Beispiel für die Arbeitsbereichsmodellregistrierung
Hinweis
In dieser Dokumentation wird die Arbeitsbereichsmodellregistrierung behandelt. Azure Databricks empfiehlt die Verwendung von Modellen im Unity Catalog. Modelle im Unity Catalog bieten zentralisierte Modellgovernance, arbeitsbereichsübergreifenden Zugriff, Datenherkunft und Bereitstellung. Die Arbeitsbereichsmodellregistrierung wird in Zukunft eingestellt.
Dieses Beispiel veranschaulicht, wie Sie die Arbeitsbereich-Modellregistrierung verwenden, um eine Machine Learning-Anwendung zu erstellen, die die tägliche Stromerzeugung eines Windparks vorhersagt. Das Beispiel veranschaulicht die folgenden Schritte:
- Nachverfolgen und Protokollieren von Modellen mit MLflow
- Registrieren von Modellen bei der Modellregistrierung
- Beschreiben von Modellen und Durchführen von Übergängen zwischen Modellversionsphasen
- Integrieren registrierter Modelle in Produktionsanwendungen
- Suchen und Ermitteln von Modellen in der Modellregistrierung
- Archivieren und Löschen von Modellen
In diesem Artikel wird beschrieben, wie Sie diese Schritte mithilfe der Benutzeroberflächen und APIs der MLflow-Nachverfolgung und der MLflow-Modellregistrierung ausführen.
Ein Notebook, das alle diese Schritte mithilfe der MLflow-Nachverfolgungs- und Registrierungs-APIs ausführt, finden Sie im Beispielnotebook für die Modellregistrierung.
Laden eines Datasets, Trainieren des Modells und Nachverfolgen mit MLflow-Nachverfolgung
Bevor Sie ein Modell in der Modellregistrierung registrieren können, müssen Sie das Modell zunächst während einer Experimentausführung trainieren und protokollieren. In diesem Abschnitt wird gezeigt, wie Sie das Windpark-Dataset laden, ein Modell trainieren und den Trainingslauf in MLflow protokollieren.
Laden des Datasets
Der folgende Code lädt ein Dataset mit Wetterdaten und Informationen zur Stromerzeugung für einen Windpark in den USA. Das Dataset enthält die Merkmale wind direction, wind speed und air temperature, von denen alle sechs Stunden (einmal um 00:00, einmal um 08:00 und einmal um 16:00) Stichproben genommen werden sowie die tägliche aggregierte Stromerzeugung (power), über mehrere Jahre hinweg.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Trainieren eines Modells
Mit dem folgenden Code wird ein neuronales Netzwerk mit TensorFlow Keras trainiert, um die Stromerzeugung basierend auf den Wettermerkmalen im Dataset vorherzusagen. MLflow wird zum Nachverfolgen der Hyperparameter, Leistungsmetriken, des Quellcodes und der Artefakte des Modells verwendet.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Registrieren und Verwalten des Modells über die MLflow-Benutzeroberfläche
Inhalt dieses Abschnitts:
- Erstellen eines neuen registrierten Modells
- Erkunden der Benutzeroberfläche der Modellregistrierung
- Hinzufügen von Modellbeschreibungen
- Durchführen des Übergangs zwischen Modellversionen
Erstellen eines neuen registrierten Modells
Navigieren Sie zur Seitenleiste „MLflow-Experimentausführungen“, indem Sie auf der rechten Seitenleiste des Azure Databricks-Notebooks auf das Symbol Experiment
 klicken.
klicken.
Suchen Sie die MLflow-Ausführung, die zu der entsprechend Trainingssitzung des TensorFlow Keras-Modells gehört, und öffnen Sie sie auf der „MLflow Run“-Benutzeroberfläche. Klicken Sie dazu auf das Symbol Ausführungsdetails anzeigen.
Scrollen Sie auf der MLflow-Benutzeroberfläche nach unten bis zum Abschnitt Artefakte, und klicken Sie auf das Verzeichnis namens model (Modell). Klicken Sie auf die angezeigte Schaltfläche Modell registrieren.

