Organisieren von Trainingsausführungen mit MLflow-Experimenten
Bei Experimenten handelt es sich um Organisationseinheiten für Ihre Modelltrainingsausführungen. Es gibt zwei Typen von Experimenten: Arbeitsbereich und Notebook.
- Sie können ein Arbeitsbereichsexperiment über die Databricks Mosaic KI-Benutzeroberfläche oder die MLflow-API erstellen. Arbeitsbereichsexperimente sind keinem Notebook zugeordnet, und jedes Notebook kann eine Ausführung für diese Experimente mithilfe der Experiment-ID oder des Experimentnamens protokollieren.
- Ein Notebookexperiment ist einem bestimmten Notebook zugeordnet. Azure Databricks erstellt automatisch ein Notebookexperiment, wenn beim Starten einer Ausführung mithilfe des Befehls mlflow.start_run() kein aktives Experiment vorhanden ist.
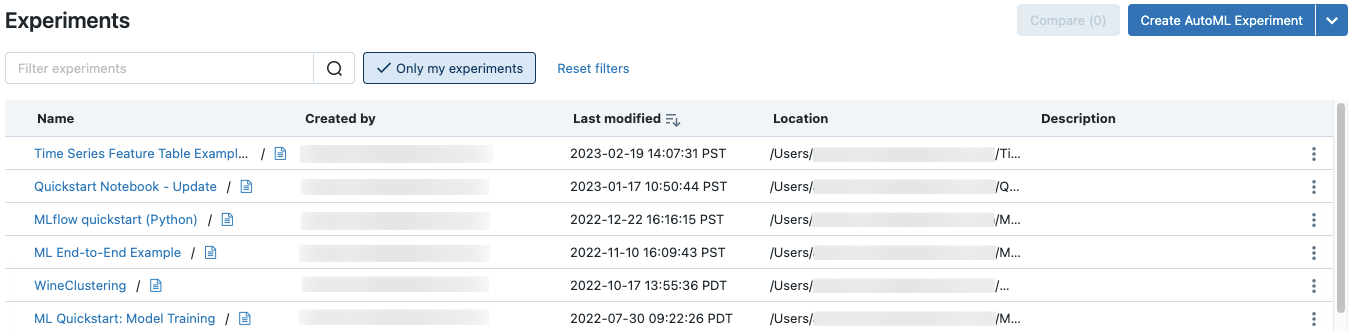
Klicken Sie auf der Seitenleiste auf Machine Learning > Experimente, um alle Experimente in einem Arbeitsbereich anzeigen, auf die Sie Zugriff haben.
Erstellen von Arbeitsbereichsexperimenten
In diesem Abschnitt wird beschrieben, wie Sie ein Arbeitsbereichsexperiment mithilfe der Azure Databricks--Benutzeroberfläche erstellen. Sie können ein Arbeitsbereichsexperiment direkt im Arbeitsbereich oder auf der Seite „Experimente“ erstellen.
Sie können auch die MLflow-API oder den Databricks-Terraform-Anbieter mit databricks_mlflow_experiment verwenden.
Anweisungen zum Protokollieren von Ausführungen in Arbeitsbereichsexperimenten finden Sie unter Beispielnotebook zur Protokollierung.
Klicken Sie in der Randleiste auf
 Arbeitsbereich.
Arbeitsbereich.Navigieren Sie zu dem Ordner, in dem Sie das Experiment erstellen möchten.
Klicken Sie mit der rechten Maustaste auf den Ordner, und wählen Sie Erstellen > MLflow-Experiment aus.
Geben Sie im Dialogfeld „MLflow-Experiment erstellen“ einen Namen für das Experiment und einen optionalen Artefaktspeicherort ein. Wenn Sie keinen Artefaktspeicherort angeben, werden Artefakte im vom MLflow verwalteten Artefaktspeicher gespeichert:
dbfs:/databricks/mlflow-tracking/<experiment-id>.Azure Databricks unterstützt Unity-Katalogvolumes, Azure Blob Storage und Azure Data Lake-Speicherartefaktespeicherorte.
