Manuelles Bereitstellen einer Java-Anwendung mit JBoss EAP auf einem Azure Red Hat OpenShift-Cluster
In diesem Artikel erfahren Sie, wie Sie eine Red Hat JBoss Enterprise Application Platform (EAP)-Anwendung in einem Azure Red Hat OpenShift-Cluster bereitstellen. Das Beispiel ist eine Java-Anwendung, die von einer SQL-Datenbank unterstützt wird. Die App wird mithilfe von JBoss EAP Helm Charts bereitgestellt.
In diesem Leitfaden erfahren Sie, wie Sie:
- Bereiten Sie eine JBoss EAP-Anwendung für OpenShift vor.
- Erstellen Sie eine einzelne Datenbankinstanz der Azure SQL-Datenbank.
- Da Azure Workload Identity von Azure OpenShift noch nicht unterstützt wird, verwendet dieser Artikel weiterhin Benutzernamen und Kennwort für die Datenbankauthentifizierung, anstatt kennwortlose Datenbankverbindungen zu verwenden.
- Bereitstellen der Anwendung auf einem Azure Red Hat OpenShift-Cluster mithilfe von JBoss Helm Charts und OpenShift Web Console
Die Beispielanwendung ist eine zustandsbehaftete Anwendung, die Informationen in einer HTTP-Sitzung speichert. Es nutzt die JBoss EAP-Clustering-Funktionen und verwendet die folgenden Jakarta EE- und MicroProfile-Technologien:
- Jakarta Server Faces
- Jakarta Enterprise Beans
- Jakarta Persistence
- MicroProfile Health
Dieser Artikel enthält schrittweise Anleitungen zum Ausführen der JBoss EAP-App auf einem Azure Red Hat OpenShift-Cluster. Eine automatisiertere Lösung, die Ihren Weg zum Azure Red Hat OpenShift-Cluster beschleunigt, finden Sie in der Schnellstartanleitung: Bereitstellen von JBoss EAP auf Azure Red Hat OpenShift mithilfe des Azure-Portal.
Wenn Sie Feedback geben oder eng an Ihrem Migrationsszenario mit dem Entwicklungsteam arbeiten möchten, das JBoss EAP für Azure-Lösungen entwickelt, füllen Sie diese kurze Umfrage zur JBoss EAP-Migration aus, und schließen Sie Ihre Kontaktinformationen ein. Das Team aus Programmmanagern, Architekten und Ingenieuren wird sich umgehend mit Ihnen in Verbindung setzen, um eine enge Zusammenarbeit zu initiieren.
Wichtig
In diesem Artikel wird eine Anwendung mit JBoss EAP Helm Charts bereitgestellt. Zum Zeitpunkt der Artikelerstellung wurde dieses Feature noch als Technology Preview bereitgestellt. Vergewissern Sie sich vor dem Bereitstellen von Anwendungen mit JBoss EAP Helm Charts in Produktionsumgebungen, dass dieses Feature ein unterstütztes Feature für Ihre JBoss EAP/XP-Produktversion ist.
Wichtig
Während Red Hat und Microsoft Azure gemeinsam Azure Red Hat OpenShift entwickeln, betreiben und unterstützen, um eine integrierte Supporterfahrung bereitzustellen, unterliegt die Software, die Sie auf Azure Red Hat OpenShift ausführen, einschließlich der in diesem Artikel beschriebenen, eigenen Support- und Lizenzbedingungen. Ausführliche Informationen zur Unterstützung von Azure Red Hat OpenShift finden Sie im Supportlebenszyklus für Azure Red Hat OpenShift 4. Ausführliche Informationen zur Unterstützung der Software, die in diesem Artikel beschrieben wird, finden Sie auf den Hauptseiten der Software, die im Artikel aufgeführt ist.
Voraussetzungen
Hinweis
Für Azure Red Hat OpenShift sind mindestens 40 Kerne erforderlich, um einen OpenShift-Cluster zu erstellen und auszuführen. Das Standardmäßige Azure-Ressourcenkontingent für ein neues Azure-Abonnement erfüllt diese Anforderung nicht. Weitere Informationen zum Anfordern einer Erhöhung des Ressourcenlimits finden Sie unter Standardkontingent: Erhöhen der Grenzwerte nach VM-Serie beschrieben. Das kostenlose Test-Abonnement ist nicht für eine Kontingentserhöhung geeignet. Upgraden Sie auf ein Pay-as-you-go Abonnement, bevor Sie eine Kontingentanfrage stellen.
Bereiten Sie einen lokalen Computer mit einem unixähnlichen Betriebssystem vor, das von den verschiedenen installierten Produkten unterstützt wird – z. B. Ubuntu, macOS oder Windows-Subsystem für Linux.
Installieren Sie eine Se-Implementierung (Java Standard Edition). Die lokalen Entwicklungsschritte in diesem Artikel wurden mit Java Development Kit (JDK) 17 aus dem Microsoft-Build von OpenJDK getestet.
Installieren Sie Maven 3.8.6 oder höher.
Installieren Sie Azure CLI 2.40 oder höher.
Klonen Sie den Code für diese Demoanwendung (todo-list) in Ihr lokales System. Die Demoanwendung finden Sie unter GitHub.
Führen Sie die Schritte in Tutorial: Erstellen eines Azure Red Hat OpenShift 4-Clusters aus.
Der Schritt „Abrufen eines Red Hat-Pull-Secrets“ wird zwar als optional bezeichnet, ist jedoch für diesen Artikel erforderlich. Das Pull-Geheimnis ermöglicht Ihrem Azure Red Hat OpenShift-Cluster die Suche nach den JBoss EAP-Anwendungsimages.
Wenn Sie planen, arbeitsspeicherintensive Anwendungen im Cluster auszuführen, geben Sie die richtige Größe des virtuellen Computers für die Workerknoten mit dem
--worker-vm-size-Parameter an. Weitere Informationen finden Sie unter:Stellen Sie eine Verbindung mit dem Cluster her, indem Sie die Schritte in Tutorial: Herstellen einer Verbindung mit einem Azure Red Hat OpenShift 4-Cluster ausführen.
- Ausführen der Schritte in „Installieren der OpenShift-CLI“
- Herstellen einer Verbindung mit einem Azure Red Hat OpenShift-Cluster mithilfe der OpenShift-CLI mit dem Benutzer
kubeadmin
Führen Sie den folgenden Befehl aus, um das OpenShift-Projekt für diese Demoanwendung zu erstellen:
oc new-project eap-demoFühren Sie den folgenden Befehl aus, um dem Standarddienstkonto die Rolle zum Anzeigen hinzuzufügen. Diese Rolle ist erforderlich, damit die Anwendung andere Pods ermitteln und einen Cluster mit ihnen einrichten kann:
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Vorbereiten der Anwendung
Klonen Sie die Beispielanwendung mit dem folgenden Befehl:
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Sie haben die Todo-list Demo-Anwendung geklont und Ihr lokales Repository befindet sich auf dem Main-Branch. Die Demoanwendung ist eine einfache Java-App, die Datensätze in Azure SQL erstellt, liest, aktualisiert und löscht. Sie können diese Anwendung wie auf einem JBoss-EAP-Server bereitstellen, der auf Ihrem lokalen Computer installiert ist. Sie müssen lediglich den Server mit dem erforderlichen Datenbanktreiber und der erforderlichen Datenquelle konfigurieren. Außerdem benötigen Sie einen Datenbankserver, auf den aus Ihrer lokalen Umgebung zugegriffen werden kann.
