CI/CD-Techniken mit Git und Databricks-Git-Ordnern (Repos)
Lernen Sie Techniken für die Verwendung von Databricks-Git-Ordnern in CI/CD-Workflows kennen. Indem Sie Die Git-Ordner Databricks im Arbeitsbereich konfigurieren, können Sie die Quellcodeverwaltung für Projektdateien in Git-Repositorys verwenden und sie in Ihre Daten-Engineering-Pipelines integrieren.
In der folgenden Abbildung sehen Sie eine Übersicht der Techniken und des Workflows:
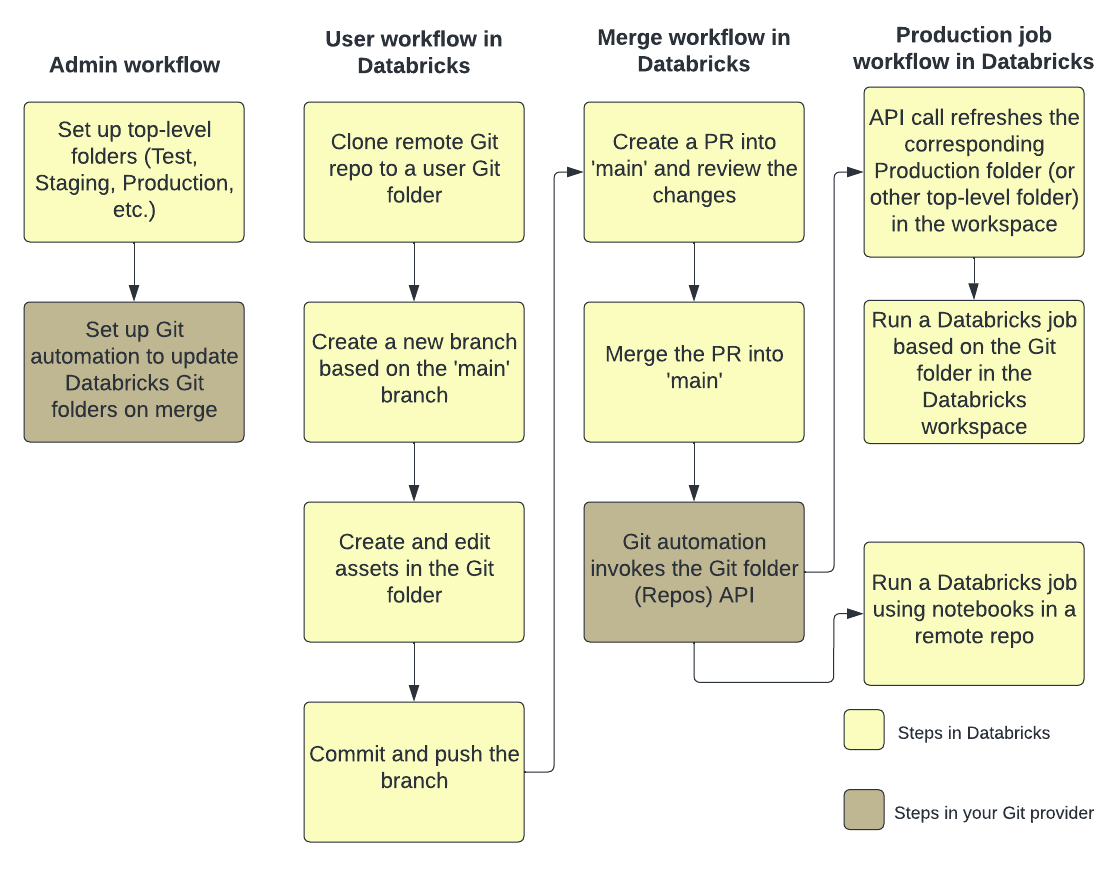
Eine Übersicht über CI/CD mit Azure Databricks finden Sie unter Was ist CI/CD in Azure Databricks?.
Entwicklungsflow
Databricks-Git-Ordner weisen Ordner auf Benutzerebene auf. Ordner auf Benutzerebene werden automatisch erstellt, wenn Benutzer ein Remoterepository zum ersten Mal klonen. Sie können sich Databricks-Git-Ordner in Benutzerordnern als „lokale Auscheckvorgänge“ vorstellen, die für jeden Benutzer individuell sind und mit denen Benutzer Änderungen an ihrem Code vornehmen.
