Muster für die Modellimplementierung
In diesem Artikel werden zwei gängige Muster für das Verschieben von ML-Artefakten durch den Stagingprozess und in die Produktion beschrieben. Die asynchrone Natur von Änderungen an Modellen und Code bedeutet, dass es mehrere mögliche Muster gibt, denen ein ML-Entwicklungsprozess folgen kann.
Modelle werden durch Code erstellt, aber die resultierenden Modellartefakte und der Code, der sie erstellt hat, können asynchron arbeiten. Das bedeutet, dass neue Modellversionen und Codeänderungen nicht unbedingt zur gleichen Zeit stattfinden. Betrachten Sie beispielsweise die folgenden Szenarien:
- Um betrügerische Transaktionen zu erkennen, entwickeln Sie eine ML-Pipeline, die ein Modell wöchentlich neu trainiert. Der Code ändert sich vielleicht nicht sehr oft, aber das Modell wird vielleicht jede Woche neu trainiert, um neue Daten einzubeziehen.
- Sie könnten ein großes Deep Neural Network erstellen, um Dokumente zu klassifizieren. In diesem Fall ist das Training des Modells rechenintensiv und zeitaufwändig, und das Modell wird wahrscheinlich nur selten neu trainiert. Der Code, der dieses Modell bereitstellt, bedient und überwacht, kann jedoch aktualisiert werden, ohne das Modell neu zu trainieren.
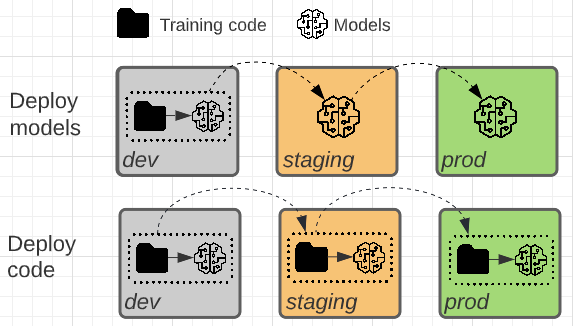
Die beiden Muster unterscheiden sich darin, ob das Modellartefakt oder der Trainingscode, der das Modellartefakt erzeugt, in die Produktion höher gestuft wird.
Bereitstellen von Code (empfohlen)
In den meisten Fällen empfiehlt Databricks den Ansatz „Code bereitstellen“. Dieser Ansatz wird in den empfohlenen MLOps-Workflow integriert.
Bei diesem Muster wird der Code für das Training der Modelle in der Entwicklungsumgebung entwickelt. Derselbe Code gelangt in den Stagingprozess und dann in die Produktion. Das Modell wird in jeder Umgebung trainiert: zunächst in der Entwicklungsumgebung als Teil der Modellentwicklung, in der Stagingumgebung (für eine begrenzte Teilmenge von Daten) als Teil der Integrationstests und in der Produktionsumgebung (für die vollständigen Produktionsdaten), um das endgültige Modell zu erzeugen.
Vorteile:
- In Unternehmen, in denen der Zugriff auf Produktionsdaten eingeschränkt ist, ermöglicht dieses Muster das Training des Modells anhand von Produktionsdaten in der Produktionsumgebung.
- Automatisiertes erneutes Training von Modellen ist sicherer, da der Trainingscode überprüft, getestet und für die Produktion genehmigt wird.
- Der unterstützende Code folgt dem gleichen Muster wie der Code für das Training des Modells. Beide durchlaufen Integrationstests im Stagingprozess.
Nachteile:
- Die Lernkurve für wissenschaftliche Fachkräfte für Daten, die ihren Code an Projektmitarbeiter weitergeben, kann steil sein. Vordefinierte Projektvorlagen und Workflows sind hilfreich.
Auch bei diesem Muster müssen die wissenschaftlichen Fachkräfte für Daten in der Lage sein, die Trainingsergebnisse aus der Produktionsumgebung zu überprüfen, da sie über das Wissen verfügen, ML-spezifische Probleme zu erkennen und zu beheben.
Wenn Ihre Situation es erfordert, dass das Modell im Stagingprozess mit dem gesamten Dataset der Produktion trainiert wird, können Sie einen Hybridansatz verwenden, indem Sie den Code im Stagingprozess bereitstellen, das Modell trainieren und dann das Modell in der Produktion implementieren. Dieser Ansatz spart Trainingskosten in der Produktion, verursacht aber zusätzliche Kosten im Stagingprozess.
Bereitstellen von Modellen
Bei diesem Muster wird das Modellartefakt durch Trainieren von Code in der Entwicklungsumgebung generiert. Das Artefakt wird anschließend in der Stagingumgebung getestet, bevor es in der Produktionsumgebung implementiert wird.