Wenn Sie jedoch auf OpenShift abzielen, sollten Sie die Funktionen Ihres JBoss-EAP-Servers kürzen. Sie können z. B. die Sicherheitsrisiken des bereitgestellten Servers verringern und den Gesamtbedarf verringern. Zudem sollten Sie unter Umständen einige MicroProfile-Spezifikationen einbinden, sodass sich Ihre Anwendung zum Ausführen in einer OpenShift-Umgebung besser eignet. Wenn Sie JBoss EAP verwenden, besteht eine Möglichkeit zum Ausführen dieser Aufgabe darin, Ihre Anwendung und Ihren Server in einer einzigen Bereitstellungseinheit zu packen, die als bootfähiges JAR bezeichnet wird. Nehmen Sie dazu an der Demoanwendung die erforderlichen Änderungen vor.
Navigieren Sie zu Ihrem lokalen Repository für die Demo-Anwendung und ändern Sie den Branch in bootable-jar:
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Hier finden Sie eine kurze Übersicht darüber, was in diesem Branch geändert wurde:
- Wir haben das
wildfly-jar-mavenPlug-In hinzugefügt, um den Server und die Anwendung in einer einzigen ausführbaren JAR-Datei bereitzustellen. Die OpenShift-Bereitstellungseinheit ist unser Server mit unserer Anwendung. - Im Maven-Plug-In haben wir eine Reihe von Galleon-Schichten angegeben. Diese Konfiguration ermöglicht es uns, die Serverfunktionen nur auf das zu kürzen, was wir benötigen. Eine umfassende Dokumentation zu Galleon finden Sie in der Dokumentation zu WildFly.
- Unsere Anwendung verwendet Jakarta Faces mit Ajax-Anforderungen, was bedeutet, dass in der HTTP-Sitzung Informationen gespeichert sind. Diese Informationen sollen nicht verloren gehen, wenn ein Pod entfernt wird. Wir könnten diese Informationen auf dem Client speichern und bei jeder Anforderung zurücksenden. Es gibt jedoch Fälle, in denen Sie sich entscheiden können, bestimmte Informationen nicht an die Clients zu verteilen. Für diese Demo haben wir beschlossen, die Sitzung in allen Podreplikaten zu replizieren. Dazu haben wir
<distributable />zu web.xmlhinzugefügt. Dadurch wird die HTTP-Sitzung zusammen mit den Serverclusteringfunktionen über alle Pods verteilt. - Wir haben zwei MicroProfile-Integritätsprüfungen hinzugefügt, mit denen Sie ermitteln können, wann die Anwendung live ist und bereit für den Empfang von Anforderungen ist.
Lokales Ausführen der Anwendung
Bevor Sie die Anwendung auf OpenShift bereitstellen, führen wir sie lokal aus, um zu überprüfen, wie sie funktioniert. Bei den folgenden Schritten wird davon ausgegangen, dass Azure SQL ausgeführt und in Ihrer lokalen Umgebung verfügbar ist.
Führen Sie zum Erstellen der Datenbank die Schritte in Schnellstart: Erstellen einer einzelnen Datenbank in Azure SQL-Datenbank aus, aber verwenden Sie die folgenden Ersetzungen.
- Verwenden Sie für die Ressourcengruppe die zuvor erstellte Ressourcengruppe.
- Verwenden Sie als
todos_db. - Verwenden Sie als
azureuser. - Verwenden Sie als
Passw0rd!. - Stellen sie im Abschnitt Firewallregeln die Option Azure-Diensten und -Ressourcen Zugriff auf diesen Server erlauben auf Ja.
Alle anderen Einstellungen können aus dem verknüpften Artikel übernommen werden.
Auf der Seite "Zusätzliche Einstellungen " müssen Sie nicht die Option auswählen, um die Datenbank mit Beispieldaten vorzufüllen, aber dies hat keinen Schaden.
Nachdem Sie die Datenbank erstellt haben, rufen Sie den Wert für den Servernamen auf der Übersichtsseite ab. Zeigen Sie mit dem Mauszeiger auf den Wert des Felds Servername, und wählen Sie das Symbol „Kopieren“ aus, das neben dem Wert angezeigt wird. Speichern Sie diesen Wert zur späteren Verwendung beiseite (wir legen eine Variable fest, die auf diesen Wert benannt ist MSSQLSERVER_HOST ).
Hinweis
Um die Kosten niedrig zu halten, leitet der Schnellstart die Leser*innen an, den serverlosen Computetarif auszuwählen. Diese Ebene wird auf Null skaliert, wenn keine Aktivität vorhanden ist. In diesem Fall reagiert die Datenbank nicht sofort. Wenn Sie bei der Ausführung der Schritte in diesem Artikel zu einem beliebigen Zeitpunkt Datenbankprobleme beobachten, sollten Sie die automatische Pause deaktivieren. Um zu erfahren, wie dies funktioniert, suchen Sie in Azure SQL-Datenbank serverlos nach „AutoAnhalten“. Zum Zeitpunkt des Schreibens deaktiviert der folgende Azure CLI-Befehl die automatische Pause für die in diesem Artikel konfigurierte Datenbank: az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Führen Sie die folgenden Schritte aus, um die Anwendung lokal zu erstellen und auszuführen.
Erstellen Sie die startbare JAR-Datei. Da wir die
eap-datasources-galleon-packMs SQL Server-Datenbank verwenden, müssen wir die Datenbanktreiberversion angeben, die wir mit dieser spezifischen Umgebungsvariable verwenden möchten. Weitere Informationen zu deneap-datasources-galleon-packund MS SQL Server finden Sie in der Dokumentation von Red Hatexport MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageStarten Sie die startbare JAR-Datei mit den folgenden Befehlen.
Sie müssen sicherstellen, dass die Azure SQL-Datenbank Netzwerkdatenverkehr vom Host zulässt, auf dem dieser Server ausgeführt wird. Da Sie beim Ausführen der Schritte in Schnellstart: Erstellen einer einzelnen Azure SQL-Datenbankinstanz die Option Aktuelle Client-IP-Adresse hinzufügen ausgewählt haben, sollte Netzwerkdatenverkehr zugelassen werden, wenn es sich bei dem Host, auf dem der Server ausgeführt wird, um denselben Host handelt, von dem Ihr Browser eine Verbindung mit dem Azure-Portal herstellt. Wenn der Host, auf dem der Server ausgeführt wird, ein anderer Host ist, müssen Sie sich auf die Verwendung der Azure-Portal zum Verwalten von IP-Firewallregeln auf Serverebene beziehen.
Beim Starten der Anwendung müssen wir die erforderlichen Umgebungsvariablen übergeben, um die Datenquelle zu konfigurieren:
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runWenn Sie mehr über die zugrunde liegende Runtime erfahren möchten, die in dieser Demo verwendet wird, finden Sie in der Dokumentation zu Galleon-Featurepaket für das Integrieren mit Datenquellen eine vollständige Liste der verfügbaren Umgebungsvariablen. Ausführliche Informationen zum Konzept von Feature Packs finden Sie in der Dokumentation zu WildFly.
