Foundation Model-APIs mit bereitgestelltem Durchsatz
In diesem Artikel wird gezeigt, wie Sie Modelle mit Foundation Model-APIs mit bereitgestelltem Durchsatz bereitstellen. Databricks empfiehlt bereitgestellten Durchsatz für Produktionsworkloads. Er optimiert Rückschlüsse für Basismodelle mit Leistungsgarantien.
Was ist bereitgestellter Durchsatz?
Der bereitgestellte Durchsatz bezieht sich darauf, für wie viele Anforderungen Sie gleichzeitig Token an einen Endpunkt senden können. Bereitstellungsendpunkte für bereitgestellten Durchsatz sind dedizierte Endpunkte, die in Form eines Bereichs von Token pro Sekunde, die Sie an den Endpunkt senden können, konfiguriert werden.
Weitere Informationen finden Sie in den folgenden Ressourcen:
- Was bedeuten die Bereiche von Token pro Sekunde im bereitgestellten Durchsatz?
- Führen Sie Ihr eigenes LLM-Endpunkt-Benchmarking
Eine Liste der unterstützten Modellarchitekturen für Endpunkte mit bereitgestelltem Durchsatz finden Sie unter Bereitgestellter Durchsatz.
Anforderungen
Siehe Anforderungen . Informationen darüber, wie man fein abgestimmte Foundation-Modelle bereitstellt, finden Sie unter Bereitstellen fein abgestimmter Foundation-Modelle.
[Empfohlen] Bereitstellen von Foundation-Modellen aus dem Unity-Katalog
Wichtig
Dieses Feature befindet sich in der Public Preview.
Databricks empfiehlt die Verwendung der Foundation-Modelle, die im Unity-Katalog vorinstalliert sind. Sie finden diese Modelle im Katalog system im Schema ai (system.ai).
So stellen Sie ein Basismodell bereit
- Navigieren Sie im Katalog-Explorer zu
system.ai. - Klicken Sie auf den Namen des Modells, das Sie bereitstellen möchten.
- Klicken Sie auf der Modellseite auf die Schaltfläche Dieses Modell bereitstellen.
- Die Seite Bereitstellungsendpunkt erstellen wird angezeigt. Siehe Erstellen eines Endpunkts mit bereitgestelltem Durchsatz mithilfe der Benutzeroberfläche.
Bereitstellen von Foundationsmodellen aus dem Databricks Marketplace
Alternativ können Sie Foundation-Modelle aus Databricks Marketplaceim Unity-Katalog installieren.
Sie können nach einer Modellfamilie suchen, auf der Modellseite die Option Zugriff erhalten auswählen und die Anmeldeinformationen eingeben, um das Modell in Unity Catalog zu installieren.
Nachdem das Modell im Unity-Katalog installiert wurde, können Sie einen Modell-Serving-Endpunkt mithilfe der Serving-Benutzeroberfläche erstellen.
Bereitstellen von DBRX-Modellen
Databricks empfiehlt die Bereitstellung des DBRX Instruct-Modells für Ihre Workloads. Um das DBRX-Instruct-Modell mit bereitgestelltem Durchsatz bereitzustellen, folgen Sie dem Leitfaden in [Empfohlen] Bereitstellen von Basismodellen aus Unity Catalog.
Bei der Bereitstellung dieser DBRX-Modelle unterstützt der bereitgestellte Durchsatz eine Kontextlänge von bis zu 16k.
DBRX-Modelle verwenden die folgende Standardsystemaufforderung, um die Relevanz und Genauigkeit in Modellantworten sicherzustellen:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Bereitstellung optimierter Grundmodelle
Wenn Sie die Modelle im system.ai-Schema nicht verwenden oder Modelle aus dem Databricks Marketplace nicht installieren können, können Sie ein fein abgestimmtes Basismodell bereitstellen, indem Sie es im Unity-Katalog eintragen. In diesem Abschnitt und den folgenden Abschnitten wird gezeigt, wie Sie Ihren Code so einrichten, dass ein MLflow-Modell im Unity-Katalog protokolliert und Ihr bereitgestellter Durchsatzendpunkt entweder über die Benutzeroberfläche oder die REST-API erstellt wird.
Die unterstützten optimierten Meta Llama 3.1-, 3.2- und 3.3-Modelle sowie deren regionale Verfügbarkeit finden Sie unter Grenzwerte für den bereitgestellten Durchsatz.
Anforderungen
- Die Bereitstellung fein abgestimmter Foundation-Modelle wird nur von MLflow 2.11 oder höher unterstützt. Databricks Runtime 15.0 ML und höher vorinstalliert die kompatible MLflow-Version.
- Databricks empfiehlt die Verwendung von Modellen im Unity-Katalog zum schnelleren Hochladen und Herunterladen großer Modelle.