Wählen Sie im Dropdownmenü Neues Modell erstellen aus, und geben Sie den folgenden Modellnamen ein:
power-forecasting-model.Klicken Sie auf Registrieren. Dadurch wird ein neues Modell namens
power-forecasting-modelregistriert und eine neue Modellversion erstellt:Version 1.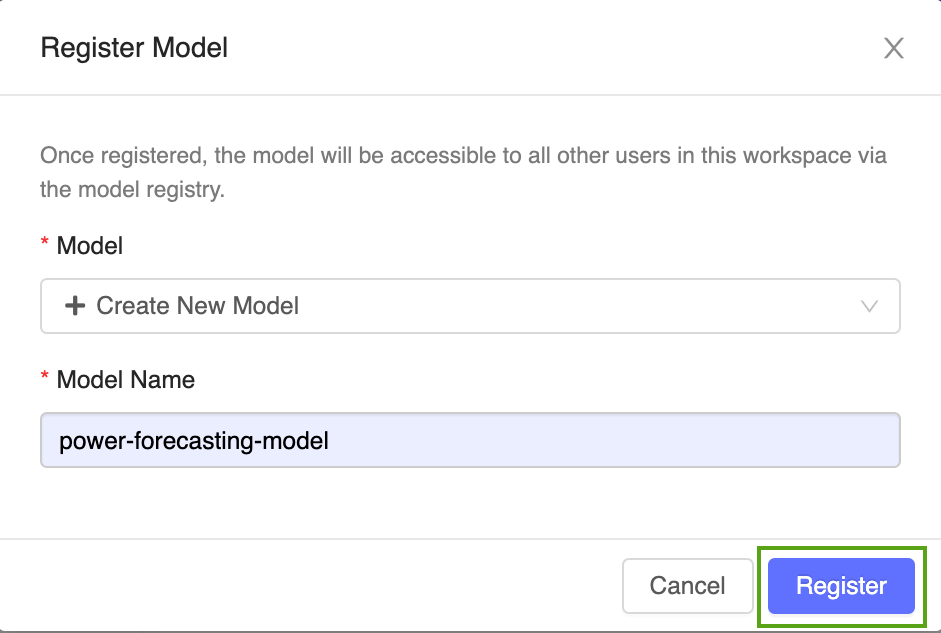
Nach ein paar Augenblicken wird auf der MLflow-Benutzeroberfläche ein Link zu dem neuen registrierten Modell angezeigt. Folgend Sie diesem Link, um die neue Modellversion auf der Benutzeroberfläche der MLflow-Modellregistrierung zu öffnen.
Erkunden der Benutzeroberfläche der Modellregistrierung
Die Seite der Modellversion auf der Benutzeroberfläche der MLflow-Modellregistrierung enthält Informationen zur Version 1 des registrierten Vorhersagemodells, einschließlich des Autors, der Erstellungszeit und der aktuellen Phase.
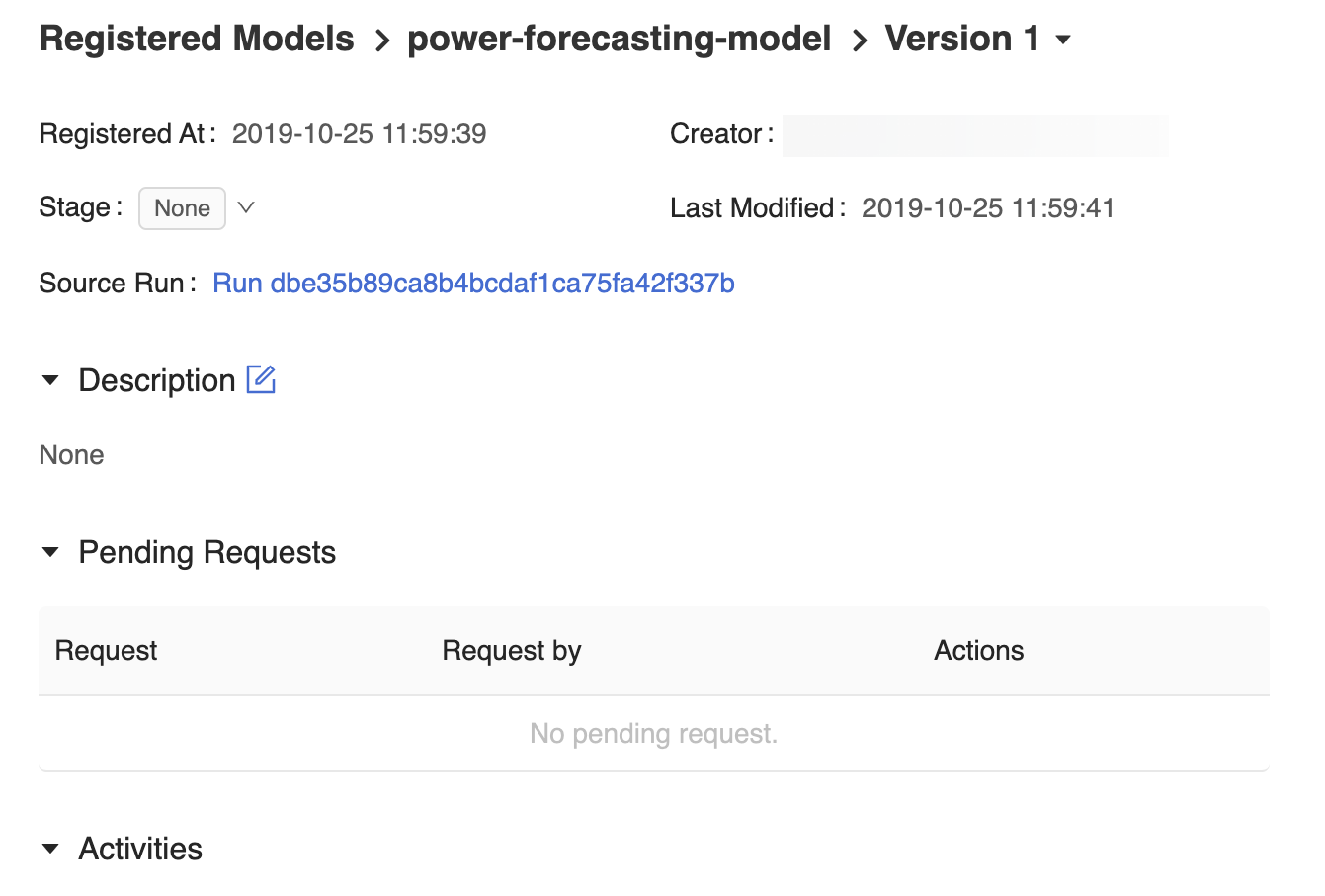
Die Seite der Modellversion enthält auch einen Link Quellausführung, über den die MLflow-Ausführung geöffnet wird, die zum Erstellen des Modells auf der „MLflow Run“-Benutzeroberfläche verwendet wurde. Über die MLflow-Benutzeroberfläche für die Ausführung können Sie auf den Link Quellnotebook zugreifen, um eine Momentaufnahme des Azure Databricks Notebooks anzuzeigen, das zum Trainieren des Modells verwendet wurde.


Um zurück zur MLflow-Modellregistrierung zu navigieren, klicken Sie in der Randleiste auf ![]() Modelle.
Modelle.
Auf der resultierenden Startseite der MLflow-Modellregistrierung wird eine Liste aller registrierten Modelle in Ihrem Azure Databricks-Arbeitsbereich angezeigt, einschließlich ihrer Versionen und Phasen.
Klicken Sie auf den Link power-forecasting-model, um die Seite des registrierten Modells zu öffnen, auf der alle Versionen des Vorhersagemodells angezeigt werden.
Hinzufügen von Modellbeschreibungen
Sie können registrierten Modellen und Modellversionen Beschreibungen hinzufügen. Beschreibungen registrierter Modelle sind nützlich für die Aufzeichnung von Informationen, die auf mehrere Modellversionen zutreffen (z. B. eine allgemeine Übersicht über das Modellierungsproblem und das Dataset). Beschreibungen der Modellversion sind nützlich, um die eindeutigen Attribute einer bestimmten Modellversion (z. B. die Methodik und den Algorithmus, mit denen das Modell entwickelt wurden) detailliert zu beschreiben.
