. Die Replikation benötigt Zeit, um abgeschlossen zu werden - ca. 1 Stunde für dieses Tutorial. Aktualisieren Sie die Seite in regelmäßigen Abständen, bis für alle virtuellen Computer Geschützt angezeigt wird, wie im folgenden Screenshot dargestellt:

Erstellen Sie als Nächstes einen Wiederherstellungsplan, der alle replizierten Elemente einschließt, sodass ein gemeinsames Failover möglich ist. Verwenden Sie die Anweisungen unter Erstellen eines Wiederherstellungsplans mit der folgenden Anpassung:
- Geben Sie in Schritt 2 einen Namen für den Plan ein, z. B.
recovery-plan-gzh032124. - Wählen Sie in Schritt 3 für Quelle die Option USA, Osten und für Ziel die Option USA, Westen 2 aus.
- Wählen Sie in Schritt 4 für Elemente auswählen alle geschützten Elemente aus, zum Beispiel die drei geschützten virtuellen Computer für dieses Tutorial.
Lassen Sie die Seite geöffnet, um sie später zum Testen des Failovers zu verwenden.
Einrichten von Azure Traffic Manager
In diesem Abschnitt erstellen Sie einen Azure Traffic Manager zur Verteilung von Datenverkehr an Ihre öffentlich zugänglichen Anwendungen über Azure-Regionen hinweg. Der primäre Endpunkt verweist auf die öffentliche IP-Adresse des Application Gateway in der primären Region und der sekundäre Endpunkt auf die öffentliche IP-Adresse des Application Gateway in der sekundären Region.
Erstellen Sie ein Azure Traffic Manager-Profil, indem Sie den Anweisungen im Schnellstart folgen: Erstellen eines Traffic Manager-Profils mithilfe des Azure-Portals. Sie benötigen nur die folgenden Abschnitte: Erstellen eines Traffic Manager-Profils und Hinzufügen von Traffic Manager-Endpunkten. Führen Sie die folgenden Schritte aus, während Sie die folgenden Abschnitte durchlaufen, und kehren Sie nach dem Erstellen und Konfigurieren des Azure Traffic Managers zu diesem Artikel zurück.
Wenn Sie den Abschnitt Erstellen eines Traffic Manager-Profils erreichen verwenden Sie in Schritt 2 Erstellen des Traffic Manager-Profils die folgenden Schritte:
- Notieren Sie den eindeutigen Traffic Manager-Profilnamen für Name, z. B.
tm-profile-gzh032124. - Notieren Sie den neuen Ressourcengruppennamen für Ressourcengruppe, z. B.
myResourceGroupTM1.
- Notieren Sie den eindeutigen Traffic Manager-Profilnamen für Name, z. B.
Gehen Sie wie folgt vor, wenn Sie den Abschnitt Hinzufügen von Traffic Manager-Endpunkten erreichen:
Nachdem Sie das Traffic Manager-Profil in Schritt 2 geöffnet haben, führen Sie auf der Seite Konfiguration die folgenden Schritte aus:
Geben Sie für DNS time to live (TTL) die Zahl 10 ein.
Verwenden Sie unter Einstellungen für schnelles Endpunktfailover die folgenden Werte:
- Wählen Sie für Interner Test die Zahl 10 aus.
- Geben Sie für Tolerierte Anzahl von Fehlern die Zahl 3 ein.
- Geben Sie für Testtimeout die Zahl 5 ein.
Wählen Sie Speichern. Warten Sie, bis der Vorgang abgeschlossen ist.
Verwenden Sie in Schritt 4 zum Hinzufügen des primären Endpunkts
myPrimaryEndpointdie folgenden Schritte:Wählen Sie für Zielressourcentyp die Option Öffentliche IP-Adresse aus.
Wählen Sie die Dropdownliste Öffentliche IP-Adresse auswählen aus, und geben Sie den Namen der öffentlichen IP-Adresse von Application Gateway in der Region USA, Osten ein. Sie sollten einen übereinstimmenden Eintrag sehen. Wählen Sie diesen für Öffentliche IP-Adresse aus.
