Juli 2019
Diese Features und Azure Databricks-Plattformverbesserungen wurden im Juli 2019 veröffentlicht.
Hinweis
Releases werden gestaffelt. Ihr Azure Databricks-Konto wird möglicherweise erst eine Woche nach dem Datum der ersten Veröffentlichung aktualisiert.
Bald verfügbar: Python 2 wird von Databricks 6.0 nicht unterstützt.
In Erwartung des bevorstehenden Endes der Lebensdauer von Python 2, das für 2020 angekündigt ist, wird Python 2 in Databricks Runtime 6.0 nicht unterstützt. Frühere Versionen von Databricks Runtime unterstützen weiterhin Python 2. Wir gehen von einer Veröffentlichung von Databricks Runtime 6.0 im Laufe des Jahres 2019 aus.
Vorabladen der Databricks Runtime-Version für Instanzen, deren Pools sich im Leerlauf befinden
30. Juli – 6. August 2019: Version 2.103
Sie können nun den Start von poolgestützten Clustern beschleunigen, indem Sie eine Databricks Runtime-Version auswählen, die auf inaktive Instanzen im Pool geladen wird. Das Feld in der Pool-Benutzeroberfläche heißt Spark-Version im Voraus laden.

Benutzerdefinierte Cluster- und Pooltags funktionieren besser zusammen.
30. Juli – 6. August 2019: Version 2.103
Anfang dieses Monats wurden mit Azure Databricks Pools eingeführt, eine Reihe von inaktiven Instanzen, mit denen Sie Cluster schnell einrichten können. In der ursprünglichen Version haben poolgestützte Cluster standardmäßige und benutzerdefinierte Tags aus der Poolkonfiguration geerbt, und Sie konnten diese Tags nicht auf Clusterebene ändern. Jetzt können Sie benutzerdefinierte Tags speziell für einen von einem Pool unterstützten Cluster konfigurieren, und dieser Cluster wendet alle benutzerdefinierten Tags an, unabhängig davon, ob sie vom Pool geerbt oder speziell diesem Cluster zugewiesen wurden. Sie können kein clusterspezifisches benutzerdefiniertes Tag mit demselben Schlüsselnamen wie ein von einem Pool geerbtes benutzerdefiniertes Tag hinzufügen (d. h., Sie können ein vom Pool geerbtes benutzerdefiniertes Tag nicht überschreiben). Weitere Informationen finden Sie unter Pooltags.
MLflow 1.1 enthält mehrere Benutzeroberflächen und API-Verbesserungen
30. Juli – 6. August 2019: Version 2.103
MLflow 1.1 führt mehrere neue Funktionen zur Verbesserung der Benutzeroberfläche und der API-Benutzerfreundlichkeit ein:
Auf der Benutzeroberfläche für die Ausführungsübersicht können Sie jetzt durch mehrere Seiten von Ausführungen navigieren, wenn die Anzahl der Ausführungen 100 überschreitet. Klicken Sie nach der 100. Ausführung auf die Schaltfläche Mehr laden, um die nächsten 100 Ausführungen zu laden.
Die Benutzeroberfläche für den Vergleich von Ausführungen bietet jetzt einen Plot mit parallelen Koordinaten. Der Plot ermöglicht die Analyse der Beziehungen zwischen einem n-dimensionalen Satz von Parametern und Metriken. Er stellt alle Ausführungen als Linien dar, die auf der Grundlage des Wertes einer Metrik (z. B. Genauigkeit) farblich gekennzeichnet sind, und zeigt die Parameterwerte für die einzelnen Ausführungen an.
Jetzt können Sie über die Benutzeroberfläche der Ausführungsübersicht Tags hinzufügen und bearbeiten sowie Tags in der Experimentsuchansicht anzeigen.
Die neue MLflowContext-API ermöglicht das Erstellen und Protokollieren von Ausführungen auf eine Weise, die der Python-API ähnlich ist. Diese API unterscheidet sich von der bestehenden Low-Level-
MlflowClient-API, die lediglich die REST-APIs umschließt.Sie können jetzt Tags aus MLflow-Ausführungen mithilfe der DeleteTag-API löschen.
Einzelheiten finden Sie im Blogbeitrag zu MLflow 1.1. Die vollständige Liste der Funktionen und Fixes finden Sie im Änderungsprotokoll zu MLflow.
pandas DataFrame-Anzeige wird genauso gerendert wie in Jupyter
30. Juli – 6. August 2019: Version 2.103
Wenn Sie nun einen Pandas-DataFrame aufrufen, wird dieser auf die gleiche Weise gerendert wie in Jupyter.
Neue Regionen
30. Juli 2019
Azure Databricks ist jetzt in den folgenden zusätzlichen Regionen verfügbar:
- Korea, Mitte
- Südafrika, Norden
Heraufgesetztes Limit für Metastore-Verbindung
16. bis 23. Juli 2019: Version 2.102
Neue Azure Databricks-Arbeitsbereiche in eastus, eastus2, centralus, westus, westus2, westeurope, northeurope erhalten eine höhere Metastore-Verbindungsgrenze von 250. Bestehende Arbeitsbereiche verwenden weiterhin ohne Unterbrechung den aktuellen Metastore und haben weiterhin eine Verbindungsgrenze von 100.
Festlegen von Berechtigungen für Pools (Public Preview)
16. bis 23. Juli 2019: Version 2.102
Die Pool-Benutzeroberfläche unterstützt jetzt die Festlegung von Berechtigungen für die Verwaltung von Pools und die Zuordnung von Clustern zu Pools.