Berücksichtigen Sie diese Option, wenn eine oder mehrere der folgenden Bedingungen zutreffen:
- Das Training von Modellen ist sehr teuer oder schwer zu reproduzieren.
- Die gesamte Arbeit erfolgt in einem einzelnen Azure Databricks-Arbeitsbereich.
- Sie arbeiten nicht mit externen Repositorys oder einem CI/CD-Prozess.
Vorteile:
- Eine einfachere Übergabe für wissenschaftliche Fachkräfte für Daten
- In Fällen, in denen das Modelltraining teuer ist, muss das Modell nur einmal trainiert werden.
Nachteile:
- Wenn der Zugriff auf Produktionsdaten von der Entwicklungsumgebung aus nicht möglich ist (was aus Sicherheitsgründen der Fall sein kann), ist diese Architektur möglicherweise nicht praktikabel.
- Das automatisierte erneute Modelltraining ist bei diesem Muster schwierig. Sie könnten das erneute Training in der Entwicklungsumgebung automatisieren, aber das Team, das für die Implementierung des Modells in der Produktion verantwortlich ist, akzeptiert das resultierende Modell möglicherweise nicht als produktionsreif.
- Unterstützender Code, z. B. Pipelines, die für Feature Engineering, Rückschluss und Überwachung verwendet werden, muss separat für die Produktion bereitgestellt werden.
In der Regel entspricht eine Umgebung (Entwicklung, Staging oder Produktion) einem Katalog in Unity Catalog. Ausführliche Informationen zum Implementieren dieses Musters finden Sie im Upgradeleitfaden.
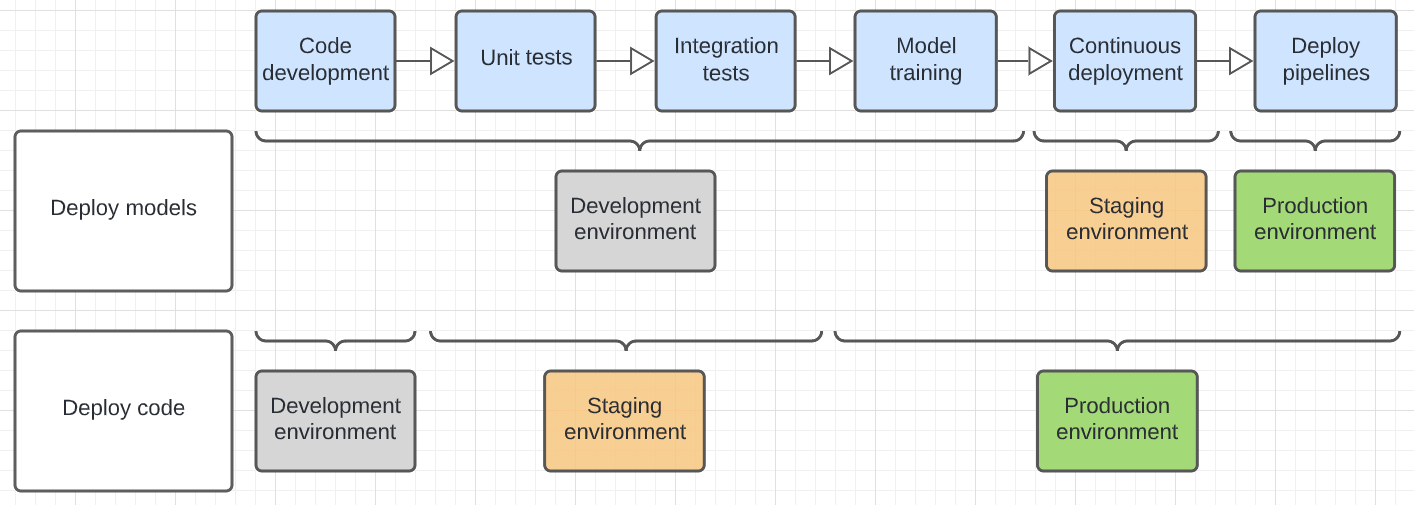
Im folgenden Diagramm wird der Codelebenszyklus für die oben genannten Bereitstellungsmuster in den verschiedenen Ausführungsumgebungen gegenübergestellt.
Die im Diagramm gezeigte Umgebung ist die endgültige Umgebung, in der ein Schritt ausgeführt wird. Zum Beispiel werden im Modell zum Bereitstellen von Modellen abschließende Einheiten- und Integrationstests in der Entwicklungsumgebung durchgeführt. Im Bereitstellungscodemuster werden Einheitentests und Integrationstests in den Entwicklungsumgebungen ausgeführt, und abschließende Einheiten- und Integrationstests werden in der Staging-Umgebung durchgeführt.