Klonen Sie in Ihrem Benutzerordner in Databricks-Git-Ordnern Ihr Remoterepository. Eine bewährte Methode besteht darin, einen neuen Featurebranch zu erstellen oder einen zuvor erstellten Branch für Ihre Arbeit auszuwählen, anstatt Änderungen direkt in den Mainbranch zu committen und zu pushen. Sie können in diesem Branch Änderungen vornehmen, committen und pushen. Wenn Sie bereit sind, Ihren Code zusammenzuführen, können Sie dies auf der Benutzeroberfläche für Git-Ordner tun.
Anforderungen
Für diesen Workflow müssen Sie Ihre Git-Integration bereits eingerichtet haben.
Hinweis
Databricks empfiehlt, dass jede*r Entwickler*in in seinem eigenen Featurebranch arbeitet. Informationen zum Beheben von Mergekonflikten finden Sie unter Auflösen von Mergekonflikten.
Zusammenarbeiten in Git-Ordnern
Im folgenden Workflow wird ein Branch namens feature-b verwendet, der auf dem Mainbranch basiert.
- Klonen Sie Ihr vorhandenes Git-Repository in Ihren Databricks-Arbeitsbereich.
- Verwenden Sie die Benutzeroberfläche für Git-Ordner, um aus dem Mainbranch einen Featurebranch zu erstellen. In diesem Beispiel wird der Einfachheit halber ein einzelner Featurebranch
feature-bverwendet. Sie können mehrere Featurebranches erstellen und verwenden, um Ihre Arbeit zu erledigen. - Nehmen Sie Ihre Änderungen an Azure Databricks-Notebooks und anderen Dateien im Repository vor.
- Committen und pushen Sie Ihre Änderungen auf Ihren Git-Anbieter.
- Mitwirkende können nun das Git-Repository in ihren eigenen Benutzerordner klonen.
- Bei der Arbeit an einem neuen Branch nimmt ein Kollege Änderungen an den Notebooks und anderen Dateien im Git-Ordner vor.
- Der Mitwirkende oder die Mitwirkende committet und pusht seine Änderungen auf den Git-Anbieter.
- Um Änderungen aus anderen Branches zusammenzuführen oder ein Rebase für den Branch feature-b in Databricks auszuführen, verwenden Sie auf der Benutzeroberfläche für Git-Ordner einen der folgenden Workflows:
- Verzweigungen zusammenführen. Wenn kein Konflikt besteht, wird der Merge mittels
git pushan das Git-Remoterepository gepusht. - Rebase auf einen anderen Branch ausführen.
- Verzweigungen zusammenführen. Wenn kein Konflikt besteht, wird der Merge mittels
- Wenn Sie Ihre Arbeit mit dem Git-Remoterepository und dem Branch
mainzusammenzuführen möchten, verwenden Sie die Benutzeroberfläche für Git-Ordner, um die Änderungen von feature-b zusammenzuführen. Wenn Es Ihnen lieber ist, können Sie stattdessen Änderungen direkt mit dem Git-Repository zusammenführen, das Ihren Git-Ordner unterstützt.
Workflow für Produktionsauftrag
Databricks-Git-Ordner bieten zwei Optionen zum Ausführen Ihrer Produktionsaufträge:
- Option 1: Bereitstellen eines Git-Remoteverweises in der Auftragsdefinition. Führen Sie beispielsweise ein bestimmtes Notebook in der
main-Verzweigung eines Git-Repositorys aus. - Option 2: Richten Sie ein Git-Repository für die Produktion ein, und rufen Sie Repos-APIs auf, um es programmgesteuert zu aktualisieren. Ausführen von Aufträgen für den Databricks-Git-Ordner, der dieses Remoterepository klont. Der Repos-API-Aufruf sollte die erste Aufgabe im Auftrag sein.