Ausführliche Informationen finden Sie unter Poolberechtigungen.
Databricks Runtime 5.5 für Machine Learning
15. Juli 2019
Databricks Runtime 5.5 ML basiert auf Databricks Runtime 5.5 LTS (EoS). Es enthält viele beliebte Machine Learning-Bibliotheken, darunter TensorFlow, PyTorch, Keras und XGBoost, und bietet verteiltes TensorFlow-Training mit Horovod.
Diese Version enthält die folgenden neuen Funktionen und Verbesserungen:
- Das Python-Paket MLflow 1.0 wurde hinzugefügt.
- Aktualisierte Machine Learning-Bibliotheken
- TensorFlow-Upgrade von 1.12.0 auf 1.13.1
- PyTorch-Upgrade von 0.4.1 auf 1.1.0
- scikit-learn-Upgrade von 0.19.1 auf 0.20.3
- Einzelknotenvorgang für HorovodRunner
Weitere Informationen finden Sie unter Databricks Runtime 5.5 LTS für ML (EoS).
Databricks Runtime 5.5
15. Juli 2019
Databricks Runtime 5.5 ist jetzt verfügbar. Databricks Runtime 5.5 enthält Apache Spark 2.4.3, aktualisierte Python-, R-, Java- und Scala-Bibliotheken und die folgenden neuen Features:
- Automatisches Optimieren (allgemeine Verfügbarkeit) mit Delta Lake in Azure Databricks
- Delta Lake auf Azure Databricks verbessert die Abfrageleistung bei der Aggregation von „Min“, „Max“ und „Count“
- Schnellere Modellrückschlusspipelines mit verbesserter Binärdateidatenquelle und benutzerdefinierter Skalariterator-pandas-Funktion (Public Preview)
- Geheimnis-API in R-Notebooks
Weitere Informationen finden Sie unter Databricks Runtime 5.5 LTS (EoS).
Beibehalten eines Instanzenpools im Standbymodus für schnelle Clusterstarts (Public Preview)
9. bis 11. Juli 2019: Version 2.101
Um die Startzeit von Clustern zu verkürzen, unterstützt Azure Databricks nun das Anhängen eines Clusters an einen vordefinierten Pool von inaktiven Instanzen. Wenn ein Cluster an einen Pool angefügt wird, werden seine Treiber- und Workerknoten aus dem Pool zugeordnet. Wenn der Pool nicht über genügend freie Ressourcen verfügt, um die Anforderungen des Clusters zu erfüllen, wird der Pool durch Zuweisung neuer Instanzen vom Cloudanbieter erweitert. Wenn ein angefügter Cluster beendet wird, werden die verwendeten Instanzen an den Pool zurückgegeben und können von einem anderen Cluster wiederverwendet werden.
Solange sich Instanzen im Pool im Leerlauf befinden, werden in Azure Databricks keine DBU-Stunden berechnet. Abrechnung des Instanzenanbieters gilt. Siehe Preise.
Ausführliche Informationen finden Sie unter Poolkonfigurationsreferenz.
Ganglia-Metriken
9. bis 11. Juli 2019: Version 2.101
Ganglia ist ein skalierbares, verteiltes Überwachungssystem, das jetzt auf Azure Databricks-Clustern verfügbar ist. Ganglia-Metriken helfen Ihnen bei der Überwachung der Leistung und des Zustands des Clusters. Auf die Ganglia-Metriken können Sie über die Clusterdetailseite zugreifen:
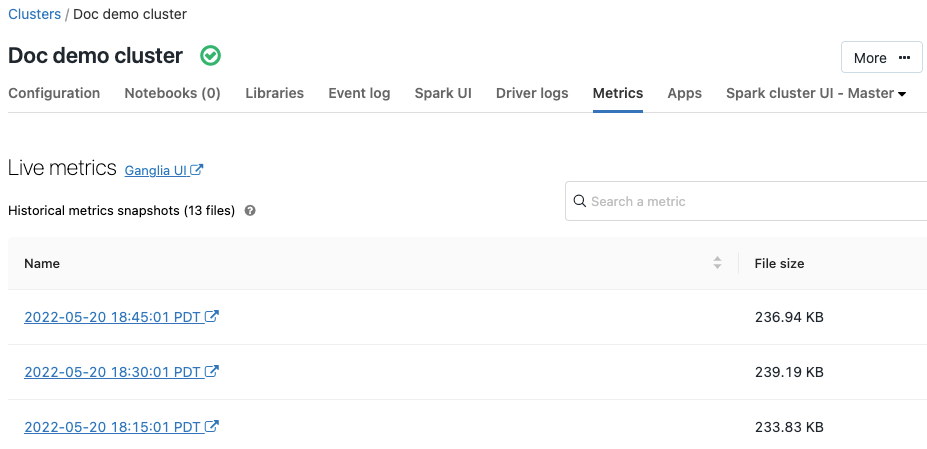
Ausführliche Informationen zur Verwendung und Konfiguration von Metriken finden Sie unter Ganglia-Metriken.
Einheitliche Farben für Reihen
9. bis 11. Juli 2019: Version 2.101
Sie können nun festlegen, dass die Farben einer Reihe in allen Diagrammen Ihres Notebooks einheitlich sein sollen. Siehe Diagrammübergreifende Farbkonsistenz.