Gehen Sie in Schritt 6 zum Hinzufügen eines sekundären Failover-Endpunkts
myFailoverEndpointwie folgt vor:Wählen Sie für Zielressourcentyp die Option Öffentliche IP-Adresse aus.
Wählen Sie die Dropdownliste Öffentliche IP-Adresse auswählen aus, und geben Sie den Namen der öffentlichen IP-Adresse von Application Gateway in der Region USA, Westen 2 ein. Sie sollten einen übereinstimmenden Eintrag sehen. Wählen Sie diesen für Öffentliche IP-Adresse aus.
Warten Sie einen Moment. Wählen Sie Aktualisieren aus, bis der Überwachungsstatus für den Endpunkt
myPrimaryEndpointOnline und der Überwachungsstatus für den EndpunktmyFailoverEndpointHerabgestuft ist.
Überprüfen Sie anschließend anhand der folgenden Schritte, ob auf die im primären JBoss EAP Cluster bereitgestellte Beispiel App über das Traffic Manager Profil zugegriffen werden kann:
Wählen Sie Übersicht für das Traffic Manager-Profil aus, das Sie erstellt haben.
Überprüfen und kopieren Sie den DNS-Namen des Traffic Manager Profils. Fügen Sie /javaee-cafe/ an. Beispiel:
http://tm-profile-gzh032124.trafficmanager.net/javaee-cafe/.Öffnen Sie die URL in einer neuen Registerkarte des Browsers. Der von Ihnen erstellte Kaffee sollte nun auf der Seite angezeigt werden.
Wenn Ihre Benutzeroberfläche nicht ähnlich aussieht, führen Sie die Problembehebung durch und lösen Sie das Problem, bevor Sie fortfahren. Lassen Sie die Konsole geöffnet, und verwenden Sie sie später für den Failovertest.
Jetzt können Sie das Traffic Manager-Profil einrichten. Halten Sie die Seite geöffnet, sodass Sie sie später für die Überwachung der Endpunktstatusänderung bei einem Failover-Ereignis verwenden können.
Testen des Failovers vom primären zum sekundären Standort
In den Schritten in diesem Abschnitt wird das Failover getestet, indem Sie im Azure-Portal ein manuelles Failover für den Azure SQL-Datenbank-Server und -Cluster von der primären auf die sekundäre Instanz und wieder auf die primäre Instanz ausführen.
Failover an den sekundären Standort
Verwenden Sie zunächst die folgenden Schritte, um ein Failover der Azure SQL-Datenbank vom primären Server zum sekundären Server durchzuführen:
- Wechseln Sie zur Browserregisterkarte Ihrer Azure SQL-Datenbank-Failovergruppe, z. B.
failovergroup-gzh032124. - Wählen Sie Failover>Ja aus.
- Warten Sie, bis der Vorgang abgeschlossen ist.
Führen Sie als Nächstes die folgenden Schritte aus, um ein Failover des JBoss EAP-Clusters mit dem Wiederherstellungsplan durchzuführen:
Geben Sie im Suchfeld oben im Azure-Portal Recovery Services-Tresore ein, und wählen Sie Recovery Services-Tresore in den Suchergebnissen aus.
Wählen Sie den Namen Ihres Recovery Services-Tresors aus, z. B.
recovery-service-vault-westus-gzh032124.Klicken Sie unter Verwalten auf Wiederherstellungspläne (Site Recovery). Wählen Sie den Wiederherstellungsplan aus, den Sie erstellt haben, z. B.
recovery-plan-gzh032124.Wählen Sie Failover aus. Wählen Sie Ich kenne die Risiken. Testfailover überspringen. aus. Belassen Sie die Standardeinstellungen für die anderen Werte. Wählen Sie OK aus.