Fügen Sie dem registrierten Modell für die Stromerzeugungsvorhersage eine allgemeine Beschreibung hinzu. Klicken Sie auf das Symbol
 , und geben Sie die folgende Beschreibung ein:
, und geben Sie die folgende Beschreibung ein:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.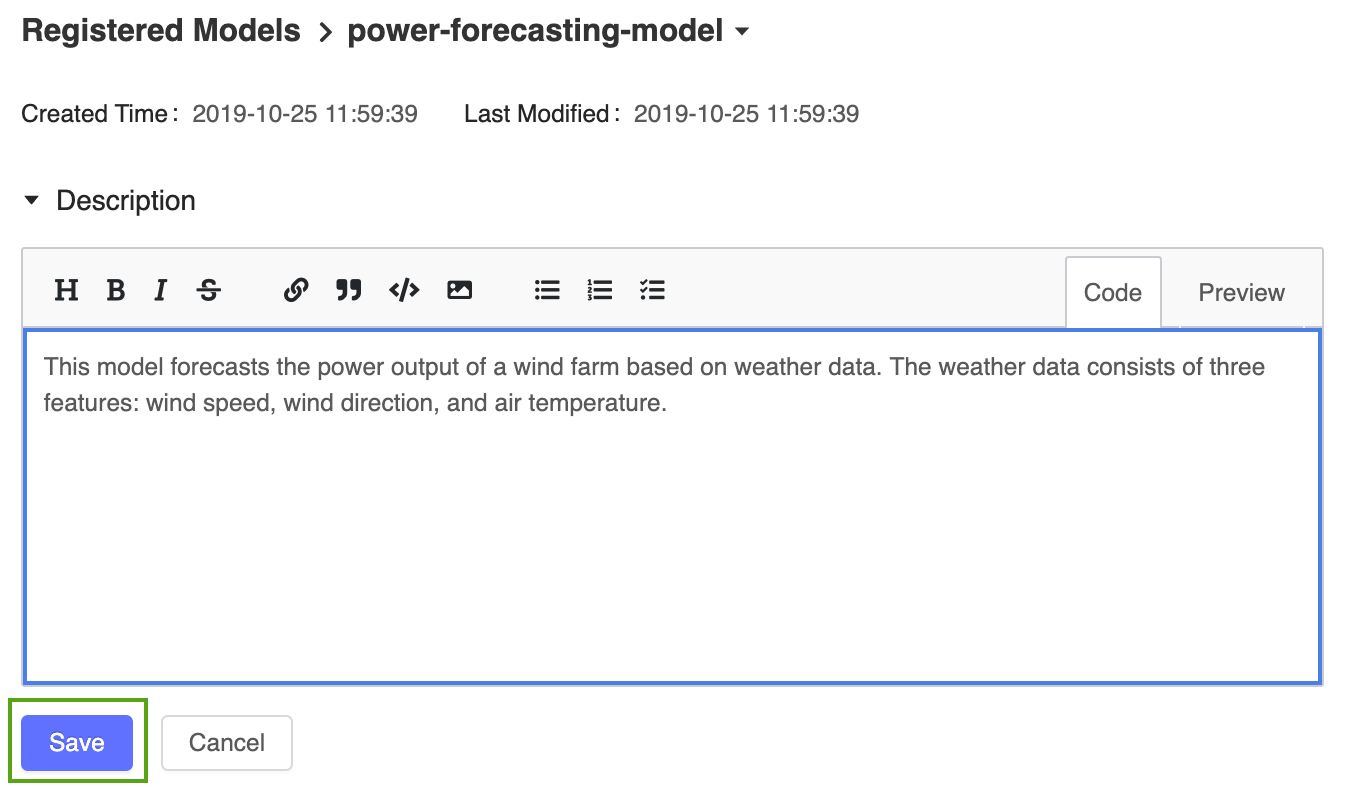
Klicken Sie auf Speichern.
Klicken Sie auf der Seite des registrierten Modells auf den Link Version 1, um zurück zur Seite der Modellversion zu navigieren.
