Identifizieren von teuren Lesevorgängen im DAG von Spark
Zum DAG
Angenommen, Sie befassen sich mit einer teuren Aufgabe. Wir müssen zunächst die ID der Phase ermitteln, die den Lesevorgang durchführt. Hier sehen wird, dass die Phasen-ID 194 ist:

Jetzt müssen wir zum SQL-DAG gelangen. Scrollen Sie auf der Auftragsseite ganz nach oben, und klicken Sie auf die zugeordnete SQL-Abfrage:

Nun sollte der DAG angezeigt werden. Wenn nicht, scrollen Sie ein bisschen herum, bis Sie ihn sehen:
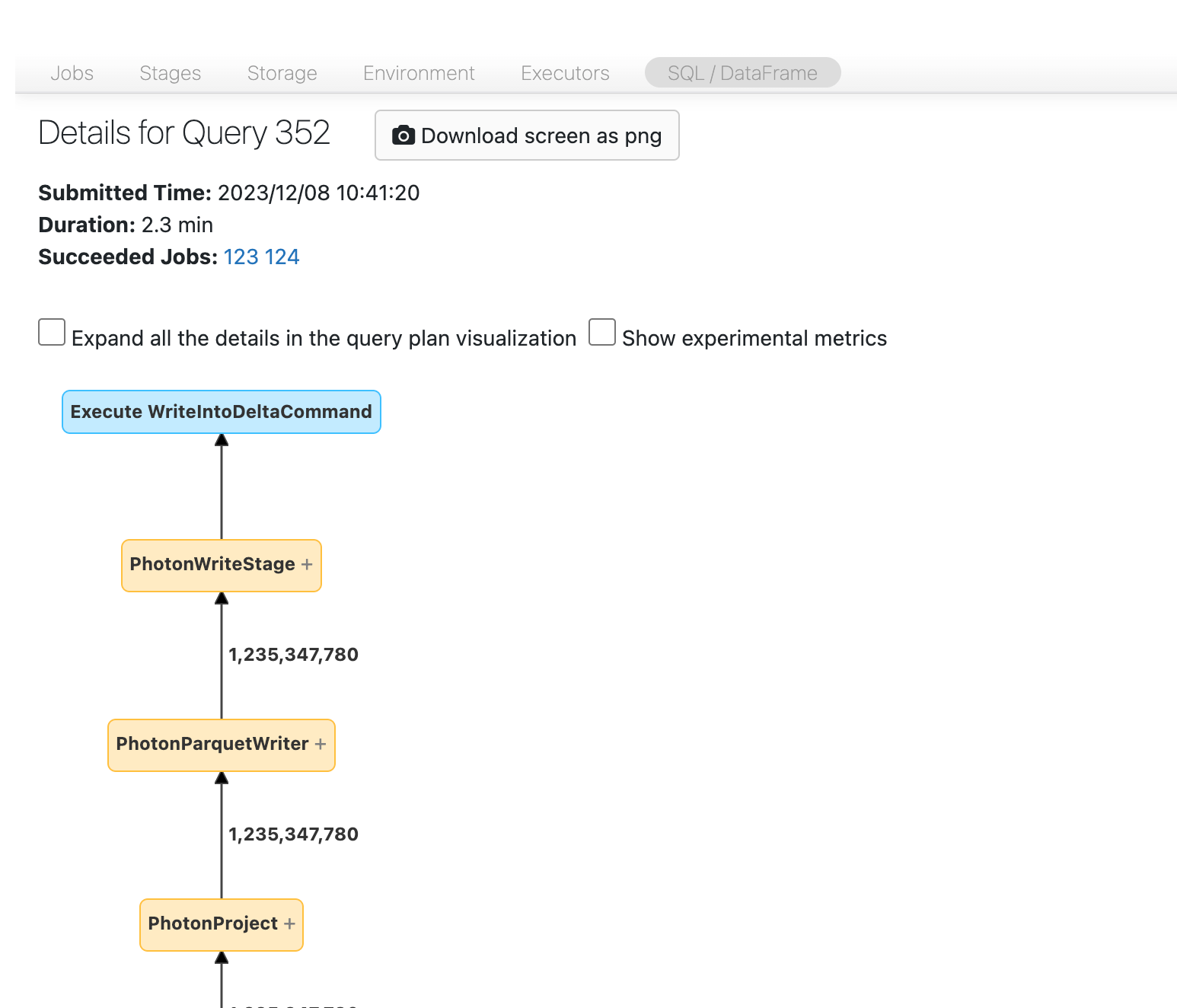
In einigen Fällen können Sie dem DAG folgen und sehen, woher die Daten stammen. Suchen Sie in anderen Fällen nach der notierten Phasen-ID:

Anschließend müssen Sie nach dem „Scan“-Knoten suchen. In diesem Fall sollte klar sein, dass wir eine Tabelle mit dem Namen transactions lesen:

In einigen Fällen müssen Sie möglicherweise auf den Knoten klicken oder einen Rollover über den Knoten ausführen, um die Position der zu lesenden Daten abzurufen.