Definieren des Katalogs, des Schemas und des Modellnamens
Um ein fein abgestimmtes Foundation-Modell bereitzustellen, definieren Sie den Unity-Katalog, das Schema und den Modellnamen Ihrer Wahl.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Protokollieren Ihres Modells
Um den bereitgestellten Durchsatz für Ihren Modellendpunkt zu aktivieren, müssen Sie Ihr Modell mit dem MLflow-transformers-Flavour protokollieren und das Argument task mit der entsprechenden Modelltypschnittstelle aus den folgenden Optionen angeben:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Diese Argumente geben die API-Signatur an, die für den Modellbereitstellungsendpunkt verwendet wird. Weitere Informationen zu diesen Aufgaben und entsprechenden Eingabe-/Ausgabeschemas finden Sie in der MLflow-Dokumentation .
Im Folgenden sehen Sie ein Beispiel für das Protokollieren eines textvervollständigenden Sprachmodells, das mit MLflow protokolliert wird:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Hinweis
Wenn Sie MLflow vor 2.12 verwenden, müssen Sie stattdessen den Vorgang innerhalb metadata Parameters derselben mlflow.transformer.log_model() Funktion angeben.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Der bereitgestellte Durchsatz unterstützt auch die einfachen (Basis-) und großen GTE-Einbettungsmodelle. Im Folgenden finden Sie ein Beispiel zum Protokollieren des Modells Alibaba-NLP/gte-large-en-v1.5, damit es mit dem bereitgestellten Durchsatz bereitgestellt werden kann:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Nachdem Ihr Modell in Unity Catalog protokolliert wurde, fahren Sie mit Erstellen eines Endpunkts mit bereitgestelltem Durchsatz mithilfe der Benutzeroberfläche fort, um einen Modellbereitstellungsendpunkt mit bereitgestelltem Durchsatz zu erstellen.
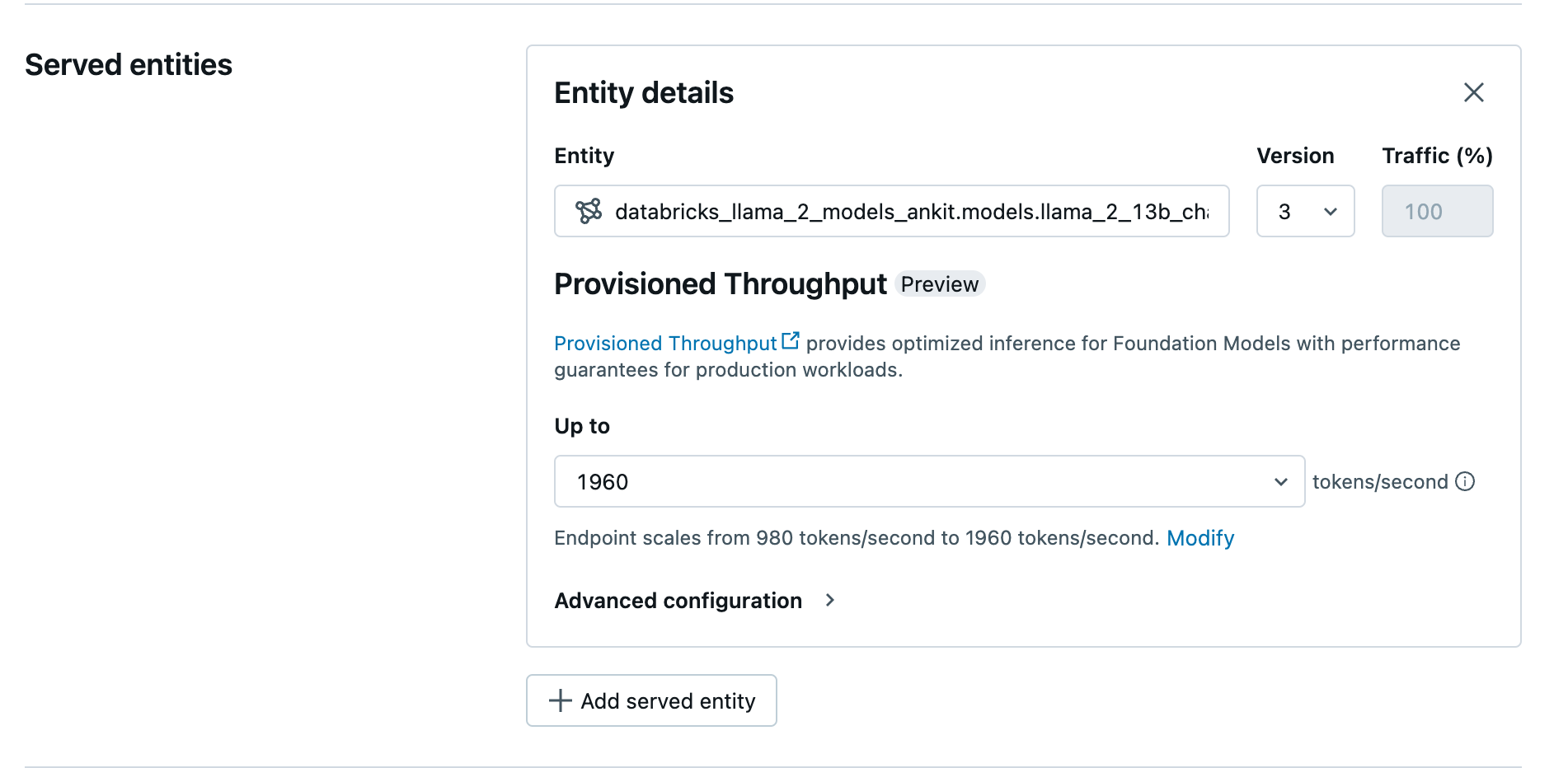
Erstellen des bereitgestellten Durchsatzendpunkts mithilfe der Benutzeroberfläche
Nachdem sich das protokollierte Modell im Unity-Katalog befindet, richten Sie einen Endpunkt für die bereitgestellte Durchsatzverarbeitung mit den folgenden Schritten ein:
- Navigieren Sie in Ihrem Arbeitsbereich zur Benutzeroberfläche für die Bereitstellung.