Option 1: Ausführen von Aufträgen mithilfe von Notebooks in einem Remoterepository
Vereinfachen Sie den Auftragsdefinitionsprozess, und behalten Sie eine maßgebliche Quelle bei, indem Sie einen Azure Databricks-Auftrag mithilfe von Notebooks in einem Git-Remoterepository ausführen. Dieser Git-Verweis kann ein Git-Commit, -Tag oder -Branch sein und wird von Ihnen in der Auftragsdefinition bereitgestellt.
Dadurch wird sichergestellt, dass Sie unbeabsichtigte Änderungen an Ihrem Produktionsauftrag verhindern können, z. B. wenn ein Benutzer lokale Änderungen in einem Produktionsrepository vornimmt oder Branches umstellt. Außerdem wird der Schritt „Continuous Deployment“ automatisiert, da Sie keinen separaten Produktions-Git-Ordner in Databricks erstellen, nicht die Berechtigungen dafür verwalten und es nicht auf dem neuesten Stand halten müssen.
Siehe Verwenden von Git mit Aufträgen.
Option 2: Einrichten eines Produktions-Git-Ordners und der Git-Automatisierung
Mit dieser Option richten Sie einen Produktions-Git-Ordner und die Automatisierung ein, um den Git-Ordner beim Merge zu aktualisieren.
Schritt 1: Einrichten von Ordnern der obersten Ebene
Der Administrator erstellt Ordner der obersten Ebene, die nicht für Benutzer gedacht sind. Der häufigste Anwendungsfall für diese Ordner der obersten Ebene ist das Erstellen von Entwicklungs-, Staging- und Produktionsordnern, die Databricks-Git-Ordner für die entsprechenden Versionen oder Branches für Entwicklung, Staging und Produktion enthalten. Wenn Ihr Unternehmen z. B. den main-Branch für die Produktion verwendet, muss der Git-Ordner für die Produktion den main-Branch darin ausgecheckt haben.
Berechtigungen für diese Ordner der obersten Ebene sind in der Regel für alle Benutzer ohne Administratorrechte innerhalb des Arbeitsbereichs schreibgeschützt. Für solche Ordner auf oberster Ebene empfehlen wir Ihnen, Dienstprinzipalen nur die Berechtigungen KANN BEARBEITEN und KANN VERWALTEN zu erteilen, um zu vermeiden, dass Arbeitsbereichsbenutzer versehentlich Änderungen an Ihrem Code vornehmen.
Schritt 2: Einrichten automatisierter Updates für Databricks-Git-Ordner mit der Git-Ordner-API
Damit ein Git-Ordner in Databricks immer die neueste Version hat, können Sie die Git-Automatisierung so einrichten, dass die Repos-API aufgerufen wird. Richten Sie in Ihrem Git-Anbieter Automatisierung ein, die nach jeder erfolgreichen Zusammenführung eines Pull Requests in den Mainbranch den Repos-API-Endpunkt im entsprechenden Git-Ordner aufruft, um diesen Ordner auf die neueste Version zu aktualisieren.
Auf GitHub kann dies beispielsweise mit GitHub Actions erreicht werden. Weitere Informationen finden Sie in der Repository-API.
Verwenden eines Dienstprinzipals für die Automatisierung mit Git-Ordnern von Databricks
Sie können entweder die Azure Databricks-Kontokonsole oder die Databricks CLI verwenden, um einen Dienstprinzipal zu erstellen, der für den Zugriff auf die Git-Ordner Ihres Arbeitsbereichs autorisiert ist.
Informationen zum Erstellen eines neuen Dienstprinzipals finden Sie unter Verwalten von Dienstprinzipalen. Wenn Sie über einen Dienstprinzipal in Ihrem Arbeitsbereich verfügen, können Sie Ihre Git-Anmeldeinformationen mit ihr verknüpfen, damit sie im Rahmen Ihrer Automatisierung auf die Git-Ordner Ihres Arbeitsbereichs zugreifen kann.