Wenn sie einen Fehler mit Text erhalten, der dem folgenden Beispiel ähnelt:
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Diese Meldung gibt an, dass Ihre Schritte, um sicherzustellen, dass der Netzwerkdatenverkehr zulässig ist, nicht funktioniert hat. Stellen Sie sicher, dass die IP-Adresse aus der Fehlermeldung in den Firewallregeln enthalten ist.
Wenn Sie eine Nachricht mit Text erhalten, der dem folgenden Beispiel ähnelt:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Diese Meldung bedeutet, dass die Beispieldaten bereits in der Datenbank enthalten sind. Diese Meldung können Sie ignorieren.
(Optional) Wenn Sie die Clusteringfunktionen überprüfen möchten, können Sie auch weitere Instanzen derselben Anwendung starten, indem Sie das Argument
jboss.node.namean die startbare JAR-Datei übergeben und zur Vermeidung von Konflikten mit den Portnummern die Portnummern mithilfe vonjboss.socket.binding.port-offsetverschieben. Um beispielsweise eine zweite Instanz zu starten, die einen neuen Pod auf OpenShift darstellt, können Sie den folgenden Befehl in einem neuen Terminalfenster ausführen:export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Wenn Ihr Cluster funktioniert, sehen Sie in der Serverkonsole eine Ablaufverfolgung ähnlich der folgenden:
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbHinweis
Standardmäßig konfiguriert die startbare JAR-Datei das JGroups-Subsystem für die Verwendung des UDP-Protokolls und sendet Nachrichten, um andere Clustermitglieder für die Multicastadresse 230.0.0.4 zu ermitteln. Wenn Sie die Clusteringfunktionen auf Ihrem lokalen Computer ordnungsgemäß überprüfen möchten, sollte Ihr Betriebssystem in der Lage sein, Multicast-Datagramme zu senden und zu empfangen und sie über Ihre Ethernet-Schnittstelle an die IP-Adresse 230.0.0.4 weiterzuleiten. Wenn in den Serverprotokollen Warnungen im Zusammenhang mit dem Cluster angezeigt werden, überprüfen Sie Ihre Netzwerkkonfiguration und ob diese Multicast an dieser Adresse unterstützt.
Öffnen Sie http://localhost:8080/ in Ihrem Browser, um die Startseite der Anwendung aufzurufen. Wenn Sie weitere Instanzen erstellt haben, können Sie darauf zugreifen, indem Sie die Portnummer verschieben, z. B. http://localhost:9080/. Die Anwendung sollte ähnlich wie in der folgenden Abbildung aussehen:
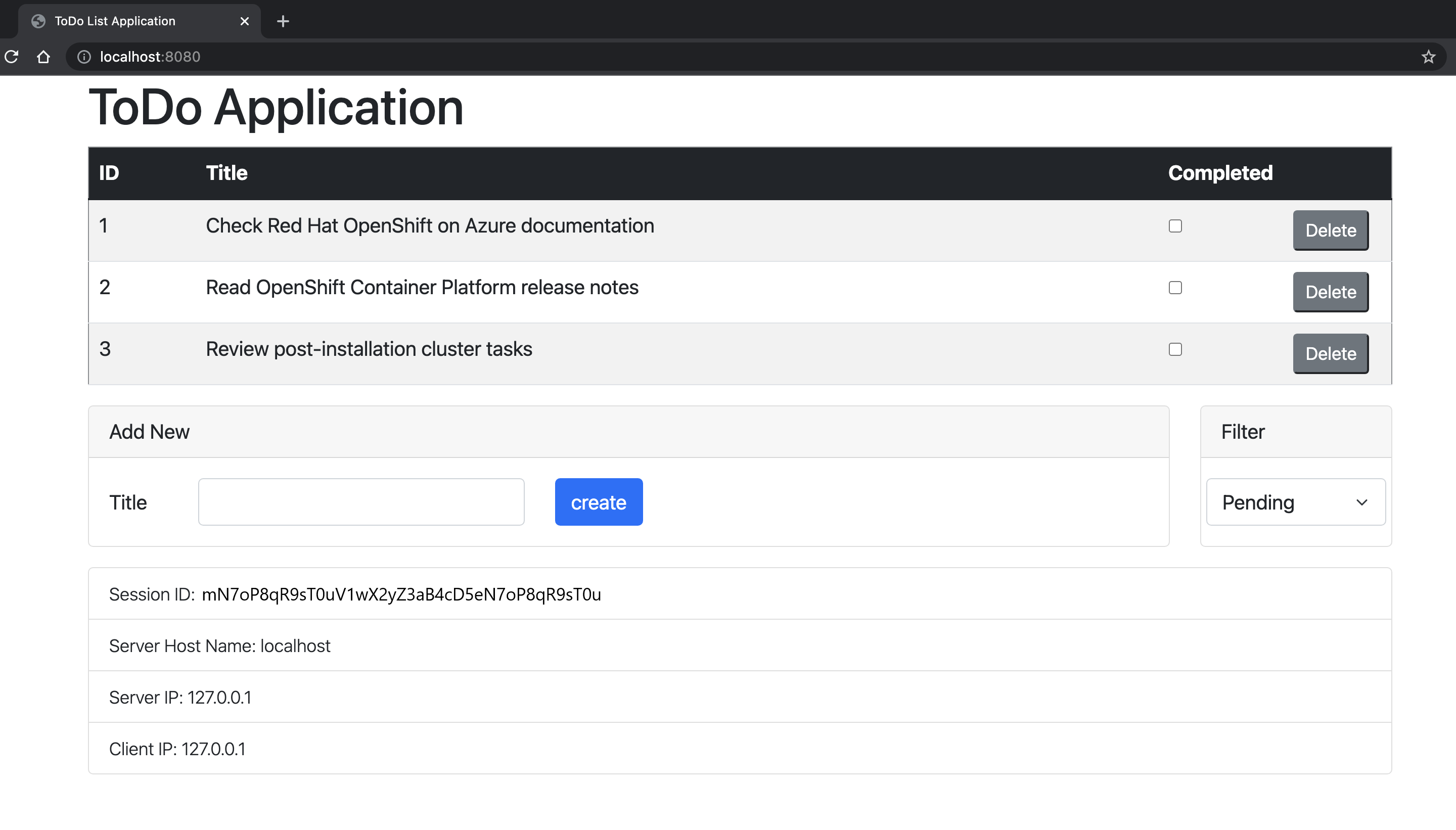
Überprüfen Sie Live- und Bereitschaftstests für die Anwendung. OpenShift verwendet diese Endpunkte, um zu überprüfen, wann Ihr Pod live ist und bereit für den Empfang von Benutzeranforderungen ist.
Um den Status des Livetests zu überprüfen, führen Sie Folgendes aus:
curl http://localhost:9990/health/liveDie folgende Ausgabe sollte angezeigt werden:
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Führen Sie Folgendes aus, um den Status der Bereitschaft zu überprüfen:
curl http://localhost:9990/health/readyDie folgende Ausgabe sollte angezeigt werden:
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Drücken Sie STRG+C, um die Anwendung zu beenden.
