Lücken zwischen Spark-Aufträgen
Ihre Auftragszeitskala kann Lücken wie die folgenden aufweisen:
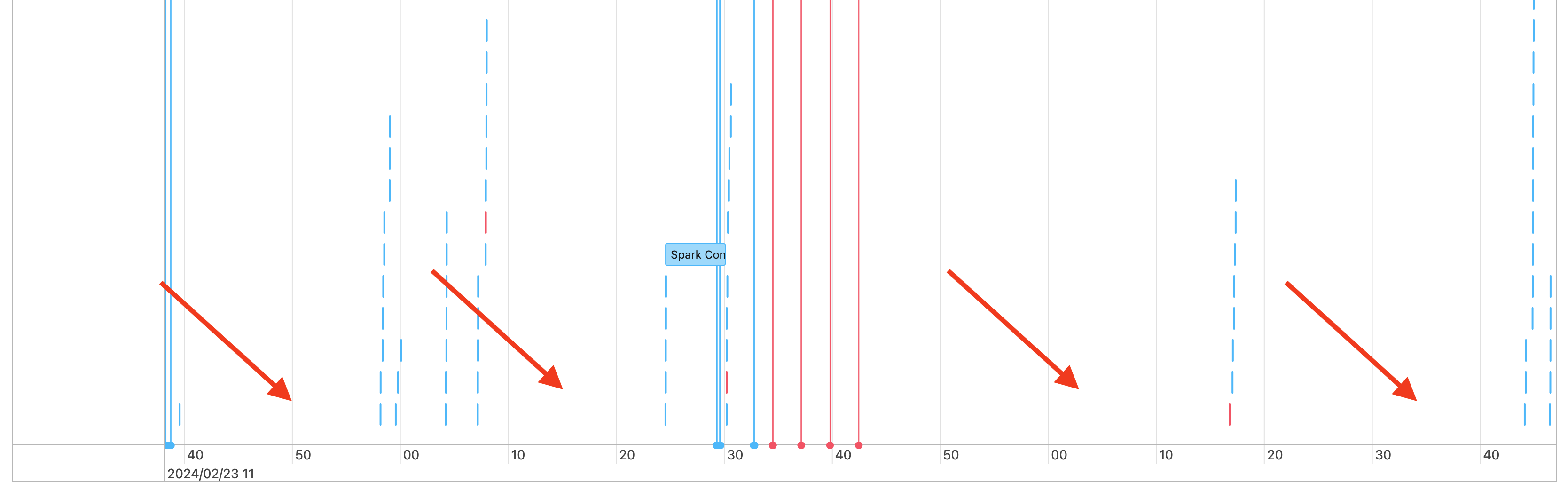
Hierfür gibt es ein paar mögliche Gründe. Wenn die Lücken einen hohen Anteil der für Ihre Workload aufgewendeten Zeit ausmachen, müssen Sie herausfinden, was diese Lücken verursacht und ob sie zu erwarten sind. Es gibt ein paar mögliche Szenarien für die Lücken:
- Es ist nichts zu tun.
- Der Treiber kompiliert einen komplexen Ausführungsplan.
- Es wird Spark-fremder Code ausgeführt.
- Der Treiber ist überlastet.
- Der Cluster funktioniert nicht ordnungsgemäß.
Nichts zu tun
Bei All-Purpose Compute ist die wahrscheinlichste Erklärung für die Lücken, dass nichts zu tun ist. Da der Cluster ausgeführt wird und Benutzer Abfragen übermitteln, sind Lücken zu erwarten. Bei diesen Lücken handelt es sich um die Zeit zwischen Abfrageübermittlungen.
Komplexer Ausführungsplan
Wenn Sie z. B. withColumn() in einer Schleife verwenden, entsteht ein sehr teurer Plan für die Verarbeitung. Bei den Lücken handelt es sich ggf. einfach um die Zeit, die der Treiber für Erstellung und Verarbeitung des Plans benötigt. Versuchen Sie in diesem Fall, den Code zu vereinfachen. Verwenden Sie selectExpr(), um mehrere withColumn()-Aufrufe in einem Ausdruck zusammenzufassen, oder konvertieren Sie den Code in SQL. Sie können weiterhin SQL in Ihren Python-Code einbetten und Python verwenden, um die Abfrage mit Zeichenfolgenfunktionen zu bearbeiten. Dadurch lässt sich diese Art von Problem häufig beheben.