Autorisieren eines Dienstprinzipals für den Zugriff auf Git-Ordner
So stellen Sie autorisierten Zugriff auf Ihre Git-Ordner für einen Dienstprinzipal mithilfe der Azure Databricks-Kontokonsole bereit:
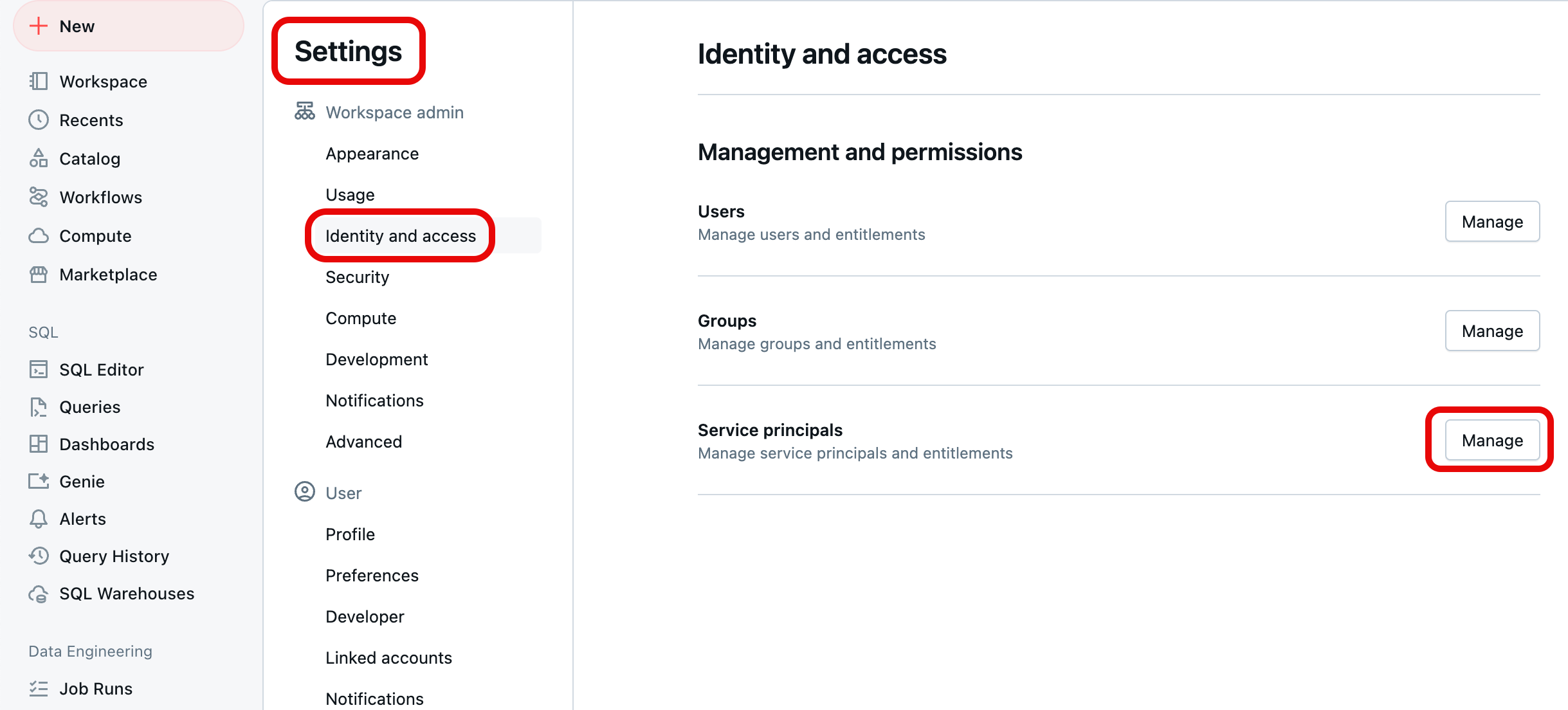
Melden Sie sich bei Ihrem Azure Databricks-Arbeitsbereich an. Sie müssen über Administratorrechte für Ihren Arbeitsbereich verfügen, um diese Schritte ausführen zu können. Wenn Sie nicht über Administratorrechte für Ihren Arbeitsbereich verfügen, fordern Sie sie an, oder wenden Sie sich an den Kontoadministrator.
Klicken Sie in der oberen rechten Ecke einer beliebigen Seite auf Ihren Benutzernamen, und wählen Sie dann Einstellungenaus.