Bereitstellen in OpenShift
Um die Anwendung bereitzustellen, verwenden wir die bereits in Azure Red Hat OpenShift verfügbaren JBoss EAP Helm Charts. Außerdem müssen wir die gewünschte Konfiguration angeben, z. B. den Datenbankbenutzer, das Datenbankkennwort, die zu verwendende Treiberversion und die von der Datenquelle verwendeten Verbindungsinformationen. Bei den folgenden Schritten wird davon ausgegangen, dass Azure SQL über Ihren OpenShift-Cluster ausgeführt und zugänglich ist, und Sie haben den Benutzernamen, das Kennwort, den Hostnamen, den Port und den Datenbanknamen in einem OpenShift OpenShift Secret-Objekt mit dem Namen mssqlserver-secretgespeichert.
Navigieren Sie zu Ihrem lokalen Repository für die Demo-Anwendung und ändern Sie den aktuellen Branch in bootable-jar-openshift:
git checkout bootable-jar-openshift
Lassen Sie uns kurz überprüfen, was wir in dieser Verzweigung geändert haben:
- Wir haben ein neues Maven-Profil mit dem Namen "
bootable-jar-openshiftBootable JAR" mit einer bestimmten Konfiguration für die Ausführung des Servers in der Cloud hinzugefügt. Beispielsweise ermöglicht es dem JGroups-Subsystem, Netzwerkanforderungen zu verwenden, um andere Pods mithilfe des KUBE_PING-Protokolls zu ermitteln. - Wir haben eine Reihe von Konfigurationsdateien im Verzeichnis jboss-on-aro-jakartaee/deployment hinzugefügt. In diesem Verzeichnis finden Sie die Konfigurationsdateien für die Bereitstellung der Anwendung.
Bereitstellen der Anwendung in OpenShift
In den nächsten Schritten wird erläutert, wie Sie die Anwendung mit einem Helm-Chart mithilfe der OpenShift-Webkonsole bereitstellen können. Vermeiden Sie mithilfe eines Features namens „Geheimnisse“ das Hartcodieren vertraulicher Werte in Ihr Helm-Chart. Ein Geheimnis ist einfach eine Sammlung von Name-Wert-Paaren, bei denen die Werte an einer bekannten Stelle angegeben werden, bevor sie benötigt werden. In unserem Fall verwendet das Helm-Diagramm zwei Secrets mit den folgenden Name-Wert-Paaren aus beiden.
mssqlserver-secretdb-hostübermittelt den Wert vonMSSQLSERVER_HOST.db-nameübermittelt den Wert vonMSSQLSERVER_DATABASE.db-passwordübermittelt den Wert vonMSSQLSERVER_PASSWORD.db-portübermittelt den Wert vonMSSQLSERVER_PORT.db-userübermittelt den Wert vonMSSQLSERVER_USER.
todo-list-secretapp-cluster-passwordvermittelt ein beliebiges, von der oder dem Benutzer*in angegebenes Kennwort, sodass Clusterknoten sicherer gebildet werden können.app-driver-versionübermittelt den Wert vonMSSQLSERVER_DRIVER_VERSION.app-ds-jndiübermittelt den Wert vonMSSQLSERVER_JNDI.
Erstellen Sie
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Erstellen Sie
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Öffnen Sie die OpenShift-Konsole, und navigieren Sie zur Entwickleransicht. Sie können die Konsolen-URL für Ihren OpenShift-Cluster ermitteln, indem Sie diesen Befehl ausführen. Melden Sie sich mit der Benutzerkennung
kubeadminund dem Kennwort an, das Sie aus einem vorhergehenden Schritt erhalten haben.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvWählen Sie im Dropdownmenü oben im Navigationsbereich die <Perspektive /> Entwickler aus.
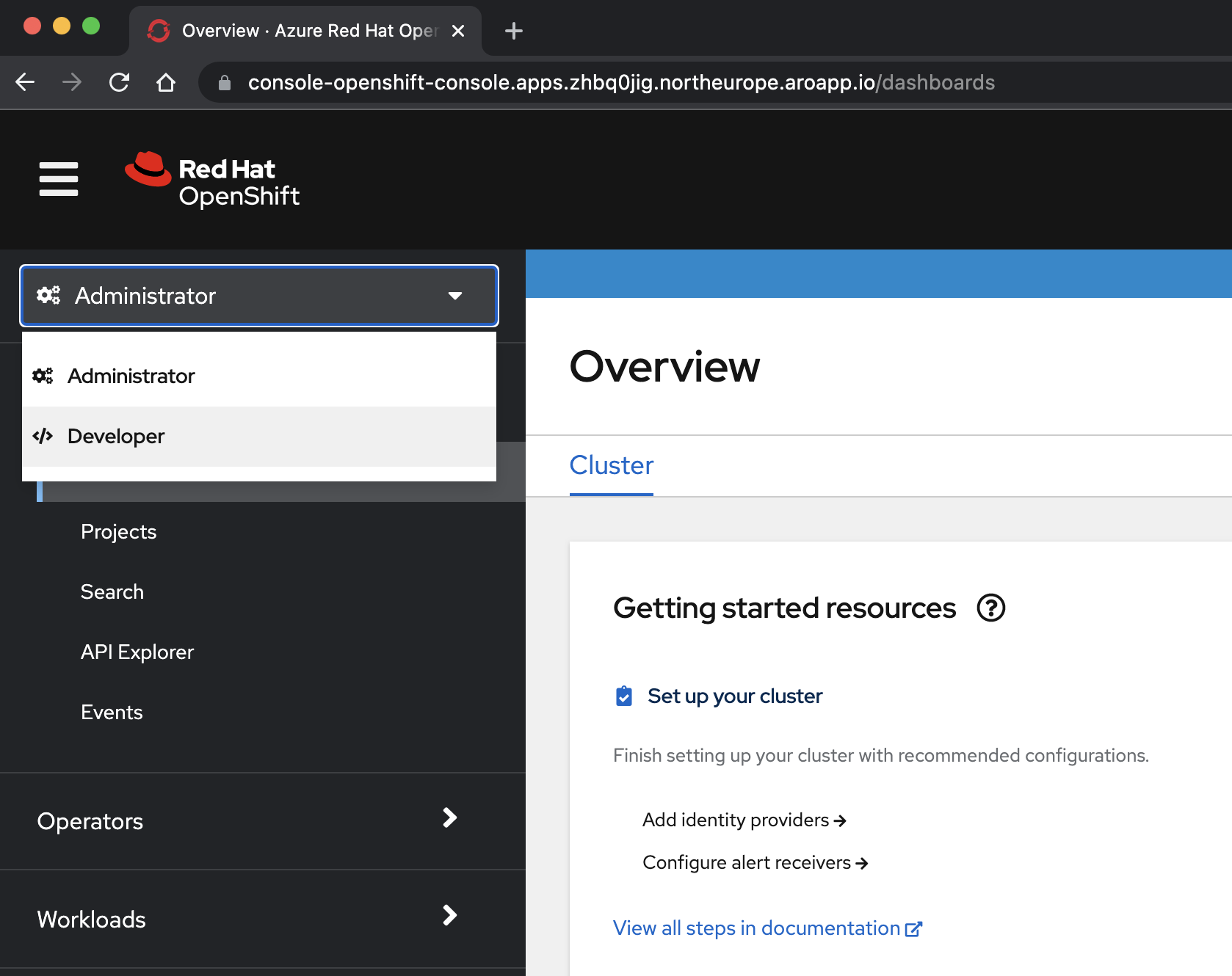
Wählen Sie in der <Perspektive "/> Entwicklertools " das eap-Demo-Projekt aus dem Dropdownmenü "Project " aus.