Ausführung von Spark-fremdem Code
Spark-Code wird entweder in SQL oder unter Verwendung einer Spark-API wie PySpark geschrieben. Jede Ausführung von Code, bei dem es sich nicht um Spark-Code handelt, wird auf der Zeitskala als Lücke angezeigt. Vielleicht gibt es bei Ihnen ja eine Schleife in Python, die native Python-Funktionen aufruft. Dieser Code wird nicht in Spark ausgeführt und ergibt ggf. eine Lücke auf der Zeitskala. Wenn Sie nicht sicher sind, ob Ihr Code Spark ausführt, versuchen Sie, ihn interaktiv in einem Notebook auszuführen. Wenn der Code Spark verwendet, werden unter der folgenden Zelle Spark-Aufträge angezeigt:

Sie können auch die Dropdownliste Spark-Aufträge unter der Zelle erweitern, um zu ermitteln, ob die Aufträge aktiv ausgeführt werden (falls Spark sich jetzt im Leerlauf befindet). Wenn Sie Spark nicht verwenden, wird die Option Spark-Aufträge unter der Zelle nicht angezeigt, oder Sie sehen, dass keine aktiv sind. Wenn Sie den Code nicht interaktiv ausführen können, können Sie mittels Protokollierung in Ihrem Code versuchen, anhand von Zeitstempeln die Lücken mit Abschnitten Ihres Codes abzugleichen. Das kann allerdings schwierig sein.