Klicken Sie auf das Symbol
, und geben Sie die folgende Beschreibung ein:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.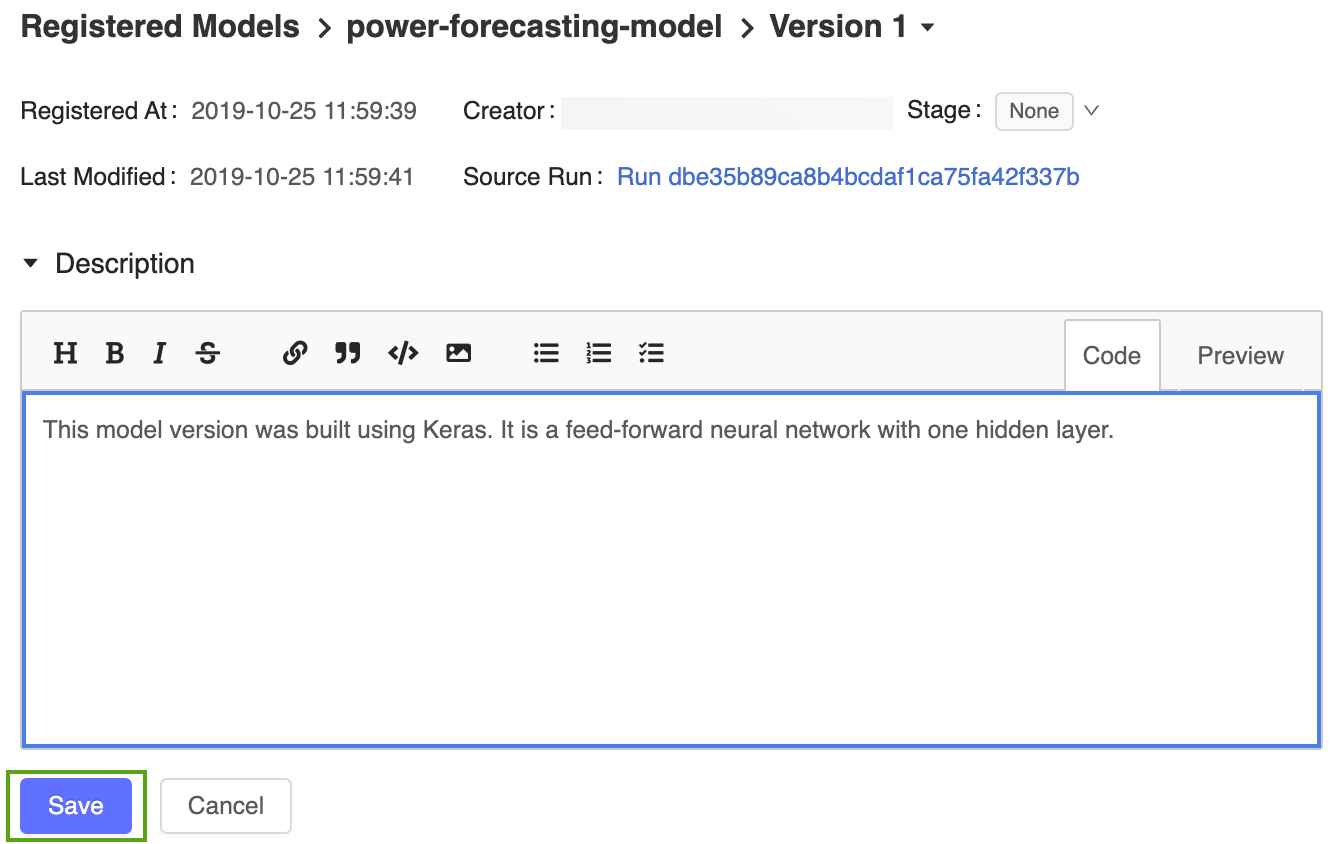
Klicken Sie auf Speichern.
Durchführen des Übergangs zwischen Modellversionen
Die MLflow-Modellregistrierung definiert mehrere Modellphasen: None (Keine), Staging, Production (Produktion) und Archived. Jede Phase hat eine eindeutige Bedeutung. Staging ist beispielsweise für das Testen des Modells bestimmt, während Production (Produktion) für Modelle gedacht ist, die die Test- oder Überprüfungsprozesse abgeschlossen haben und die in Anwendungen bereitgestellt wurden.
Klicken Sie auf die Schaltfläche Stage (Phase), um die Liste der verfügbaren Modellphasen und Ihre verfügbaren Phasenübergangsoptionen anzuzeigen.
Wählen Sie Transition to->Production (Übergang zu -> Produktion) aus, und klicken Sie im Bestätigungsfenster des Phasenübergangs auf OK, um das Modell an die Phase Production (Produktion) zu übergeben.

Nachdem die Modellversion in die Produktion übergegangen ist, wird die aktuelle Phase auf der Benutzeroberfläche angezeigt, und dem Aktivitätsprotokoll wird ein Eintrag hinzugefügt, der den Übergang wiedergibt.