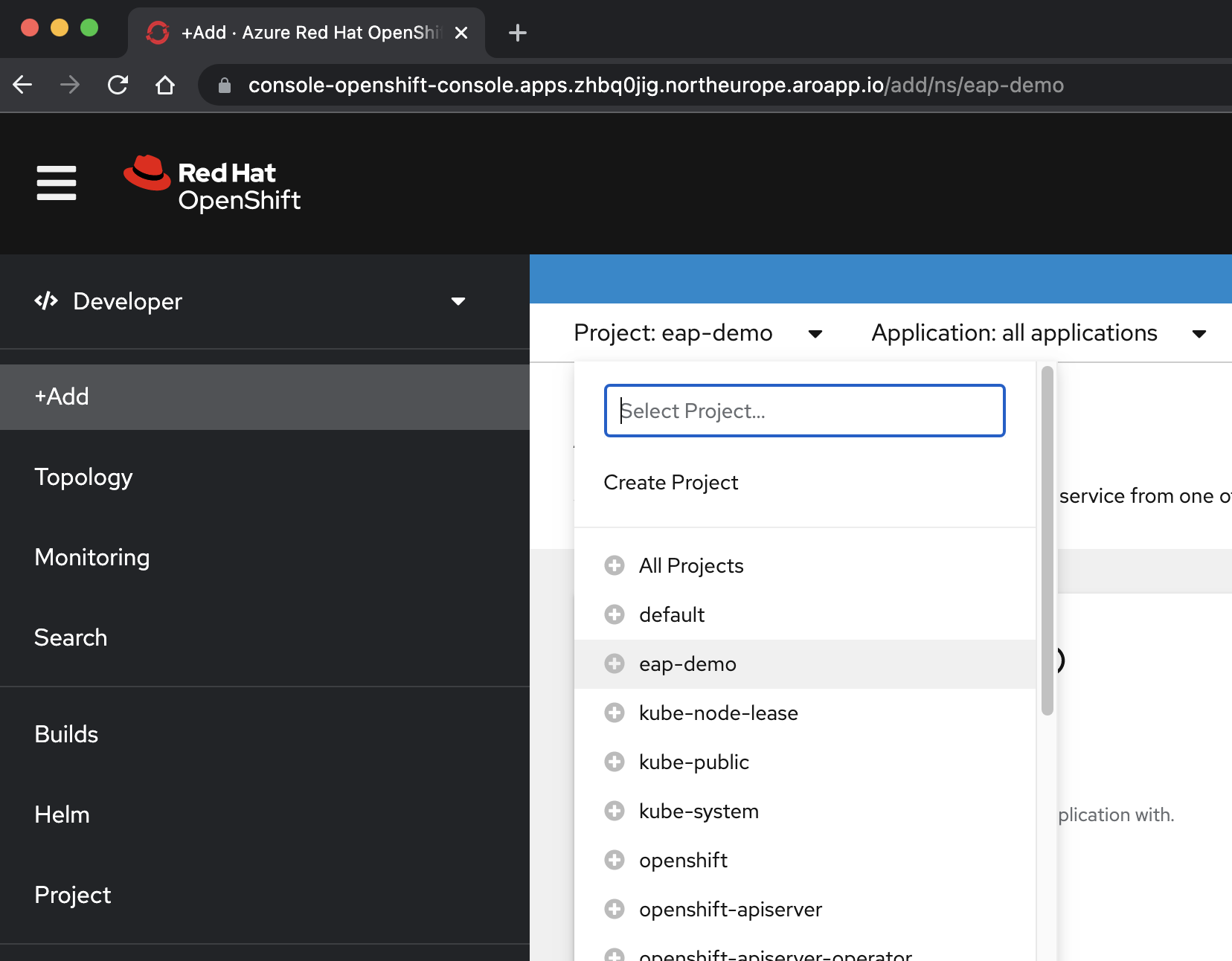
Wählen Sie + Hinzufügen aus. Wählen Sie im Abschnitt Entwicklerkatalog die Option Helm-Chart aus. Sie gelangen zum Helm-Diagrammkatalog, der in Ihrem Azure Red Hat OpenShift-Cluster verfügbar ist. Geben Sie im Feld Nach Stichwort filterneap ein. Es sollten mehrere Optionen angezeigt werden, wie hier gezeigt:
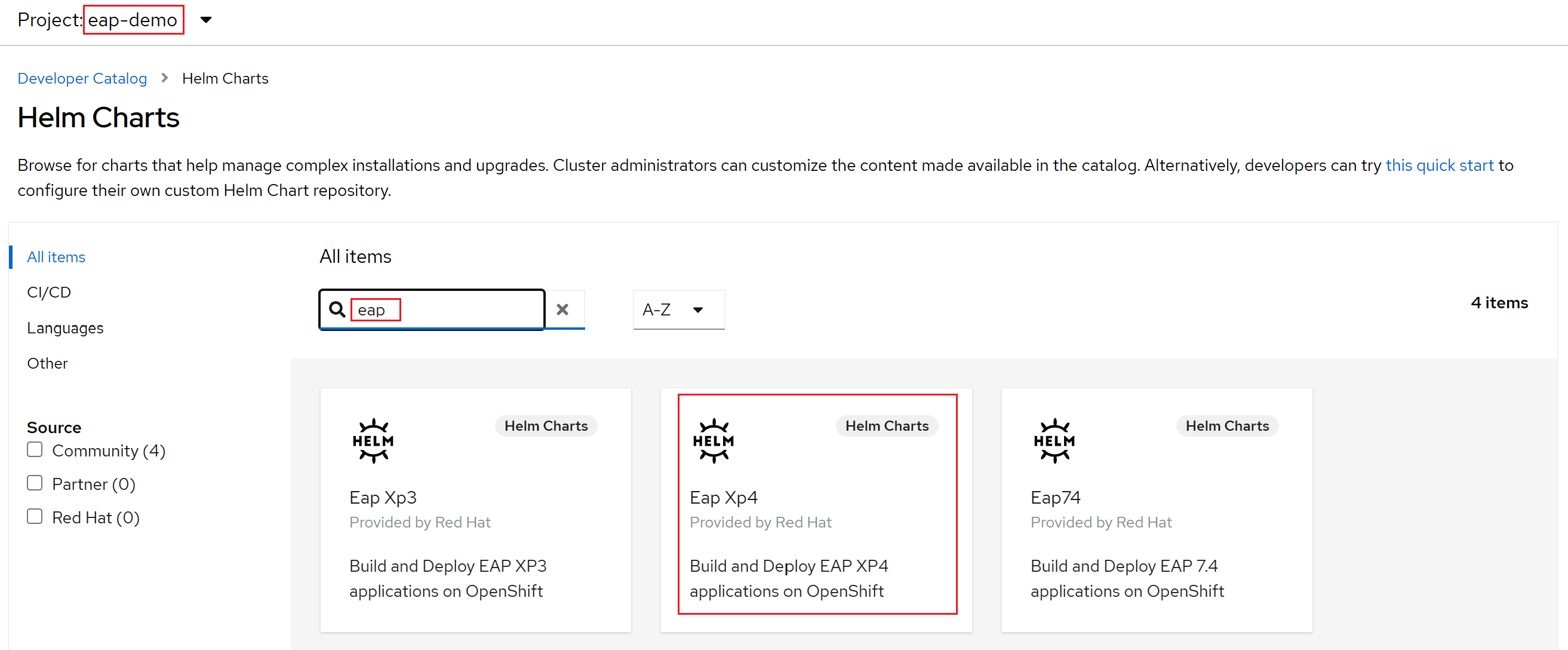
Da unsere Anwendung MicroProfile-Funktionen verwendet, wählen wir das Helmdiagramm für EAP Xp aus. Das "Xp" steht für Expansion Pack. Mit dem JBoss Enterprise Application Platform-Erweiterungspaket können Entwickler Eclipse MicroProfile-APIs (Application Programming Interfaces) verwenden, um auf Microservices basierende Anwendungen zu erstellen und bereitzustellen.