In MLflow 2.15.0 und höher können Sie Artefakte in einem Unity-Katalogvolume speichern. Wenn Sie ein MLflow-Experiment erstellen, geben Sie einen Volumespfad des Formulars
dbfs:/Volumes/catalog_name/schema_name/volume_name/user/specified/pathals Artefaktspeicherort des MLflow-Experiments an.Um Artefakte in Azure Blob Storage zu speichern, geben Sie einen URI im Formular
wasbs://<container>@<storage-account>.blob.core.windows.net/<path>an. In Azure Blob Storage gespeicherte Artefakte werden nicht auf der MLflow-Benutzeroberfläche angezeigt. Sie müssen sie mithilfe eines Blob Storage-Clients herunterladen.Hinweis
Wenn Sie ein Artefakt an einem anderen Speicherort als DBFS speichern, wird das Artefakt nicht auf der MLflow-Benutzeroberfläche angezeigt. Modelle, die an anderen Speicherorten als DBFS gespeichert sind, können nicht in der Modellregistrierung registriert werden.
Klicken Sie auf Erstellen. Es wird ein leeres Experiment angezeigt.
Sie können auch ein neues Arbeitsbereichsexperiment auf der Seite „Experimente“ erstellen. Um ein neues Experiment zu erstellen, verwenden Sie das Dropdownmenü  . Im Dropdownmenü können Sie entweder ein AutoML-Experiment oder ein leeres Experiment auswählen.
. Im Dropdownmenü können Sie entweder ein AutoML-Experiment oder ein leeres Experiment auswählen.
AutoML-Experiment. Die Seite AutoML-Experiment konfigurieren wird angezeigt. Informationen zur Verwendung von AutoML finden Sie unter "Was ist AutoML?"
Leeres Experiment. Das Dialogfeld MLflow-Experiment erstellen wird angezeigt. Geben Sie einen Namen und einen optionalen Artefaktspeicherort in das Dialogfeld ein, um ein neues Arbeitsbereichsexperiment zu erstellen. Der Standardartefaktspeicherort ist
dbfs:/databricks/mlflow-tracking/<experiment-id>.Um Experimentausführungen zu protokollieren, rufen Sie
mlflow.set_experiment()mit dem Experimentpfad auf. Der Experimentpfad wird oben auf der Experimentseite angezeigt. Weitere Informationen und ein Beispielnotebook finden Sie unter Beispielnotebook zur Protokollierung.
Erstellen von Notebookexperimenten
Wenn Sie den Befehl mlflow.start_run() in einem Notebook verwenden, protokolliert die Ausführung Metriken und Parameter im aktiven Experiment. Wenn kein Experiment aktiv ist, erstellt Azure Databricks ein Notebookexperiment. Ein Notebookexperiment hat den gleichen Namen und dieselbe ID wie das entsprechende Notebook. Die Notebook-ID ist der numerische Bezeichner am Ende einer Notebook-URL und -ID.
Alternativ können Sie einen Azure Databricks-Arbeitsbereichspfad an ein vorhandenes Notebook in mlflow.set_experiment() übergeben, um ein Notebook-Experiment dafür zu erstellen.
Anweisungen zum Protokollieren von Ausführungen in Notebookexperimenten finden Sie unter Beispielnotebook zur Protokollierung.
Hinweis
Wenn Sie ein Notebookexperiment mithilfe der API löschen (z. B MlflowClient.tracking.delete_experiment() in Python), wird das Notebook selbst in den Ordner „Papierkorb“ verschoben.
Anzeigen von Experimenten
Jedes Experiment, auf das Sie Zugriff haben, wird auf der Seite Experimente angezeigt. Auf dieser Seite können Sie ein beliebiges Experiment anzeigen. Klicken Sie auf einen Experimentnamen, um die Seite Experimente anzuzeigen.
Weitere Möglichkeiten für den Zugriff auf die Seite „Experiment“:
- Sie können über das Arbeitsbereichsmenü auf die Seite „Experiment“ für ein Arbeitsbereichsexperiment zugreifen.
- Sie können über das Notebook auf die Seite „Experiment“ für ein Notebookexperiment zugreifen.
Um nach Experimenten zu suchen, geben Sie Text in das Feld Experimente filtern ein, und drücken Sie die EINGABETASTE, oder klicken Sie auf das Lupensymbol. Die Experimentliste ändert sich so, dass nur die Experimente angezeigt werden, die den Suchtext in der Spalte Name, Erstellt von, Speicherort oder Beschreibung enthalten.
Klicken Sie auf den Namen eines Experiments in der Tabelle, um dessen Seite „Experiment“ anzuzeigen:
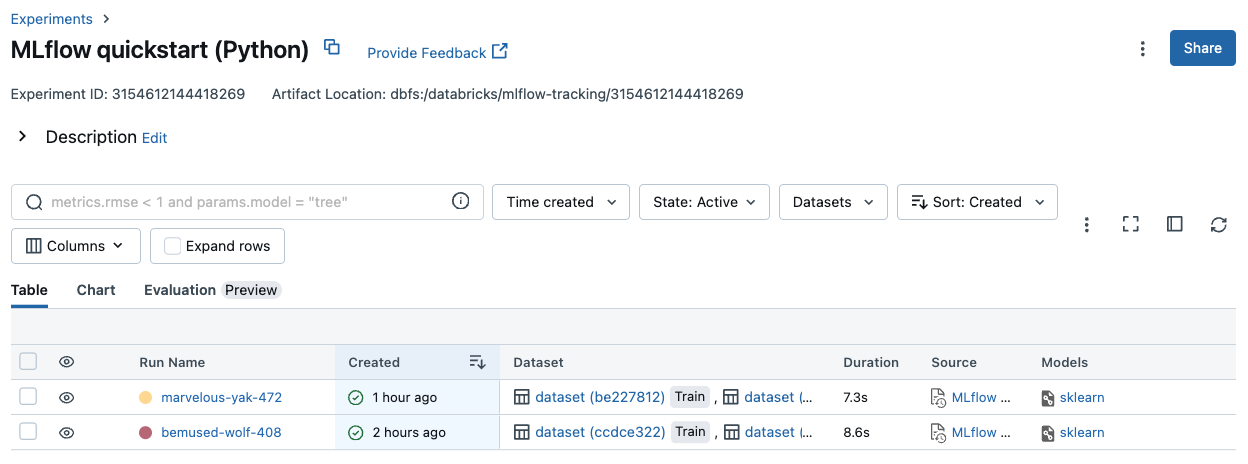
Auf der Seite „Experiment“ werden alle dem Experiment zugeordneten Ausführungen aufgeführt. In der Tabelle können Sie die Ausführungsseite für jede Ausführung öffnen, die dem Experiment zugeordnet ist, indem Sie auf den Ausführungsnamen klicken. In der Spalte Quelle erhalten Sie Zugriff auf die Notebookversion, die die Ausführung erstellt hat. Sie können auch Metriken oder Parametereinstellungen verwenden, um Ausführungen zu suchen und zu filtern.
Anzeigen von Arbeitsbereichsexperimenten
- Klicken Sie in der Randleiste auf Arbeitsbereich.
- Gehen Sie zum Ordner mit dem Experiment.
- Klicken Sie auf den Namen des Experiments.
Anzeigen von Notebookexperimenten
Klicken Sie auf der rechten Seitenleiste des Notebooks auf das Symbol Experiment![]() .
.
Die Seitenleiste „Experimentausführungen“ wird mit einer Zusammenfassung der einzelnen Ausführungen angezeigt, die dem Notebookexperiment zugeordnet sind, einschließlich Ausführungsparametern und Metriken. Am oberen Rand der Seitenleiste befindet sich der Name des Experiments, in dem das Notebook zuletzt Ausführungen protokolliert hat (entweder ein Notebookexperiment oder ein Arbeitsbereichsexperiment).

Über die Seitenleiste können Sie zur Seite „Experiment“ oder direkt zu einer Ausführung navigieren.
- Um das Experiment anzuzeigen, klicken Sie ganz rechts neben Experimentausführungen auf
 .
. - Klicken Sie zum Anzeigen einer Ausführung auf den Namen der Ausführung.
Verwalten von Experimenten
Sie können Berechtigungen für ein Experiment, das Sie besitzen, auf der Seite Experimente oder im Arbeitsbereichsmenü umbenennen, löschen oder verwalten.
Hinweis
Sie können Berechtigungen für ein MLflow-Experiment, das von einem Notebook in einem Databricks Git-Ordner erstellt wurde, nicht direkt umbenennen, löschen oder verwalten. Sie müssen diese Aktionen auf Git-Ordnerebene ausführen.
Umbenennen von Experimenten über die Seite „Experimente“ oder die Seite „Experiment“
Wichtig
Dieses Feature befindet sich in der Public Preview.
Um ein Experiment auf der Seite Experimente oder der Seite des Experiments umzubenennen, klicken Sie auf das ![]() , und wählen Sie Umbenennen aus.
, und wählen Sie Umbenennen aus.
Umbenennen von Experimenten über das Arbeitsbereichsmenü
- Klicken Sie in der Randleiste auf Arbeitsbereich.
- Gehen Sie zum Ordner mit dem Experiment.
- Klicken Sie mit der rechten Maustaste auf den Namen des Experiments, und wählen Sie Umbenennen aus.
Kopieren von Experimentnamen
Um den Experimentnamen zu kopieren, klicken Sie auf ![]() oben auf der Seite „Experiment“. Sie können diesen Namen im MLflow-Befehl
oben auf der Seite „Experiment“. Sie können diesen Namen im MLflow-Befehl set_experiment verwenden, um das aktive MLflow-Experiment festzulegen.
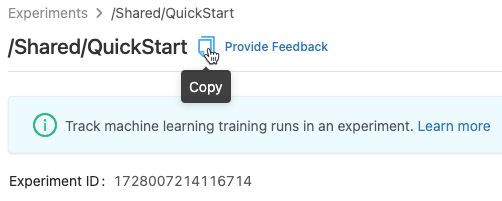
Sie können den Experimentnamen auch über die Seitenleiste „Experiment“ in einem Notebook kopieren.
Löschen von Notebookexperimenten
Notebookexperimente sind Teil des Notebooks und können nicht separat gelöscht werden. Wenn Sie ein Notebook löschen, wird das zugehörige Notebookexperiment gelöscht. Wenn Sie ein Notebookexperiment über die Benutzeroberfläche löschen, wird das Notebook ebenfalls gelöscht.
Verwenden Sie zum Löschen von Notebookexperimenten mithilfe der API die Arbeitsbereichs-API, um sicherzustellen, dass sowohl das Notebook als auch das Experiment aus dem Arbeitsbereich gelöscht werden.
Löschen von Arbeitsbereichsexperimenten über das Arbeitsbereichsmenü
- Klicken Sie in der Randleiste auf Arbeitsbereich.
- Gehen Sie zum Ordner mit dem Experiment.
- Klicken Sie mit der rechten Maustaste auf den Namen des Experiments, und wählen Sie In Papierkorb verschieben aus.
Löschen von Arbeitsbereichs- oder Notebookexperiments auf der Seite „Experimente“ oder der Seite „Experiment“
Wichtig
Dieses Feature befindet sich in der Public Preview.
Um ein Experiment von der Seite Experimente oder der Seite des Experiments aus zu löschen, klicken Sie auf das ![]() , und wählen Sie Löschen aus.
, und wählen Sie Löschen aus.
Wenn Sie ein Notebookexperiment löschen, wird das Notebook ebenfalls gelöscht.
Ändern von Berechtigungen für ein Experiment
Um die Berechtigungen für ein Experiment auf der Seite „Experiment“ zu ändern, klicken Sie auf Freigabe.

Sie können die Berechtigungen für ein Experiment, das Sie besitzen, auf der Seite Experimente ändern. Klicken Sie auf ![]() in der Spalte Aktionen, und wählen Sie Berechtigung aus.
in der Spalte Aktionen, und wählen Sie Berechtigung aus.
Informationen zu Experimentberechtigungsebenen finden Sie unter Zugriffssteuerungslisten für MLFlow-Experimente.
Kopieren von Experimenten zwischen Arbeitsbereichen
Um MLflow-Experimente zwischen Arbeitsbereichen zu migrieren, können Sie das communitygesteuerte Open Source Projekt MLflow Export-Import verwenden.
Mit diesen Tools können Sie folgende Aktionen ausführen:
- Teilen und Zusammenarbeiten mit anderen wissenschaftlichen Fachkräften für Daten auf demselben oder einem anderen Nachverfolgungsserver. Sie können beispielsweise ein Experiment von einem anderen Benutzer in Ihren Arbeitsbereich klonen.
- Kopieren von MLflow-Experimenten und Ausführen dieser Experimente auf Ihrem lokalen Nachverfolgungsserver in Ihren Databricks-Arbeitsbereich.
- Sichern von unternehmenskritischen Experimenten und Modellen in einem anderen Databricks-Arbeitsbereich.