Die MLflow-Modellregistrierung gestattet, dass mehrere Modellversionen in derselben Phase sind. Beim Verweisen auf ein Modell anhand der Phase verwendet die Modellregistrierung die neueste Modellversion (die Modellversion mit der höchsten Versions-ID). Auf der Seite des registrierten Modells werden alle Versionen eines bestimmten Modells angezeigt.
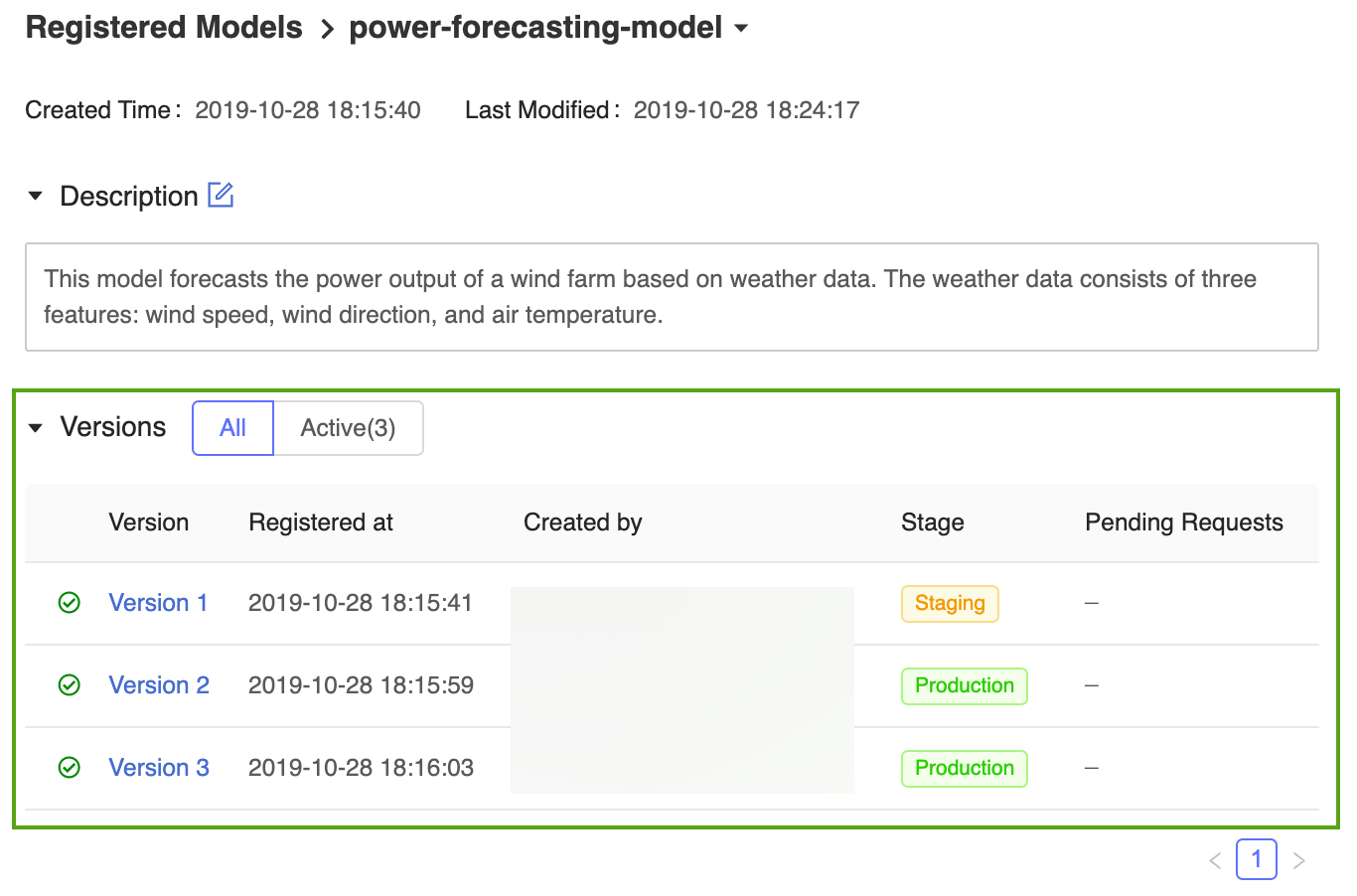
Registrieren und Verwalten des Modells über die MLflow-API
Inhalt dieses Abschnitts:
- Programmgesteuertes Definieren des Modellnamens
- Registrieren des Modells
- Hinzufügen von Modell- und Modellversionsbeschreibungen mithilfe der API
- Durchführen des Übergangs zwischen Modellversionen und Abrufen von Details mithilfe der API
Programmgesteuertes Definieren des Modellnamens
Nachdem das Modell nun registriert und in die Produktion übergegangen ist, können Sie mit programmgesteuerten MLflow-APIs darauf verweisen. Definieren Sie den Namen des registrierten Modells wie folgt:
model_name = "power-forecasting-model"
Registrieren des Modells
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Hinzufügen von Modell- und Modellversionsbeschreibungen mithilfe der API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Durchführen des Übergangs zwischen Modellversionen und Abrufen von Details mithilfe der API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Laden von Versionen des registrierten Modells mithilfe der API
Die Komponente „MLflow-Modelle“ definiert Funktionen zum Laden von Modellen aus mehreren Machine Learning-Frameworks. Beispielsweise wird mlflow.tensorflow.load_model() verwendet, um TensorFlow-Modelle zu laden, die im MLflow-Format gespeichert wurden. mlflow.sklearn.load_model() wird verwendet, um scikit-learn-Modelle zu laden, die im MLflow-Format gespeichert wurden.
Diese Funktionen können Modelle aus der MLflow-Modellregistrierung laden.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Vorhersagen der Stromerzeugung mit dem Produktionsmodell
In diesem Abschnitt wird das Produktionsmodell verwendet, um Wettervorhersagedaten für den Windpark auszuwerten. Die forecast_power()-Anwendung lädt die neueste Version des Vorhersagemodells aus der angegebenen Phase und verwendet es, um die Stromerzeugung für die nächsten fünf Tage vorherzusagen.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Erstellen einer neuen Modellversion