Wenn Lücken auf der Zeitskala auf die Ausführung von Spark-fremdem Code zurückzuführen sind, bedeutet das, dass sich alle Ihre Worker im Leerlauf befinden und Ihnen während der Lücken wahrscheinlich unnötige Kosten entstehen. Vielleicht ist dies beabsichtigt und unvermeidbar, aber wenn Sie den Code so schreiben können, dass Spark verwendet wird, können Sie den Cluster optimal nutzen. Informationen zur Arbeit mit Spark finden Sie in diesem Tutorial.
Der Treiber ist überlastet.
Um festzustellen, ob Ihr Treiber überladen ist, müssen Sie sich die Clustermetriken ansehen.
Wenn Ihr Cluster mindestens DBR 13.0 verwendet, klicken Sie auf Metriken, wie im folgenden Screenshot hervorgehoben:
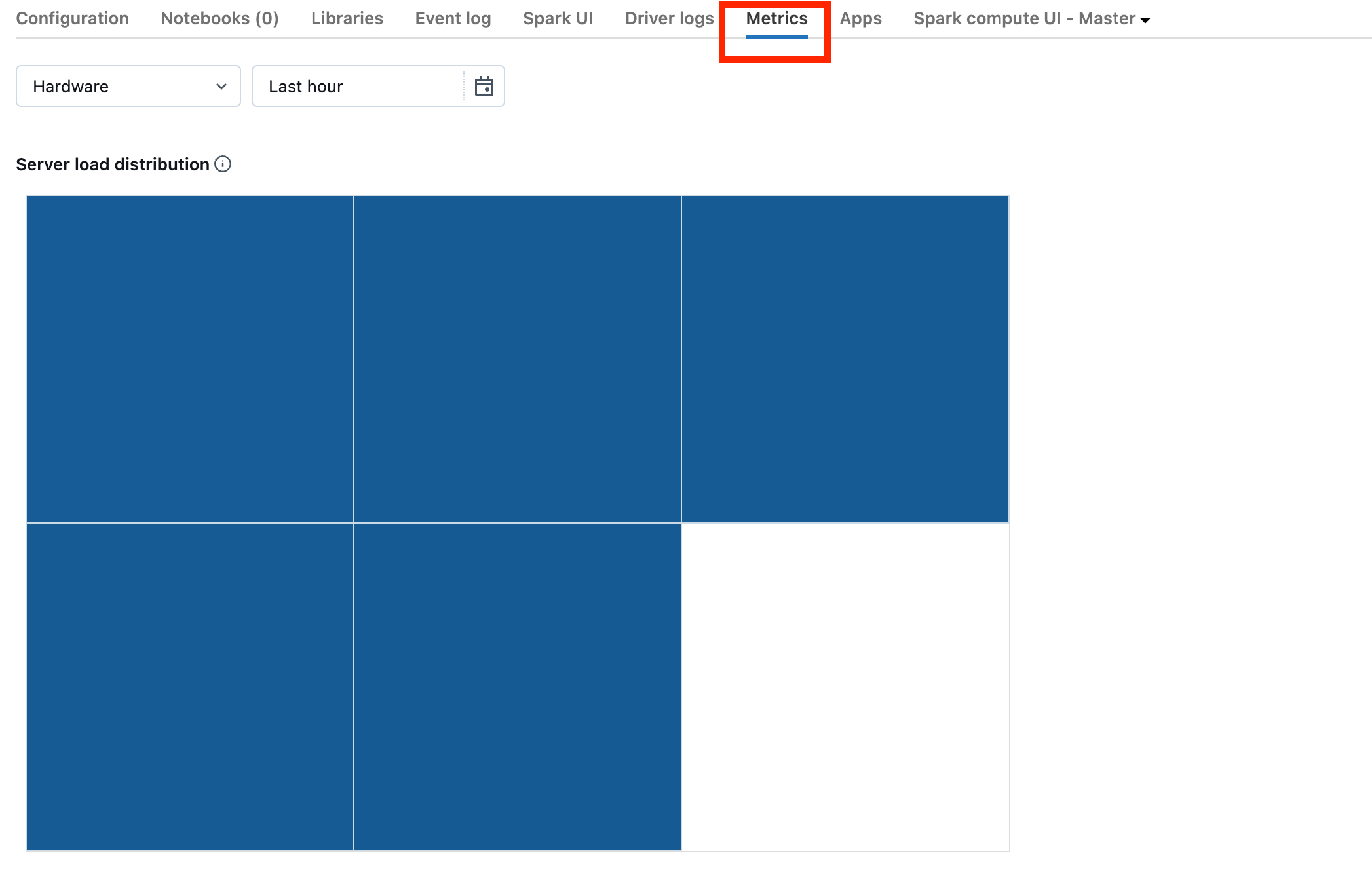
Sehen Sie sich die Visualisierung Serverlastverteilung an. Prüfen Sie, ob der Treiber stark ausgelastet ist. Die Visualisierung enthält für jeden Computer im Cluster einen farbigen Block. Rot bedeutet „stark ausgelastet“. Blau bedeutet „überhaupt nicht ausgelastet“.
Der vorherige Screenshot zeigt im Grunde einen Cluster im Leerlauf. Ist der Treiber überlastet, sieht das in etwa wie folgt aus:
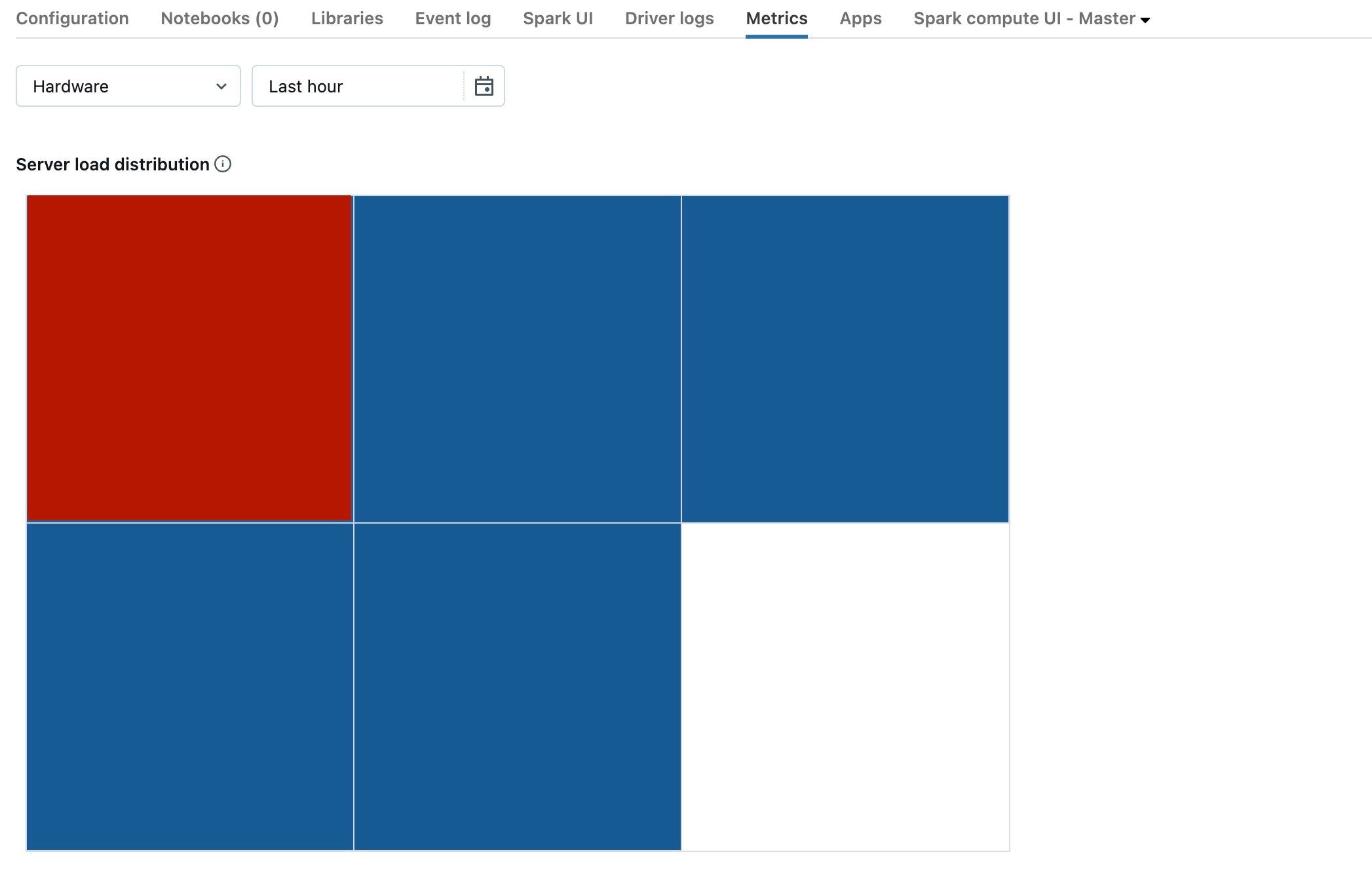
Wie Sie sehen, ist eines der Quadrate rot, und die anderen sind blau. Zeigen Sie mit der Maus auf das rote Quadrat, und vergewissern Sie sich, dass der rote Block Ihren Treiber darstellt.