Hinweis
Sie können optional Testfailover und Testfailover bereinigen ausführen, um vor dem Failover sicherzustellen, dass alles wie erwartet funktioniert. Weitere Informationen finden Sie unter Tutorial: Ausführen eines Notfallwiederherstellungsverfahrens für Azure-VMs. In diesem Tutorial wird das Failover direkt verwendet, um die Übung zu vereinfachen.
Überwachen Sie das Failover in Benachrichtigungen, bis es abgeschlossen ist. Die Übung in diesem Tutorial dauert etwa 10 Minuten.
Führen Sie ein Commit für das Failover aus.
Vergewissern Sie sich, dass die Schritte im vorherigen Abschnitt erfolgreich vervollständigt wurden. Führen Sie dann die folgenden Schritte aus, um das Failover zu committen:
Geben Sie im Suchfeld oben im Azure-Portal Recovery Services-Tresore ein, und wählen Sie die entsprechende Option in den Suchergebnissen aus.
Wählen Sie Ihren Recovery Services-Tresor aus, z. B.
recovery-service-vault-westus-gzh032124.Wählen Sie im Abschnitt Verwalten die Option Wiederherstellungspläne (Site Recovery) aus.
Wählen Sie den Wiederherstellungsplan aus, z. B.
recovery-plan-gzh032124.Wählen Sie Commit und dann OK aus.
Überwachen Sie die Benachrichtigungen, bis der Vorgang abgeschlossen ist.

Wählen Sie Elemente im Wiederherstellungsplan aus. Es sollten drei Elemente angezeigt werden, die mit Commit für Failover ausgeführt aufgeführt sind.

Deaktivieren der Replikation
Führen Sie die folgenden Schritte aus, um die Replikation für Elemente im Wiederherstellungsplan zu deaktivieren und den Wiederherstellungsplan zu löschen:
- Klicken Sie bei jedem Element in Elemente im Wiederherstellungsplan mit der rechten Maustaste auf das Element, und wählen Sie Replikation deaktivieren aus.
- Wenn Sie aufgefordert werden, einen Grund oder Gründe für die Deaktivierung des Schutzes für diesen virtuellen Computer anzugeben, wählen Sie Ihren bevorzugten Grund aus – z. B. Ich habe die Migration meiner Anwendung abgeschlossen. Wählen Sie OK aus.
- Wiederholen Sie Schritt 1, bis Sie die Replikation für alle Elemente deaktivieren.
- Überwachen Sie den Prozess in Benachrichtigungen, bis er abgeschlossen ist.
- Wählen Sie Übersicht>Löschen aus. Wählen Sie Ja aus, um den Löschvorgang zu bestätigen.
Erneutes Schützen des Failoverstandorts
Die sekundäre Region ist nun der Failoverstandort und ist aktiv, daher sollten Sie ihn in Ihrer primären Region erneut schützen.
Bereinigen Sie zunächst die Ressourcen in der Ressourcengruppe mit dem Namen jboss-eap-cluster-eastus-gzh032124, die nicht mehr verwendet werden.
Geben Sie im Suchfeld oben im Azure-Portal Ressourcengruppen ein, und wählen Sie dann in den Suchergebnissen Ressourcengruppen aus.
Wählen Sie den Namen der Ressourcengruppe für Ihre neu erstellte sekundäre Region.
Wählen Sie neben dem Textbereich Nach einem beliebigen Feld filtern... das X aus, um alle Filter zu entfernen.
Klicken Sie auf Filter hinzufügen. Legen Sie Filter auf Typ fest. Legen Sie Operator auf Ist gleich fest.
Wählen Sie das Dropdownmenü neben dem Feld Wert aus.
Schalten Sie das Kontrollkästchen Alle auswählen um, bis keine Werte mehr ausgewählt sind.
Stellen Sie sicher, dass alle der folgenden Typen ausgewählt sind:
- Virtueller Computer
- Datenträger
- Privater Endpunkt
- Netzwerkschnittstelle
- Storage-Konto
Wählen Sie das Dropdownmenü neben dem Feld Wert aus, um das Dropdownmenü zu schließen. Für den Wert Wert muss 5 Ressourcentypen angezeigt werden.