Klassische Machine Learning-Methoden sind auch bei der Stromerzeugungsvorhersage effektiv. Der folgende Code trainiert ein Modell mit einer zufälligen Gesamtstruktur (Random Forest) mit scikit-learn und registriert es über die mlflow.sklearn.log_model()-Funktion bei der MLflow-Modellregistrierung.
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Abrufen der neuen Modellversions-ID mithilfe der MLflow-Modellregistrierungssuche
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Hinzufügen einer Beschreibung zur neuen Modellversion
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Durchführen des Übergangs der neuen Modellversion zu „Staging“ und Testen des Modells
Vor der Bereitstellung eines Modells in einer Produktionsanwendung ist es häufig die bewährte Methode, es in einer Stagingumgebung zu testen. Mit dem folgenden Code wird die neue Modellversion an Staging übergeben und ihre Leistung bewertet.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Bereitstellen der neuen Modellversion in der Produktion
Nachdem überprüft wurde, ob die neue Modellversion im Staging gut funktioniert, übergibt der folgende Code das Modell in die Produktion und verwendet genau denselben Anwendungscode aus dem Abschnitt Vorhersagen der Stromerzeugung mit dem Produktionsmodell, um eine Stromerzeugungsvorhersage zu erstellen.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Es gibt jetzt zwei Modellversionen des Vorhersagemodells in der Produktionsphase: die im Keras-Modell trainierte Modellversion und die in scikit-learn trainierte Version.

Hinweis
Beim Verweisen auf ein Modell anhand der Phase verwendet die MLflow-Modellmodellregistrierung automatisch die neueste Produktionsversion. Dadurch können Sie Ihre Produktionsmodelle aktualisieren, ohne den Anwendungscode zu ändern.
Archivieren und Löschen von Modellen
Wenn eine Modellversion nicht mehr verwendet wird, können Sie sie archivieren oder löschen. Sie können auch ein vollständiges registriertes Modell löschen. Dadurch werden alle zugehörigen Modellversionen entfernt.
Archivieren der Version 1 des Modells für die Stromerzeugungsvorhersage
Archivieren der Version 1 des Modells für die Stromerzeugungsvorhersage, weil es nicht mehr verwendet wird. Sie können Modelle auf der Benutzeroberfläche der MLflow-Modellregistrierung oder über die MLflow-API archivieren.