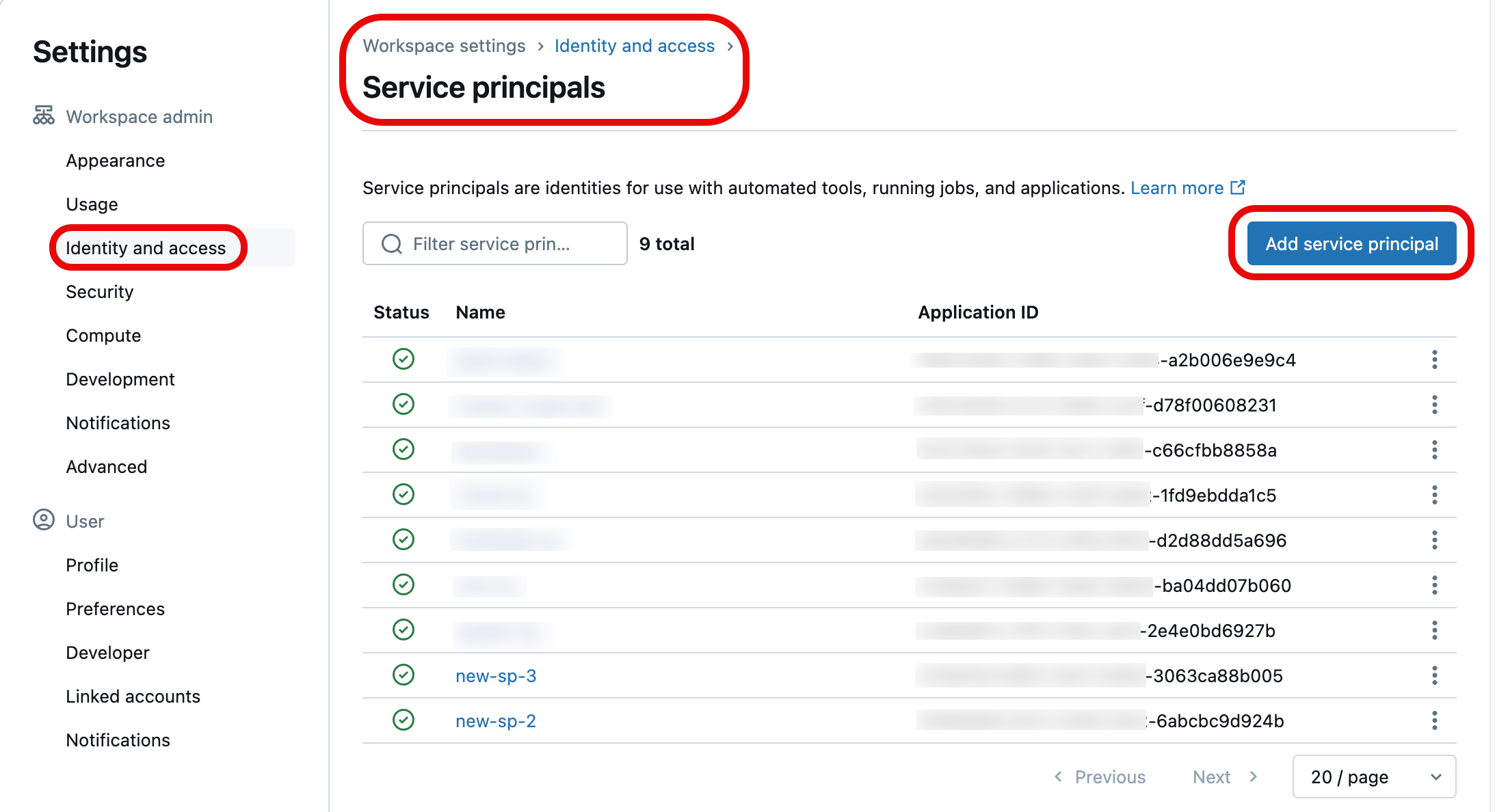
Wählen Sie Identität und Zugriff unter Arbeitsbereichsadministrator im linken Navigationsbereich aus, und wählen Sie dann die Schaltfläche Verwalten für Dienstprinzipale aus.
Wählen Sie in der Liste der Dienstprinzipale die Option aus, die Sie mit Git-Anmeldeinformationen aktualisieren möchten. Sie können auch einen neuen Dienstprinzipal erstellen, indem Sie Dienstprinzipal hinzufügen auswählen.
