Führen Sie Ihr eigenes LLM-Endpunkt-Benchmarking durch
Dieser Artikel enthält ein von Databricks empfohlenes Notebook-Beispiel für das Benchmarking eines LLM-Endpunkts. Es enthält auch eine kurze Einführung in die Durchführung von LLM-Rückschlüssen von Databricks und berechnet Wartezeit und Durchsatz als Endpunktleistungsmetriken.
LLM-Rückschluss auf Databricks misst Token pro Sekunde für den bereitgestellten Durchsatzmodus für Foundation Model-APIs. Siehe Was bedeuten die Bereiche für Token pro Sekunde im bereitgestellten Durchsatz?.
Benchmarking Beispiel-Notizbuch
Sie können das folgende Notebook in Ihre Databricks-Umgebung importieren und den Namen Ihres LLM-Endpunkts angeben, um einen Auslastungstest auszuführen.
Benchmarking eines LLM-Endpunkts
Einführung in die LLM-Rückschlüsse
LLMs führen Rückschlüsse in einem zweistufigen Prozess durch:
- Vorausfüllen, wobei die Token in der Eingabeaufforderung parallel verarbeitet werden.
- Decodierung, bei welcher der Text automatisch regressiv um ein Token nach dem anderen erzeugt wird. Jedes generierte Token wird an die Eingabe angefügt und wieder in das Modell eingespeist, um das nächste Token zu generieren. Die Generierung wird beendet, wenn das LLM ein spezielles Stopptoken ausgibt oder eine benutzerdefinierte Bedingung erfüllt ist.
Die meisten Produktionsanwendungen verfügen über ein Latenzbudget und Databricks empfiehlt, den Durchsatz zu maximieren, da das Latenzbudget eingehalten wird.
- Die Anzahl der Eingabetoken wirkt sich erheblich auf den erforderlichen Arbeitsspeicher aus, um Anforderungen zu verarbeiten.
- Die Anzahl der Ausgabetoken dominiert die Antwortgesamtwartezeit.
Databricks unterteilt die LLM-Rückschlüsse in die folgenden Untermetriken:
- Zeit für das erste Token (TTFT): So schnell können Benutzer die Ausgabe des Modells nach der Eingabe ihrer Abfrage sehen. Geringe Wartezeiten auf eine Antwort sind bei Echtzeit-Interaktionen von entscheidender Bedeutung, bei Offline-Workloads jedoch weniger wichtig. Diese Metrik wird durch die zum Verarbeiten der Eingabeaufforderung erforderliche Zeit gesteuert und dann das erste Ausgabetoken generiert.
- Zeit pro Ausgabetoken (TPOT): Zeit zum Generieren eines Ausgabetokens für jeden Benutzer, der das System abfragt. Diese Metrik entspricht der Wahrnehmung der „Geschwindigkeit“ des Modells. Ein TPOT von 100 Millisekunden pro Token würde beispielsweise 10 Token pro Sekunde oder ~450 Wörter pro Minute bedeuten, was schneller ist, als ein normaler Mensch lesen kann.
Basierend auf diesen Metriken kann die Gesamtlatenz und der Durchsatz wie folgt definiert werden:
- Wartezeit = TTFT + (TPOT) * (die Anzahl der zu generierenden Token)
- Durchsatz = Anzahl der Ausgabetoken pro Sekunde für alle Parallelitätsanforderungen
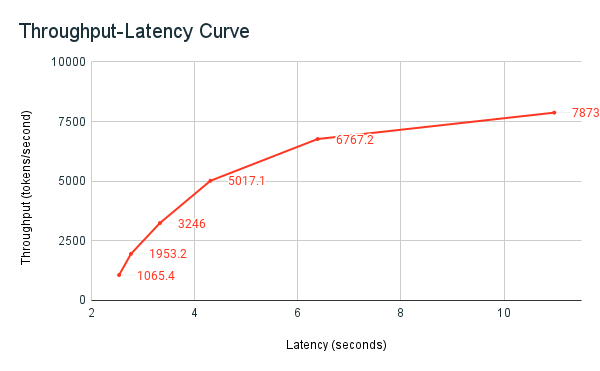
Auf Databricks können LLM-Dienstendpunkte skaliert werden, um die von Clients gesendete Last mit mehreren gleichzeitigen Anforderungen abzugleichen. Es gibt einen Kompromiss zwischen Wartezeit und Durchsatz. Dies liegt daran, dass gleichzeitige Anforderungen an LLM-Endpunkte gleichzeitig verarbeitet werden können und verarbeitet werden. Bei einer geringen Anzahl gleichzeitiger Anforderungslasten ist die Wartezeit so gering wie möglich. Wenn Sie jedoch die Anforderungslast erhöhen, kann die Wartezeit möglicherweise steigen, aber der Durchsatz steigt wahrscheinlich auch. Das liegt daran, dass zwei Anforderungen im Wert von Token pro Sekunde in weniger als der doppelten Zeit verarbeitet werden können.
Daher ist die Kontrolle der Anzahl der parallelen Anforderungen an Ihr System der Schlüssel zum Ausgleich von Latenz und Durchsatz. Wenn Sie einen Anwendungsfall mit geringer Wartezeit haben, möchten Sie weniger gleichzeitige Anforderungen an den Endpunkt senden, um die Wartezeit gering zu halten. Wenn Sie einen Anwendungsfall mit hohem Durchsatz haben, möchten Sie den Endpunkt mit vielen Parallelitätsanforderungen sättigen, da sich ein höherer Durchsatz auch auf Kosten der Wartezeit lohnt.
Databricks-Benchmarking-Nutzung
Das zuvor freigegebene Benchmarking-Beispiel-Notebook ist der Benchmarking-Nutzen von Databricks. Das Notebook zeigt die Wartezeit- und Durchsatzmetriken an und zeichnet den Durchsatz im Vergleich zur Latenzkurve über unterschiedliche Anzahl paralleler Anforderungen ab. Die automatische Skalierung von Databricks-Endpunkten basiert auf einer „ausgewogenen“ Strategie zwischen Wartezeit und Durchsatz. Im Notebook sehen Sie, dass die Latenzzeit und der Durchsatz steigen, wenn mehr Benutzer gleichzeitig den Endpunkt abfragen.
Weitere Einzelheiten zur Philosophie von Databricks in Bezug auf das LLM-Leistungsbenchmarking finden Sie im Blog LLM Inference Performance Engineering: Bewährte Methoden beschrieben.