Fehlerhafte Aufträgen oder entfernte Executors
Sie sehen fehlerhafte Aufträge oder entfernte Executors:
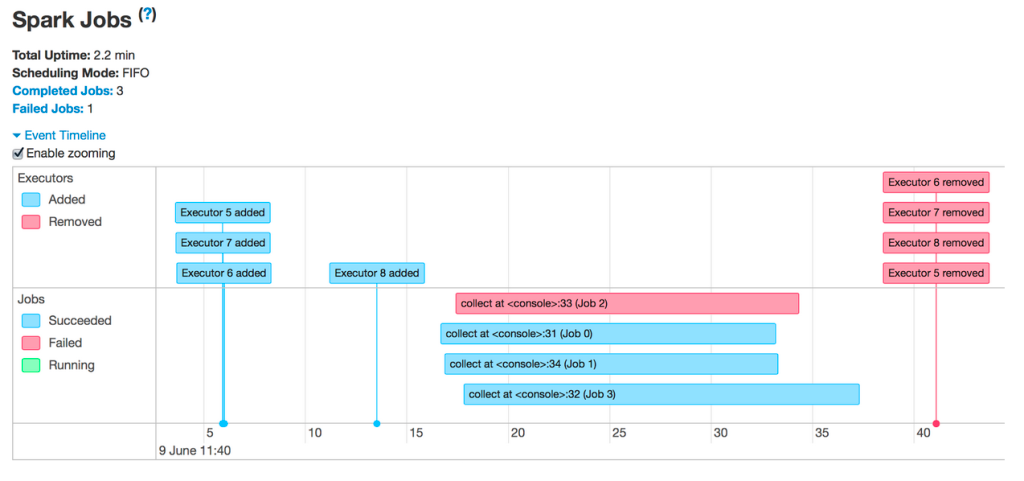
Häufigste Gründe für das Entfernen von Executors:
- Automatische Skalierung: In diesem Fall ist dies ein erwarteter Vorgang und kein Fehler. Siehe Aktivieren der automatischen Skalierung
- Spotinstanzverluste: Der Cloudanbieter gibt Ihre VMs frei. Hier erfahren Sie mehr über reservierte Spotinstanzen.
- Executors verfügen nicht über genügend Arbeitsspeicher.
Fehlerhafte Aufträge
Wenn Ihnen fehlerhafte Jobs angezeigt werden, klicken Sie auf diese, um zu ihrer Seite zu gelangen. Scrollen Sie dann nach unten, um die fehlerhafte Phase und einen Fehlergrund anzuzeigen:

Möglicherweise wird ein allgemeiner Fehler angezeigt. Klicken Sie in der Beschreibung auf den Link, um zu sehen, ob Sie weitere Informationen abrufen können:

Wenn Sie auf dieser Seite nach unten scrollen, können Sie sehen, warum die einzelnen Aufgaben fehlgeschlagen sind. In diesem Fall wird deutlich, dass es ein Speicherproblem gibt:

Fehlerhafte Executors
Um zu ermitteln, warum Ihre Executors fehlschlagen, sollten Sie zuerst im Compute-Ereignisprotokoll überprüfen, ob es eine Erklärung für das Fehlschlagen der Executors gibt. Beispielsweise verwenden Sie Spotinstanzen, und der Cloudanbieter nimmt sie zurück.

Überprüfen Sie, ob Ereignisse vorliegen, die den Verlust von Executors erklären. So werden beispielsweise Meldungen mit dem Hinweis angezeigt, dass die Größe des Clusters geändert wird oder Spotinstanzen verloren gehen.
- Lesen Sie bei Verwendung von Spotinstanzen die Informationen unter Verlust von Spotinstanzen.
- Wenn die Computegrröße mit automatischer Skalierung geändert wurde, ist dies ein erwarteter Vorgang und kein Fehler. Siehe Größenänderung bei Clustern.
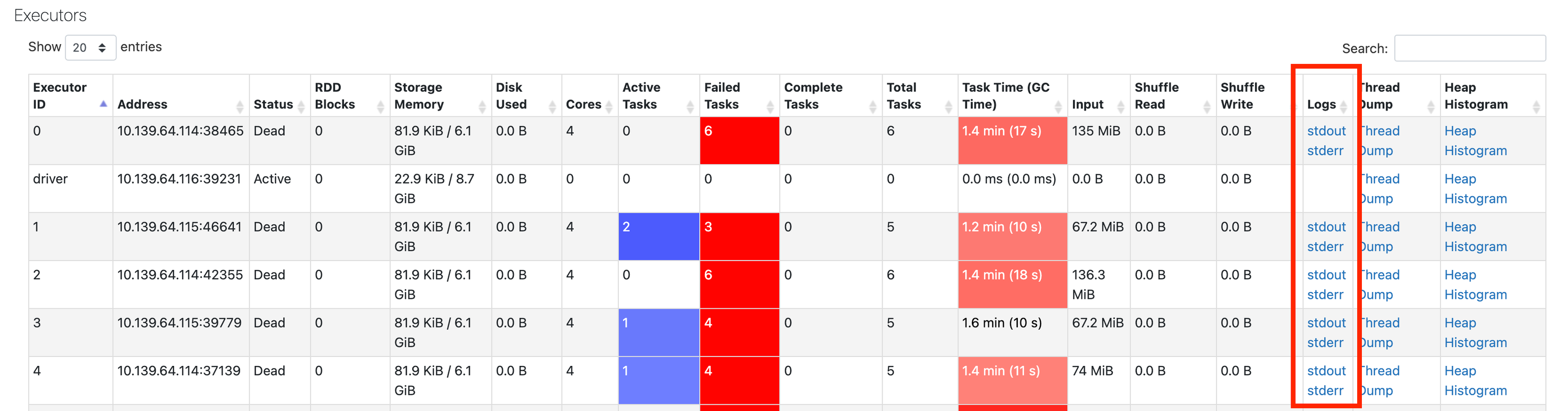
Wenn im Ereignisprotokoll keine Informationen angezeigt werden, navigieren Sie zurück zur Spark-Benutzeroberfläche, und klicken Sie dann auf die Registerkarte Executors:

Hier können Sie die Protokolle von den fehlerhaften Executors abrufen:
Nächster Schritt
Wenn Sie so weit gekommen sind, ist die wahrscheinlichste Erklärung ein Speicherproblem. Der nächste Schritt besteht darin, Speicherprobleme zu untersuchen. Siehe Spark-Speicherprobleme.