Wählen Sie Übernehmen.
Aktivieren Sie das Kontrollkästchen neben der Bezeichnung Name oben in der gefilterten Liste.
Klicken Sie auf Löschen.
Geben Sie Löschen ein, um den Löschvorgang zu bestätigen und wählen Sie dann Löschen. Überwachen Sie den Prozess in Benachrichtigungen, bis er abgeschlossen ist.
Führen Sie als Nächstes dieselben Schritte unter Einrichten der Notfallwiederherstellung für den Cluster mit Azure Site Recovery in der primären Region mit Ausnahme der folgenden Unterschiede aus:
Führen Sie für Erstellen eines Recovery Services-Tresors die folgenden Schritte aus:
- Wählen Sie die in der primären Region bereitgestellten Ressourcengruppe aus, z. B.
jboss-eap-cluster-eastus-gzh032124. - Geben Sie einen anderen Namen für den Diensttresor ein, z. B.
recovery-service-vault-eastus-gzh032124. - Wählen Sie USA, Osten als Region aus.
- Wählen Sie die in der primären Region bereitgestellten Ressourcengruppe aus, z. B.
Verwenden Sie für Replikation aktivieren die folgenden Schritte:
Wählen Sie für Region in Quelle die Option USA, Westen 2 aus.
Führen Sie für Replikationseinstellungen die folgenden Schritte aus:
Wählen Sie für Zielressourcengruppe die vorhandene Ressourcengruppe aus, die in der primären Region bereitgestellt wurde, z. B.
jboss-eap-cluster-eastus-gzh032124.Wählen Sie für Failover für virtuelles Netzwerk ausführen das vorhandene virtuelle Netzwerk in der primären Region aus.
Wählen Sie für Wiederherstellungsplan erstellen und für Quelle die Option USA, Westen 2 und für Ziel die Option USA, Osten aus.
Hinweis
Möglicherweise stellen Sie fest, dass Azure Site Recovery das Neustarten der Schutzfunktion für VMs unterstützt, wenn die Ziel-VM vorhanden ist. Weitere Informationen finden Sie im Abschnitt Erneutes Schützen der VM im Tutorial: Ausführen eines Failovers in eine sekundäre Region für Azure-VMs. Es funktioniert jedoch nicht, wenn die einzigen Änderungen zwischen dem Quelldatenträger und dem Zieldatenträger basierend auf dem Überprüfungsergebnis für den JBoss EAP-Cluster synchronisiert werden. In diesem Tutorial wird nach dem Failover eine neue Replikation vom sekundären Standort zum primären Standort eingerichtet, wobei alle Datenträger aus der Region, für die ein Failover ausgeführt wurde, in die primäre Region kopiert werden. Weitere Informationen erhalten Sie im Abschnitt Was geschieht beim erneuten Schützen? unter Erneutes Schützen von virtuellen Azure-Computern, für die ein Failover zur primären Region durchgeführt wurde.
Failback zum primären Standort
Führen Sie die gleichen Schritte im Abschnitt Failover an den sekundären Standort aus, um ein Failback auf den primären Standort einschließlich Datenbankserver und Cluster durchzuführen, mit Ausnahme der folgenden Unterschiede:
Wählen Sie den in der primären Region bereitgestellten Wiederherstellungsdiensttresor aus, z. B.
recovery-service-vault-eastus-gzh032124.Wählen Sie die in der primären Region bereitgestellten Ressourcengruppe aus, z. B.
jboss-eap-cluster-eastus-gzh032124.Wählen Sie im Abschnitt Ein Commit für das Failover ausführen Ihren Recovery Services-Tresor aus, den Sie am primären Standort bereitgestellt haben, z. B.
recovery-service-vault-eastus-gzh032124.Im Traffic Manager-Profil sollte Ihnen angezeigt werden, dass der Endpunkt
myPrimaryEndpointin Online geändert wird und der EndpunktmyFailoverEndpointzu Herabgestuft wechselt.Führen Sie im Abschnitt Erneutes Schützen des Failoverstandorts die folgenden Schritte aus:
Die primäre Region ist Ihr Failoverstandort und ist aktiv, daher sollten Sie ihn in Ihrer sekundären Region erneut schützen.