Wählen Sie die Registerkarte Git-Integration aus. (Wenn Sie den Dienstprinzipal nicht erstellt oder ihm nicht die Berechtigung „Dienstprinzipal-Manager“ zugewiesen haben, wird sie abgeblendet.) Wählen Sie darunter den Git-Anbieter für die Anmeldeinformationen (z. B. GitHub), wählen Sie Git-Konto verknüpfen aus, und wählen Sie dann Link aus.
Sie können auch ein Git Personal Access Token (PAT) verwenden, wenn Sie ihre eigenen Git-Anmeldeinformationen nicht verknüpfen möchten. Wenn Sie stattdessen ein PAT verwenden möchten, wählen Sie persönliches Zugriffstoken aus, und stellen Sie die Tokeninformationen für das Git-Konto bereit, das beim Authentifizieren des Zugriffs des Dienstprinzipals verwendet werden soll. Weitere Informationen zum Abrufen eines PAT von einem Git-Anbieter finden Sie unter Konfigurieren von Git-Anmeldeinformationen & Verbinden eines Remote-Repositorys mit Azure Databricks.
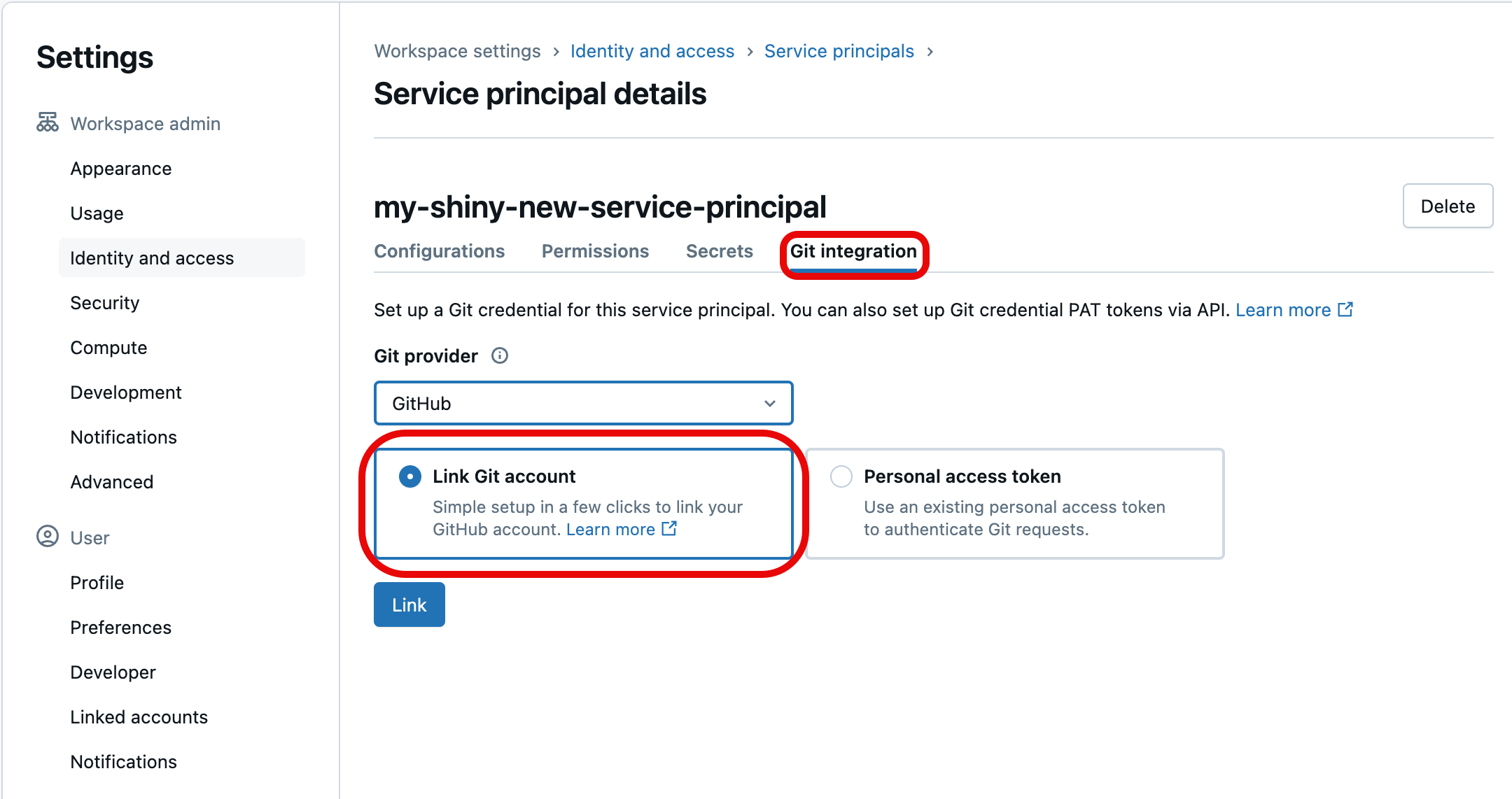
Sie werden aufgefordert, das Git-Benutzerkonto auszuwählen, um eine Verknüpfung zu erstellen. Wählen Sie das Git-Benutzerkonto aus, das der Dienstprinzipal für den Zugriff verwendet, und wählen Sie Weiter aus. (Wenn das benutzerkonto, das Sie verwenden möchten, nicht angezeigt wird, wählen Sie Ein anderes Konto verwenden.)