Archivieren der Version 1 auf der MLflow-Benutzeroberfläche
So archivieren Sie die Version 1 des Modells für die Stromerzeugungsvorhersage
Öffnen Sie seine entsprechende Seite der Modellversion auf der Benutzeroberfläche der MLflow-Modellregistrierung:

Klicken Sie auf die Schaltfläche Stage (Phase), und wählen Sie Transition To ->Archived (Übergang zu -> Archiviert) aus:
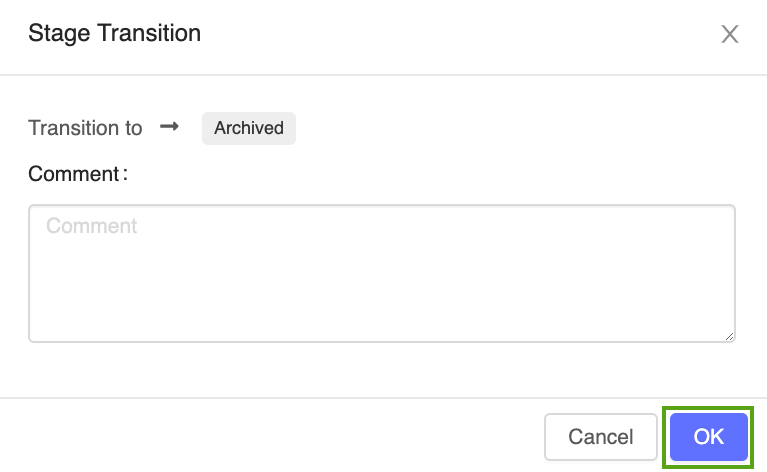
Klicken Sie im Bestätigungsfenster für den Phasenübergang auf OK.

Archivieren der Version 1 mithilfe der MLflow-API
Im folgenden Code wird die MlflowClient.update_model_version()-Funktion verwendet, um die Version 1 des Modells für die Stromerzeugungsvorhersage zu archivieren.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Löschen der Version 1 des Modells für die Stromerzeugungsvorhersage
Sie können ebenfalls die MLflow-Benutzeroberfläche oder die MLflow-API verwenden, um Modellversionen zu löschen.
Warnung
Das Löschen von Modellversionen ist endgültig und kann nicht rückgängig macht werden.
Löschen der Version 1 auf der MLflow-Benutzeroberfläche
So löschen Sie die Version 1 des Modells für die Stromerzeugungsvorhersage
Öffnen Sie seine entsprechende Seite der Modellversion auf der Benutzeroberfläche der MLflow-Modellregistrierung.
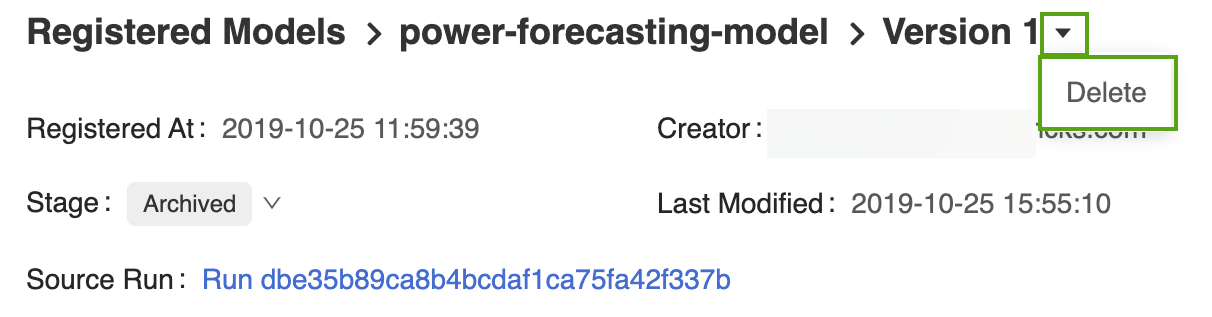
Wählen Sie den Dropdownpfeil neben dem Versionsbezeichner aus, und klicken Sie auf Löschen.
Löschen der Version 1 mithilfe der MLflow-API
client.delete_model_version(
name=model_name,
version=1,
)
Löschen des Modells mithilfe der MLflow-API
Sie müssen zuerst alle verbleibenden Modellversionsphasen an None (Keine) oder Archived (Archiviert) übergeben.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)