Wählen Sie das JBoss EAP XP 4 Helm-Diagramm und dann "Helmdiagramm installieren" aus.
Nun müssen Sie das Chart konfigurieren, um die Anwendung erstellen und bereitstellen zu können:
Ändern Sie den Namen des Release in eap-todo-list-demo.
Wir können das Helm-Chart über eine Formularansicht oder eine YAML-Ansicht konfigurieren. Wählen Sie im Abschnitt mit der Bezeichnung Konfigurieren mit die Option YAML-Ansicht aus.
Ändern Sie den YAML-Inhalt, um das Helm-Chart zu konfigurieren, indem Sie anstelle des vorhandenen Inhalts den Inhalt der Helm Chart-Datei kopieren, die unter deployment/application/todo-list-helm-chart.yaml verfügbar ist:
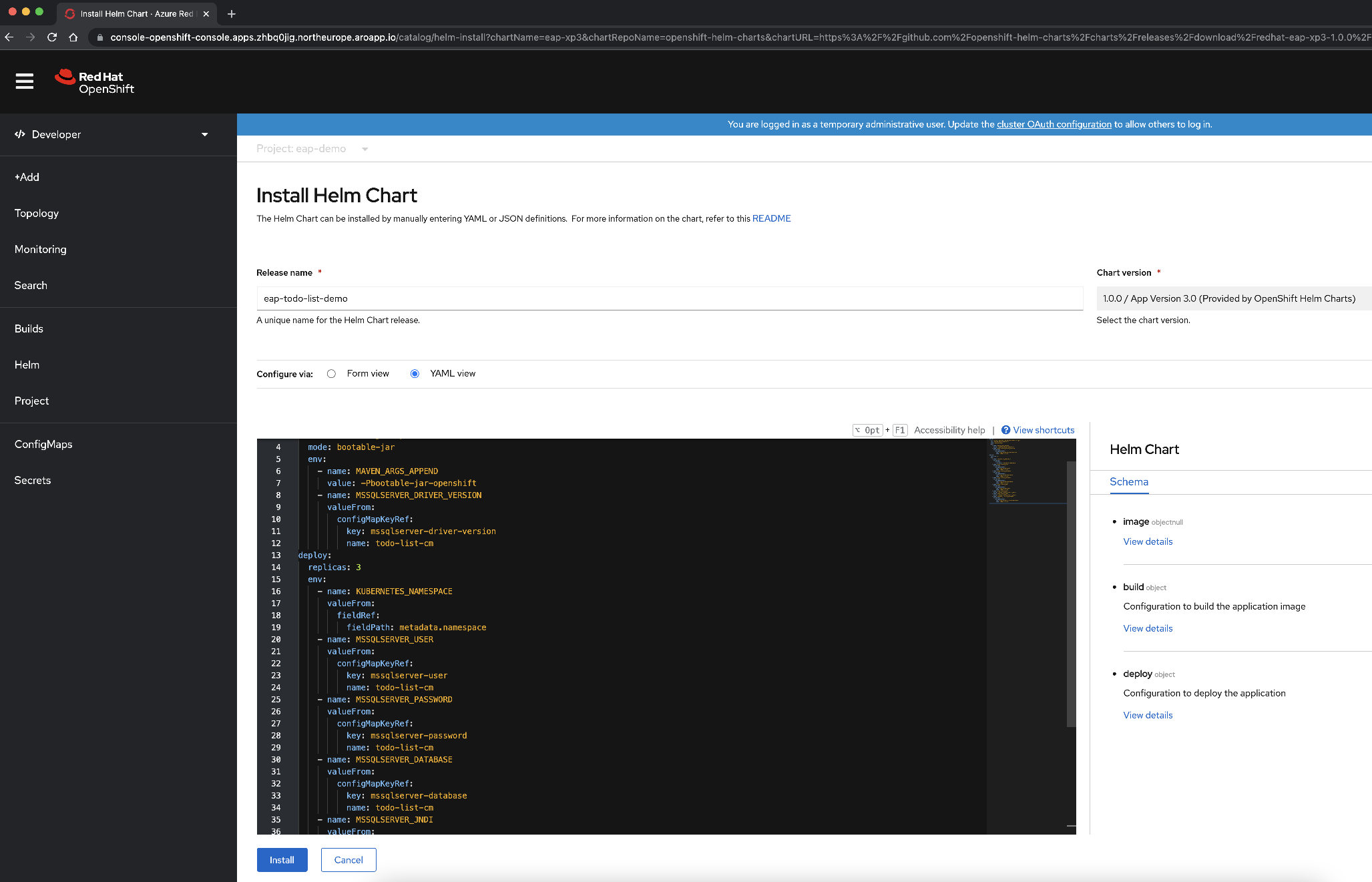
Dieser Inhalt verweist auf die geheimen Schlüssel, die Sie zuvor festgelegt haben.
Wählen Sie abschließend Installieren aus, um die Anwendungsbereitstellung zu starten. Diese Aktion öffnet die Topologieansicht mit einer grafischen Darstellung der Helm-Version (mit dem Namen "eap-todo-list-demo") und den zugehörigen Ressourcen.