- Wählen Sie Bereitstellungsendpunkt erstellen aus.
- Wählen Sie im Feld Entität Ihr Modell aus dem Unity-Katalog aus. Für in Frage kommende Modelle wird auf der Benutzeroberfläche für die bereitgestellte Entität der Bildschirm Bereitgestellter Durchsatz angezeigt.
- In der Dropdownliste Bis zu können Sie den Durchsatz in Form der maximalen Anzahl von Token pro Sekunde für Ihren Endpunkt konfigurieren.
- Endpunkte mit bereitgestelltem Durchsatz werden automatisch skaliert. Sie können Ändern auswählen, um die Mindestanzahl von Token pro Sekunde anzuzeigen, auf die Ihr Endpunkt herunterskalieren kann.
Erstellen Des bereitgestellten Durchsatzendpunkts mithilfe der REST-API
Um Ihr Modell im bereitgestellten Durchsatzmodus mithilfe der REST-API bereitzustellen, müssen Sie min_provisioned_throughput und max_provisioned_throughput Felder in Ihrer Anforderung angeben. Wenn Sie Python bevorzugen, können Sie auch einen Endpunkt mithilfe des MLflow Deployment SDKerstellen.
Informationen zum Ermitteln des geeigneten Bereichs des bereitgestellten Durchsatzes für Ihr Modell finden Sie unter Schrittweises Abrufen des bereitgestellten Durchsatzes.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Logarithmische Wahrscheinlichkeit für Chatvervollständigungsaufgaben
Für Chatabschlussaufgaben können Sie den logprobs-Parameter verwenden, um die Protokollwahrscheinlichkeit eines Token bereitzustellen, das als Teil des Erstellungsprozesses für große Sprachenmodelle erfasst wird.For chat completion tasks, you can use the logprobs parameter to provide the log probability of a token being sampled as part of the large language model generation process. Sie können logprobs für eine Vielzahl von Szenarien verwenden, einschließlich Klassifizierung, Bewertung der Modellunsicherheit und Ausführen von Auswertungsmetriken. Details zu Parametern finden Sie unter Chataufgabe.
Schrittweises Abrufen des bereitgestellten Durchsatzes
Der bereitgestellte Durchsatz ist in Schritten von Token pro Sekunde verfügbar, wobei bestimmte Schritten je nach Modell variieren. Um den geeigneten Bereich für Ihre Anforderungen zu identifizieren, empfiehlt Databricks die Verwendung der Modelloptimierungsinformations-API innerhalb der Plattform.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Im Folgenden sehen Sie eine Beispielantwort der API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Notebook-Beispiele
Die folgenden Notizbücher zeigen Beispiele, wie man eine Foundation Model-API mit bereitgestelltem Durchsatz erstellt.
Notebook: Bereitgestellter Durchsatz für GTE-Modelle
Notebook: Bereitgestellter Durchsatz für BGE-Modelle
Das folgende Notebook zeigt, wie Sie das destillierte DeepSeek R1-Llama-Modell in Unity Catalog herunterladen und registrieren, sodass Sie es über einen Endpunkt von Foundation Model-APIs mit bereitgestelltem Durchsatz bereitstellen können.
Notebook: Bereitgestellter Durchsatz für das destillierte DeepSeek R1-Llama-Modell
Einschränkungen
- Die Modellbereitstellung kann aufgrund von GPU-Kapazitätsproblemen fehlschlagen, was zu einem Timeout bei der Erstellung oder Aktualisierung des Endpunkts führt. Wenden Sie sich an Ihr Databricks-Kontoteam, um bei der Lösung zu helfen.
- Die automatische Skalierung für Foundation Models-APIs ist langsamer als die CPU-Modellbereitstellung. Databricks empfiehlt eine Überbereitstellung, um Anforderungstimeouts zu vermeiden.
- GTE v1.5 (Englisch) generiert keine normalisierten Einbettungen.