Informationen zur Behebung eines überlasteten Treibers finden Sie unter Überlasteter Spark-Treiber.
Der Cluster funktioniert nicht ordnungsgemäß.
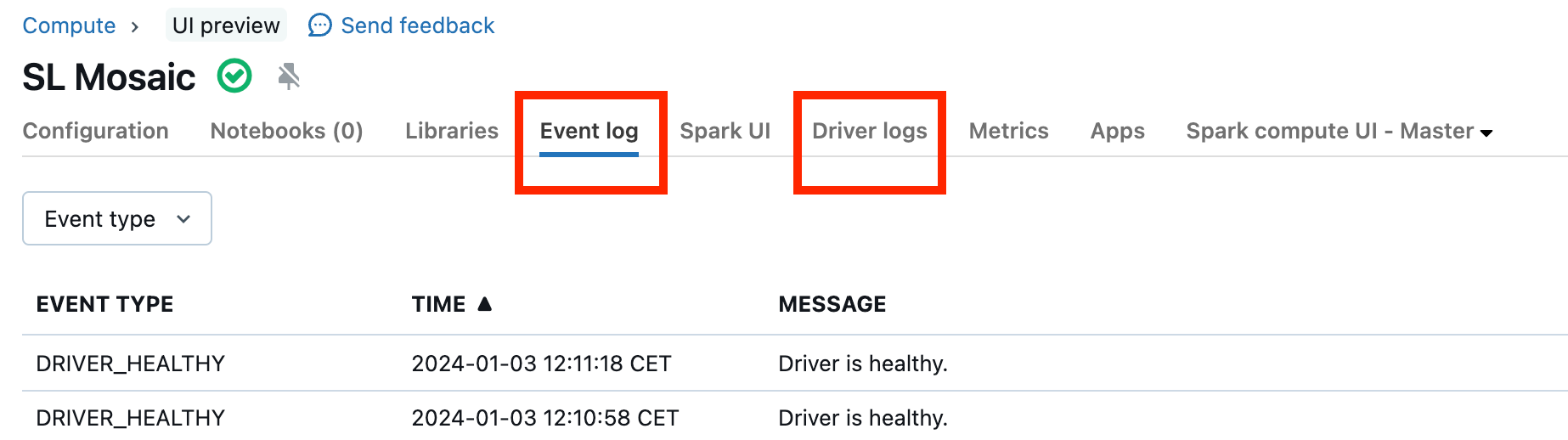
Fehlerhafte Cluster sind selten. Aber wenn ein fehlerhafter Cluster vorliegt, kann es schwierig sein, zu ermitteln, was passiert ist. Es empfiehlt sich gegebenenfalls, den Cluster einfach neu starten, um zu prüfen, ob das Problem dadurch behoben wird. Sie können auch einen Blick in die Protokolle werfen, um zu prüfen, ob Ihnen etwas verdächtig vorkommt. Verwenden Sie dazu die im folgenden Screenshot hervorgehobenen Registerkarten Ereignisprotokoll und Treiberprotokolle:
Sie können Übermittlung des Clusterprotokolls aktivieren, um auf die Protokolle der Worker zuzugreifen. Außerdem können Sie die Protokollebene ändern. Möglicherweise müssen Sie sich aber an Ihr Databricks-Kontoteam wenden, um Hilfe zu erhalten.