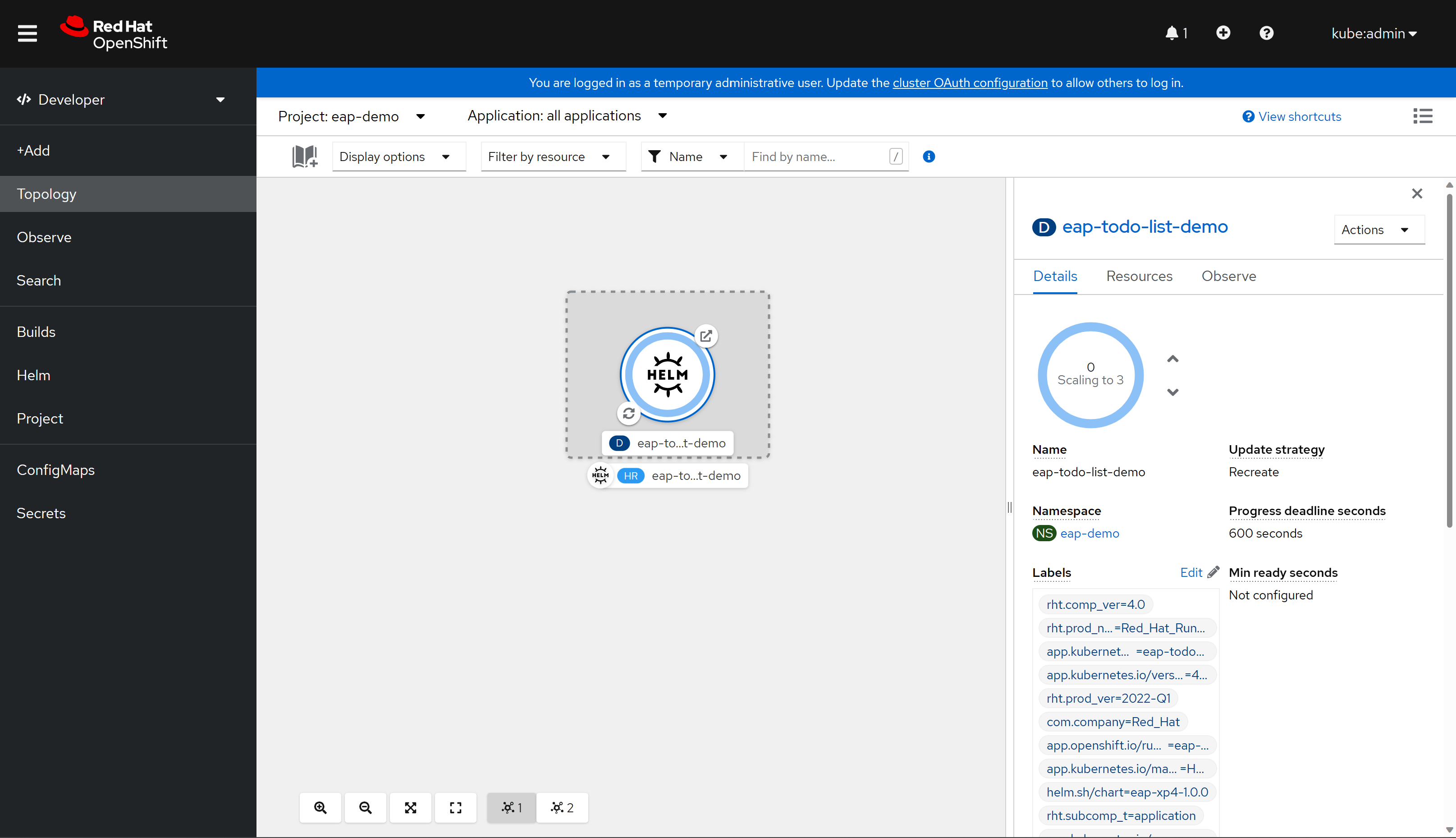
Das Helm-Release (abgekürzt HR) hat den Namen eap-todo-list-demo. Es enthält eine Bereitstellungsressource (abgekürzt D), die ebenfalls den Namen eap-todo-list-demo trägt.
Wenn Sie das Symbol mit zwei Pfeilen in einem Kreis unten links im Feld "D " auswählen, gelangen Sie zum Bereich "Protokolle ". Hier können Sie den Fortschritt des Builds einsehen. Um zur Topologieansicht zurückzukehren, wählen Sie Topologie im linken Navigationsbereich aus.
Wenn der Build abgeschlossen ist, zeigt das symbol unten links ein grünes Häkchen an.
Nach Abschluss der Bereitstellung ist die Kreiskontur dunkelblau. Wenn Sie mit der Maus auf das dunkelblau zeigen, sollte eine Meldung angezeigt werden, die etwas ähnliches angibt
3 Running. Wenn diese Meldung angezeigt wird, können Sie über die der Bereitstellung zugeordnete Route die URL (mit dem Symbol oben rechts) anwenden.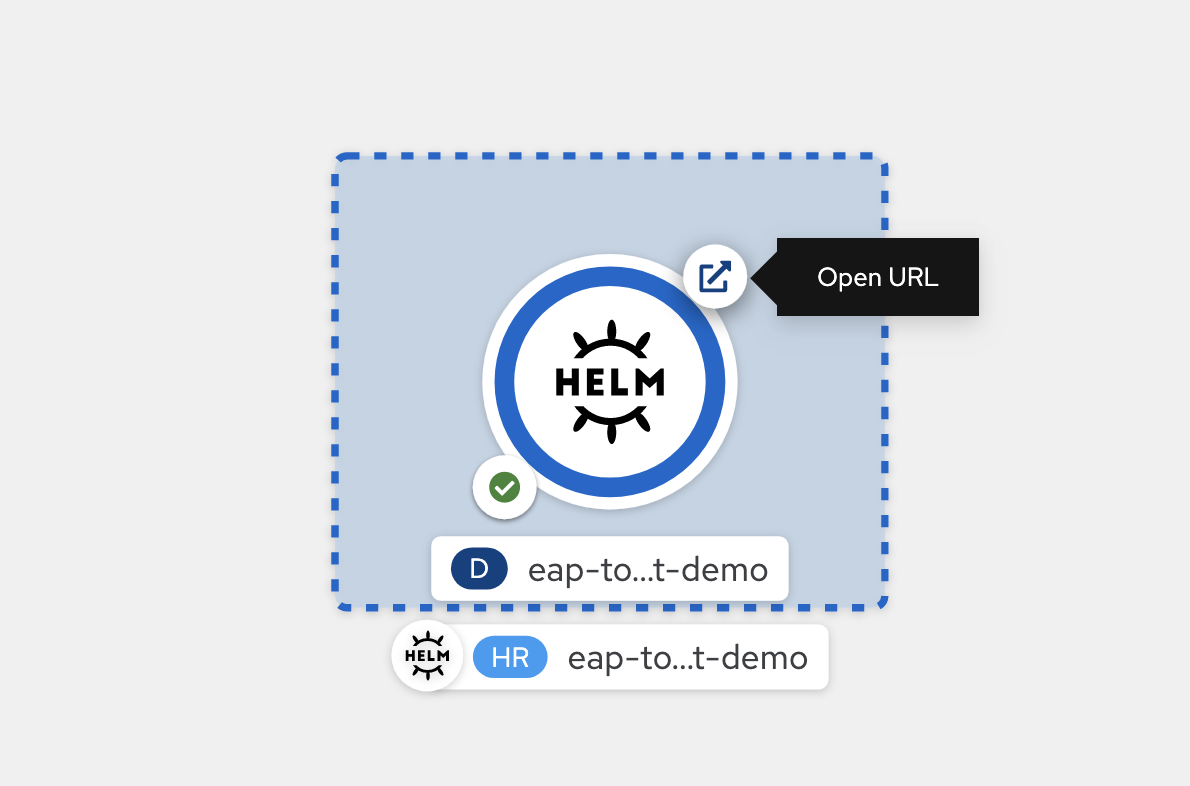
Die Anwendung wird in Ihrem Browser geöffnet und ähnelt der Anwendung in der folgenden Abbildung, die zur Verwendung bereit ist:
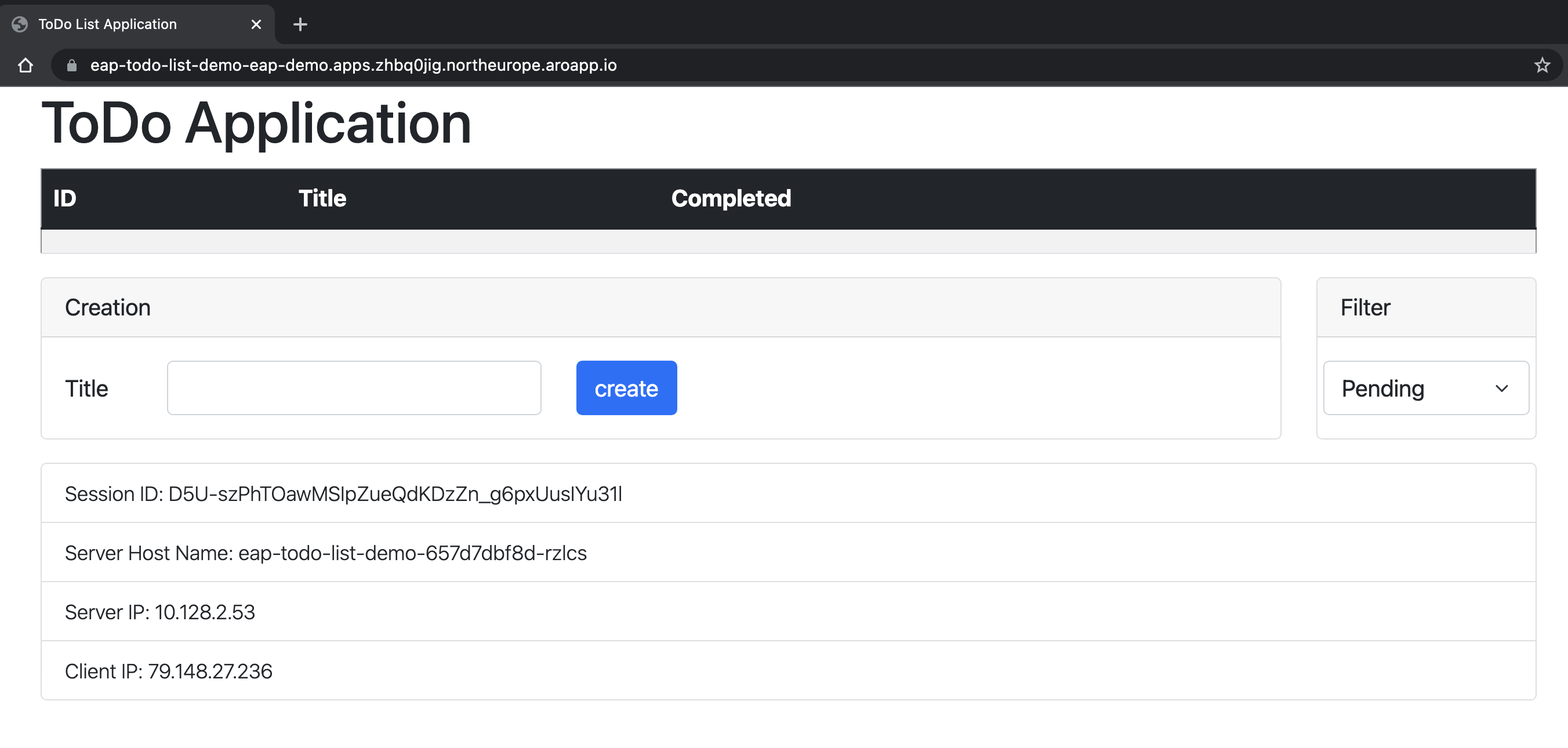
Die Anwendung zeigt Ihnen den Namen des Pods an, das die Informationen liefert. Um die Funktionalitäten des Clustering zu überprüfen, können Sie einige Todo-Elemente hinzufügen. Löschen Sie dann den Pod mit dem Namen, der im Feld "Serverhostname" angegeben ist, das in der Anwendung angezeigt wird.
oc delete pod <pod-name>Erstellen Sie nach dem Löschen des Pods ein neues Todo im selben Anwendungsfenster. Sie können sehen, dass die neue Todo über eine Ajax-Anforderung hinzugefügt wird und das Feld Server Hostname nun einen anderen Namen anzeigt. Hinter den Kulissen hat der OpenShift-Lastenausgleich die neue Anforderung gesendet und an einen verfügbaren Pod übermittelt. Die Ansicht "Jakarta Gesichter" wird aus der HTTP-Sitzungskopie wiederhergestellt, die in dem Pod gespeichert ist, der die Anforderung verarbeitet. Tatsächlich können Sie sehen, dass sich das Feld "Sitzungs-ID " nicht geändert hat. Wenn die Sitzung nicht auf Ihren Pods repliziert wird, erhalten Sie eine Jakarta-GesichterViewExpiredException, und Ihre Anwendung funktioniert nicht wie erwartet.