Wählen Sie im nächsten Dialogfeld Databricks autorisieren aus. Sie sehen die Meldung „Konto wird verknüpft ...“ kurz und dann die aktualisierten Dienstprinzipaldetails.
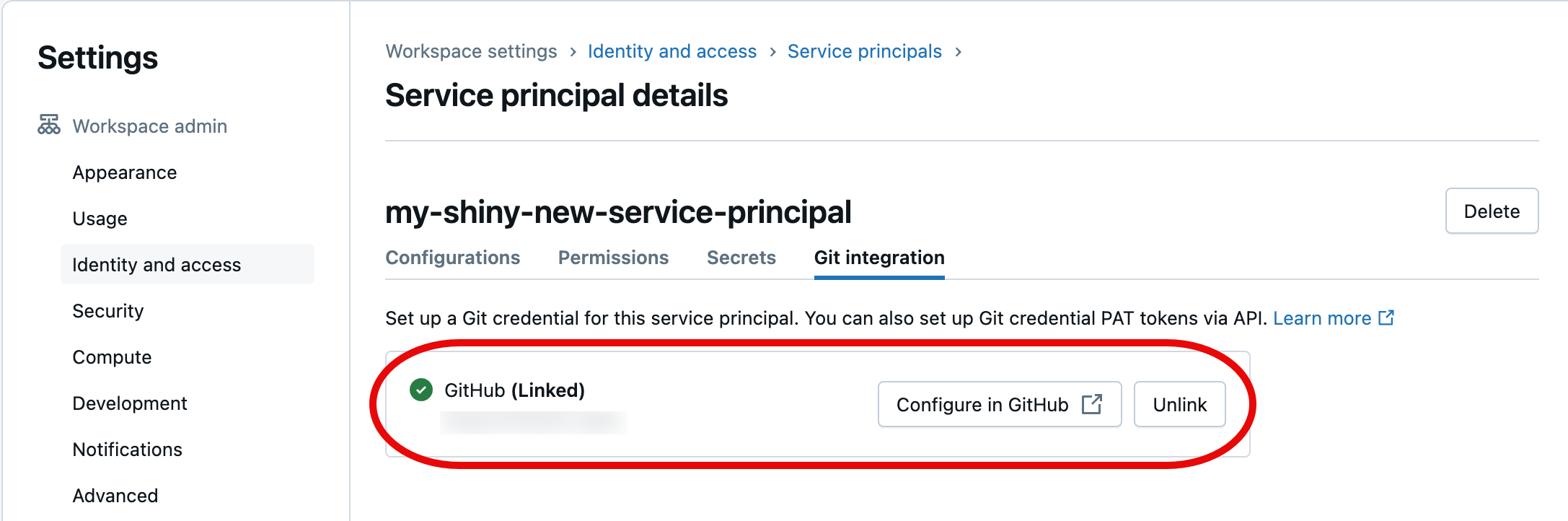
Der von Ihnen ausgewählte Dienstprinzipal wendet nun die verknüpften Git-Anmeldeinformationen an, wenn Sie im Rahmen Ihrer Automatisierung auf die Git-Ordner-Ressourcen des Azure Databricks-Arbeitsbereichs zugreifen.