Bereinigen Sie die in Ihrer sekundären Region bereitgestellte Ressource, z. B. Ressourcen, die in
jboss-eap-cluster-westus-gzh032124bereitgestellt wurden.Verwenden Sie dieselben Schritte im Abschnitt Einrichten der Notfallwiederherstellung für den Cluster mit Azure Site Recovery zum Schutz der primären Region in der sekundären Region mit Ausnahme der folgenden Schritte:
Überspringen Sie die Schritte unter Erstellen eines Recovery Services-Tresors, da Sie bereits einen Erstellen eines Recovery Services-Tresor erstellt haben, z. B.
recovery-service-vault-westus-gzh032124.Wählen Sie für Replikation aktivieren>Replikationseinstellungen>Failover für virtuelles Netzwerk durchführen das vorhandene Netzwerk in der sekundären Region aus.
Bereinigen von Ressourcen
Wenn Sie die JBoss-EAP-Cluster und andere Komponenten nicht weiterhin verwenden werden, führen Sie die folgenden Schritte aus, um die Ressourcengruppen zu löschen und die in diesem Lernprogramm verwendeten Ressourcen zu säubern:
Geben Sie den Namen der Ressourcengruppe der Azure SQL Database Server - zum Beispiel
sqlserver-rg-gzh032124- in das Suchfeld oben im Azure-Portal ein. Wählen Sie dann die übereinstimmende Ressourcengruppe aus den Suchergebnissen aus.Wählen Sie die Option Ressourcengruppe löschen.
Geben Sie unter Ressourcengruppennamen eingeben, um den Löschvorgang zu bestätigen den Ressourcengruppennamen ein.
Klicken Sie auf Löschen.
Wiederholen Sie die Schritte 1–4 für die Ressourcengruppe von Traffic Manager, z. B.
myResourceGroupTM1.Geben Sie im Suchfeld oben im Azure-Portal Recovery Services-Tresore ein, und wählen Sie dann Recovery Services-Tresore in den Suchergebnissen aus.
Wählen Sie den Namen Ihres Recovery Services-Tresors aus, z. B.
recovery-service-vault-westus-gzh032124.Klicken Sie unter Verwalten auf Wiederherstellungspläne (Site Recovery). Wählen Sie den Wiederherstellungsplan aus, den Sie erstellt haben, z. B.
recovery-plan-gzh032124.Verwenden Sie dieselben Schritte im Abschnitt Deaktivieren der Replikation, um Sperren für replizierte Elemente zu entfernen.
Wiederholen Sie die Schritte 1-4 für die Ressourcengruppe des primären JBoss EAP Clusters - z.B.
jboss-eap-cluster-westus-gzh032124.Wiederholen Sie die Schritte 1-4 für die Ressourcengruppe des sekundären JBoss EAP Clusters, z.B.
jboss-eap-cluster-eastus-gzh032124.
Nächste Schritte
In diesem Tutorial richten Sie eine HA/DR-Lösung ein, die aus einer Aktiv-Passiv-Anwendungsinfrastrukturebene mit einer Aktiv-Passiv-Datenbankebene besteht und in der sich beide Ebenen über zwei geografisch unterschiedliche Standorte erstrecken. Am ersten Standort ist sowohl die Anwendungsinfrastrukturebene als auch die Datenbankebene aktiv. Am zweiten Standort wird die sekundäre Domäne mit dem Azure Site Recovery-Dienst wiederhergestellt, und die sekundäre Datenbank befindet sich im Standbymodus.
Entdecken Sie die folgenden Referenzen für weitere Optionen zum Aufbau von HA/DR-Lösungen und zum Ausführen von JBoss EAP auf Azure: