Prognose (serverlos) mit AutoML
Wichtig
Dieses Feature befindet sich in der Public Preview.
In diesem Artikel erfahren Sie, wie Sie ein serverloses Prognoseexperiment mithilfe der Mosaic AI-Modelltrainings-UI durchführen.
Mosaik AI Model Training - Prognose vereinfacht die Prognose von Zeitreihendaten, indem automatisch der beste Algorithmus und Hyperparameter ausgewählt werden, während sie auf vollständig verwalteten Computeressourcen ausgeführt werden.
Informationen zum Unterschied zwischen serverloser Prognose und klassischer Berechnungsprognose finden Sie unter Serverless-Prognose im Vergleich zur klassischen Berechnungsprognose.
Anforderungen
Schulungsdaten mit einer Zeitreihenspalte, die als Unity-Katalogtabelle gespeichert werden.
Wenn der Arbeitsbereich das Secure Egress Gateway (SEG) aktiviert hat, muss
pypi.orgder Liste der zulässigen Domänen hinzugefügt werden. Siehe Verwaltung von Netzwerkrichtlinien für die serverlose Ausgangskontrolle.
Erstellen eines Prognoseexperiments mit der Benutzeroberfläche
Wechseln Sie zu Ihrer Azure Databricks-Startseite, und klicken Sie in der Randleiste auf Experimente.
Wählen Sie in der Kachel Vorhersagen die Option Training starten aus.
Wählen Sie die Schulungsdaten aus einer Liste der Unity-Katalogtabellen aus, auf die Sie zugreifen können.
- Spalte "Zeit": Wählen Sie die Spalte aus, die die Zeiträume für die Zeitreihe enthält. Die Spalten müssen vom Typ
timestampoderdatesein. - Prognosehäufigkeit: Wählen Sie die Zeiteinheit aus, die die Häufigkeit Ihrer Eingabedaten darstellt. Beispiel: Minuten, Stunden, Tage, Monate. Dadurch wird die Granularität Ihrer Zeitreihe bestimmt.
- Prognosehorizont: Geben Sie an, wie viele Einheiten der ausgewählten Häufigkeit in die Zukunft prognostiziert werden sollen. Zusammen mit der Prognosehäufigkeit definiert dies sowohl die Zeiteinheiten als auch die Anzahl der zu prognostizierenden Zeiteinheiten.
Anmerkung
Um den Auto-ARIMA Algorithmus zu verwenden, muss die Zeitreihe eine normale Häufigkeit aufweisen, wobei das Intervall zwischen zwei Punkten während der gesamten Zeitreihe identisch sein muss. AutoML behandelt fehlende Zeitschritte, indem diese Werte mit dem vorherigen Wert ausgefüllt werden.
- Spalte "Zeit": Wählen Sie die Spalte aus, die die Zeiträume für die Zeitreihe enthält. Die Spalten müssen vom Typ
Wählen Sie eine Prognosezielspalte aus, die das Modell vorhersagen soll.
Geben Sie optional eine Unity-Katalogtabelle Prognosedatenpfad an, um die Ausgabeprognosen zu speichern.
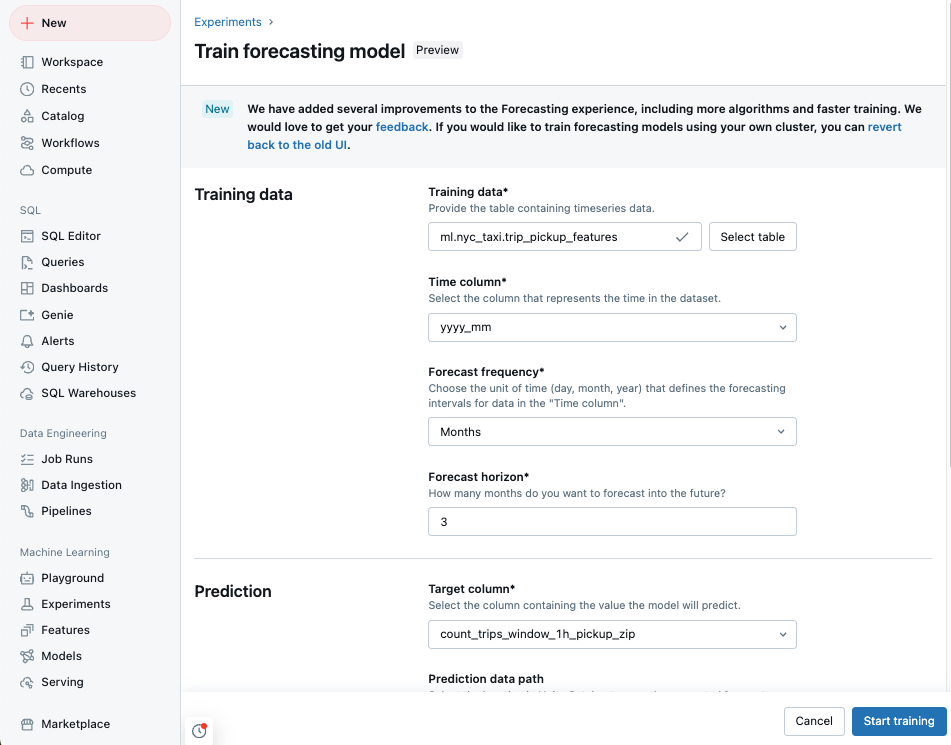
Wählen Sie einen Unity Catalog-Speicherort und -Namen für die Modellregistrierung aus.
Legen Sie optional erweiterte Optionen fest:
- Experimentname: Geben Sie einen MLflow-Experimentnamen an.
- Spalten der Zeitreihenbezeichner – Wählen Sie für die Prognose mit mehreren Reihen die Spalten aus, die die einzelne Zeitreihe identifizieren. Databricks gruppiert die Daten nach diesen Spalten als unterschiedliche Zeitreihen und trainiert ein Modell für jede Datenreihe unabhängig voneinander.
- Primäre Metrik: Wählen Sie die primäre Metrik aus, die zum Auswerten und Auswählen des besten Modells verwendet wird.
- Schulungsframework: Wählen Sie die Frameworks für AutoML aus, die Sie erkunden möchten.
- Geteilte Spalte: Wählen Sie die Spalte aus, die benutzerdefinierte Datenteilung enthält. Die Werte müssen „train“, „validate“ und „test“ lauten.
- Gewichtungsspalte: Geben Sie die Spalte an, die für die Gewichtungszeitreihe verwendet werden soll. Alle Proben für eine bestimmte Zeitreihe müssen das gleiche Gewicht aufweisen. Die Gewichtung muss sich im Bereich [0, 10000] befinden.
- Ferienregion: Wählen Sie die Urlaubsregion aus, die als Kovariate in modellschulungen verwendet werden soll.
- Zeitüberschreitung: Legen Sie eine maximale Dauer für das AutoML-Experiment fest.
Ausführen des Experiments und Überwachen der Ergebnisse
Um das AutoML-Experiment zu starten, klicken Sie auf Schulung starten. Auf der Experimentschulungsseite können Sie folgende Aktionen ausführen:
- Beenden Sie das Experiment jederzeit.
- Monitor läuft.
- Navigieren Sie zur Laufseite für einen beliebigen Lauf.
Anzeigen von Ergebnissen oder Verwenden des besten Modells
Nach Abschluss der Schulung werden die Vorhersageergebnisse in der angegebenen Delta-Tabelle gespeichert, und das beste Modell wird im Unity-Katalog registriert.
Wählen Sie auf der Seite "Experimente" die folgenden schritte aus:
- Wählen Sie Vorhersagen anzeigen lassen aus, um die Tabelle mit den Prognoseergebnissen anzuzeigen.
- Wählen Sie Batch-Inferenz-Notizbuch aus, um ein automatisch generiertes Notizbuch für die Batch-Inferenz mit dem besten Modell zu öffnen.
- Wählen Sie Bereitstellungsendpunkt erstellen aus, um das beste Modell für einen Modellbereitstellungsendpunkt bereitzustellen.
Serverlose Prognose im Vergleich zur klassischen Berechnungsprognose
In der folgenden Tabelle sind die Unterschiede zwischen serverlosen Vorhersagen und Vorhersagen mit klassischer Compute zusammengefasst.
| Merkmal | Serverlose Prognose | Klassische Berechnungsvorhersage |
|---|---|---|
| Compute-Infrastruktur | Azure Databricks verwaltet die Computekonfiguration und optimiert automatisch Kosten und Leistung. | Vom Benutzer konfigurierte Rechenleistung |
| Steuerung | Modelle und Artefakte, die im Unity-Katalog registriert sind | Vom Benutzer konfigurierter Arbeitsbereichsdateispeicher |
| Algorithmusauswahl | Statistische Modelle sowie der Deep Learning Neural Net Algorithmus DeepAR | Statistische Modelle |
| Integration des Featurespeichers | Nicht unterstützt | Unterstützt |
| Automatisch generierte Notizbücher | Batchableitungsnotebook | Quellcode für alle Testversionen |
| Ein-Klick-Modell zur Modellbereitstellung | Unterstützt | Nicht unterstützt |
| Benutzerdefinierte Trainings-/Validierungs-/Testaufteilungen | Unterstützt | Nicht unterstützt |
| Benutzerdefinierte Gewichtungen für einzelne Zeitreihen | Unterstützt | Nicht unterstützt |