Terraform-Integration
Sie können Databricks-Git-Ordner auch in einem vollständig automatisierten Setup mit Terraform und databricks_repo verwalten:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Um Terraform zum Hinzufügen von Git-Anmeldeinformationen zu einem Dienstprinzipal zu verwenden, fügen Sie die folgende Konfiguration hinzu:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Konfigurieren einer automatisierten CI/CD-Pipeline mit Databricks-Git-Ordnern
Hier ist eine einfache Automatisierung, die als GitHub-Aktion ausgeführt werden kann.
Anforderungen
- Sie haben einen Git-Ordner in einem Databricks-Arbeitsbereich zur Nachverfolgung des zusammengeführten Basisbranch erstellt.
- Sie verfügen über ein Python-Paket, das die Artefakte erstellt, die an einem DBFS-Speicherort platziert werden sollen. Ihr Code muss:
- Aktualisieren Sie das Repository, das Ihrer bevorzugten Verzweigung (z. B.
development) zugeordnet ist, um die neuesten Versionen Ihrer Notebooks zu enthalten. - Erstellen Sie alle Artefakte, und kopieren Sie sie in den Bibliothekspfad.
- Ersetzen Sie die letzten Versionen von Buildartefakten, um zu vermeiden, dass Sie Artefaktversionen in Ihrem Auftrag manuell aktualisieren müssen.
- Aktualisieren Sie das Repository, das Ihrer bevorzugten Verzweigung (z. B.
Erstellen eines automatisierten CI/CD-Workflows
Richten Sie geheime Schlüssel ein, damit Ihr Code auf den Databricks-Arbeitsbereich zugreifen kann. Fügen Sie dem Github-Repository die folgenden geheimen Schlüssel hinzu:
- DEPLOYMENT_TARGET_URL: Legen Sie dies auf Ihre Arbeitsbereichs-URL fest. Fügen Sie die
/?oTeilzeichenfolge nicht ein. - DEPLOYMENT_TARGET_TOKEN: Legen Sie dies auf ein Databricks Personal Access Token (PAT) fest. Sie können einen Databricks PAT generieren, indem Sie die Anweisungen in Azure Databricks-Authentifizierung für persönliche Zugriffstoken befolgen.
- DEPLOYMENT_TARGET_URL: Legen Sie dies auf Ihre Arbeitsbereichs-URL fest. Fügen Sie die
Navigieren Sie zur Registerkarte Aktionen Ihres Git-Repositorys und klicken Sie auf die Schaltfläche Neuer Workflow. Wählen Sie oben auf der Seite Workflow selbst einrichten aus und fügen Sie dieses Skript ein:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itAktualisieren Sie die folgenden Umgebungsvariablenwerte mit Ihren eigenen:
- DBFS_LIB_PATH: Der Pfad in DBFS zu den Bibliotheken (Wheels), die Sie in dieser Automatisierung verwenden, beginnen mit
dbfs:. Beispiel:dbfs:/mnt/myproject/libraries. - REPO_PATH: Der Pfad in Ihrem Databricks-Arbeitsbereich zum Git-Ordner, in dem Notebooks aktualisiert werden.
- LATEST_WHEEL_NAME: Der Name der zuletzt kompilierten Python-Wheel-Datei (
.whl). Dieser wird verwendet, um die manuelle Aktualisierung von Wheel-Versionen in Ihren Databricks-Aufträgen zu vermeiden. Beispiel:your_wheel-latest-py3-none-any.whl.
- DBFS_LIB_PATH: Der Pfad in DBFS zu den Bibliotheken (Wheels), die Sie in dieser Automatisierung verwenden, beginnen mit
Wählen Sie Änderungen übernehmen... aus, um das Skript als GitHub Actions-Workflow zu übernehmen. Wenn der Pull Request für diesen Workflow zusammengeführt ist, wechseln Sie zur Registerkarte Aktionen des Git-Repositorys und überprüfen Sie den erfolgreichen Abschluss der Aktionen.