Bereinigen von Ressourcen
Löschen der Anwendung
Wenn Sie nur Ihre Anwendung löschen möchten, können Sie die OpenShift-Konsole öffnen und in der Entwickleransicht zur Menüoption Helm navigieren. In diesem Menü können Sie alle Helmdiagrammversionen sehen, die auf Ihrem Cluster installiert sind.

Finden Sie das eap-todo-list-demo Helm Chart. Wählen Sie am Ende der Zeile die vertikalen Punkte in der Baumstruktur aus, um den Eintrag im Kontextmenü der Aktion zu öffnen.
Wählen Sie Uninstall Helm Release (Helm-Release deinstallieren) aus, um die Anwendung zu entfernen. Beachten Sie, dass das geheime Objekt, das zum Bereitstellen der Anwendungskonfiguration verwendet wird, nicht Teil des Diagramms ist. Sie müssen es separat entfernen, wenn Sie es nicht mehr benötigen.
Führen Sie den folgenden Befehl aus, wenn Sie das Geheimnis löschen möchten, das die Anwendungskonfiguration enthält:
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Löschen des OpenShift-Projekts
Sie können auch alle für diese Demo erstellten Konfigurationen löschen, indem Sie das Projekt eap-demo löschen. Führen Sie dazu den folgenden Befehl aus:
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Löschen des Azure Red Hat OpenShift-Clusters
Löschen Sie den Azure Red Hat OpenShift-Cluster mit den folgenden Schritten in Tutorial: Löschen eines Azure Red Hat OpenShift 4-Clusters.
Löschen der Ressourcengruppe
Wenn Sie alle ressourcen löschen möchten, die mit den vorherigen Schritten erstellt wurden, löschen Sie die Ressourcengruppe, die Sie für den Azure Red Hat OpenShift-Cluster erstellt haben.
Nächste Schritte
Weitere Informationen finden Sie über die in diesem Handbuch verwendeten Verweise:
- Red Hat JBoss Enterprise Application Platform
- Azure Red Hat OpenShift
- JBoss EAP Helm Charts
- JBoss EAP Bootable JAR
Entdecken Sie weitere Optionen, um JBoss EAP auf Azure auszuführen.